-
C++项目:高并发内存池
文章目录
全文约 36181 字,预计阅读时长: 103分钟
项目介绍
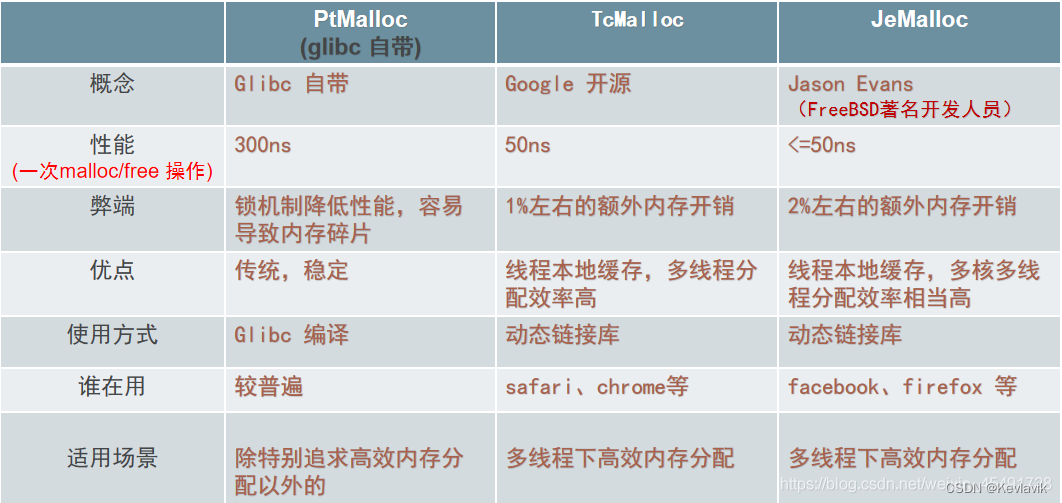
当前项目是实现一个高并发的内存池,他的原型是google的一个开源项目tcmalloc,tcmalloc全称Thread-Caching Malloc,即线程缓存的malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数(malloc、free)。new、delete底层使用的也是malloc、free。
这个项目是把tcmalloc最核心的框架简化后拿出来,模拟实现出一个自己的高并发内存池,目的就是学习其精华
这个项目会用到C/C++、数据结构(链表、哈希桶)、操作系统内存管理、单例模式、多线程、互斥锁等等方面的知识。
什么是内存池
池化技术
所谓“池化技术”,就是程序先向系统申请过量的资源,然后自己管理,以备不时之需。之所以要申请过量的资源,是因为每次申请该资源都有较大的开销,不如提前申请好了,这样使用时就会变得非常快捷,大大提高程序运行效率。
- 在计算机中,有很多使用“池”这种技术的地方,除了内存池,还有连接池、线程池、对象池等。
- 以服务器上的线程池为例,它的主要思想是:先启动若干数量的线程,让它们处于睡眠状态,当接收到客户端的请求时,唤醒池中某个睡眠的线程,让它来处理客户端的请求,当处理完这个请求,线程又进入睡眠状态。
- 生活中的例子:上学时期的生活费,通常是向家长准备一周的或一个月的,而不是每顿饭吃完了每次都向家长要。
内存池
内存池是指程序预先从操作系统申请一块足够大内存,此后,当程序中需要申请内存的时候,不是直接向操作系统申请,而是直接从内存池中获取。原因一每次都会有从用户态到内核态的切换,要做大量的工作。
同理,当程序释放内存的时候,并不真正将内存返回给操作系统,而是返回内存池。当程序退出(或者特定时间)时,内存池才将之前申请的内存真正释放。
内存池主要解决的问题
内存池主要解决的当然是效率的问题,其次如果作为系统的内存分配器的角度,还需要解决一下内存碎片的问题。
再需要补充说明的是内存碎片分为外碎片和内碎片。
- 外部碎片是一些空闲的连续内存区域太小,这些内存空间不连续,以至于合计的内存足够,但是不能满足一些的内存分配申请需求。
- 内部碎片是由于一些对齐的需求,导致分配出去的空间中一些内存无法被利用。内碎片问题,我们后面项目就会看到,那会再进行更准确的理解。
malloc
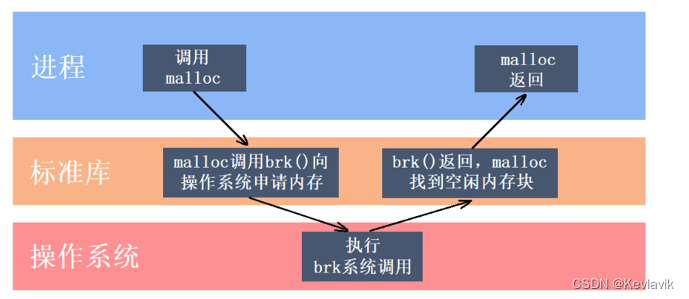
C/C++中我们要动态申请内存都是通过malloc去申请内存,但是我们要知道,实际我们不是直接去堆获取内存的;而是通过库函数,库函数在通过OS提供的接口去申请。由于库函数会考虑很多情况,所以效率比较慢。
注意,此时操作系统根本就没有真正的分配物理内存。那么什么时候操作系统才会真正的分配物理内存呢?
