-
我们写的代码是如何一步步变成可执行程序(.EXE)的?
这篇文章,我们来探讨一下,我们写的代码,是如何一步步变成可执行程序,最终运行得出结果的,一起来学习吧!!!
1. 程序的翻译环境和执行环境
在ANSI C(美国国家标准协会(ANSI)及国际标准化组织(ISO)推出的关于C语言的标准)的任何一种实现中,程序都存在两个不同的环境。
第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。
第2种是执行环境,用于实际代码执行。也就是说:
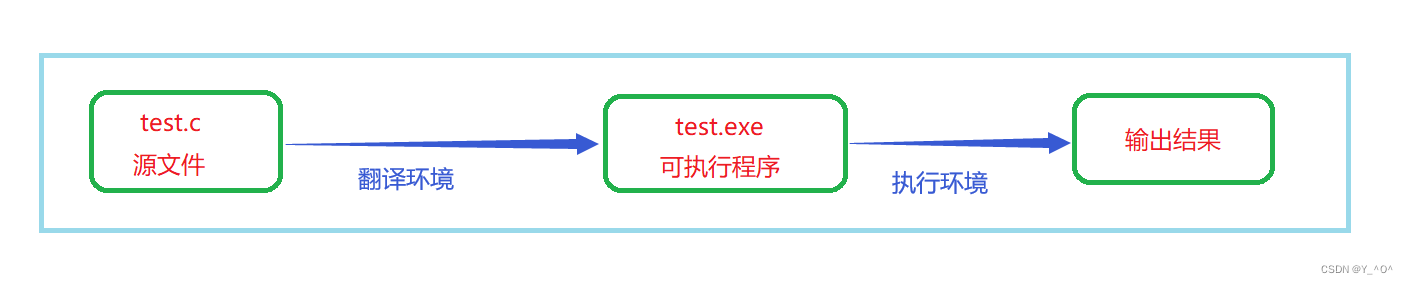
我们写好的任何一个源代码,到最终产生结果,都要经历这两个环境。
比如,我们写好了一个test.c的源文件,它需要先经过翻译环境生成可执行程序test.exe,然后再经过执行环境产生最终的结果。
2. 翻译环境详解
2.1翻译环境介绍
对于翻译环境呢,又分为编译和链接

1. 有时候我们的一个程序可能不止一个源文件,组成一个程序的每个源文件通过编译过程分别转换成目标代码(object code)。
2. 每个目标文件由链接器(linker)捆绑在一起,形成一个单一而完整的可执行程序。
3. 链接器同时也会引入标准C函数库中任何被该程序所用到的函数,而且它可以搜索程序员个人的程序库,将其需要的函数也链接到程序中,最终生成可执行程序。那下面我们就在
vs2022写一个代码,让大家粗略的感受一下编译和链接的这个过程:
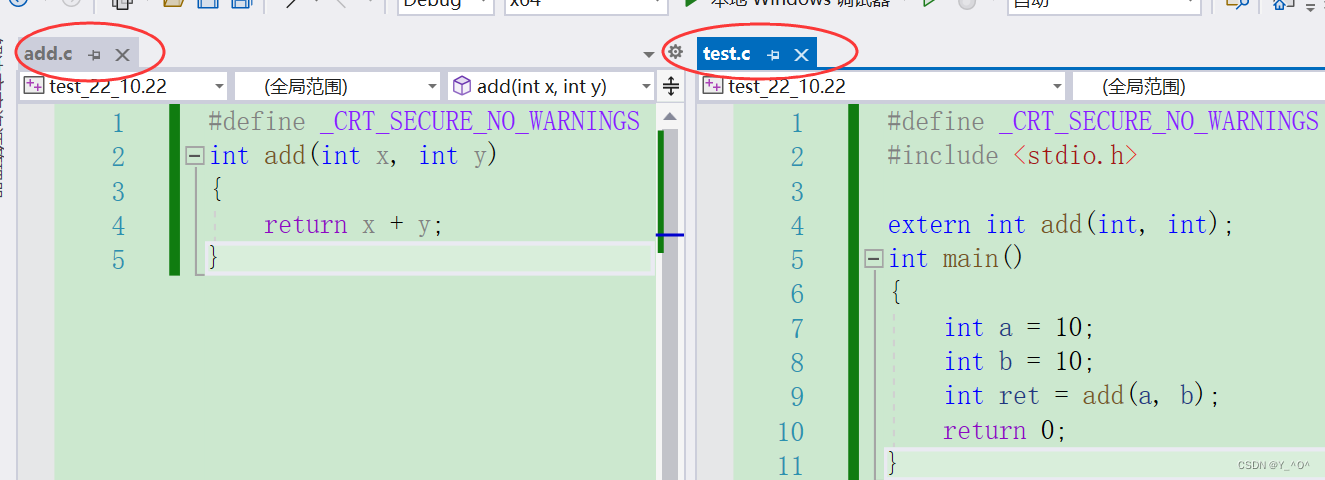
看这个程序,包含了两个源文件。那我们现在
vs上对该程序生成解决方案:
然后我们进入到文件所在路径进行观察:

我们发现,经过编译过程,test.c和add.c已经生成了对应的目标文件。然后:
链接器会把这些目标文件和链接库链接在一起,最终生成可执行程序。
那因为在test.c中使用了add.c中的add函数,所以这两个源文件要被链接在一起,这我们能想通。
那还有一个链接库,这是个什么鬼?
