本文示例代码已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
大家好我是费老师,在诸如网络爬虫、web应用开发等场景中,我们需要利用Python完成大量的url解析、生成等操作。
而在Python生态中,无论是使用诸如urllib之类的标准库,还是各种第三方库,可以用来有效处理url的方法都非常之丰富。而今天费老师我要给大家介绍的url处理库,则是我在实际使用中综合考虑简单易用性与运算速度后,最为满意的😋。

2 在Python中利用yarl高效处理url
这个可以用来高效便捷处理url的第三方库叫做yarl,使用pip install yarl完成安装后,下面我们来快速学习其主要的一些功能方法:
2.1 利用yarl解析url信息#
基于yarl中的URL(),我们可以从任意合法的url中解析出下图所示的各个构成部分:

先来看一个简单的例子,其中对我保管每一篇博客文章附件的github仓库路径url进行解析:
from yarl import URL
url = URL('https://github.com/CNFeffery/DataScienceStudyNotes/tree/master/%E5%8E%86%E5%8F%B2%E6%96%87%E7%AB%A0%E9%99%84%E4%BB%B6%E5%88%97%E8%A1%A8')
原始的网址由于包含了中文等非ASCII字符,所以粘贴到代码中后变成了url编码后的样子,直接调用human_repr()方法即可进行解码还原:
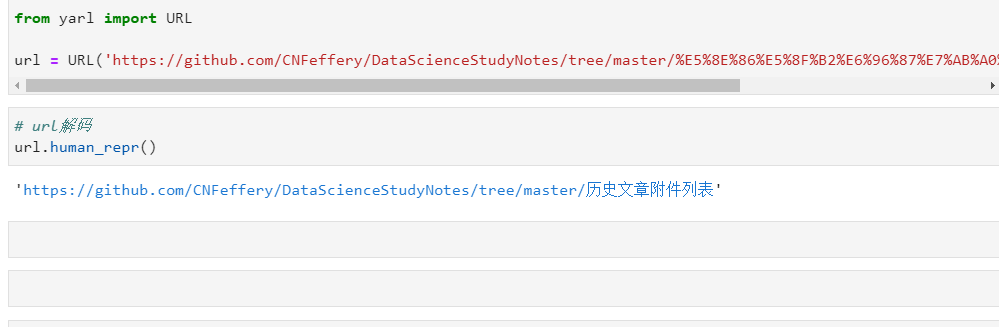
而通过获取对应url各部分名称的属性,即可分别提取出相应信息:

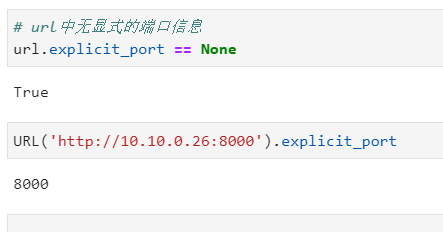
其中端口信息是基于scheme信息按照常规情况进行推断的,http即为80,https即为443,若需要获取url中显式出现的端口信息,可以使用explicit_port:
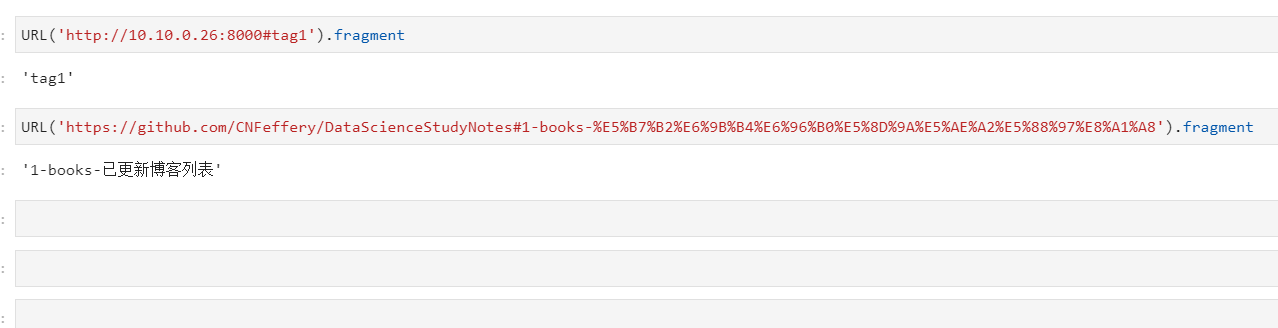
针对url中的hash标签信息则可以通过fragment取得:
若要解析的url中包含query参数信息,则可以直接调用query得到MultiDict类型的返回结果,这是种特殊的字典类型,它允许存在重复的键,对于不存在重复的键值对,可以像普通字典那样索引值,否则则需要通过getall()方法来返回所传入键对应的所有值列表:

可以感受到通过yarl解析url非常的方便~
2.2 利用yarl构造url#
当我们需要基于已有的各部分信息构造url时,yarl就更加方便了,基础的方式是基于URL.build()方法,以函数传参的方式定义url:

而如果你已经有了具体存在的yarl.URL对象,想在此基础上进行其他部分内容的设置,则可以使用一系列名称格式为with_xxx()的方法,其中xxx就对应着各个部分的名称:
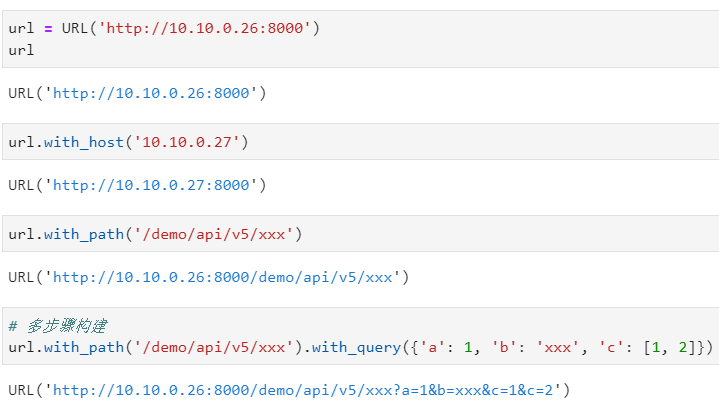
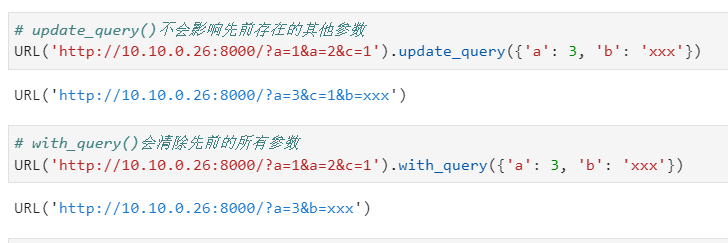
特别地,针对查询参数部分,还专门有update_query()方法进行参数追加,它与with_query()的区别可以从下面的例子中体会到:
2.3 利用/、%运算符快捷合成url#
在yarl中,针对/、%运算符进行了重写,以支持类似下面例子的快捷操作,非常的方便:

除了上面介绍的yarl常用功能以外,还有譬如利用is_absolute()方法判断url是否为绝对路径等其他实用功能,感兴趣的读者朋友们可以前往官方文档了解更多(https://yarl.aio-libs.org/en/latest/index.html)。
以上就是本文的全部内容,欢迎在评论区与我进行讨论~