答案是当我们真正使用这段内存时,当我们真正使用这段内存时,这时会产生一个缺页错误,操作系统捕捉到该错误后开始真正的分配物理内存,操作系统处理完该错误后我们的程序才能真正的读写这块内存。
库函数的malloc就是一个内存池。
- malloc() 相当于向操作系统“批发”了一块较大的内存空间,然后“零售”给程序用。当全部“售完”或程序有大量的内存需求时,再根据实际需求向操作系统“进货”。
malloc调用brk后开始转入内核态,此时操作系统中的虚拟内存系统开始工作,扩大进程的堆区,注意额外扩大的这一部分内存仅仅是虚拟内存。
malloc的实现方式有很多种,一般不同编译器平台用的都是不同的。比如windows的vs系列用的微软自己写的一套,linux gcc用的glibc中的ptmalloc。
malloc的此层实现原理
页
- 向系统申请内存以页为单位:你想申请多少个页的内存?实际系统提供给的接口
VirtualAlloc还是以字节为单位。 - 根据不同的平台调用不同的接口。
- 8KB = 8 * 1024 Byte
//根据平台使用OS提供的接口直接去堆上(物理内存)申请内存 inline static void* SystemAlloc(size_t kpage) { #ifdef _WIN32 //win32 OS提供的接口 void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE); #else //linux下brk mmap等 #endif // _WIN32 if (ptr == nullptr) { throw std::bad_alloc(); } return ptr; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
页
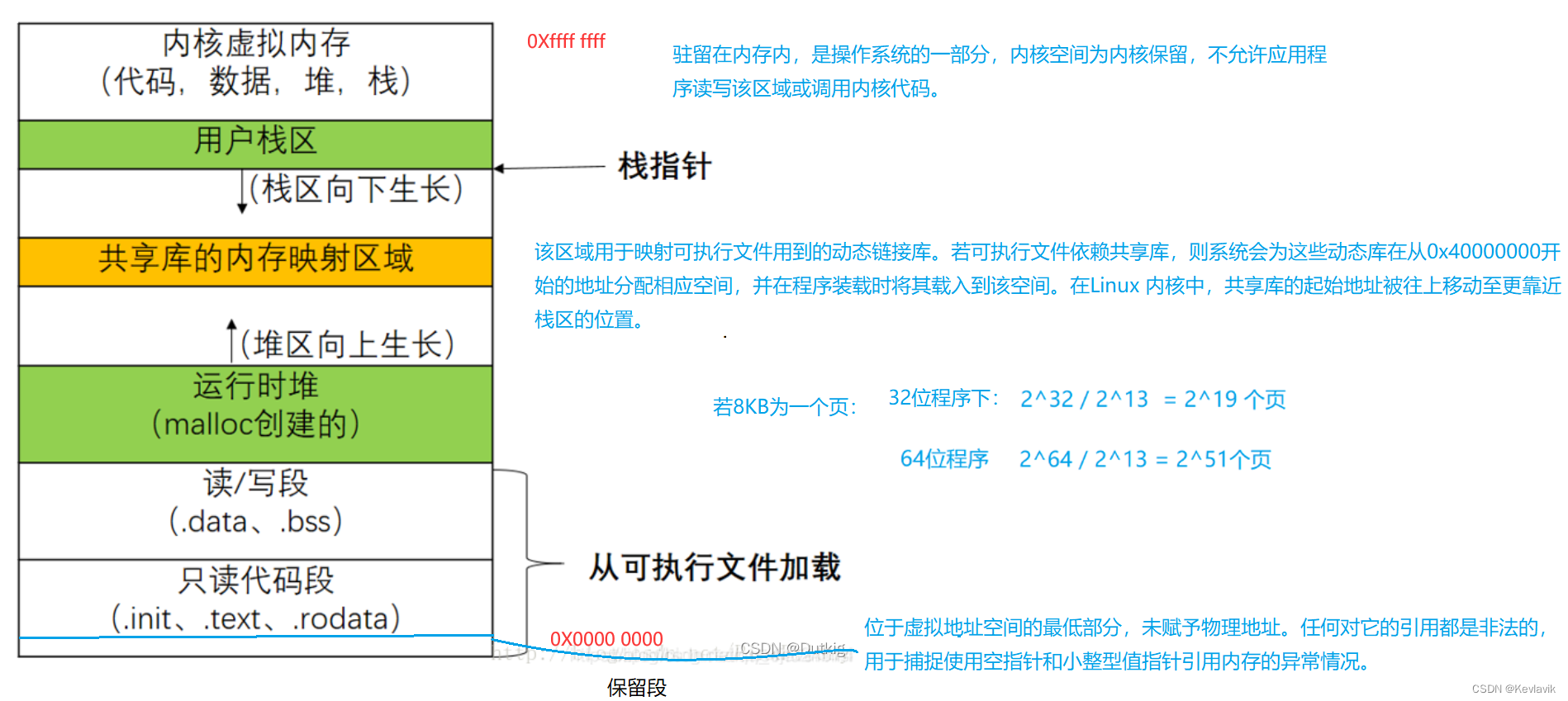
进程的虚拟内存被分为若干个“段”;每个段其实还被分成了若干个“块”,我们将这个“块”称为“页”。注:绝大多数处理器上的内存页的默认大小都是 4KB,虽然部分处理器会使用 8KB、16KB 或者 64KB 作为默认的页面大小,但是 4KB 的页面仍然是操作系统默认内存页配置的主流。本文按8KB。
内存的映射(虚拟地址和物理地址之间的转换)也是以“页”为单位的;一般来说一页的大小4K。注意:虚拟地址一般由段号、页号、页中偏移量构成,从而最终计算出你的物理地址;缺页:消除了进程全部载入内存中,按需调页(也就是换页)。以上就是Linux的段页式内存管理。Linux ——进程的虚拟地址空间,逻辑地址和物理地址,进程管理命令
- 知道页号可以得出申请到的内存地址,根据地址可以得出页号
定长的内存池
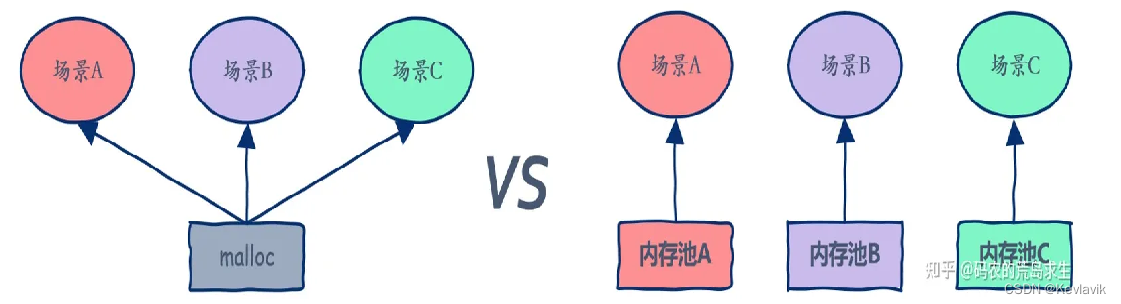