大家有没有注意到我们刚才的程序中还使用到了一个库函数——printf,像这些我们调用到的标准C函数库中的函数,就是放在链接库中的,链接器也会引入标准C函数库中这些被程序所用到的函数。刚刚在上面的过程中我们提到了编译器和链接器这两个东西。
而对于我们平时写代码使用的这些工具,就比如我现在使用的这个
vs2022,它其实不单单有编译和链接的功能,我们平时用的这些工具,它们都是一个集成开发环境(IDE),像常见的有Visual Studio、Dev C++、Xcode、Visual C++ 6.0、C-Free、Code::Blocks等。集成开发环境就是一系列开发工具的组合套装,比如编辑器,编译器,链接器,调式器等。
我们可以在上面编辑代码,编译和链接代码,以及调式代码等。
这个大家了解一下。2.2 编译详解
对于编译本身,又可以划分为3个阶段:预编译(预处理)、编译、汇编。
下面我们一起来看一下:
就还看上面那段代码,首先,大概的过程是这样的:
紧接着我们就来分析一下其中的细节:
注:接下来的大部分演示将在Linux环境下利用
gcc进行,因为vs上面有些东西我们不好观察,所有有些操作大家不必关心,只要明白我们在干什么就行了。当然这里面用到的一些命令大家可以了解一下:
- 预处理 选项 gcc -E test.c -o test.i
预处理完成之后就停下来,预处理之后产生的结果都放在test.i文件中。 - 编译 选项 gcc -S test.c
编译完成之后就停下来,结果保存在test.s中。 - 汇编 gcc -c test.c
汇编完成之后就停下来,结果保存在test.o中。
然后我们写这样一段代码:
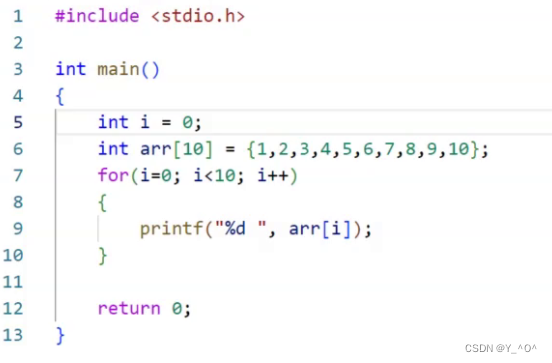
我们接下来对我们写的源文件
test.c直接编译,然后生成了一个a.out的可执行程序,运行,我们看到成功打印了1到10的数字
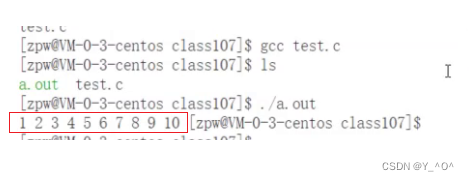
但是我们刚刚直接完成了整个编译过程,并没有观察到其中的具体细节。
2.2.1 预处理(预编译)
下面我们就分别观察一下其中的细节:
首先我们利用gcc -E test.c -o test.i让程序在预编译(预处理)之后停下来,并把内容输出到test.i文件中:
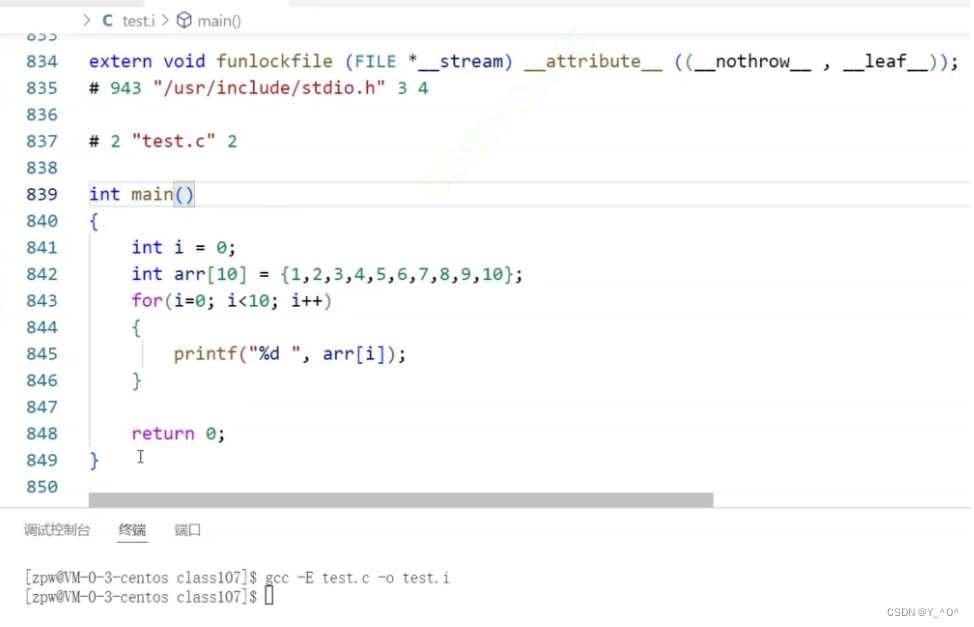
我们看到里面有很多内容,八百多行,但里面包含了我们写的代码。那为什么多了这么多内容呢?
