-
数据库——创建和管理表
目录
1.1 一条数据存储的过程
-
存储数据是处理数据的第一步 。只有正确地把数据存储起来,我们才能进行有效的处理和分析。否则,只能是一团乱麻,无从下手。那么,怎样才能把用户各种经营相关的、纷繁复杂的数据,有序、高效地存储起来呢? 在 MySQL 中,一个完整的数据存储过程总共有 4 步,分别是创建数据库、确认字段、创建数据表、插入数据。
 我们要先创建一个数据库,而不是直接创建数据表呢?因为从系统架构的层次上看, MySQL 数据库系统从大到小依次是 数据库服务器 、 数据库 、 数据表 、数据表的 行与列 。
我们要先创建一个数据库,而不是直接创建数据表呢?因为从系统架构的层次上看, MySQL 数据库系统从大到小依次是 数据库服务器 、 数据库 、 数据表 、数据表的 行与列 。1.2 标识符命名规则
- 数据库名、表名不得超过30个字符,变量名限制为29个
-
数据库名、表名不得超过 30 个字符,变量名限制为 29 个
-
数据库名、表名、字段名等对象名中间不要包含空格
- 同一个MySQL软件中,数据库不能同名;同一个库中,表不能重名;同一个表中,字段不能重名
-
必须保证你的字段没有和保留字、数据库系统或常用方法冲突。如果坚持使用,请在 SQL 语句中使 用` (着重号)引起来
-
保持字段名和类型的一致性:在命名字段并为其指定数据类型的时候一定要保证一致性,假如数据 类型在一个表里是整数,那在另一个表里可就别变成字符型了
1.3 MySQL中的数据类型

其中,常用的几类类型介绍如下:

2. 创建和管理数据库
- 方式1:创建数据库
CREATE DATABASE 数据库名;
- 方式2:创建数据库并指定字符集
CREATE DATABASE 数据库名 CHARACTER SET 字符集;
- 方式3:判断数据库是否已经存在,不存在则创建数据库( 推荐 )
CREATE DATABASE IF NOT EXISTS 数据库名;
最好也加上字符集
CREATE DATABASE IF NOT EXISTS 数据库名 CHARACTER SET 字符集;( 推荐 )
字符集:utf8---gbk
- 如果MySQL中已经存在相关的数据库,则忽略创建语句,不再创建数据库。
-
注意:DATABASE 不能改名。一些可视化工具可以改名,它是建新库,把所有表复制到新库,再删 旧库完成的。
#1-2管理数据库
#查看当前连接中的数据库都有哪些:
SHOW DATABASES;2.2 使用数据库
- 查看当前所有的数据库
SHOW DATABASES; #有一个S,代表多个数据库
- 查看当前正在使用的数据库
SELECT DATABASE(); #使用的一个 mysql 中的全局函数
- 查看指定库下所有的表
SHOW TABLES FROM 数据库名;
- 查看数据库的创建信息
SHOW CREATE DATABASE 数据库名 ;或者:SHOW CREATE DATABASE 数据库名 \G- 使用/切换数据库
USE 数据库名;
- 注意:要操作表格和数据之前必须先说明是对哪个数据库进行操作,否则就要对所有对象加上“数 据库名.”。
2.3 修改数据库
- 更改数据库字符集
ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
- #2.3修改数据库
- #更改数据库字符集
- #ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
- SHOW CREATE DATABASE dbtest;#CREATE DATABASE `dbtest` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */
- ALTER DATABASE dbtest CHARACTER SET 'gbk';
- SHOW CREATE DATABASE dbtest;#CREATE DATABASE `dbtest` /*!40100 DEFAULT CHARACTER SET gbk */ /*!80016 DEFAULT ENCRYPTION='N' */
#2.3修改数据库
#更改数据库字符集
#ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
SHOW CREATE DATABASE dbtest;#CREATE DATABASE `dbtest` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */ALTER DATABASE dbtest CHARACTER SET 'gbk';
SHOW CREATE DATABASE dbtest;#CREATE DATABASE `dbtest` /*!40100 DEFAULT CHARACTER SET gbk */ /*!80016 DEFAULT ENCRYPTION='N' */
2.4删除数据库
- 方式1:删除指定的数据库
DROP DATABASE 数据库名;
- 方式2:删除指定的数据库( 推荐 )
DROP DATABASE IF EXISTS 数据库名;
- #1.4删除数据库
- #方式一:
- DROP DATABASE dbtext01;
- #方式二:
- DROP DATABASE IF EXISTS dbtext01;
- #DDL数据定义语言:CREATE \ALTER\ DROP \RENAME \TRUNCATE
- #1. 创建和管理数据库
- #如何创建数据库?
- #方式一:
- CREATE DATABASE dbtest; #创建此数据库使用的是默认的字符集utf8mb4
- SHOW DATABASES;
- #方式二:CREATE DATABASE 数据库名 CHARACTER SET 字符集;
- # 显式了指明了要哦创建的数据库的字符集
- CREATE DATABASE dbtest CHARACTER SET 'gbk';
- #方式三::判断数据库是否已经存在,不存在则创建数据库( 推荐 )
- #如果已经存在,则创建不成功,但是不会报错。
- #CREATE DATABASE IF NOT EXISTS 数据库名;
- CREATE DATABASE IF NOT EXISTS dbtest CHARACTER SET 'utf8';
- #1-2管理数据库
- #查看当前连接中的数据库都有哪些
- SHOW DATABASES;
- #2.2 使用数据库
- #切换数据库
- USE dbtest;
- #查看当前数据库中都有哪些数据表
- SHOW TABLES;
- #查看当前使用的数据库
- SELECT DATABASE()
- FROM DUAL;
- #查看指定数据库下保存的数据表
- SHOW TABLES FROM dbtest;
- #2.3修改数据库
- #更改数据库字符集
- #ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
- SHOW CREATE DATABASE dbtest;#CREATE DATABASE `dbtest` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */
- ALTER DATABASE dbtest CHARACTER SET 'gbk';
- SHOW CREATE DATABASE dbtest;#CREATE DATABASE `dbtest` /*!40100 DEFAULT CHARACTER SET gbk */ /*!80016 DEFAULT ENCRYPTION='N' */
- #1.4删除数据库
- #方式一:
- DROP DATABASE dbtext01;
- #方式二:
- DROP DATABASE IF EXISTS dbtext01;
3. 创建表
3.1 创建方式 1(白手起家型)- 必须具备:
-
---CREATE TABLE权限---存储空间
- 语法格式:
CREATE TABLE [ IF NOT EXISTS ] 表名 (字段 1, 数据类型 [ 约束条件 ] [ 默认值 ],字段 2, 数据类型 [ 约束条件 ] [ 默认值 ],字段 3, 数据类型 [ 约束条件 ] [ 默认值 ],……[ 表约束条件 ]);加上了IF NOT EXISTS关键字,则表示:如果当前数据库中不存在要创建的数据表,则创建数据表; 如果当前数据库中已经存在要创建的数据表,则忽略建表语句,不再创建数据表。- 必须指定:
- 表名
列名(或字段名) ,数据类型, 长度
- 可选指定:
-
约束条件默认值
-
- 创建表举例1:
创建表CREATE TABLE emp (-- int 类型emp_id INT ,-- 最多保存 20 个中英文字符emp_name VARCHAR ( 20 ),-- 总位数不超过 15 位salary DOUBLE ,-- 日期类型birthday DATE);DESC emp;
 MySQL 在执行建表语句时,将 id 字段的类型设置为 int(11) ,这里的 11 实际上是 int 类型指定的显示宽度,默 认的显示宽度为11 。也可以在创建数据表的时候指定数据的显示宽度。
MySQL 在执行建表语句时,将 id 字段的类型设置为 int(11) ,这里的 11 实际上是 int 类型指定的显示宽度,默 认的显示宽度为11 。也可以在创建数据表的时候指定数据的显示宽度。- 创建表举例2:
CREATE TABLE dept(-- int 类型,自增deptno INT ( 2 ) AUTO_INCREMENT ,dname VARCHAR ( 14 ),loc VARCHAR ( 13 ),-- 主键PRIMARY KEY (deptno));DESCRIBE dept;
在MySQL 8.x版本中,不再推荐为INT类型指定显示长度,并在未来的版本中可能去掉这样的语法。
3.2 创建方式2(基于现有的表创建,同时导入数据)-
使用 AS subquery 选项, 将创建表和插入数据结合起来

