-
Sharding-JDBC实现读写分离
前言
快一个月没有更新文章了,太忙了太忙了,虽然慢了一点,但是我肯定不会断更。上一篇文章是《Mysql主从复制》,光是数据库层面的主从复制可不行,应用层面也是需要读写分离的,所以接上一篇文章我们来讲如何通过Sharding-JDBC实现应用读写分离
认识Sharding-sphere
遇到了什么问题
上一篇文章我们只是解决了数据库层面的主从复制,那么应用层面也需要做处理,就是把写操作打到主库,把读操作打到 从库,也就实现了读写分离了,如下图

那么如何才能够将业务中的读写请求路由到不同的读写库呢?想起刚出道那几年,我为了处理这个问题,自己基于SpringJDBC提供的AbstractRoutingDataSource,使用AOP+ThreadLocal技术自己封装到一套框架来实现读写分离,后来发现业界有更好的的框架已经解决了这个问题,如今能够实现读写分离的组件挺多,业界比较热门的介绍两款:MyCat , Sharding-sphere,今天主要是介绍如何使用Sharding-sphere来实现读写分离。Sharding-sphere是啥
官网:http://shardingsphere.apache.org/index_zh.html
什么是 Apache ShardingSphere?
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。这句话看起来好像没有那么好理解,总之就是可以实现读写分离,数据库分片(分库分表),分布式事务支持等,也支持云原生。下图是它具备的能力,看起来很强大

这里还有一段对它的解释:Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。 它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
我们可以认为Sharding-sphere是一个关系型数据的分布式中间件。有三个部分组成,sharding-jdbc(JAVA),sharding-proxy(异构系统),Sharding-Sidecar(云原生)。

-
ShardingJDBC :sharding-jdbc 是一个开源的适用于微服务的分布式数据访问基础类库(jar),它始终以云原生的基础开发套件为目标。只支持java语言。sharding-jdbc完整的实现了分库分表/读写分离/分布式主键功能,并实现了柔性事务