大家有没有注意到我们在代码的第一行就包含了一个头文件
stdio.h,那test.i中八百多行的内容中,在我们写的代码之前的那一大部分的内容是不是都是头文件带进来的内容。
是的,预编译之后的test.i中前面的那么多内容都是来自头文件stdio.h的内容。
我们可以验证一下,我们就打开一下stdio.h看看它里面的内容(具体操作大家不必关心):
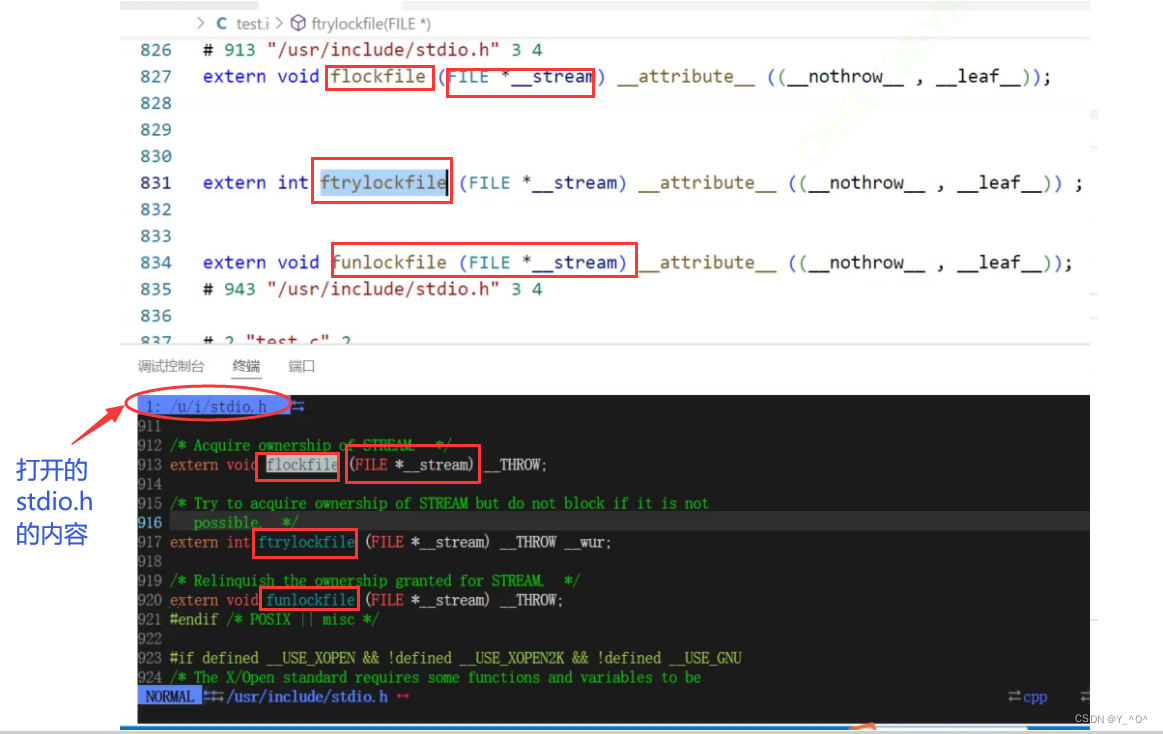
我们能够看到它们里面的有些内容是完全一样的。那从这里我们就能够得出一个结论:
在预编译阶段需要做的事情之一是头文件的包含这件事。
那我们继续探讨一下,预处理阶段还会做其它哪些事情呢?
我们现在对刚才的代码做一些修改:
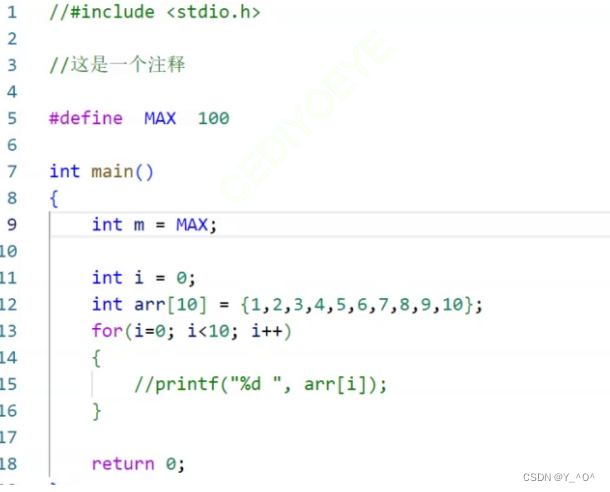
我们现在不打印数组的元素了,那自然stdio.h我们也不用包含了,然后我们又添加了一行注释,并用#define定义了一个标识符,赋给了变量m。
然后我们再把预处理后的内容写到test.i文件中,一起来看一下:
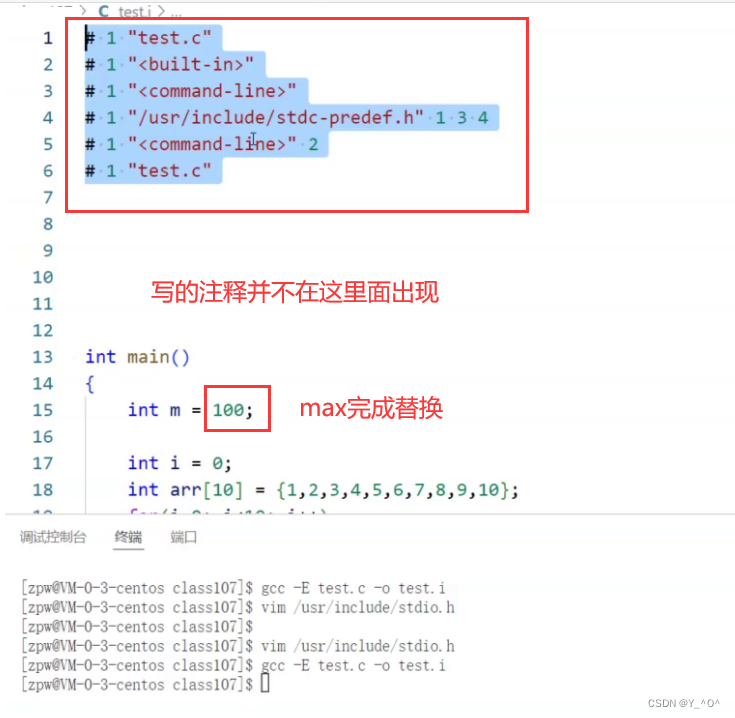
这次我们再来看,前面就没有那一大堆#include带进来的东西了。因为这次我们把头文件的包含注释掉了。
而且我们注释掉的代码和自己写的注释也没有出现在test.i中。
另外,我们定义的标识符#define MAX 100,也没有,而是直接将MAX替换成了100。所以,我们就知道,在预编译阶段还做了:
注释的删除
#define定义的符号的替换
当然,肯定还不止这些事情,我们现在只是大致了解一下,下一篇文章我们会给大家详细介绍预处理。2.2.2 编译
那我们接下来就来研究一下编译阶段会发生什么?