-
指定的列和子查询中的列要一一对应
- 通过列名和默认值定义列
- CREATE TABLE emp1 AS SELECT * FROM employees;
- CREATE TABLE emp2 AS SELECT * FROM employees WHERE 1=2; -- 创建的emp2是空表
- CREATE TABLE dept80
- AS
- SELECT employee_id, last_name, salary*12 ANNSAL, hire_date
- FROM employees
- WHERE department_id = 80;
- DESCRIBE dept80;

3.3 查看数据表结构
-
在 MySQL 中创建好数据表之后,可以查看数据表的结构。 MySQL 支持使用 DESCRIBE/DESC 语句查看数据 表结构,也支持使用 SHOW CREATE TABLE 语句查看数据表结构。
语法格式如下:
SHOW CREATE TABLE 表名\G
>>使用 SHOW CREATE TABLE 语句不仅可以查看表创建时的详细语句,还可以查看存储引擎和字符编码。- #3. 创建表
- USE dbtest;
- SHOW CREATE DATABASE dbtest;
- #CREATE DATABASE `dbtest` /*!40100 DEFAULT CHARACTER SET gbk */ /*!80016 DEFAULT ENCRYPTION='N' */
- ALTER DATABASE dbtest CHARACTER SET 'utf8';
- SHOW TABLES;
- #方式一:
- CREATE TABLE IF NOT EXISTS myempl(
- id INT,
- emp_name VARCHAR(15),
- hire_date DATE
- );
- #查看表结构
- DESC myempl;
- #或者
- #查看创建表的语句结构
- SHOW CREATE TABLE myempl;
- SELECT * FROM myempl;
- #方式二:基于现有的表创建,同时导入数据
- CREATE TABLE myemp2
- AS
- SELECT *
- FROM employees;
- DESC myemp2;
- SELECT *
- FROM myemp2;
小练习:
- #练习一:创建一表 employees_copy,实现对 employees表的复制,包括表的数据
- CREATE TABLE employees_copy
- AS
- SELECT *
- FROM employees;
- SELECT *
- FROM employees_copy;
- #练习一:创建一表 employees_blank,实现对 employees表的复制,不包括表的数据
- CREATE TABLE employees_blank
- AS
- SELECT*
- FROM employees
- WHERE 1=2;
- SELECT*
- FROM employees_blank;
employees表:

练习一:

练习二:
 4. 修改表
4. 修改表- 修改表指的是修改数据库中已经存在的数据表的结构。
使用 ALTER TABLE 语句可以实现:
>>>向已有的表中添加列>>>>修改现有表中的列>>>>>删除现有表中的列>>>>>>>重命名现有表中的列4.1 追加一个列
语法格式如下:
ALTER TABLE 表名 ADD 【COLUMN】 字段名 字段类型 【FIRST|AFTER 字段名】;
- 举例:
ALTER TABLE dept80ADD job_id varchar ( 15 );
练习:
- #3-1添加一个字段
- #ALTER TABLE 表名 ADD 【COLUMN】 字段名 字段类型 【FIRST|AFTER 字段名】;
- //把age放在name后面,如果放第一个用 FIRST
- ALTER TABLE myemp2
- ADD age INT AFTER name;

#查看myemp2表结构:
DESC myemp2;

4.2 修改一个列
- 可以修改列的数据类型,长度、默认值和位置
- 修改字段数据类型、长度、默认值、位置的语法格式如下:
ALTER TABLE 表名 MODIFY 【 COLUMN 】 字段名 1 字段类型 【 DEFAULT 默认值】【 FIRST| AFTER 字段名 2】 ;- 举例:
ALTER TABLE dept80MODIFY last_name VARCHAR ( 30 );ALTER TABLE dept80MODIFY salary double ( 9 , 2 ) default 1000 ;- 对默认值的修改只影响今后对表的修改
-
此外,还可以通过此种方式修改列的约束。
小练习:
- #3-2修改一个字段:数据类型-长度-默认值(略)
- #ALTER TABLE 表名 MODIFY 【COLUMN】 字段名1 字段类型 【DEFAULT 默认值】【FIRST|AFTER 字段名2】;
- ALTER TABLE myemp2
- MODIFY name VARCHAR(25);
- ALTER TABLE myemp2
- MODIFY name VARCHAR(25) DEFAULT 'ddd';
- DESC myemp2;

