-
MySQL进阶之SQL优化、视图、存储过程
1.插入数据优化:
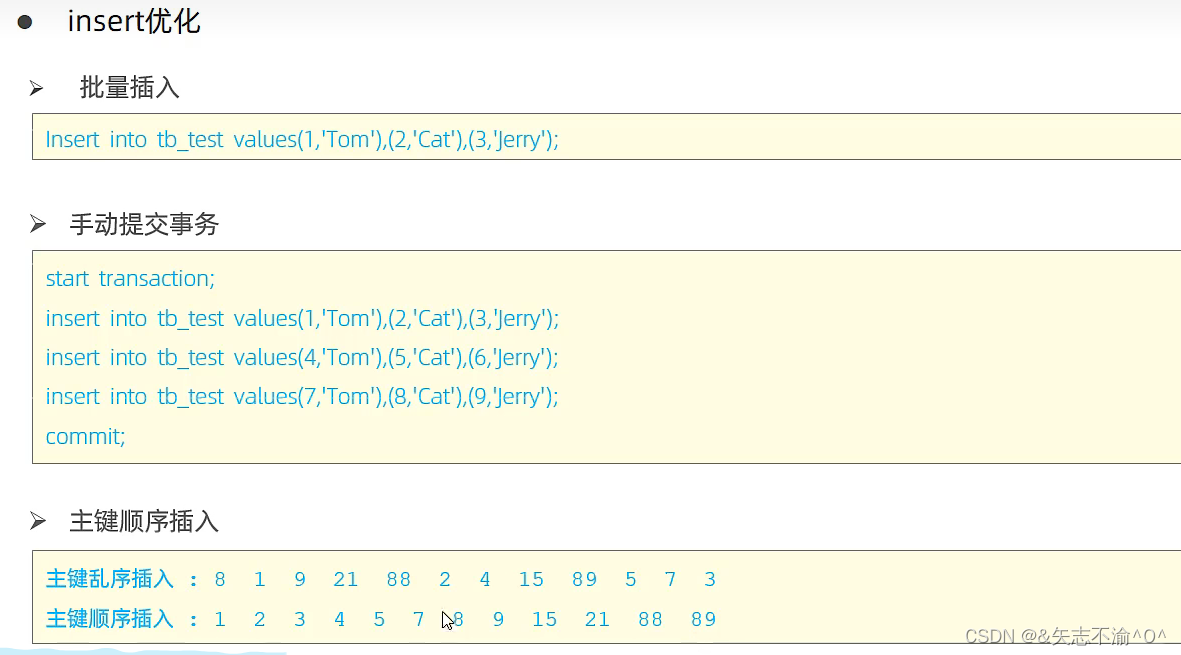
顺序插入要比乱序插入性能较高。

在第一次使用这个大批量插入数据时应该使用下列的命令来设置
 使用select @@local_infile可以看出这个local_infile开关是否打开,0是关闭,1是打开。关闭就用set打开。
使用select @@local_infile可以看出这个local_infile开关是否打开,0是关闭,1是打开。关闭就用set打开。
注意插入数据时,应先use某个数据库。

load data local infile '文件名'by ','(通过逗号分隔开)lines terminated by '\n';
2.主键优化:
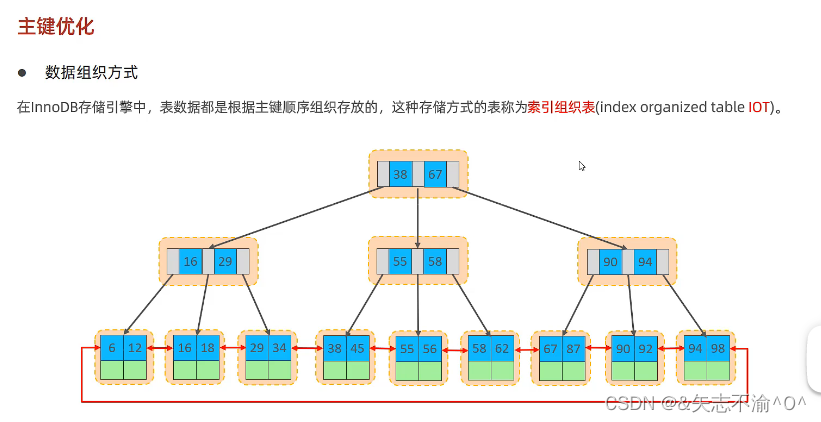
主键顺序插入时:
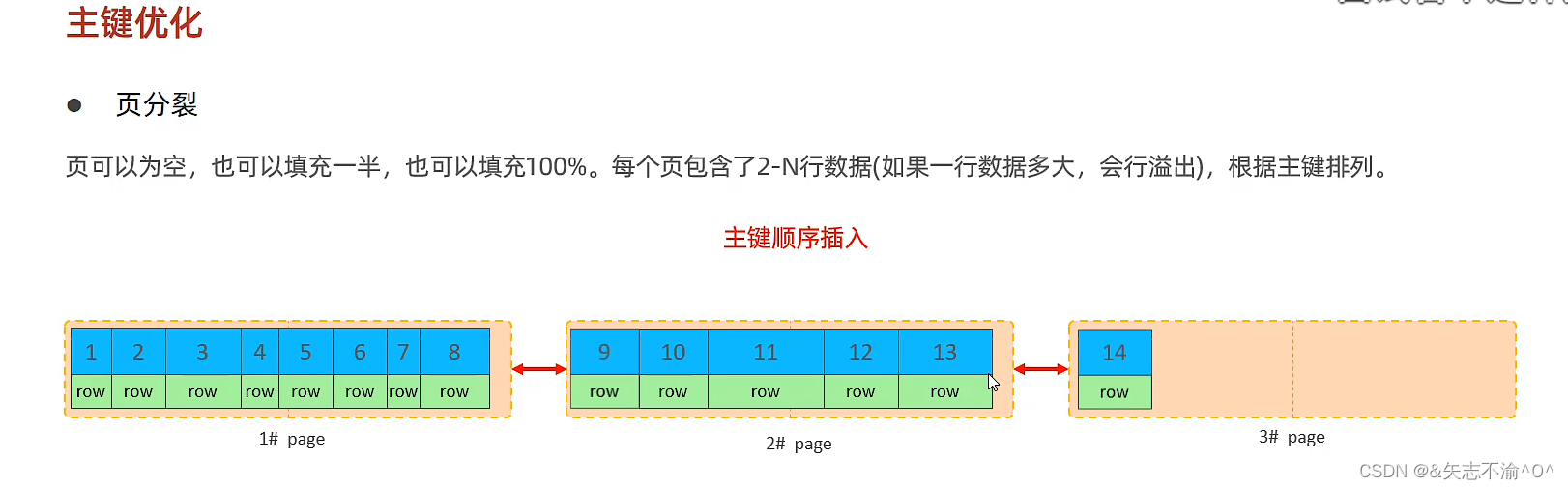
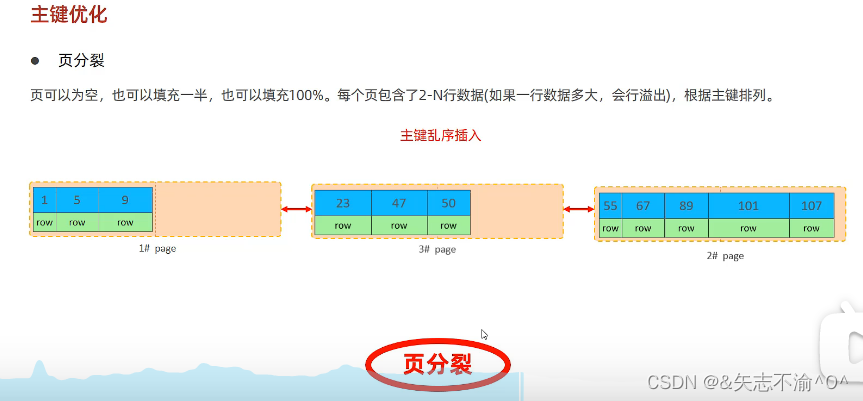
主键乱序插入时:可能会发生页分裂现象。
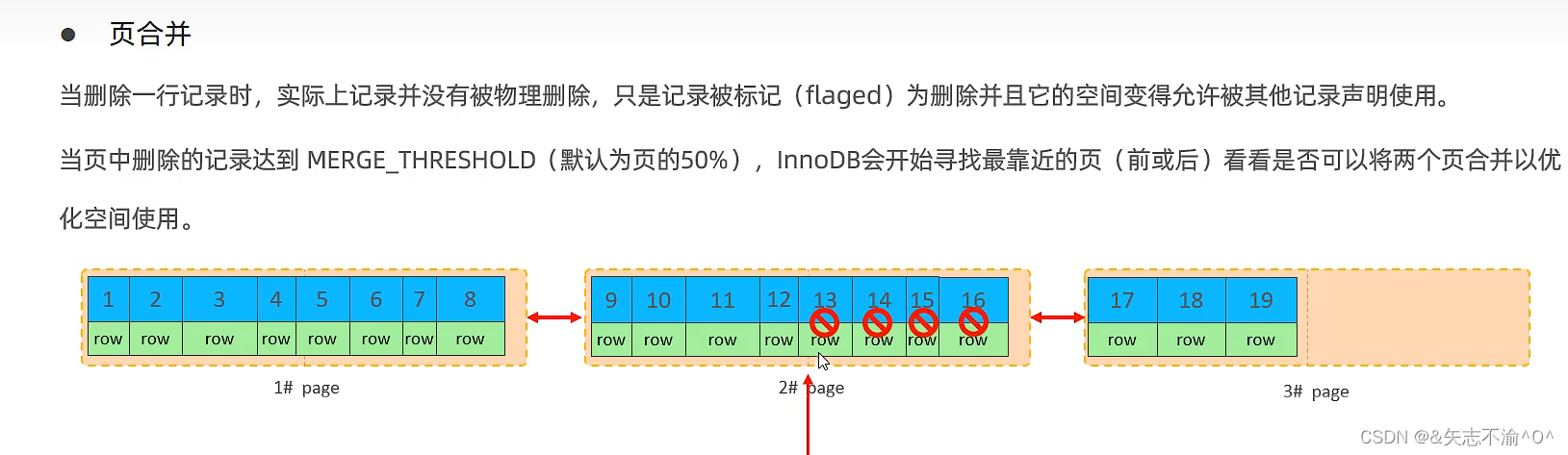
当数据删除量超过一般就可以考虑页合并啦。下面就是可以直接进行页合并了。
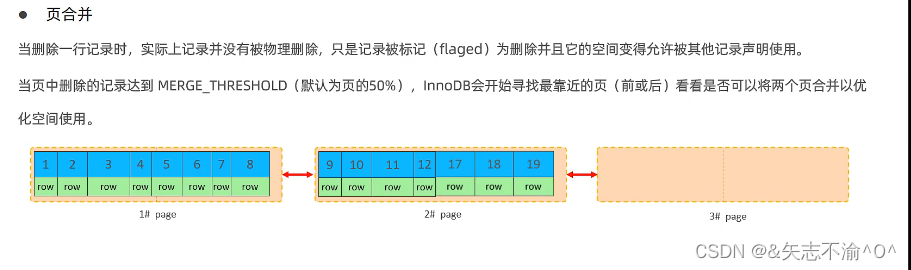
再次插入数据时就插入到3号数据页。
3.order by优化:

先按age排序,当age相同时再按phone排
当没有建立与这两个索引相匹配的索引时,查询的结果就是using filesort。反之,则结果就是using index。

当一个降序一个升序时就要另外建立一个与之相关的索引啦,注意要指定哪个升序哪个降序,
若没有明确指出,默认就是升序排序。

尽量使用覆盖索引,尽量不要使用select *
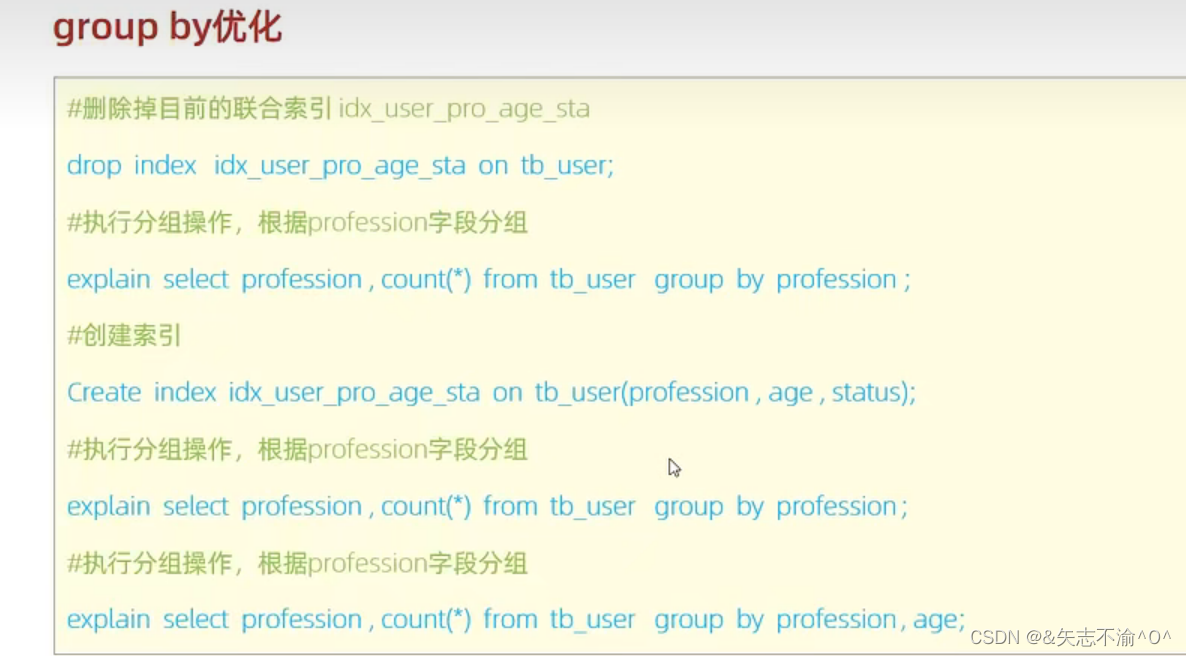
4.group by优化

5.limit优化:通过覆盖索引和子查询的方式来优化。
limit 0,10表示从0开始,每页返回10个数据。

6.count优化:
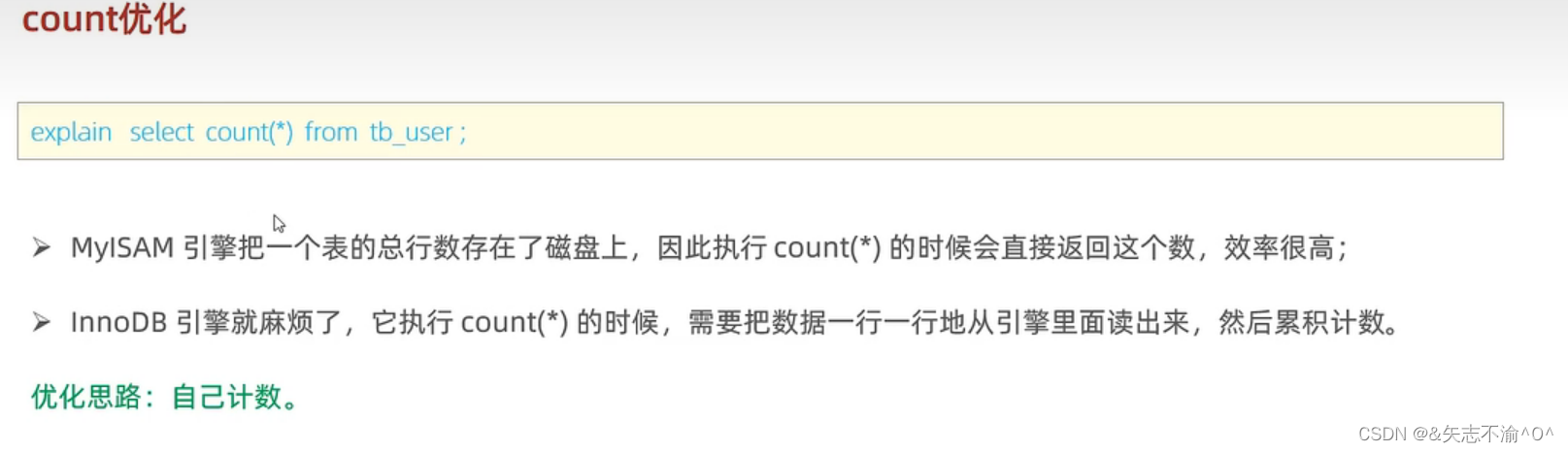
select count(profession)from tb_user;//注意这个profession不能为空,为空的那一个不能参与计数。