还是这段代码:
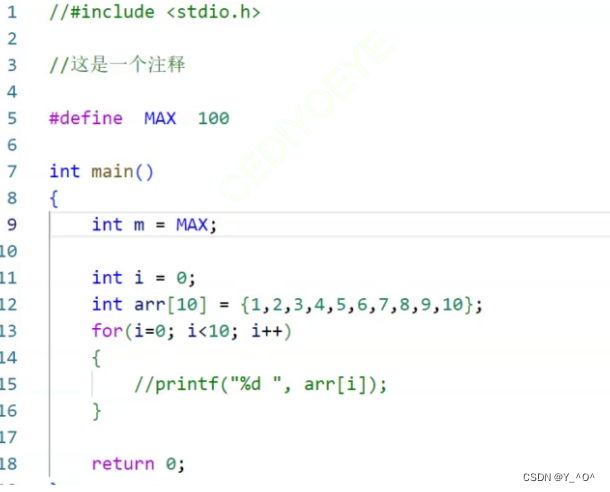
我们这次让它在编译之后停下来,然后我们来观察:
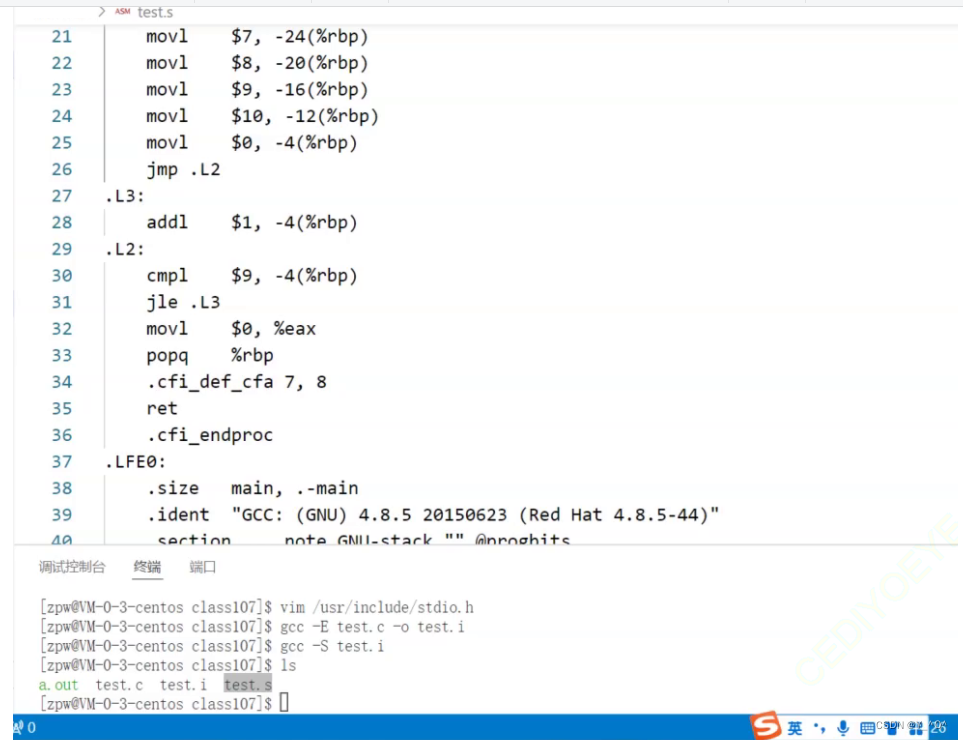
这时编译之后的内容,如果大家之前在自己的编译器上查看过汇编代码的话,会发现这和汇编代码非常像,其实这就是产生的汇编代码。
所以,在编译过程中,会把预处理之后的C语言代码转换成汇编代码。那在转换的过程中,又会做什么呢?