4.3 重命名一个列
- 使用 CHANGE old_column new_column dataType子句重命名列。语法格式如下:
ALTER TABLE 表名 CHANGE 【column】 列名 新列名 新数据类型;
- 举例:
ALTER TABLE dept80CHANGE department_name dept_name varchar ( 15 );小练习:
- #3-3重命名一个字段
- #ALTER TABLE 表名 CHANGE 【column】 列名 新列名 新数据类型;
- ALTER TABLE myemp2
- CHANGE name emp_name VARCHAR(20);
- DESC myemp2;

4.4 删除一个列
-
删除表中某个字段的语法格式如下:
ALTER TABLE 表名 DROP 【COLUMN】字段名
- 举例:
ALTER TABLE dept80DROP COLUMN job_id;- #3-4删除一个字段
- #ALTER TABLE 表名 DROP 【COLUMN】字段名
- ALTER TABLE myemp2
- DROP COLUMN age;
- DESC myemp2;

5.-重命名表
- 方式一:使用RENAME
RENAME TABLE empTO myemp;- 方式二:
ALTER table deptRENAME [ TO ] detail_dept; -- [TO] 可以省略- 必须是对象的拥有者
- #4-重命名表
- #方式一:使用RENAME
- #RENAME TABLE emp
- #TO myemp;
- RENAME TABLE myempl
- To myemp11;
- DESC myemp11;

6. 删除表
- 在MySQL中,当一张数据表 没有与其他任何数据表形成关联关系 时,可以将当前数据表直接删除。
- 数据和结构都被删除
- 所有正在运行的相关事务被提交
- 所有相关索引被删除
- 语法格式:
DROP TABLE [IF EXISTS] 数据表1 [, 数据表2, …, 数据表n];
IF EXISTS 的含义为:如果当前数据库中存在相应的数据表,则删除数据表;如果当前数据库中不存 在相应的数据表,则忽略删除语句,不再执行删除数据表的操作。- 举例:
DROP TABLE dept80;
- DROP TABLE 语句不能回滚
- #5-删除表---DROP TABLE 语句不能回滚(不能撤销,删除了就没了)
- #DROP TABLE [IF EXISTS] 数据表1 [, 数据表2, …, 数据表n];
- DROP TABLE IF EXISTS myemp11;
- DESC myemp11;

7. 清空表
- TRUNCATE TABLE语句:
- 删除表中所有的数据
- 释放表的存储空间
- 举例:
TRUNCATE TABLE detail_dept;
TRUNCATE语句不能回滚,而使用 DELETE 语句删除数据,可以回滚
对比:
DELETE FROM emp2;#TRUNCATE TABLE emp2;SELECT * FROM emp2;ROLLBACK ;SELECT * FROM emp2;阿里开发规范:【参考】 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少,但 TRUNCATE 无事务且不触发 TRIGGER ,有可能造成事故,故不建议在开发代码中使用此语句。说明: TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同。- SELECT *
- FROM myemp2;
原来表:

执行清空操作:
TRUNCATE TABLE myemp2;清空后:
- SELECT *
- FROM myemp2;

表结构还在:
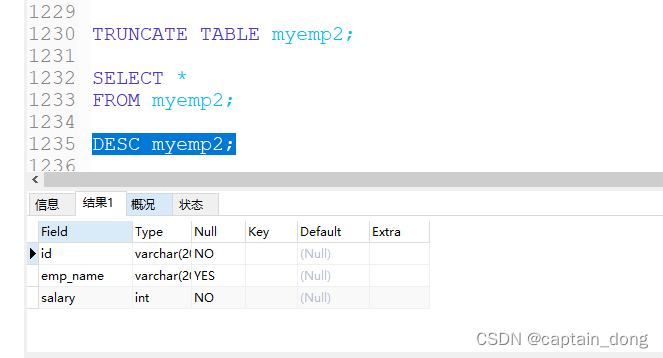
8. 内容拓展
-
拓展 1 :阿里巴巴《 Java 开发手册》之 MySQL 字段命名
 表删除 操作将把表的定义和表中的数据一起删除,并且 MySQL 在执行删除操作时,不会有任何的确认信 息提示,因此执行删除操时应当慎重。在删除表前,最好对表中的数据进行 备份 ,这样当操作失误时可 以对数据进行恢复,以免造成无法挽回的后果。同样的,在使用 ALTER TABLE 进行表的基本修改操作时,在执行操作过程之前,也应该确保对数据进 行完整的 备份 ,因为数据库的改变是 无法撤销 的,如果添加了一个不需要的字段,可以将其删除;相 同的,如果删除了一个需要的列,该列下面的所有数据都将会丢失。
表删除 操作将把表的定义和表中的数据一起删除,并且 MySQL 在执行删除操作时,不会有任何的确认信 息提示,因此执行删除操时应当慎重。在删除表前,最好对表中的数据进行 备份 ,这样当操作失误时可 以对数据进行恢复,以免造成无法挽回的后果。同样的,在使用 ALTER TABLE 进行表的基本修改操作时,在执行操作过程之前,也应该确保对数据进 行完整的 备份 ,因为数据库的改变是 无法撤销 的,如果添加了一个不需要的字段,可以将其删除;相 同的,如果删除了一个需要的列,该列下面的所有数据都将会丢失。拓展3:MySQL8新特性—DDL的原子化
-
在 MySQL 8.0 版本中, InnoDB 表的 DDL 支持事务完整性,即 DDL 操作要么成功要么回滚 。 DDL 操作回滚日志 写入到data dictionary 数据字典表 mysql.innodb_ddl_log (该表是隐藏的表,通过 show tables 无法看到) 中,用于回滚操作。通过设置参数,可将DDL 操作日志打印输出到 MySQL 错误日志中。
分别在MySQL 5.7版本和MySQL 8.0版本中创建数据库和数据表,结果如下:
CREATE DATABASE mytest;USE mytest;CREATE TABLE book1(book_id INT ,book_name VARCHAR ( 255 ));SHOW TABLES ;(1)在 MySQL 5.7 版本中,测试步骤如下: 删除数据表 book1 和数据表 book2 ,结果如下:mysql> DROP TABLE book1,book2;ERROR 1051 ( 42 S02): Unknown table 'mytest.book2'再次查询数据库中的数据表名称,结果如下:
mysql> SHOW TABLES ;Empty set ( 0.00 sec)从结果可以看出,虽然删除操作时报错了,但是仍然删除了数据表book1。
(2)在 MySQL 8.0 版本中,测试步骤如下: 删除数据表 book1 和数据表 book2 ,结果如下:mysql> DROP TABLE book1,book2;ERROR 1051 ( 42 S02): Unknown table 'mytest.book2'再次查询数据库中的数据表名称,结果如下:

数据库学习记录-----代码
- #字符串函数
- SELECT
- ASCII('abcdf'),
- CHAR_LENGTH('hello'),
- CHAR_LENGTH('诗栋'),
- LENGTH('helllo'),
- LENGTH('我嗯')
- FROM
- DUAL;
- SELECT
- CONCAT(NAME, '-work for-', id) "details"
- FROM
- students;
- #日期和时间函数
- #获取日期,时间
- SELECT
- CURDATE(),
- CURRENT_DATE (),
- CURTIME(),
- NOW(),
- SYSDATE(),
- #2022-09-24 -2022-09-24- 09:42:57 -2022-09-24 09:42:57- 2022-09-24 09:42:57
- UTC_DATE(),
- UTC_TIME() #-2022-09-24-01:42:57
- FROM
- DUAL;
- #日期与时间的转换
- SELECT
- UNIX_TIMESTAMP(),
- FROM_UNIXTIME(1663984252),
- UNIX_TIMESTAMP('2022-09-24 09:50:52'),
- FROM_UNIXTIME(1663984252)
- FROM
- DUAL;
- SELECT
- YEAR (CURDATE()),
- MONTH (CURDATE()),
- DAY (CURDATE()),
- WEEKDAY('2022-09-25'),
- HOUR (CURTIME()),
- MINUTE (NOW()),
- SECOND (SYSDATE())
- FROM
- DUAL;
- #日期的操作函数----》》extract(type FROM data)type指定返回的值
- SELECT
- EXTRACT(YEAR FROM NOW()),
- EXTRACT(MONTH FROM NOW()),
- EXTRACT(DAY FROM NOW()),
- EXTRACT(HOUR FROM NOW()),
- EXTRACT(MINUTE FROM NOW()),
- EXTRACT(SECOND FROM NOW()),
- EXTRACT(QUARTER FROM NOW())
- FROM
- DUAL;
- #时间和秒钟的转换函数 TIME_TO_SEC(time)将time转化为秒返回结果值;
- #SEC_TO_TIME(seconds)TIME(second) 将second描述转化为包含小时、分钟、秒的时间
- SELECT
- TIME_TO_SEC(CURTIME()),
- SEC_TO_TIME(9000)
- FROM
- DUAL;
- #计算日期和时间的函数
- # DATE_ADD(date,INTERVAL expr unit)或ADDDATE(date,INTERVAL expr unit)返回与给定时间相差INTERVAL时间段的日期时间
- #DATE_SUB(date,INTERVAL expr unit)返回与data相差INTERVAL时间间隔的日期
- SELECT
- NOW(),
- DATE_ADD(NOW(), INTERVAL 1 YEAR),
- #2022-09-26 00:48:01;2023-09-26 00:48:01
- DATE_SUB(NOW(), INTERVAL 1 YEAR),
- #2021-09-26 00:53:59
- DATE_ADD(
- NOW(),
- INTERVAL '1_1' YEAR_MONTH
- ) #2023-10-26 00:58:14;加1年1个月
- FROM
- DUAL;
- #日期的格式化与解析,格式化:日期---》字符串,解析:字符串————》日期
- #DATE_FORMAT(date,format)按照字符串format格式转化日期date值
- SELECT
- DATE_FORMAT(CURDATE(), '%Y-%M-%d'),
- #2022-September-26
- DATE_FORMAT(NOW(), '%Y-%M-%d'),
- #2022-September-26
- TIME_FORMAT(CURDATE(), '%H:%i:%s'),
- #00:00:00
- DATE_FORMAT(
- CURDATE(),
- '%Y-%M-%d %h:%i:%s %W %T %r'
- ) #2022-September-26 12:00:00 Monday 00:00:00 12:00:00 AM
- FROM
- DUAL;
- #解析:格式化的逆过程·
- SELECT
- STR_TO_DATE(
- '2022-October-26 12:30:20 Monday 1',
- '%Y-%M-%d %h:%i:%s %W'
- ) #2022-10-26 00:30:20
- FROM
- DUAL;
- SELECT
- GET_FORMAT(DATE, 'USA') #%m.%d.%Y
- SELECT
- GET_FORMAT(
- CURDATE(),
- GET_FORMAT(DATE, 'USA')
- )
- FROM
- DUAL;
- #流程控制函数
- #IF(VALUE,VALUE1,VALUE2)
- SELECT
- NAME,
- salary,
- IF (
- salary >= 6000,
- '高工资',
- '低工资'
- )
- FROM
- employees;
- #IFNULL(expr1,expr2)如果expr1是null则输出expr2否则输出本身
- #CASE
- #相当于java的if....else
- SELECT
- last_name,
- CASE
- WHEN salary >= 2000 THEN
- '孙悟空'
- WHEN salary >= 5000 THEN
- '孙悟净'
- WHEN salary >= 9000 THEN
- '孙悟能' ELT '曹耿'
- END "details"
- FROM
- employees;
- #相当于java的switch
- #CASE....WHEN.......THEN........WHEN....THEN...ELSE....end
- SELECT
- employee_id,
- last_name,
- department_id,
- salary,
- CASE department - id
- WHEN 10 THEN
- salary * 1.1
- WHEN 20 THEN
- salary * 1.2
- WHEN 20 THEN
- salary * 1.3
- ELSE
- salary * 1.4
- END "details"
- FROM
- employees;
- #相当于java的switch
- #CASE....WHEN.......THEN........WHEN....THEN...ELSE....end
- SELECT
- employee_id,
- last_name,
- department_id,
- salary,
- CASE department - id
- WHEN 10 THEN
- salary * 1.1
- WHEN 20 THEN
- salary * 1.2
- WHEN 20 THEN
- salary * 1.3
- END "details"
- FROM
- employees;
- WHERE
- department_id IN (10, 20, 30);
- #5-加密与解密函数
- #PASSWORD()在mysql8.0被弃用
- #加密
- SELECT
- MD5('mysql'),
- SHA('mysql') #81c3b080dad537de7e10e0987a4bf52e
- FROM
- DUAL;
- #f460c882a18c1304d88854e902e11b85d71e7e1b
- #加密:
- #ENCODE(str,,)/DECODE(crypt_str,pass_str):返回pass_str作为加密密码加密value在mysql8.0被弃用
- #解密:
- #DECODE(crypt_str,pass_str):返回pass_str作为解密密码解密value 在mysql8.0被弃用
- SELECT
- ENCODE('shenlidong', 'mysql'),
- ENCODE(
- 'shenlidong',
- 'mysql',
- 'mysql'
- )
- FROM
- DUAL;
- #在mysql8.0被弃用,5.7可以