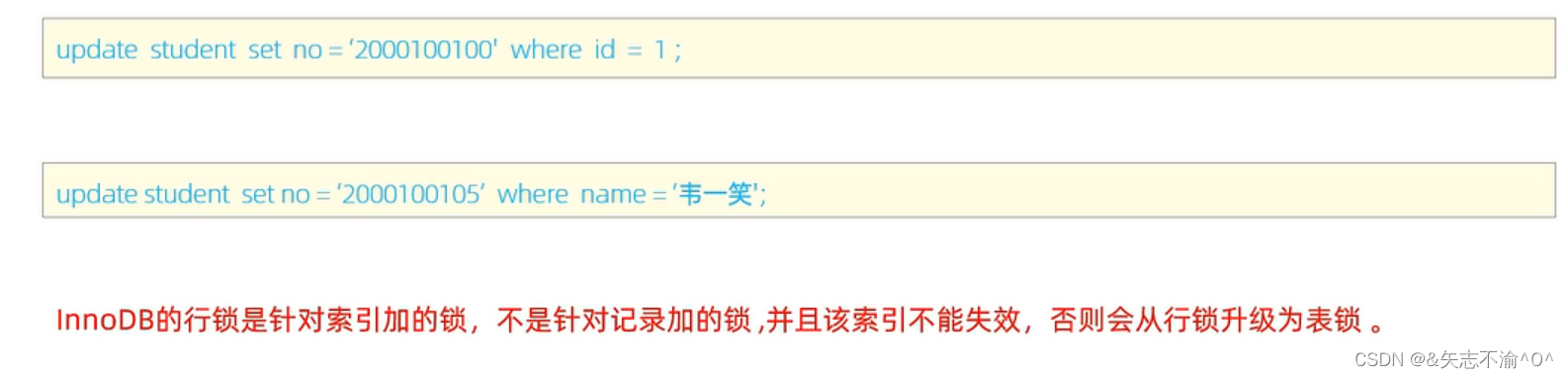
所以where条件字段一定要有索引。否则性能会降低。
uuid是指比较长的随机字符串。
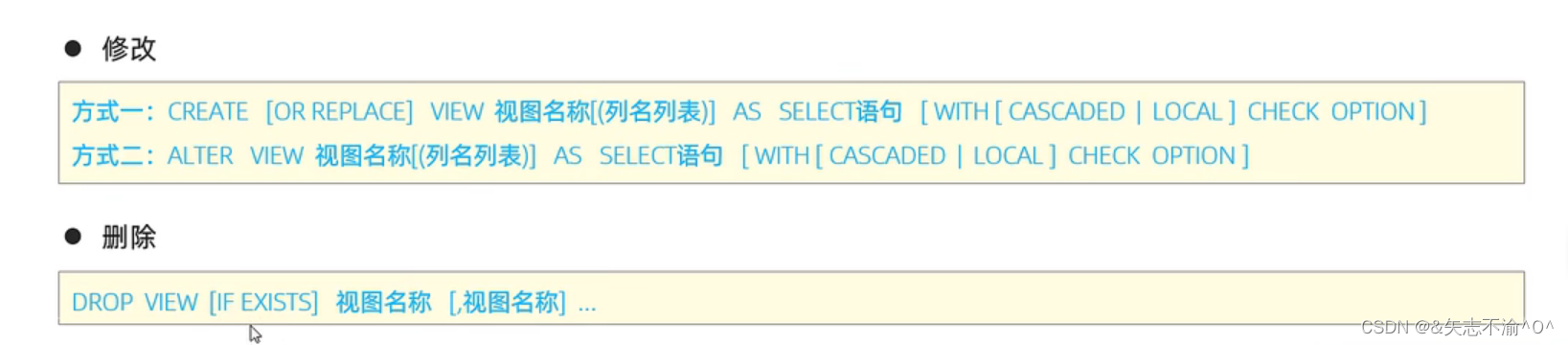
视图:数据库的存储对象







向视图中插入数据其实是向基表中插入数据。但当我们在基表中查询数据时,这些从视图插入的数据并不存在。
解决方法,在建立视图的sql语句末尾加上with cascaded/local check option
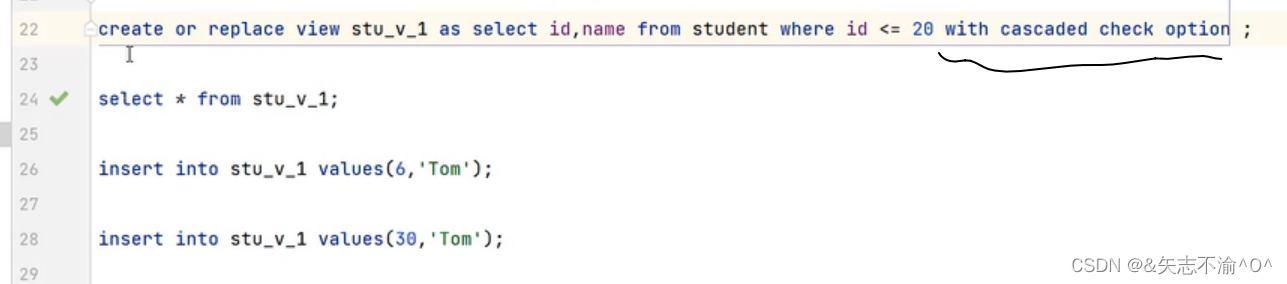
这样再插入数据时,就可以把符合where条件的数据插入到基表和视图中啦,注意不符合where条件的数据不会插入到基表和视图
只有加入with cascaded(级联)/local check option才会去检查插入的数据是否违背where条件表达式。
基于视图再创建视图:

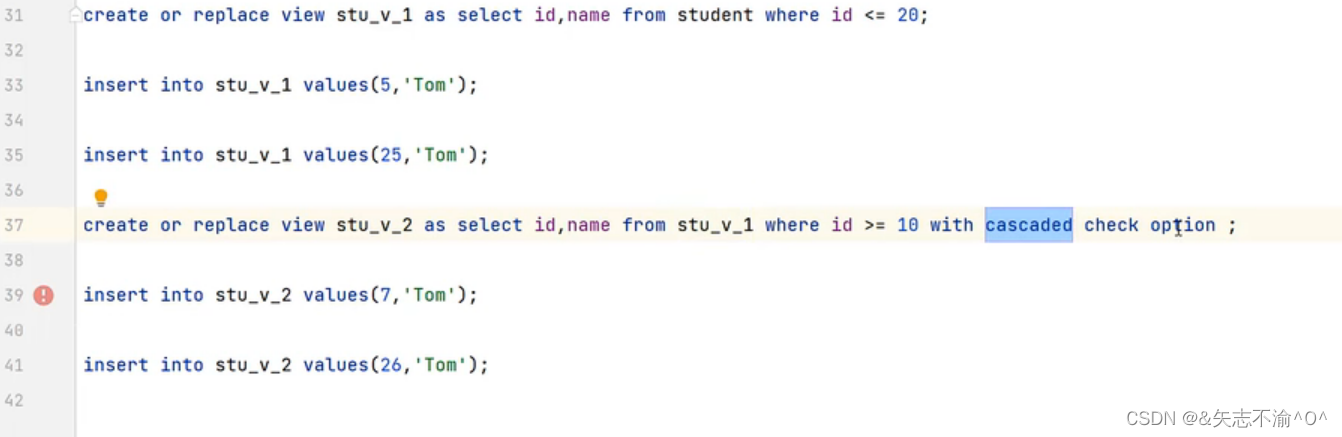
这里26插不进去是因为不仅要检查插入的视图,还要再去检查该视图依赖的视图的where条件表达式。

主要要有检查选项才会去执行检查是否符合where条件表达式
视图更新:



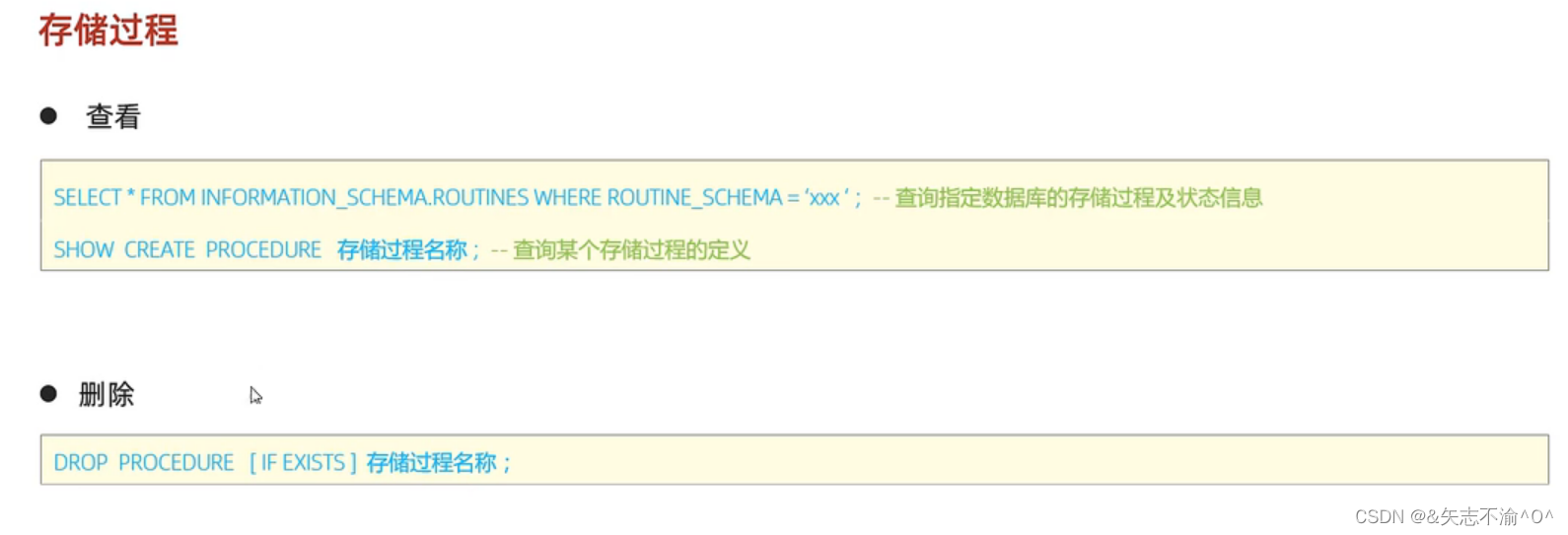
存储过程:

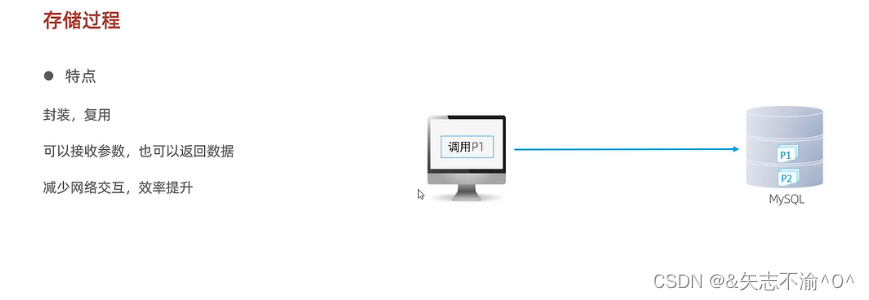
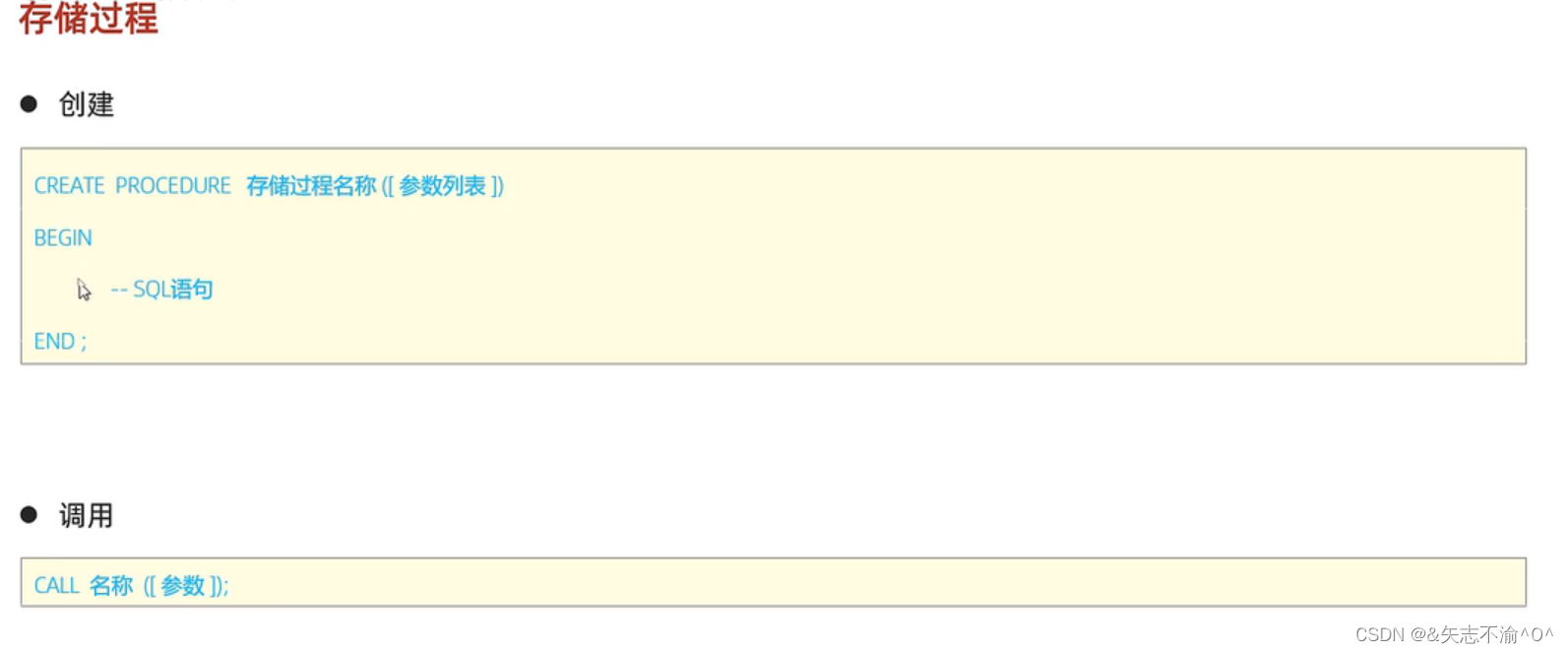
存储过程的SQL语句:
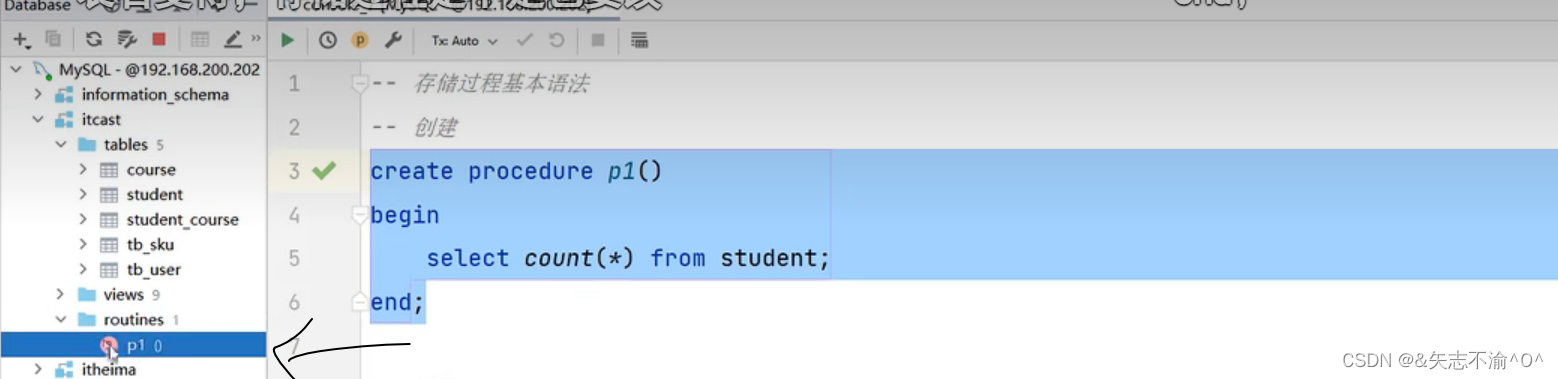
建立存储过程后在rountine文件夹下会有一个p1
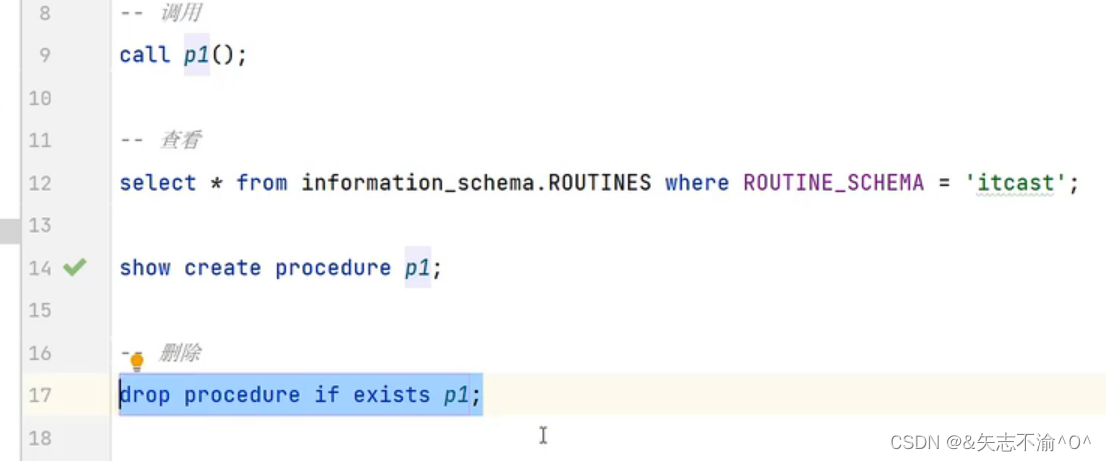