malloc其实就是一个通用的大众货,什么场景下都可以用,但是什么场景下都可以用就意味着什么场景下都不会有很高的性能
- 我们先来设计一个定长内存池当然这个定长内存池:解决固定大小的内存申请释放需求。
- 学习他目的有两层:
- 先熟悉一下简单内存池是如何控制的,他会作为我们后面内存池的一个基础组件。
- 性能达到极致同时不用考虑内存碎片的问题。
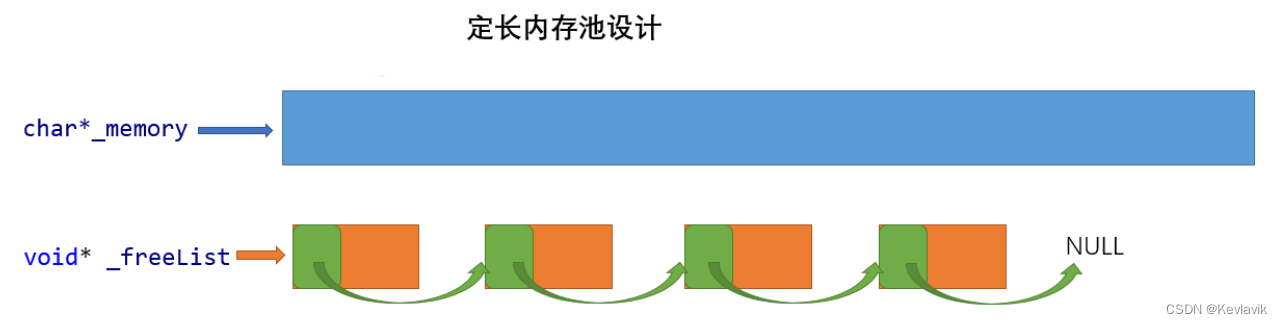
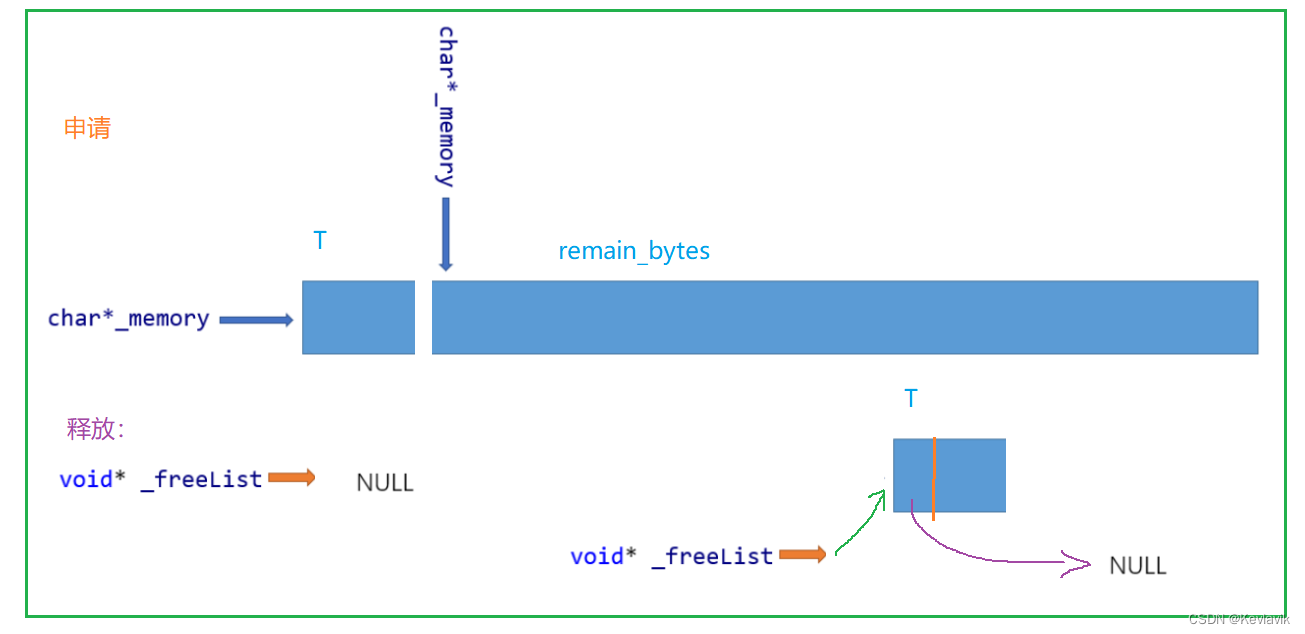
char* _memory:指向大块内存的指针void* _freelist:对进程不用的还回来的内存进行管理。- Windows 32位平台下
viod*是 4 Byte; 64位下是8 Byte。
#include#include #include using std::cout; using std::endl; #ifdef _WIN32 #include #else // #endif //template //class ObjectPool //{ //}; //根据平台使用OS提供的接口直接去堆上(物理内存)申请内存 inline static void* SystemAlloc(size_t kpage) //需要多少的页 8*1024 Byte { #ifdef _WIN32 //win32 OS提供的接口 void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE); #else //linux下brk mmap等 #endif // _WIN32 if (ptr == nullptr) { throw std::bad_alloc(); } return ptr; } template<class T> class ObjectPool { private: char* _memory = nullptr; // 指向大块内存的指针 size_t _remainBytes = 0; // 大块内存在切分过程中剩余字节数 void* _freelist = nullptr; // 还回来过程中链接的自由链表的头指针 public: T* New() { T* obj = nullptr; //头上四个字节处存着 下一个内存块儿的地址 //32位平台下viod* 是 4; 64位下是8 个字节大小 if (_freelist) { void* next = *((void**)_freelist); obj = (T*)_freelist; _freelist = next; } else { if (_remainBytes < sizeof(T)) { //一次要大一点的 128 KB _remainBytes = 128 <<10; //_memory = (char*)malloc(_remainBytes); //直接忽略平台的差异 _memory = (char*)SystemAlloc(_remainBytes >> 13); //要几个kpage if (_memory == nullptr) { throw std::bad_alloc(); } } obj = (T*)_memory; //确定不同平台下T类型的大小;起码要留出一个存放下一个内存块儿地址的空间大小。 size_t objsize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T); _memory += objsize; _remainBytes -= objsize; } new(obj)T; //定位new,显式调用T的构造函数初始化 因为原版库函数new就会调用T类型的构造函数 return obj; } void Delete(T* obj) { obj->~T(); //显式调用析构函数清理对象 显式调用定位new 就会显式调用析构。 //头插 *((void**)obj) = _freelist; _freelist = obj; } }; - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
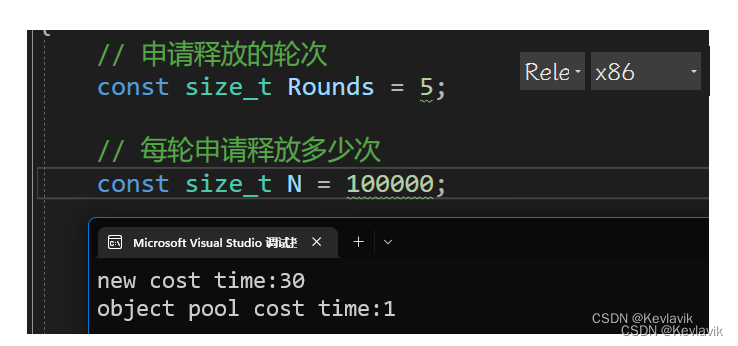
对比测试
库函数 malloc 与 定长内存池的对比测试
struct TreeNode { int _val; TreeNode* _left; TreeNode* _right; TreeNode() :_val(0) , _left(nullptr) , _right(nullptr) { } }; void TestObjectPool() { // 申请释放的轮次 const size_t Rounds = 5; // 每轮申请释放多少次 const size_t N = 100000; std::vector<TreeNode*> v1; v1.reserve(N); size_t begin1 = clock(); for (size_t j = 0; j < Rounds; ++j) { for (int i = 0; i < N; ++i) { v1.push_back(new TreeNode); } for (int i = 0; i < N; ++i) { delete v1[i]; } v1.clear(); } size_t end1 = clock(); std::vector<TreeNode*> v2; v2.reserve(N); ObjectPool<TreeNode> TNPool; size_t begin2 = clock(); for (size_t j = 0; j < Rounds; ++j) { for (int i = 0; i < N; ++i) { v2.push_back(TNPool.New()); } for (int i = 0; i < N; ++i) { TNPool.Delete(v2[i]); } v2.clear(); } size_t end2 = clock(); cout << "new cost time:" << end1 - begin1 << endl; cout << "object pool cost time:" << end2 - begin2 << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
高并发内存池整体框架设计
现代很多的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。malloc本身其实已经很优秀,那么我们项目的原型tcmalloc就是在多线程高并发的场景下更胜一筹。
所以实现的内存池需要考虑以下几方面的问题:1. 性能问题。2. 内存碎片问题。3. 多线程环境下,锁竞争问题。
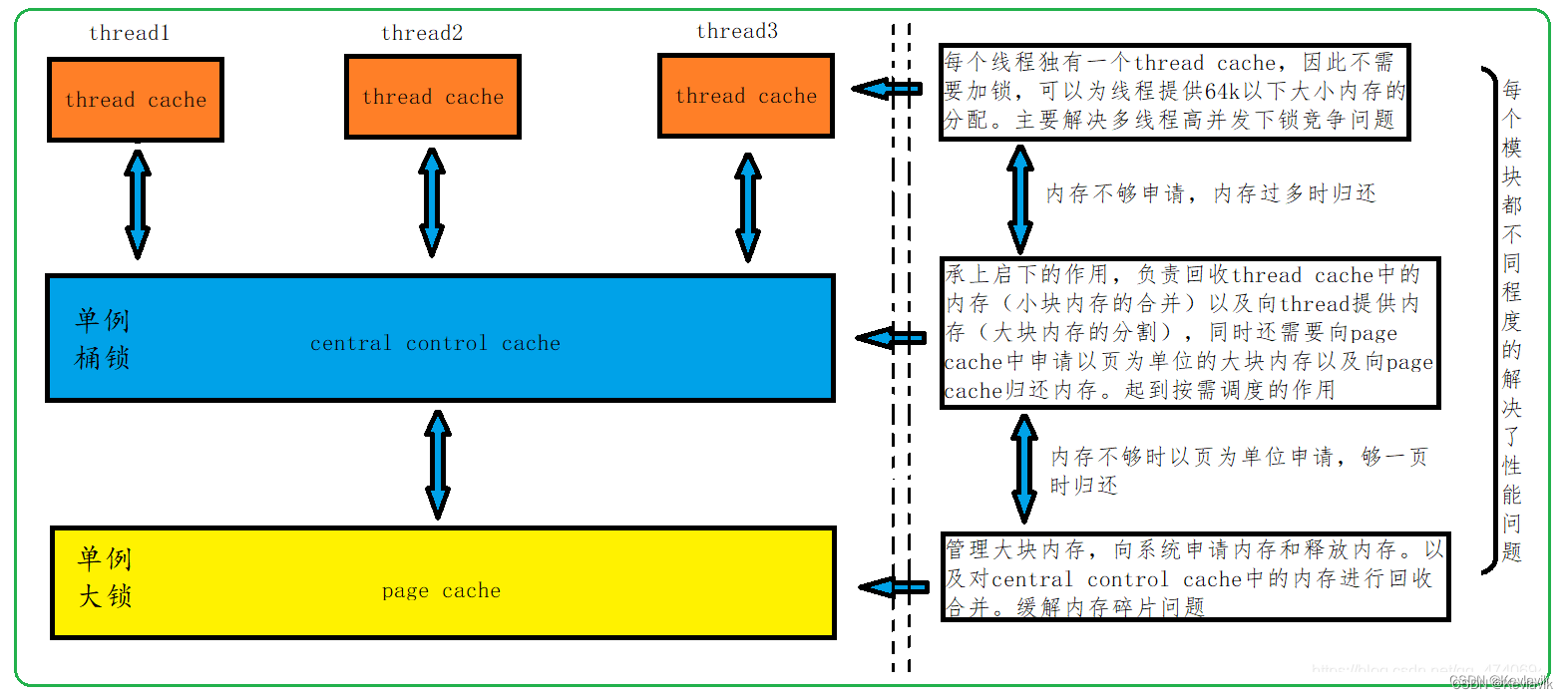
concurrent memory pool主要由以下3个部分构成:
thread cache:线程缓存是每个线程独有的,用于小于256KB的内存的分配,线程从这里申请内存不需要加锁,每个线程独享一个cache,这也就是这个并发线程池高效的地方。central cache:中心缓存是所有线程所共享,thread cache是按需从central cache中获取的对象。central cache合适的时机回收thread cache中的对象,避免一个线程占用了太多的内存,而其他线程的内存吃紧,达到内存分配在多个线程中更均衡的按需调度的目的。central cache是存在竞争的,所以从这里取内存对象是需要加锁,首先这里用的是桶锁,其次只有thread cache的没有内存对象时才会找central cache,所以这里竞争不会很激烈。page cache:页缓存是在central cache缓存上面的一层缓存,存储的内存是以页为单位存储及分配的,central cache没有内存对象时,从page cache分配出一定数量的page,并切割成定长大小的小块内存,分配给central cache。当一个span的几个跨度页的对象都回收以后,page cache会回收central cache满足条件的span对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题。
首先把申请流程走通,其次走释放;接着测试;随后一些优化;最后项目总结。
整个进程会有多个线程内存池
Thread Cache,但只有一个Central Cache和一个Page Cache,所以后两者都要设计成单例模式。