- #[SQL]SELECT ENCODE('shenlidong','mysql'),ENCODE('shenlidong','mysql','mysql')
- #FROM DUAL;
- #[Err] 1305 - FUNCTION dbtest.ENCODE does not exist
- #mysql信息函数
- SELECT
- VERSION(),
- CONNECTION_ID(),
- DATABASE (),
- SCHEMA (),
- USER (),
- CURRENT_USER (),
- CHARSET('shenlidong'),
- COLLATION ('shenlidong')
- FROM
- DUAL;
- #其他函数
- SELECT
- FORMAT(123.123, 2),
- FORMAT(123.125, 0),
- FORMAT(123.125, 2)
- FROM
- DUAL;
- SELECT
- CONV(16, 10, 2),
- CONV(8888, 10, 16),
- CONV(NULL, 10, 2)
- FROM
- DUAL;
- #BENCHMARK(count,expr):用于测试表达式的执行效率(时间)
- SELECT
- INET_ATON('192.168.10.1')
- FROM
- DUAL;
- SELECT
- INET_ATON('192.168.10.1'),
- CHARSET(
- CONVERT ('shenlidong' USING 'utf8') }
- FROM
- DUAL;
- #3232238081
- /*
- SELECT employees
- INSERT INTO employees VALUES(1002,'wangwu',1500);
- INSERT INTO employees VALUES(1003,'likui',2300);
- INSERT INTO employees VALUES(1004,'shimin',3000);
- INSERT INTO employees VALUES(1005,'liyuan',3500);
- FROM employees;*/
- #8-1聚合函数
- #8-1-1AVG() SUM()
- SELECT
- id,
- NAME,
- salary,
- AVG(salary),
- SUM(salary),
- SUM(id)
- FROM
- employees;
- #8-1-2 MAx() MIN()
- SELECT
- MAX(salary),
- MIN(salary)
- FROM
- employees;
- SELECT
- MAX(NAME),
- MIN(NAME) #wangwu lisi
- FROM
- employees;
- #8-1-3 COUNT()
- #1.计算指定字段在查询结构中出现的个数(不包含有Null值的)
- SELECT
- COUNT(id),
- COUNT(salary),
- COUNT(salary * 3),
- COUNT(1),
- COUNT(*) #4 4 4 4 4
- FROM
- employees;
- #如果计算表中有多少条记录,如何实现?
- #方式一:COUNT(*)
- #方式二:COUNT(1)‘
- #方式三:COUNT(具体字段):不一定对!
- #2-注意:计算指定字段出现的个数时,是不计算有null值的。
- #3-
- SELECT
- AVG(salary),
- SUM(salary) / COUNT(salary) aver #2550.0000 2550.0000
- FROM
- employees;
- #。。。。。。。。。。。。。。。。。
- SELECT
- AVG(IFNULL(salary, 1)) aver1,
- SUM(salary) / COUNT(IFNULL(salary, 1)) aver2 #2550.0000 2550.0000
- FROM
- employees;
- #
- SELECT
- *
- FROM
- employees;
- #方差 标准差 中位数等
- #8-2 GROUP BY 的使用
- #需求:查询各个部门的平均工资、最高工资
- SELECT
- id,
- AVG(salary),
- SUM(salary)
- FROM
- employees
- GROUP BY
- id #结论1:select中出现的非组函数的字段必须声明在group BY中
- #反之,group BY中声明的字段可以不出现在select中。
- #结论2:GROUP BY 声明在from后面、where后面,Order BY前面、limit前面
- #结论3:MySql中GROUP BY使用with ROLLUP
- SELECT
- id,
- AVG(salary),
- SUM(salary)
- FROM
- employees
- GROUP BY
- id WITH ROLLUP #计算整体的平均 : AVG(salary): 2550.0000 SUM(salary):10200
- #需求:查询各个部门的平均工资,按照低到高排列
- SELECT
- id,
- AVG(salary) aver_sal
- FROM
- employees
- GROUP BY
- id
- ORDER BY
- aver_sal ASC;
- SELECT
- id,
- AVG(salary) aver_sal
- FROM
- employees
- GROUP BY
- id WITH ROLLUP
- ORDER BY
- aver_sal;
- #8-3 HAVING 的使用(作用:用来过滤数据的)
- SELECT
- id,
- MAX(salary)
- FROM
- employees #WHERE MAX(salary)>1000 #错误方式过滤
- GROUP BY
- id;
- #要求1:如果过滤条件中使用了聚合函数,则必须使用HAVING来替换where。否则,报错
- #要求2:HAVING必须声明在GROUP BY 后面
- SELECT
- id,
- MAX(salary)
- FROM
- employees
- GROUP BY
- id
- HAVING
- MAX(salary) > 2000;
- #开发中,我们使用HAVING的前提是SQL中使用了GROUP BY
- #需求:查employees中id为1001,1002,1004中的比2000的最高工资
- #方式一:(推荐使用,执行效率高于方式二)
- SELECT
- id,
- MAX(salary)
- FROM
- employees
- WHERE
- id IN (1001, 1002, 1004)
- GROUP BY
- id
- HAVING
- MAX(salary) > 2000;
- #方式二:
- SELECT
- id,
- MAX(salary)
- FROM
- employees
- WHERE
- id IN (1001, 1002, 1004)
- GROUP BY
- id
- HAVING
- MAX(salary) > 2000
- AND id IN (1001, 1002, 1004);
- #结论:当过滤条件中有聚合函数时,则此过滤条件必须声明在HAVING
- # 当过滤条件中没有聚合函数时,则此过滤条件声明在WHERE或HAVING中都可以。但是,建议声明在WHERE中
- /*
- WHERE和HAVING的对比:
- 1-从适用范围上:HAVING适用范围更广
- HAVING 可以完成 WHERE 不能完成的任务。这是因为,
- 在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。
- HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,
- 对分组的结果集进行筛选,这个功能是 WHERE 无法完成
- 的。另外,WHERE排除的记录不再包括在分组中。
- 2-如果过滤条件中没有聚合函数:这种情况下,WHERE的执行效率要高于HAVING
- 如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接
- 后筛选。
- */
- #4. SQL底层执行原理
- #SELECT语句的完整结构
- /*sql92语法:
- SELECT ...,...,...(存在聚合函数)
- FROM ...,...,...,...
- WHERE 多表连接条件 AND 不包含组(聚合函数)函数的过滤条件
- GROUP BY 包含组函数的过滤条件
- ORDER BY ... (ASC/DESC)
- LIMIT ...,...(分页操作)