相当于我们重定义结束符¥¥
查看系统变量:

session表示绘画级别的系统变量。global表示全局的系统变量。
 表示查看autocommit这个系统变量的值。
表示查看autocommit这个系统变量的值。
这些设置在服务器重启后都会恢复到默认值,需要在mysql系统文件中永久设置

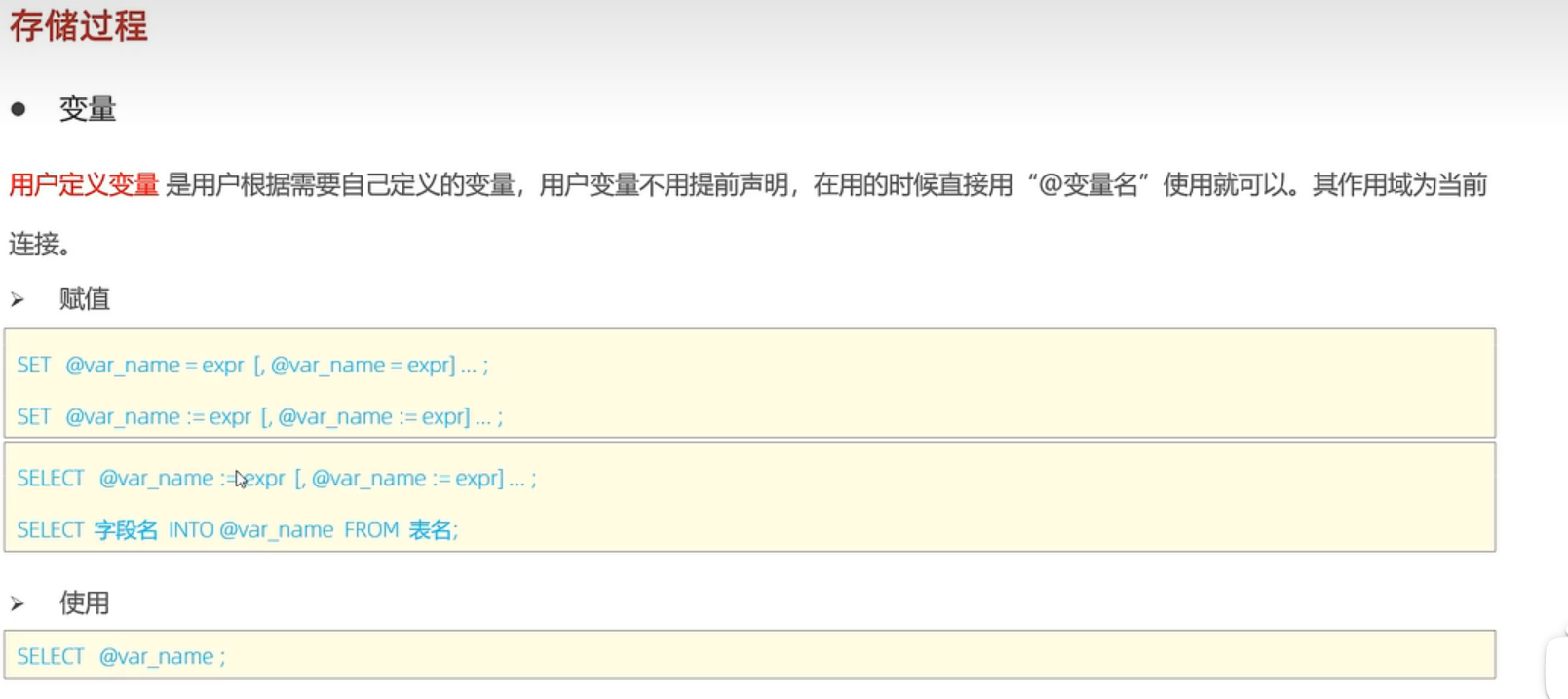
用户定义变量:
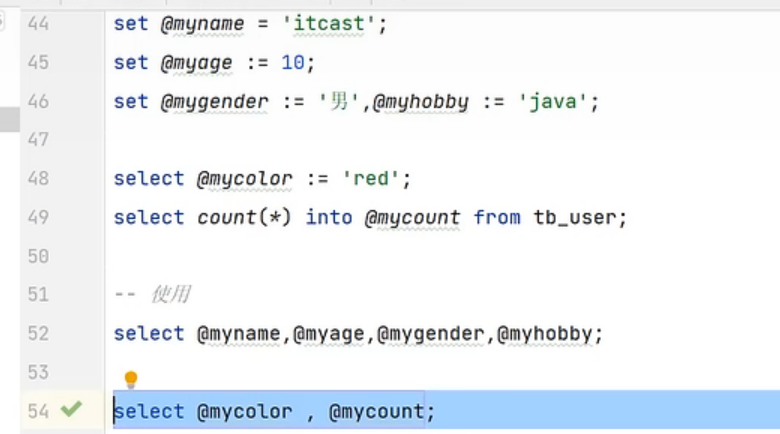
随便赋值用:= 当设置一个变量却没有赋值时,系统默认为null
局部变量:
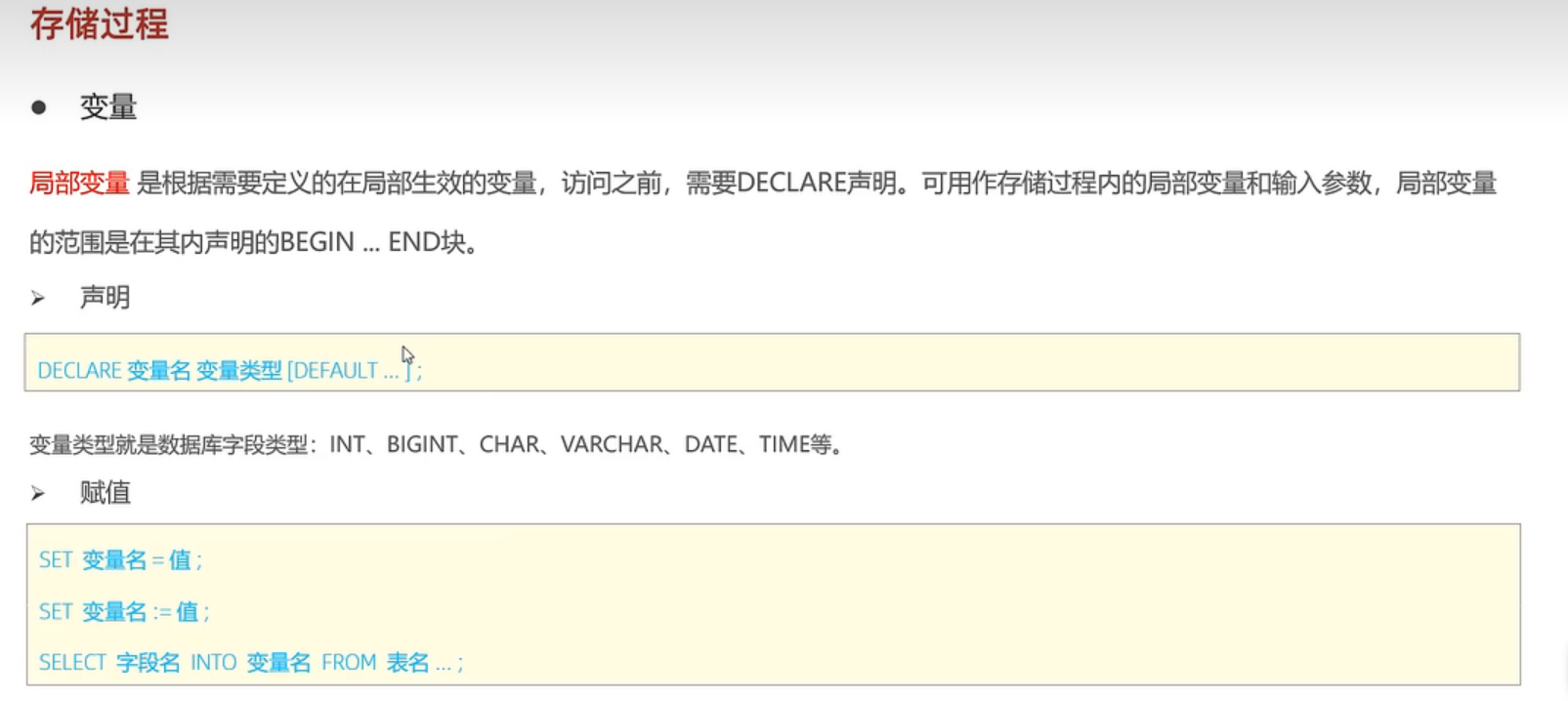
声明时declare后面的default加上一个数就是默认值。
设置局部变量的案例:

注意赋值和使用不要和局部变量的赋值和使用混淆。select @stu_student是关于局部变量的。最后使用call+存储过程来调用。
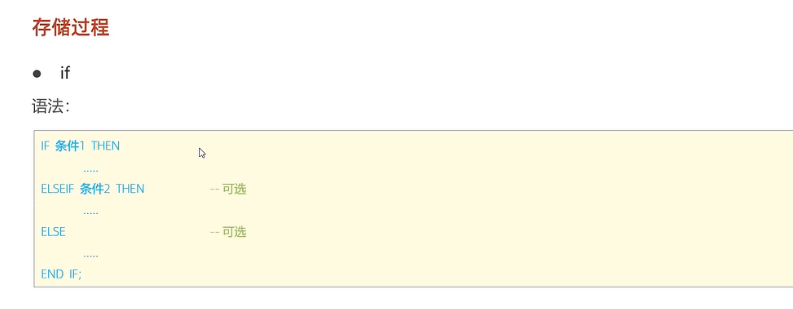
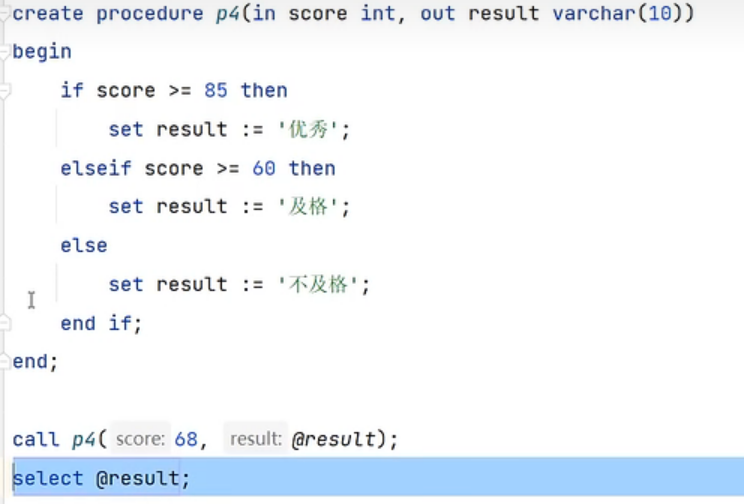
1.if判断:
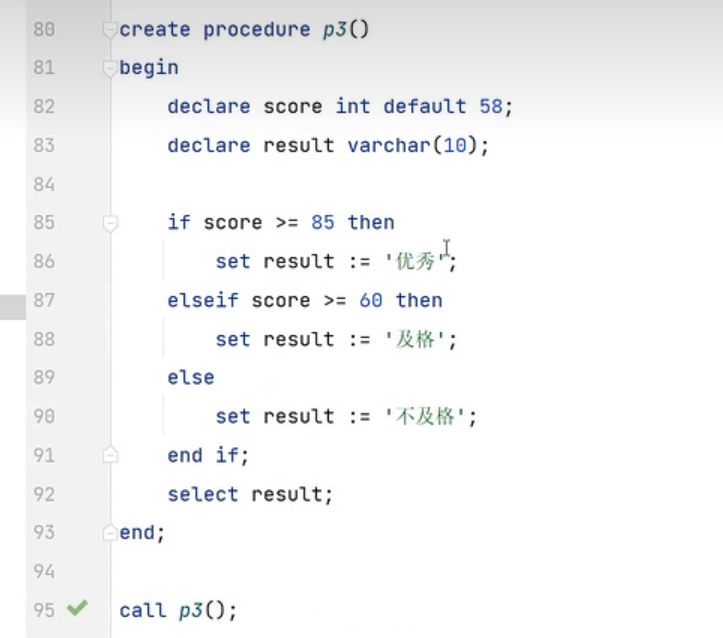
案例:
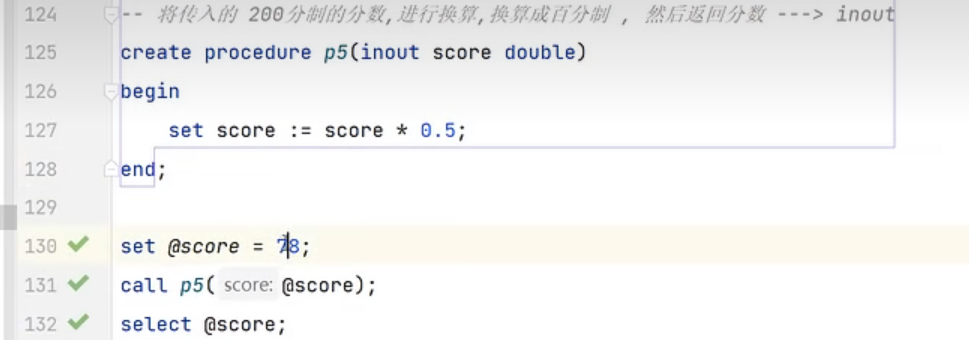
2.参数:
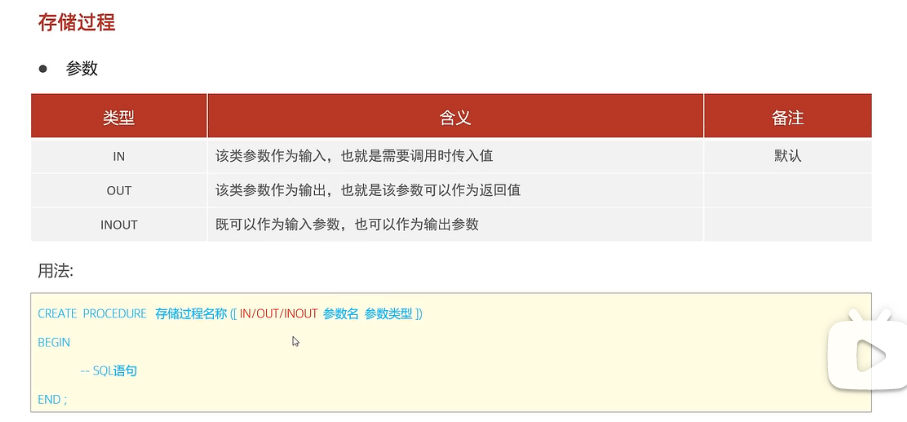
若不设置参数类型,默认就是in类型。
case判断:
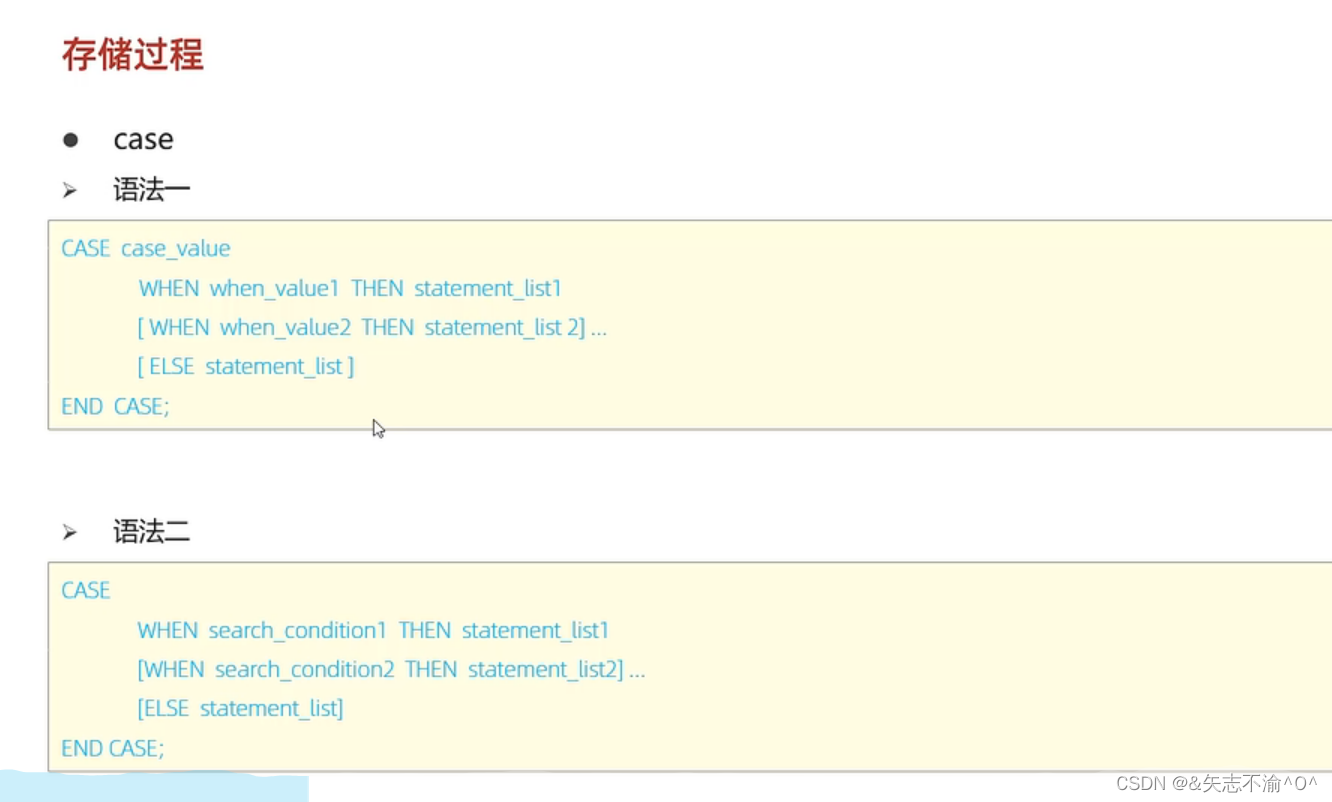
用第二种居多。