1.语法分析
2.词法分析
3.语义分析
4.符号汇总
那这几步又是干什么呢?
大家如果不知道也没关系,不重要,不过这里我们需要去了解一下符号汇总。那接下来,我们就了解一下符号汇总
我们再来写这样一段代码:
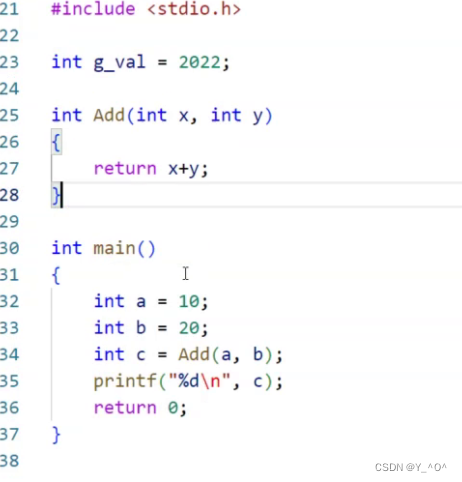
我们知道这段代码在完成整个编译过程之后,就会产生对应的可执行程序(a.out)。
而这个可执行程序是按照一定的文件格式来进行组织的,这个格式叫做elf,a.out文件的内部呢,按照这个格式会划分成一个一个的段,分别存放不同内容的数据,其中有一个叫做符号表的东西。那我们怎么查看a.out这个文件呢?
我们去直接打开的话是不行的:

不过我们可以使用vim编辑器打开它,但是我们也看不懂:
因为a.out其实是个二进制的文件,不过我们可以借助readelf来查看。
我们可以利用相关命令只看符号表的内容:
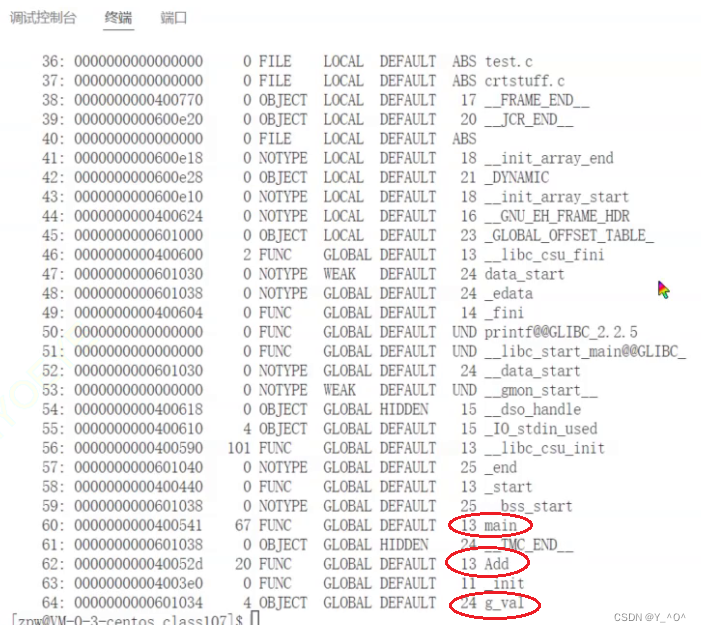
我们发现,从中能找到一些我们在代码中定义的符号,我们定义的全局变量g_val,还有main函数和Add函数的函数名。
但是我们定义的一些局部变量a,b,c好像并没有在里面找到。所以:
符号汇总其实就会把我们程序中的这些全局变量,函数名这种符号给汇总起来。
那这其实就是符号汇总的一个作用,为什么要单独解释一下符号汇总呢?
因为在链接的部分我们需要用到这些知识。2.2.3 汇编
那接下来就是汇编了,编译的最后一步。
那经过汇编之后,编译结束,是不是就产生对应的目标文件了呢 ?
是的。那我们现在执行相关的命令让它在汇编之后停止:
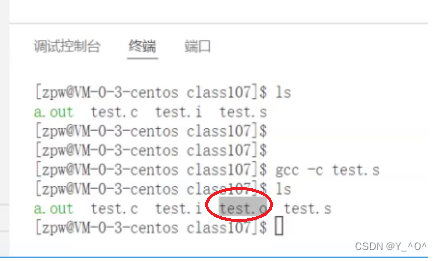
我们发现汇编之后又多了一个文件test.o,这个文件其实就是生成的目标文件。

而它,是一个二进制文件。
而机器指令就是二进制的。所以:
汇编这一步做的其实就是把汇编指令转化为二进制的机器指令。
而生成的目标文件
test.o其实也是elf格式的,我们打开她也能看到相关的符号: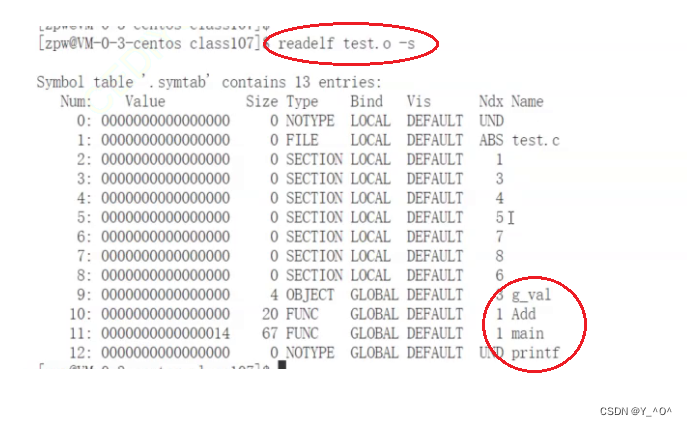
所以,除了把汇编指令转化为二进制的机器指令,这一步还会做什么呢?