- #sql99语法:
- SELECT ...,...,...(存在聚合函数)
- FROM ...(LEFT/RIGHT)JOIN...ON 多表连接条件
- ...(LEFT/RIGHT)JOIN...ON
- WHERE 不包含组(聚合函数)函数的过滤条件
- GROUP BY 包含组函数的过滤条件
- ORDER BY ... (ASC/DESC)
- LIMIT ...,...(分页操作)
- */
- #4.SQL语句的执行过程:
- #FROM...,...-->ON-->(LEFT/RIGHT JOIN)-->WHERE-->GROUP BY-->HAVING-->SELECT-->DISTINCT(去重)-->ORDER BY-->LIMIT
- #第09章_子查询
- #子查询指一个查询语句嵌套在另一个查询语句内部的查询。
- #需求:谁的工资比lidong高
- SELECT
- id,
- salary
- FROM
- employees
- WHERE
- salary > (
- SELECT
- salary
- FROM
- employees
- WHERE
- id = 1002
- );
- #称谓的规范:外查询(或主查询)、内查询(子查询)
- /*
- 子查询(内查询)在主查询之前一次执行完成。
- 子查询的结果被主查询(外查询)使用 。
- 注意事项
- 子查询要包含在括号内
- 将子查询放在比较条件的右侧
- 单行操作符对应单行子查询,多行操作符对应多行子查询
- */
- /*
- 3 子查询的分类:
- 角度一:
- 按内查询的结果返回一条还是多条记录,将子查询分为 单行子查询 -多行子查询 。
- 角度二:
- 我们按内查询是否被执行多次,将子查询划分为 相关(或关联)子查询 和
- 不相关(或非关联)子查询 (如上例)。
- 相关(或关联)子查询:比如:查询工资大于本部门平均工资的员工信息
- */
- #4. 单行子查询
- #4.1 单行比较操作符
- #题目:查询工资大于1002号员工工资的员工的信息
- #子查询的编写技巧(或步骤):1-从里往外写;2-从外往里写
- SELECT
- salary
- FROM
- employees
- WHERE
- id = 1002;
- #工资:2500
- SELECT
- id,
- employees.`name`,
- salary
- FROM
- employees
- WHERE
- salary > 2500;
- # id :1003 name: shangsan salary:2700
- #子查询方式:
- SELECT
- id,
- employees.`name`,
- salary
- FROM
- employees
- WHERE
- salary > (
- SELECT
- salary
- FROM
- employees
- WHERE
- id = 1002
- );
- # id :1003 name: shangsan salary:2700
- #题目:返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id和工资
- SELECT
- last_name,
- job_id,
- salary
- FROM
- employees
- WHERE
- job_id = (
- SELECT
- job_id
- FROM
- employees
- WHERE
- employee_id = 141
- )
- AND salary > (
- SELECT
- salary
- FROM
- employees
- WHERE
- employee_id = 143
- );
- #题目:返回公司工资最少的员工的last_name,job_id和salary
- SELECT
- last_name,
- job_id,
- salary
- FROM
- employees
- WHERE
- salary = (
- SELECT
- MIN(salary)
- FROM
- employees
- );
- #题目:查询与141号员工的manager_id和department_id相同的其他员工的employee_id,manager_id,department_id
- #方式一:
- SELECT
- employee_id,manager_id,department_id
- FROM
- employees
- WHERE
- manager_id = (
- SELECT
- manager_id
- FROM
- employees
- WHERE
- employee_id = 141
- )
- AND department_id = (
- SELECT
- department_id
- FROM
- employees
- WHERE
- employee_id = 141
- )
- AND employee_id <> 141;
- #方式二(了解)
- SELECT
- employee_id,
- manager_id,
- department_id
- FROM
- employees
- WHERE
- (manager_id, department_id) = (
- SELECT
- manager_id,
- department_id
- FROM
- employees
- WHERE
- employee_id = 141
- )
- AND employee_id <> 141;
- #题目:查询最低工资大于50号部门最低工资的部门id和其最低工资
- SELECT
- department_id ,, MIN(salary)
- FROM
- employees
- WHERE
- department_id IS NOT NULL
- GROUP BY
- department_id
- HAVING
- MIN(salary) > (
- SELECT
- MIN(salary)
- FROM
- employees
- WHERE
- department_id = 50
- );
- #题目:显式员工的employee_id,last_name,location。
- # 其中,若员工department_id与location_id为1800
- # 的department_id相同,则location为’Canada’,其余则为’USA’。
- SELECT
- employee_id,
- last_name,
- CASE department_id
- WHEN (
- SELECT
- department_id
- FROM
- department
- WHERE
- location_id = 1800
- ) THEN
- ’Canada’
- ELSE
- ’USA’
- END "location"
- FROM
- employees #2.5 子查询中的空值问题
- SELECT
- last_name,
- job_id
- FROM
- employees
- WHERE
- job_id = (
- SELECT
- job_id
- FROM
- employees
- WHERE
- last_name = 'Haas'
- );
- #非法使用子查询
- #Subquery returns more than 1 row
- SELECT
- employee_id,
- last_name
- FROM
- employees
- WHERE
- salary = (
- SELECT
- MIN(salary)
- FROM
- employees
- GROUP BY
- department_id
- );
- #3. 多行子查询
- #IN
- SELECT
- employee_id,
- last_name
- FROM
- employees
- WHERE
- salary IN (
- SELECT
- MIN(salary)
- FROM
- employees
- GROUP BY
- department_id
- );
- #ANY
- #题目:返回其它job_id中比job_id为‘IT_PROG’部门任一工资低的员工的员工号、
- #姓名、job_id 以及salary
- SELECT
- employee_id,
- job_id,
- salary
- FROM
- employees
- WHERE
- job_id <> ‘IT_PROG’
- AND salary < ANY (
- SELECT
- salary
- FROM
- employees
- WHERE
- job_id = ‘IT_PROG’
- );
- #ALL