thread cache
- thread cache是哈希桶结构。
- 每个桶是由一个或多个定长内存块为对象映射的自由链表,不同的桶(内存块起始指针)映射至不同的下标,相同大的内存块儿放入到同一个桶下。
- 每个线程都会有一个thread cache对象,这样每个线程在这里获取对象和释放对象时是无锁的。
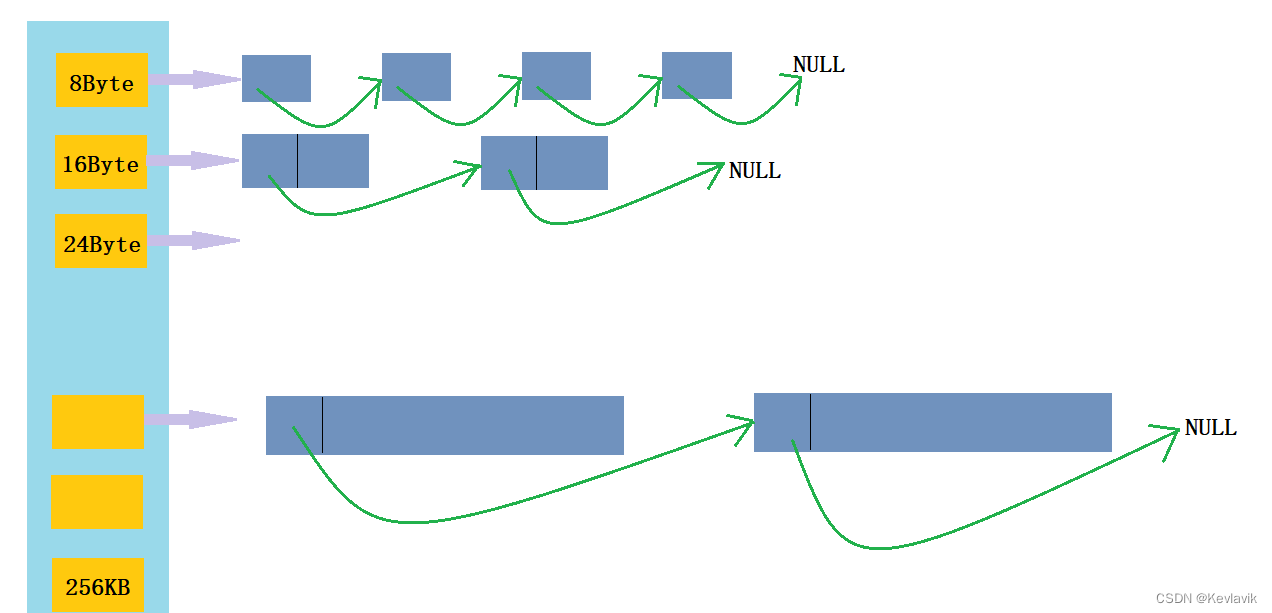
整体设计
FreeList:管理切分好的小对象(内存块)的自由链表。起初链表下一个内存块都没有的,是下一层中心池将一个或多个页分成一个个对应的对齐内存块分配给线程内存池的。- 为了记录下一个内存块的地址,依然采取将内存块头4/8个字节存储。强转成二级指针,32位下是4,解引用就等于取到了头4个字节,就可以对其赋值。
thread cache是一个FreeList的自由链表数组。
//强转存储 static void*& NextObj(void* obj) { return *(void**)obj; } class FreeList { private: void* _freeList; //普普通通的空类型指针 public: void Push(void* obj) //不用的内存块插入到链表中,头插 { assert(obj); NextObj(obj) = _freeList; _freeList = obj; } void* Pop()//线程要用内存块,有就头删一个。 { assert(_freeList); void* obj = _freeList; _freeList = NextObj(_freeList); return obj; } bool Empty() { return _freeList == nullptr; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
申请 与 释放内存
申请内存
- 当内存申请
size<=256KB,先获取到线程本地存储的thread cache对象,计算size映射的哈希桶自由链表下标i。 - 如果自由链表
_freeLists[i]中有对象,则直接Pop一个内存对象返回。 - 如果
_freeLists[i]中没有对象时,则批量从central cache中获取一定数量的对象,插入到自由链表并返回一个对象。
释放内存
- 当释放内存小于256 KB 时将内存释放回thread cache,计算size映射自由链表桶位置i,将对象Push到_freeLists[i]。
- 当链表的长度过长,则回收一部分内存对象到central cache。
thread cache代码框架:
项目开发中,一些大家常用的库会放在一个公共的头文件中,一些常用自定义的结构也会放在公共的头文件中。