就是把上一步汇总的符号形成符号表。2.3 链接详解
通过上面的学习,我们知道,整个编译过程完成后,会产生目标文件,然后链接器就要对这样目标文件进行链接了。
那链接过程又会发生什么呢?
链接过程是将多个目标文件(可重定位目标文件)以及库文件组合在一起,生成最终的可执行文件。主要过程有:
1. 合并段表
2. 符号表的合并和重定位
当然肯定不止这些,比如上面我们提到链接器会引入标准C函数库中任何被该程序所用到的函数,而且它可以搜索程序员个人的程序库,将其需要的函数也链接到程序中,最终生成可执行程序等,这里我们重点介绍这两个。2.3.1 合并段表
那什么是合并段表呢?
我们上面提到过生成的目标文件
test.o其实也是elf格式的,而按照这个格式呢,会把文件分成一个一个的段,分别用来存放表示不同用途的数据。那就拿我们最开始在vs上写的那个代码来说:
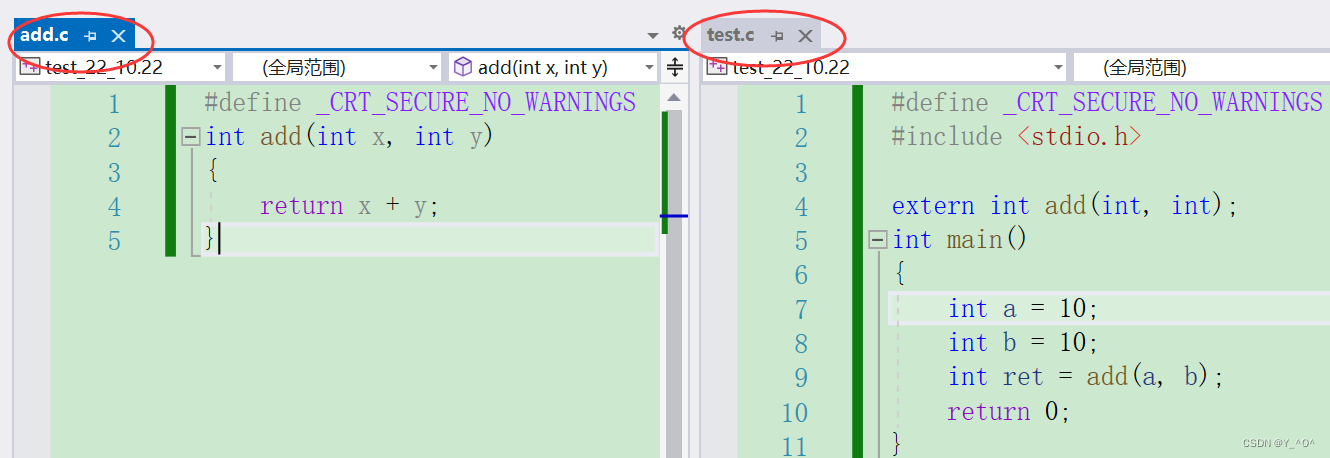
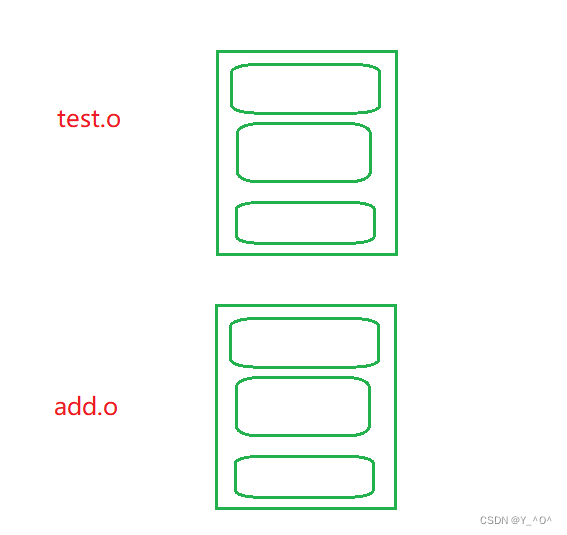
两个.c的源文件test.c和add,c,那编译之后就生成两个目标文件test.o和add.o,它们都是elf格式的文件,按同样的方式划分。
而最终链接之后生成的可执行文件是不是也是elf格式的啊,那这个时候,它们就会把这些相同段的内容都放在一起,最终生成一个可执行程序:
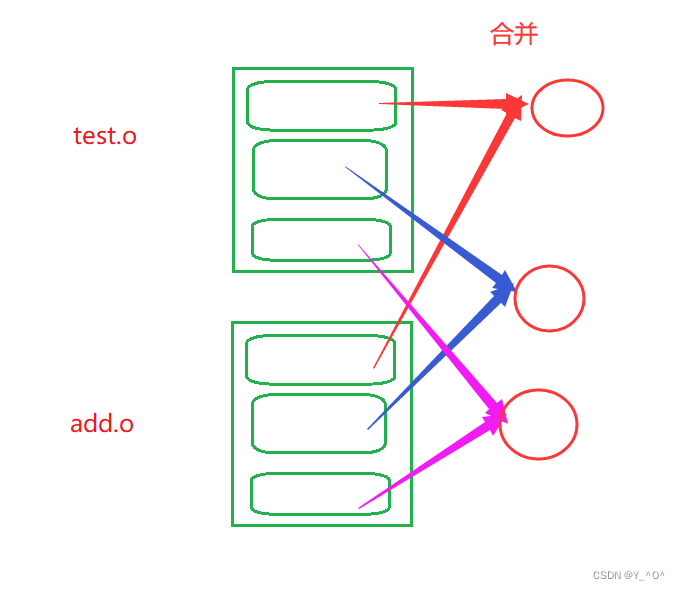
这就是合并段表。2.3.2 符号表的合并和重定位
那符号表的合并和重定位又是什么呢?