- #题目:返回其它job_id中比job_id为‘IT_PROG’部门所有工资低的员工的员工号、
- #姓名、job_id 以及salary
- SELECT
- employee_id,
- job_id,
- salary
- FROM
- employees
- WHERE
- job_id <> ‘IT_PROG’
- AND salary < ALL (
- SELECT
- salary
- FROM
- employees
- WHERE
- job_id = ‘IT_PROG’
- );
- #题目:查询平均工资最低的部门id
- #方式一:
- SELECT
- department_id
- FROM
- employees
- GROUP BY
- department_id
- HAVING
- AVG(salary) = (
- SELECT
- MIN(avg_sal)
- FROM
- (
- SELECT
- AVG(salary) avg_sal
- FROM
- employees
- GROUP BY
- department_id
- ) dept_avg_sal
- ) #方式二:
- SELECT
- department_id
- FROM
- employees
- GROUP BY
- department_id
- HAVING
- AVG(salary) <= ALL (
- SELECT
- AVG(salary) avg_sal
- FROM
- employees
- GROUP BY
- department_id
- ) #3.3 空值问题 解决
- SELECT
- last_name
- FROM
- employees
- WHERE
- employee_id NOT IN (
- SELECT
- manager_id
- FROM
- employees
- WHERE
- manager_id IS NOT NULL
- );
- #4. 相关子查询
- /*
- 如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件
- 关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为 关联子查询 。
- */
- #题目:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id
- #方式一:
- SELECT
- last_name,
- salary,
- department_id
- FROM
- employees e1
- WHERE
- salary > (
- SELECT
- AVG(salary)
- FROM
- employees e2
- WHERE
- department_id = e1.`department_id`
- );
- #方式二:(在from中声明子查询)
- SELECT
- e1.last_name,
- e1.salary,
- e1.department_id
- FROM
- employees e1,
- (
- SELECT
- department_id,
- AVG(salary) dept_avg_sal
- FROM
- employees
- GROUP BY
- department_id
- ) e2
- WHERE
- e1.`department_id` = e2.department_id
- AND e1.`salary` > e2.dept_avg_sal;
- #在ORDER BY 中使用子查询:
- #题目:查询员工的id,salary,按照department_name 排序
- SELECT
- employee_id,
- salary
- FROM
- employees e
- ORDER BY
- (
- SELECT
- department_name
- FROM
- departments d
- WHERE
- e.`department_id` = d.`department_id`
- );
- #结论:在 SELECT中,出除了 GROUP BY和 LIMIT之外,其他位置都可以声明子查询
- #题目:若employees表中employee_id与job_history表中employee_id相同的数目不小于2,输出这些相同
- #id的员工的employee_id,last_name和其job_id
- SELECT
- e.employee_id,
- last_name,
- e.job_id
- FROM
- employees e
- WHERE
- 2 <= (
- SELECT
- COUNT(*)
- FROM
- job_history
- WHERE
- employee_id = e.employee_id
- );
- #4.3 EXISTS 与 NOT EXISTS关键字
- #题目:查询公司管理者的employee_id,last_name,job_id,department_id信息
- #方式一:
- SELECT
- employee_id,
- last_name,
- job_id,
- department_id
- FROM
- employees e1
- WHERE
- EXISTS (
- SELECT
- *
- FROM
- employees e2
- WHERE
- e2.manager_id = e1.employee_id
- );
- #方式二:(自连接)
- SELECT DISTINCT
- e1.employee_id,
- e1.last_name,
- e1.job_id,
- e1.department_id
- FROM
- employees e1
- JOIN employees e2
- WHERE
- e1.employee_id = e2.manager_id;
- #方式三:(子查询)
- SELECT
- employee_id,
- last_name,
- job_id,
- department_id
- FROM
- employees
- WHERE
- employee_id IN (
- SELECT DISTINCT
- manager_id
- FROM
- employees
- );
- #题目:查询departments表中,不存在于employees表中的部门的department_id和department_name
- #方式一:
- SELECT
- d.department_id,
- d.department_name
- FROM
- employees e
- RIGHT JOIN departments d ON e.`department_id` = d.`department_id`
- WHERE
- e.`department_id` IS NULL;
- #方式二:
- SELECT
- department_id,
- department_name
- FROM
- departments d
- WHERE
- NOT EXISTS (
- SELECT
- 'X'
- FROM
- employees e
- WHERE
- d.department_id = e.department_id
- );
- #4.4 相关更新
- UPDATE table1 alias1
- SET COLUMN = (
- SELECT
- expression
- FROM
- table2 alias2
- WHERE
- alias1. COLUMN = alias2. COLUMN
- );
- #题目:在employees中增加一个department_name字段,数据为员工对应的部门名称
- # 1)
- ALTER TABLE employees ADD (
- department_name VARCHAR2 (14)
- );
- # 2)
- UPDATE employees e
- SET department_name = (
- SELECT
- department_name
- FROM
- departments d
- WHERE
- e.department_id = d.department_id
- );
- #4.4 相关删除
- DELETE
- FROM
- table1 alias1
- WHERE
- COLUMN operator (
- SELECT
- expression
- FROM
- table2 alias2
- WHERE
- alias1. COLUMN = alias2. COLUMN
- );
- #题目:删除表employees中,其与emp_history表皆有的数据
- DELETE
- FROM