-
ShardingProxy :定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持,也就是支持多做开发语言的异构系统
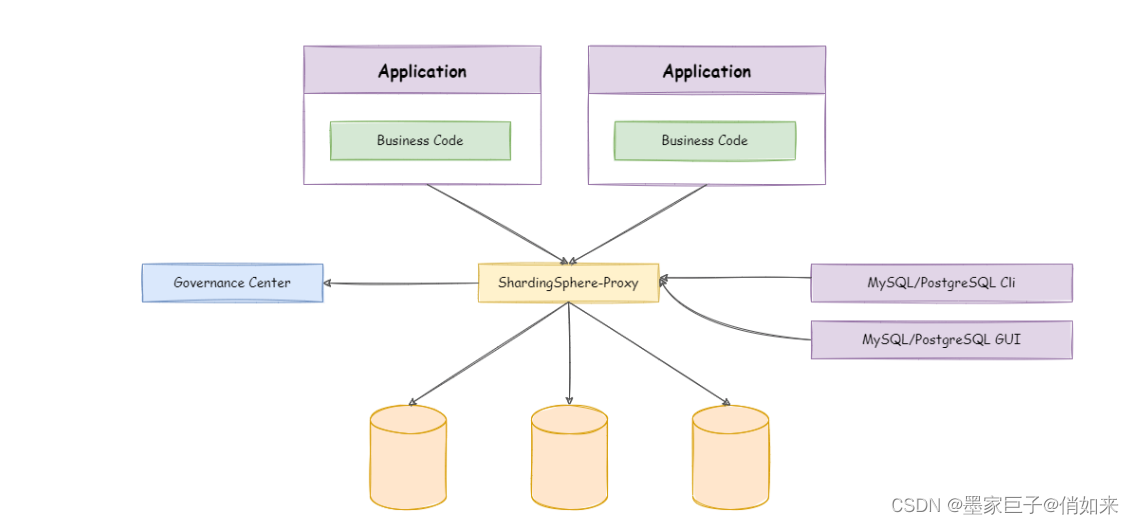
-
Sharding-Sidecar :定位为Kubernetes(k8s)或Mesos的云原生数据库代理,以DaemonSet的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的的啮合层,即Database Mesh,又可称数据网格。
ShardingJDBC入门
文档:https://shardingsphere.apache.org/document/4.1.1/cn/manual/sharding-jdbc/usage/read-write-splitting/#%E5%9F%BA%E4%BA%8Espring-boot%E7%9A%84%E8%A7%84%E5%88%99%E9%85%8D%E7%BD%AE ;最新版本是5.x,我这里使用的是4.x来演示,如果想要使用最新版本,自己可以参考官方文档。
上面说到,ShardingJDBC是针对Java应用实现读写分离,或者分库分表支持,要使用他首先需要导入依赖,这里以SpringBoot 2.2.x版本作为演示
第一步:除了SpringBoot依赖之外,还需要导入sharding-jdbc依赖
<dependency> <groupId>org.apache.shardingspheregroupId> <artifactId>sharding-core-apiartifactId> <version>4.1.1version> dependency> <dependency> <groupId>org.apache.shardingspheregroupId> <artifactId>sharding-jdbc-spring-boot-starterartifactId> <version>4.1.1version> <exclusions> <exclusion> <groupId>com.google.guavagroupId> <artifactId>guavaartifactId> exclusion> exclusions> dependency> <dependency> <groupId>com.alibabagroupId> <artifactId>druidartifactId> <version>1.1.9version> dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
解释:这里我排除了guava,会和SpringCloud中的guava包冲突 ,如果你没有出现依赖冲突可以不用排除,另外 这里使用了druid的连接池
第二步:配置读写分离
创建一个application.properties 配置文件,我有一个master和一个slave,所以加入内容:
#主,从数据库的名字,如果有更多的从,在后面继续加就可以 spring.shardingsphere.datasource.names=master,slave0 #主数据的链接信息 spring.shardingsphere.datasource.master.type=com.alibaba.druid.pool.DruidDataSource #spring.shardingsphere.datasource.master.type=org.apache.commons.dbcp2.BasicDataSource spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.master.url=jdbc:mysql://localhost:3306/itsource-student spring.shardingsphere.datasource.master.username=root spring.shardingsphere.datasource.master.password=密码 #从数据库的链接 信息,如果有更多的从,在后面继续加就可以 spring.shardingsphere.datasource.slave0.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.slave0.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.slave0.url=jdbc:mysql://localhost:3307/itsource-student spring.shardingsphere.datasource.slave0.username=root spring.shardingsphere.datasource.slave0.password=密码 #从数据库的负载均衡 spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin #集群名字 spring.shardingsphere.masterslave.name=ms #主数据库名字,对应第一行的配置 spring.shardingsphere.masterslave.master-data-source-name=master #多个从数据名字,逗号分隔 spring.shardingsphere.masterslave.slave-data-source-names=slave0 #是否打印sql spring.shardingsphere.props.sql.show=true- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
这里就配置好了,ShardingJDBC会根据执行的是查询操作,或者增删改操作,然后自动选择配置中的主,从数据库。
第三部:启动测试
启动的时候就可以看到控制台日志:
16:32:55.914 [restartedMain] INFO 。。.ConfigurationLogger - [log,104] .. loadBalanceAlgorithmType: round_robin masterDataSourceName: master name: ms slaveDataSourceNames: - slave0- 1
- 2
- 3
- 4
- 5
- 6
当执行查询的时候可以从日志中看出是走的 slave0 ,而执行增删改的时候会走master。
16:36:21.140 [restartedMain] INFO ShardingSphere-SQL - [log,74] - Actual SQL: slave0 ::: select ...- 1
- 2
强制走主库
主从复制会出现一个问题,数据在主插入,读却是从从库读取,这个之间可能存在一定延迟,导致数据不一致,所以在实时性要求比较高的数据一般会强制要求走主库查询,我们可以做这样的设置
HintManager.clear(); try (HintManager hintManager = HintManager.getInstance()) { //设置走主库 hintManager.setMasterRouteOnly(); return xxMapper.selectList(); }- 1
- 2
- 3
- 4
- 5
- 6
然后测试观察控制台,看得出查询是走了主库 master 了
16:45:32.320 [http-nio-8080-exec-9] INFO ShardingSphere-SQL - [log,74] - Actual SQL: master ::: select ...- 1
- 2
当然这样比价麻烦,因为每次要走主库都要添加这一段代码,比较好的处理方式是使用AOP来解决。
第一步:定义注解
@Retention(RetentionPolicy.RUNTIME) @Target({ElementType.TYPE,ElementType.METHOD}) public @interface DataSourceMaster { }- 1
- 2
- 3
- 4
第二步:定义AOP切面,获取方法上的DataSourceMaster 来设置走主库
@Slf4j @Component @Aspect public class DataSourceMasterAop { @Around("execution(* cn.itsource.service.impl.*.*(..))") public Object master(ProceedingJoinPoint joinPoint){ Object[] args = joinPoint.getArgs(); Object ret = null; MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature(); Method method = methodSignature.getMethod(); DataSourceMaster shardingJdbcMaster = method.getAnnotation(DataSourceMaster.class); HintManager hintManager = null; try { if (Objects.nonNull(shardingJdbcMaster)) { HintManager.clear(); hintManager = HintManager.getInstance(); hintManager.setMasterRouteOnly(); } ret = joinPoint.proceed(args); }catch (Exception ex){ log.error("exception error",ex); }finally { if (Objects.nonNull(shardingJdbcMaster) && Objects.nonNull(hintManager)) { hintManager.close(); } } return ret; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
第三步:在方法上贴注解即可
@DataSourceMaster public List<Xxx> selectList(){ return XxxMapper.selectList(); }- 1
- 2
- 3
- 4
好了,文章就写到这里咯,喜欢的话请一定给个好评,你的肯定是我最大的动力哦~~~
-
-
相关阅读:
计算机网络知识点笔记(1)概述
maven私服搭建
Node介绍(nvm安装和npm常用命令)
R语言复现:中国Charls数据库一篇现况调查论文的缺失数据填补方法
PyTorch实战:实现Cifar10彩色图片分类
uniapp 修改引入组件样式 使用/deep/、::v-deep、>>>不生效 解决
任务调度框架 Quartz 一文读懂
JoySSL证书买二送一买三送二特别活动
第 45 届国际大学生程序设计竞赛(ICPC)亚洲区域赛(银川),签到题5题
基于STM32+OneNet设计的GPS定位器(ESP8266)
- 原文地址:https://blog.csdn.net/u014494148/article/details/127462721