我们已经知道了在汇编阶段会生成符号表,这些符号往往是一些全局变量,函数名等和它们对应地址的映射。
我们还来看这段代码:
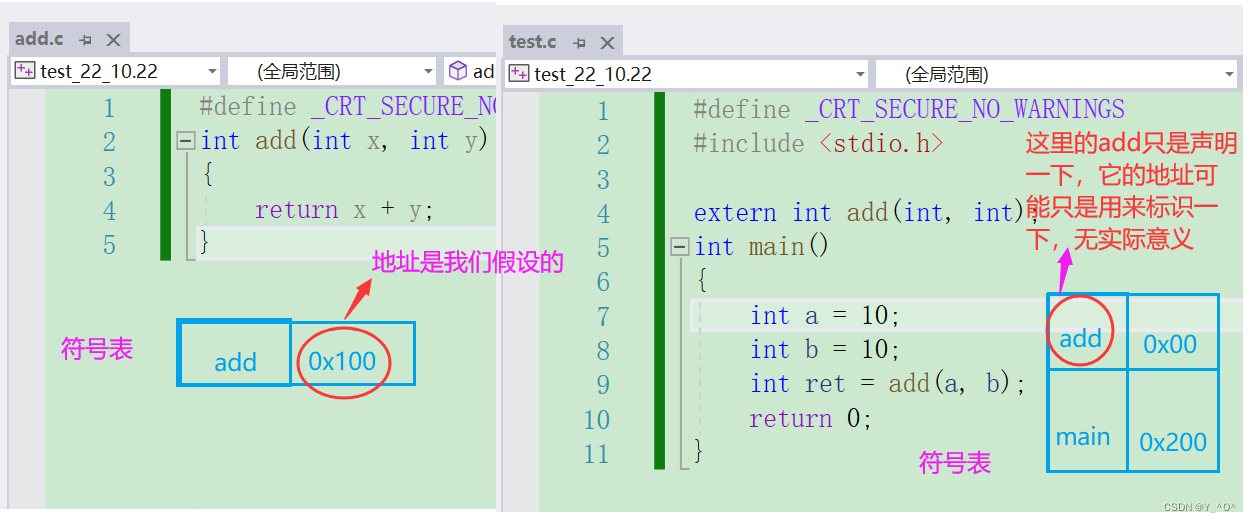
那这两个文件最后要生成一个可执行文件呀,所以就需要对它们的符号表进行合并。
那合并的时候就会有一个问题,两个文件中都有一个
add符号,地址应该选哪一个呢?
选add.c中的,为什么?
因为函数add.c在test.c中只是声明了一下,而真正的函数add的实现是在add.c中的,所以,最终要选择add.c中函数add的地址作为最终add的地址:
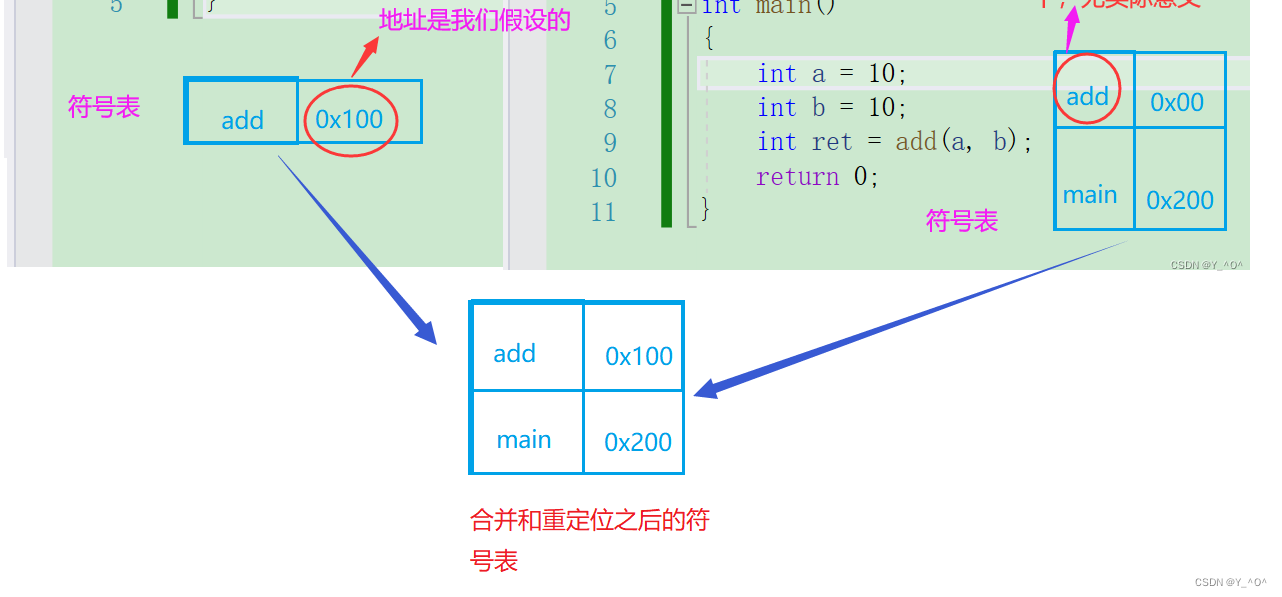
这就是符号表的合并和重定位。那这些东西有什么用处呢?