- employees e
- WHERE
- employee_id IN (
- SELECT
- employee_id
- FROM
- emp_history
- WHERE
- employee_id = e.employee_id
- );
- #问题:谁的工资比Abel的高?
- #方式1:自连接
- SELECT
- e2.last_name,
- e2.salary
- FROM
- employees e1,
- employees e2
- WHERE
- e1.last_name = 'Abel'
- AND e1.`salary` < e2.`salary` #方式2:子查询
- SELECT
- last_name,
- salary
- FROM
- employees
- WHERE
- salary > (
- SELECT
- salary
- FROM
- employees
- WHERE
- last_name = 'Abel'
- );
- #DDL数据定义语言:CREATE \ALTER\ DROP \RENAME \TRUNCATE
- #1. 创建和管理数据库
- #如何创建数据库?
- #方式一:
- CREATE DATABASE dbtest;
- #创建此数据库使用的是默认的字符集utf8mb4
- SHOW DATABASES;
- #方式二:CREATE DATABASE 数据库名 CHARACTER SET 字符集;
- # 显式了指明了要哦创建的数据库的字符集
- CREATE DATABASE dbtest CHARACTER
- SET 'gbk';
- #方式三::判断数据库是否已经存在,不存在则创建数据库( 推荐 )
- #如果已经存在,则创建不成功,但是不会报错。
- #CREATE DATABASE IF NOT EXISTS 数据库名;
- CREATE DATABASE
- IF NOT EXISTS dbtest CHARACTER
- SET 'utf8';
- #1-2管理数据库
- #查看当前连接中的数据库都有哪些
- SHOW DATABASES;
- #2.2 使用数据库
- #切换数据库
- USE dbtest;
- #查看当前数据库中都有哪些数据表
- SHOW TABLES;
- #查看当前使用的数据库
- SELECT
- DATABASE ()
- FROM
- DUAL;
- #查看指定数据库下保存的数据表
- SHOW TABLES
- FROM
- dbtest;
- #2.3修改数据库
- #更改数据库字符集
- #ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
- SHOW CREATE DATABASE dbtest;
- #CREATE DATABASE `dbtest` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */
- ALTER DATABASE dbtest CHARACTER
- SET 'gbk';
- SHOW CREATE DATABASE dbtest;
- #CREATE DATABASE `dbtest` /*!40100 DEFAULT CHARACTER SET gbk */ /*!80016 DEFAULT ENCRYPTION='N' */
- #1.4删除数据库
- #方式一:
- DROP DATABASE dbtext01;
- #方式二:
- DROP DATABASE
- IF EXISTS dbtext01;
- #3. 创建表
- USE dbtest;
- SHOW CREATE DATABASE dbtest;
- #CREATE DATABASE `dbtest` /*!40100 DEFAULT CHARACTER SET gbk */ /*!80016 DEFAULT ENCRYPTION='N' */
- ALTER DATABASE dbtest CHARACTER
- SET 'utf8';
- SHOW TABLES;
- #方式一:
- CREATE TABLE
- IF NOT EXISTS myempl (
- id INT,
- emp_name VARCHAR (15),
- hire_date DATE
- );
- #查看表结构
- DESC myempl;
- #或者
- #查看创建表的语句结构
- SHOW CREATE TABLE myempl;
- SELECT
- *
- FROM
- myempl;
- #方式二:基于现有的表创建,同时导入数据
- CREATE TABLE myemp2 AS SELECT
- *
- FROM
- employees;
- DESC myemp2;
- SELECT
- *
- FROM
- myemp2;
- #练习一:创建一表 employees_copy,实现对 employees表的复制,包括表的数据
- CREATE TABLE employees_copy AS SELECT
- *
- FROM
- employees;
- SELECT
- *
- FROM
- employees_copy;
- #练习一:创建一表 employees_blank,实现对 employees表的复制,不包括表的数据
- CREATE TABLE employees_blank AS SELECT
- *
- FROM
- employees
- WHERE
- 1 = 2;
- SELECT
- *
- FROM
- employees_blank;
- #3-修改表-----ALTER TABLE
- DESC myemp2;
- #3-1添加一个字段
- #ALTER TABLE 表名 ADD 【COLUMN】 字段名 字段类型 【FIRST|AFTER 字段名】;
- // 把age放在name后面,
- 如果放第一个用 FIRST ALTER TABLE myemp2 ADD age INT AFTER NAME;
- DESC myemp2;
- #3-2修改一个字段:数据类型-长度-默认值(略)
- #ALTER TABLE 表名 MODIFY 【COLUMN】 字段名1 字段类型 【DEFAULT 默认值】【FIRST|AFTER 字段名2】;
- ALTER TABLE myemp2 MODIFY NAME VARCHAR (25);
- ALTER TABLE myemp2 MODIFY NAME VARCHAR (25) DEFAULT 'ddd';
- DESC myemp2;
- #3-3重命名一个字段
- #ALTER TABLE 表名 CHANGE 【column】 列名 新列名 新数据类型;
- ALTER TABLE myemp2 CHANGE NAME emp_name VARCHAR (20);
- DESC myemp2;
- #3-4删除一个字段
- #ALTER TABLE 表名 DROP 【COLUMN】字段名
- ALTER TABLE myemp2 DROP COLUMN age;
- DESC myemp2;
- #4-重命名表
- #方式一:使用RENAME
- #RENAME TABLE emp
- #TO myemp;
- RENAME TABLE myempl TO myemp11;
- DESC myemp11;
- #5-删除表---DROP TABLE 语句不能回滚
- #DROP TABLE [IF EXISTS] 数据表1 [, 数据表2, …, 数据表n];
- DROP TABLE
- IF EXISTS myemp11;
- DESC myemp11;
- #6-清空表--表结构还在,数据没了
- #TRUNCATE TABLE detail_dept;
- SELECT
- *
- FROM
- myemp2;
- TRUNCATE TABLE myemp2;
- SELECT
- *
- FROM
- myemp2;
- DESC myemp2;
-
-
相关阅读:
2022就业季|Spring认证教你,如何使用 Spring 构建 REST 服务(五)
伸展树原理介绍
can not remove .unionfs
可转债市场和发行体制——市场的结构、发行方式、市场参与者与角色
SpringMVC(四)域对象共享数据
如何使用IntelliJ IDEA将普通项目转换为Maven项目
PerfView专题 (第三篇):如何寻找 C# 中的 VirtualAlloc 内存泄漏
Drools 规则引擎一文读懂
【dp树状数组优化】跳跃(jump)
navicat定时任务无效
- 原文地址:https://blog.csdn.net/m0_63064861/article/details/127458581