#include"Common.h" //实现线程直接申请释放的线程内存池 class ThreadCache { public: //线程申请内存 void* Allocate(size_t size); //释放 void Deallocate(void* ptr, size_t size); private: FreeList _freeList[?]; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
哈希桶映射对齐规则
FreeList 每个桶下面挂多大的内存块以及用多少个桶呢?
每个字节大小都映射一个位置?不太科学。每个桶下起码得有8个字节(64为平台下)存储下一个内存块儿的地址,那么是否就按8个字节为单位的等差数列映射呢?
_freeList[0] = 8byte,_freeList[1] = 16byte;...._freeList[32768] = 256* 1024byte,也还是不太行。因此有前辈高手相出了下面的解决方案:不同的区域,采用不同大小内存块(对齐数),作等差数列。
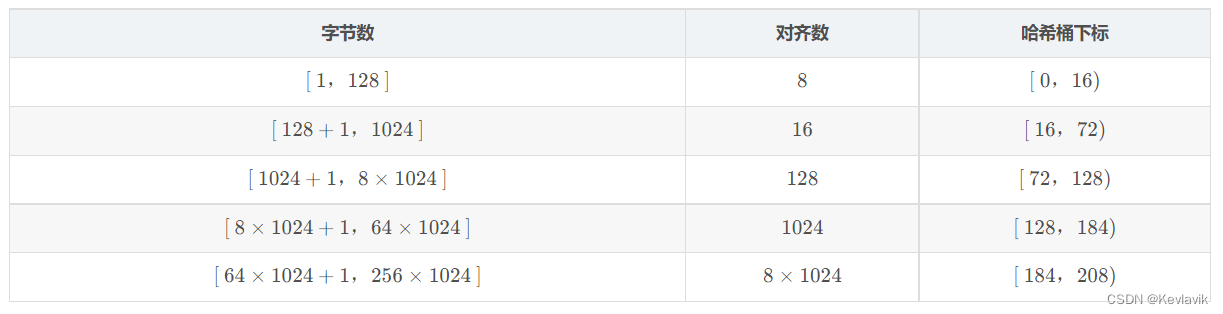
此刻还可以计算空间浪费率,虽然对齐产生的内碎片会引起一定程度的空间浪费,但按照上面的对齐规则,我们可以将浪费率控制到百分之十左右。1–128这个区间不做讨论,比如129~1024这个区间,该区域的对齐数是16,那么最大浪费的字节数就是15,这15个字节就是内碎片;假如申请130个字节,则分配144个字节的内存块, 15 / 144 ≈ 10.42 15/144\approx10.42 15/144≈10.42%。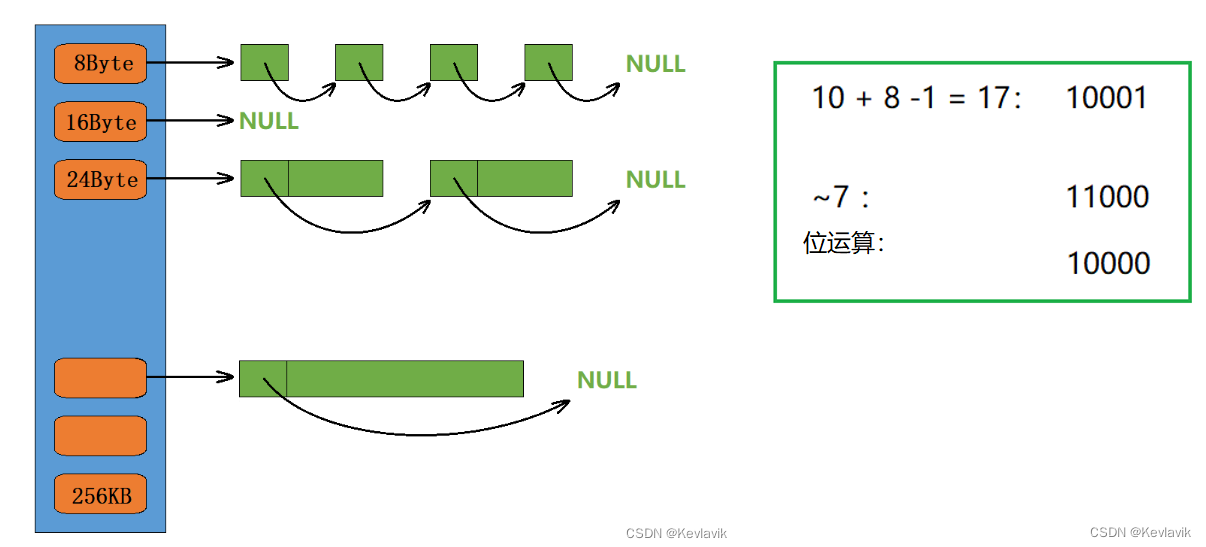
- 上面还可以得出,用208个桶。
- 每个桶的内存块大小定好了,那么如何通过线程要申请的内存块找到数组的下标呢?
- 这时就可以把获取对齐内存块和获取下标封装成一个类:
- 计算对齐内存块及其下标。
- 内存块要看在哪个区间,且向上对齐;如要9个byte,也要给16个byte。下列注释的子函数为普通写法,用的则是高手前辈的位运算写法,效率更快。
class AlignIndex { public: // 10 / 8 16 /*size_t _AlignUp(size_t sz,size_t alignSz) { size_t retSize; if (sz % alignSz != 0) { retSize = (sz / alignSz + 1) * alignSz; } else { retSize = sz; } return retSize; }*/ static inline size_t _AlignUp(size_t bytes, size_t alignSz) { return ((bytes + alignSz - 1) & ~(alignSz - 1));//位运算效率更高 } static inline size_t AlignUp(size_t size) { if (size <= 128) { return _AlignUp(size, 8); //每个区间采取的对齐数 } else if (size<=1024) { return _AlignUp(size, 16); } else if (size <= 8 * 1024) { return _AlignUp(size, 128); } else if (size <= 64 * 1024) { return _AlignUp(size, 1024); } else if (size <= 256 * 1024) { return _AlignUp(size, 8*1024); } else { assert(false); return -1; } } /*static inline size_t _Index(size_t bytes, size_t align_shift)//8,16,128,1024... { if (bytes % align_shift == 0) { return bytes / align_shift - 1; } else { return bytes / align_shift; } }*/ static inline size_t _Index(size_t bytes, size_t align_shift) { return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1; } //获取内存块所处的下标 static inline size_t Index(size_t bytes) { assert(bytes <= MAX_BYTES); static int rangei[4] = { 16,56, 56, 56 }; if (bytes<=128) { return _Index(bytes, 3); } else- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
-
相关阅读:
WebRTC QoS方法之Pacer实现
vue状态管理工具
DGIOT国内首家轻量级物联网开源平台——真实ModbusRTU接入实战教程
rpy2: Unable to determine R library path:
LAYUI-FROM
Python Day9 字符串进阶【零基础】
【数据结构】基本概念和术语
向量空间-向量基、坐标转换
Distribution (mathematics)
基于单片机的室内空气质量监控系统设计
- 原文地址:https://blog.csdn.net/WTFamer/article/details/127313517