当链接过程中进行了符号表的合并和重定位之后,
test.c中main函数调用add的时候是不是就能通过符号表中重定位之后的有效的函数地址找到add函数并调用它。
当然如果add.c中没有定义add函数,或者函数名我们写错的情况下,是不是也会因为符号表中没有有效的信息而报错。
我们可以验证一下,相信大家也遇到过这种情况:

如果调用时函数名写错呢?
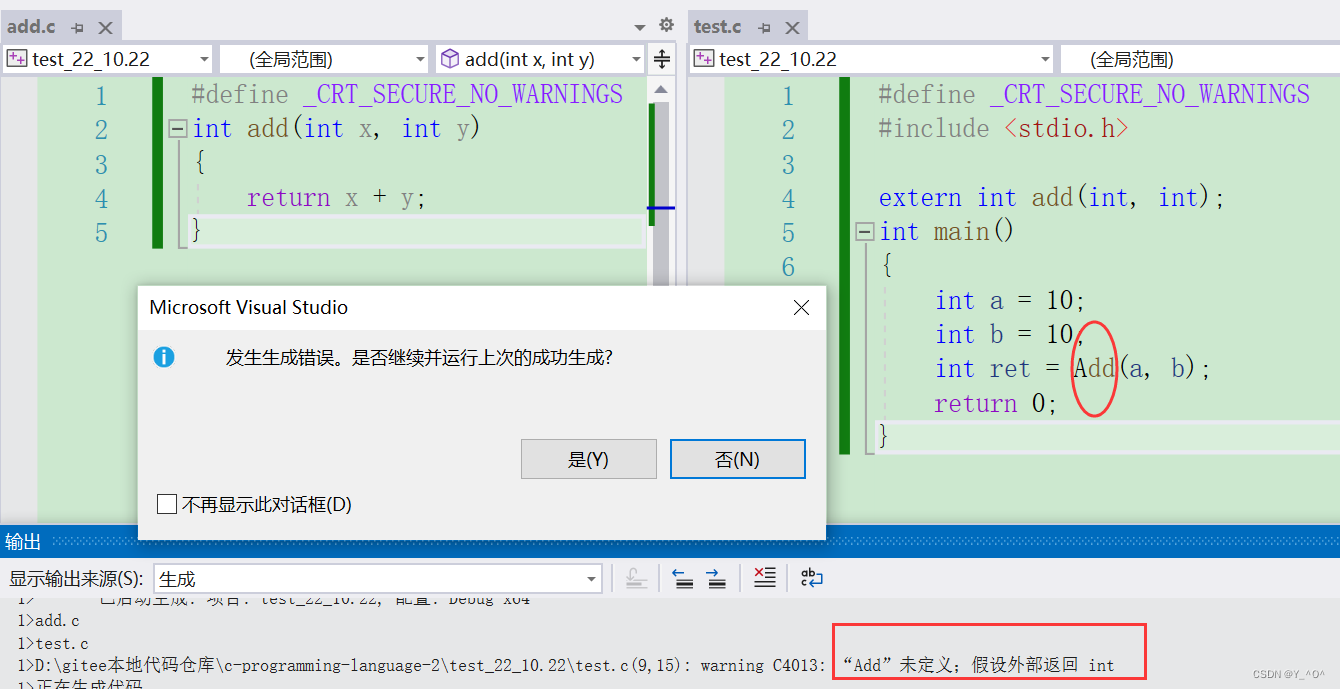
这就体现了符号表的用处。3. 运行环境
最后,我们来了解一下一个程序执行的过程:
- 程序必须载入内存中。在有操作系统的环境中:这个过程一般由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
- 程序的执行便开始。接着便调用main函数。
- 开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留他们的值。
- 终止程序。正常终止main函数;也有可能是意外终止。
这篇文章,我们比较笼统的介绍了一个程序从编译到链接,再到最后执行的过程,下一篇文章,我们将详细的介绍一下预处理过程。
这篇文章就到这里,希望能帮助到大家,也欢迎大家指正!!!

- 预处理 选项 gcc -E test.c -o test.i
-
相关阅读:
FPGA project : beep
2022大湾区杯奥港金融数学建模竞赛思路及代码
net mvc中使用vue自定义组件遇到的坑
Unity - 2D物理系统
4G/5G卡使用 EC200-CN
【校招VIP】计算机网络之TCP/IP模型归纳
多线程编程(1) - 先入门
不知道PPT转PDF简单方法有哪些?三个方法让你知道PPT转PDF怎么转
【uniapp】uniapp的安卓apk图标角标设置消息数量
ADC噪声全面分析 -02- ADC 噪声测量方法和相关参数
- 原文地址:https://blog.csdn.net/m0_70980326/article/details/127457749