concat作用是拼接字符串。

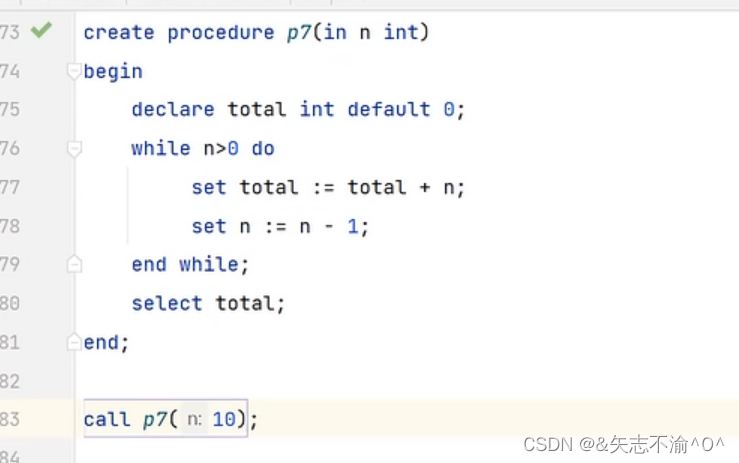
while循环:
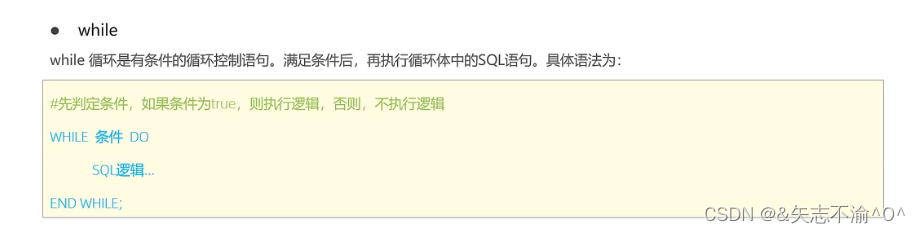
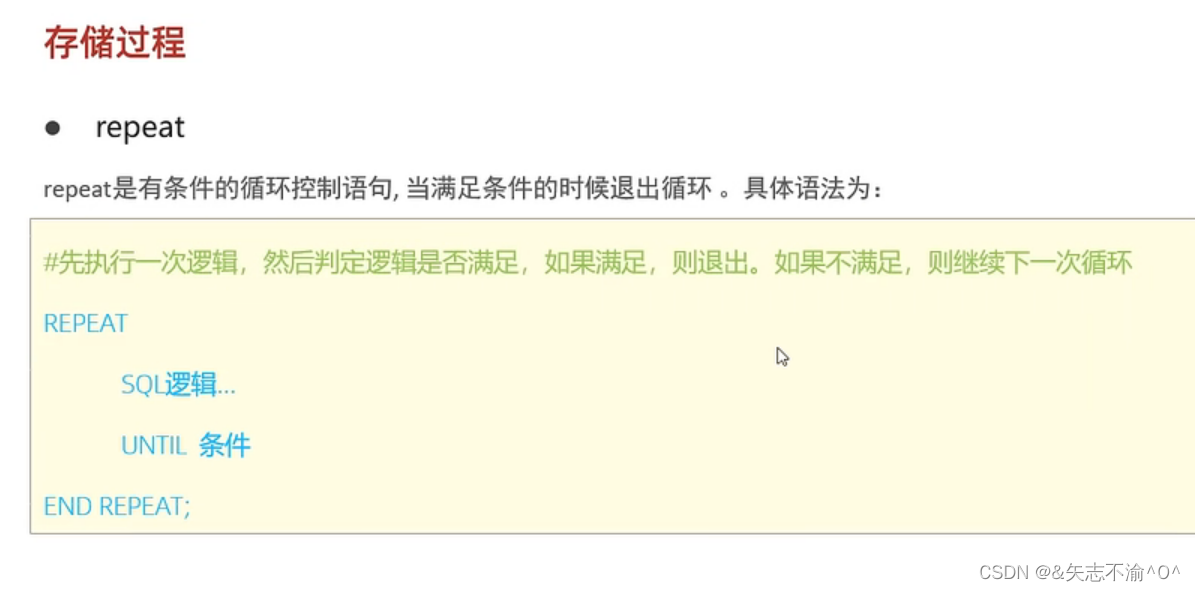
repeat循环:有条件的循环控制语句
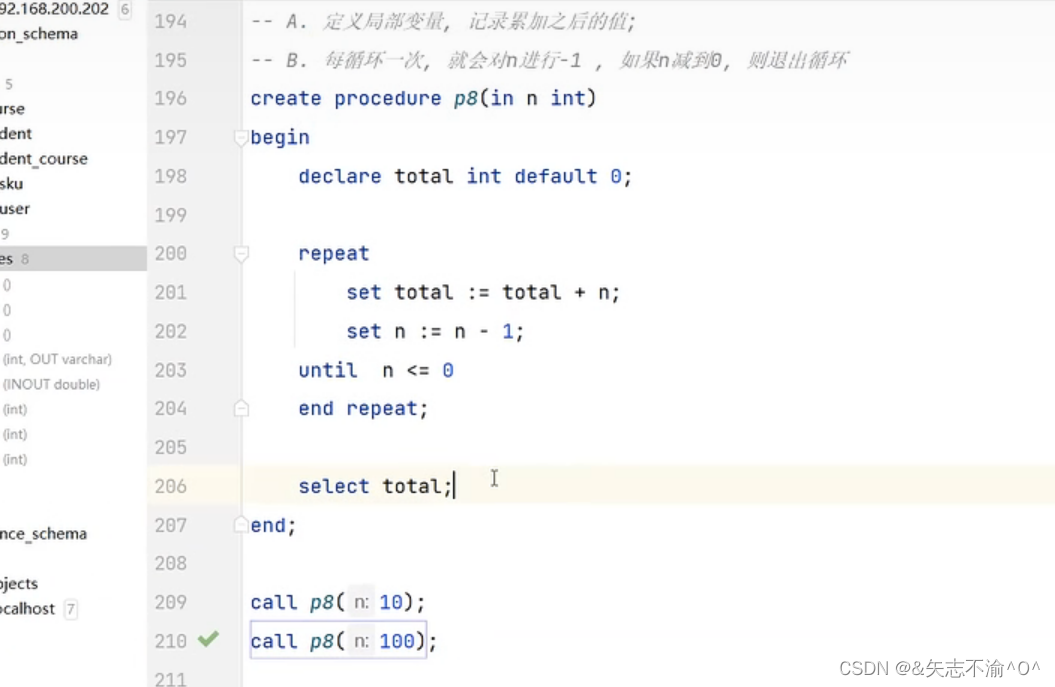
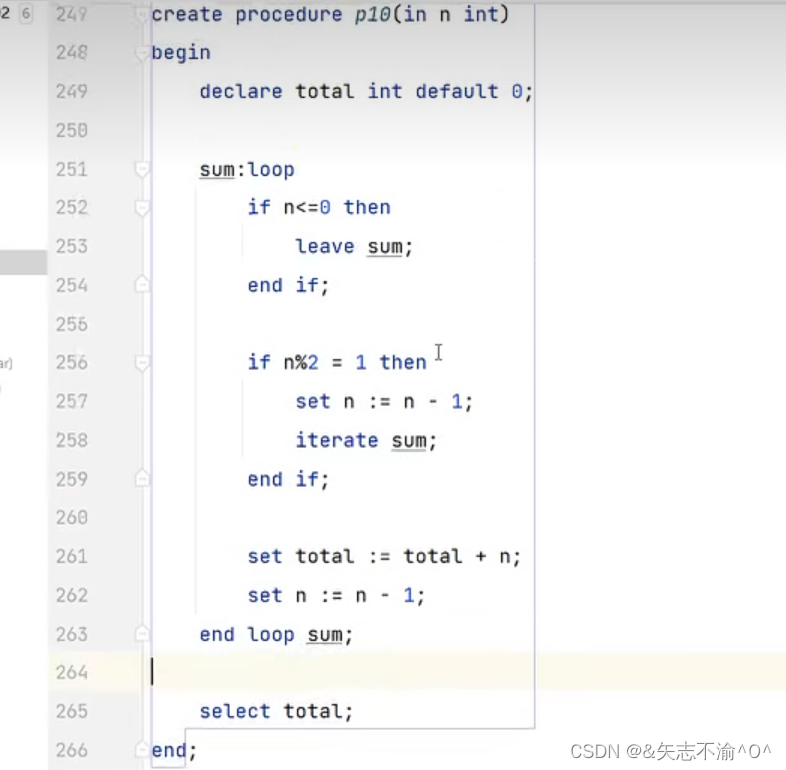
loop循环:

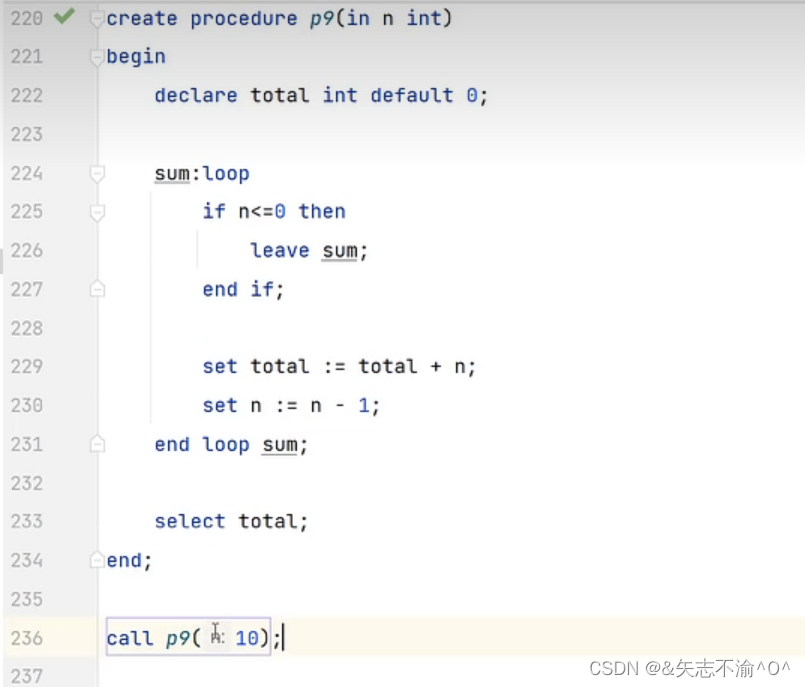
sum:就是我们自己定义的标签。
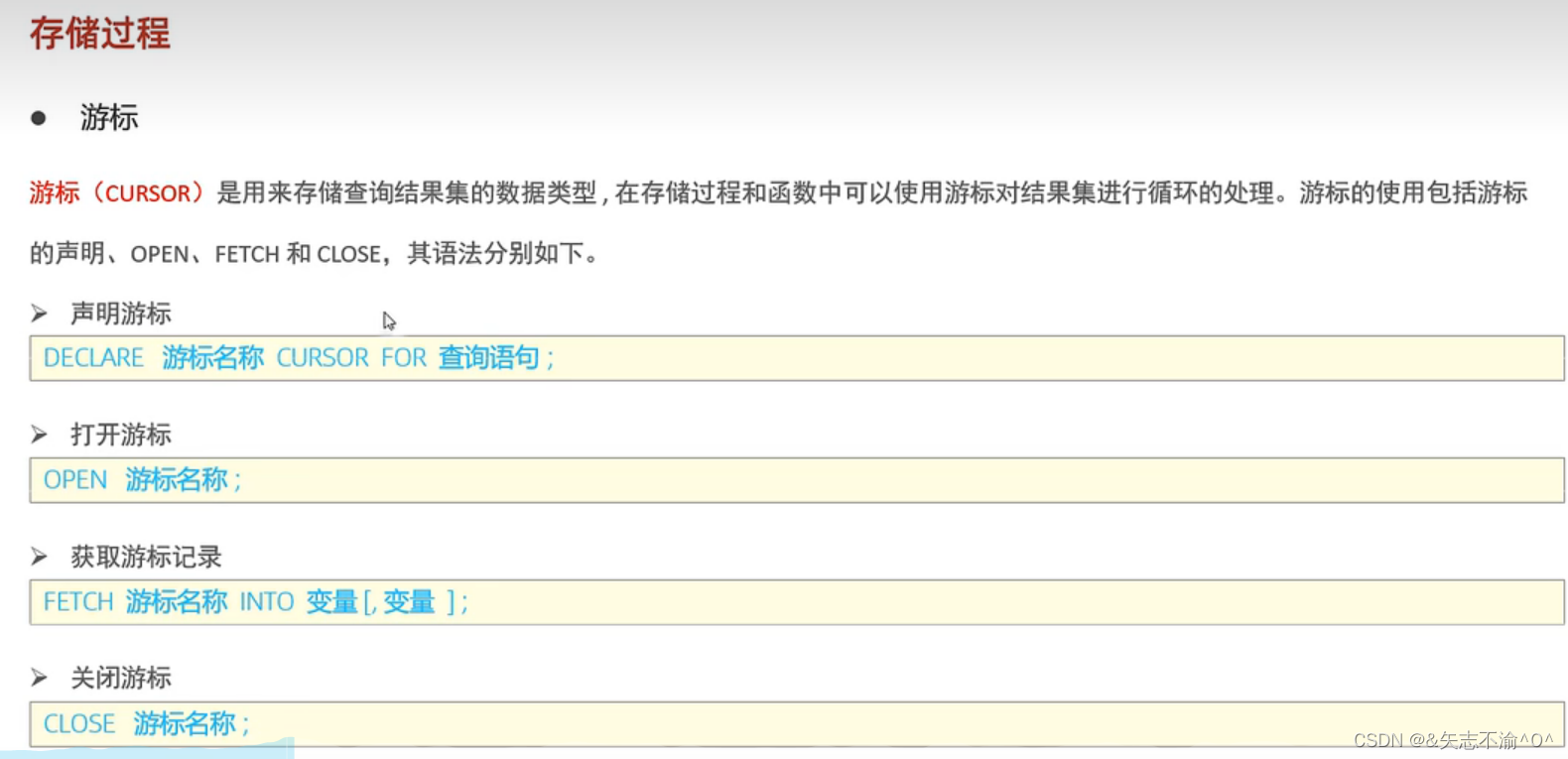
游标:
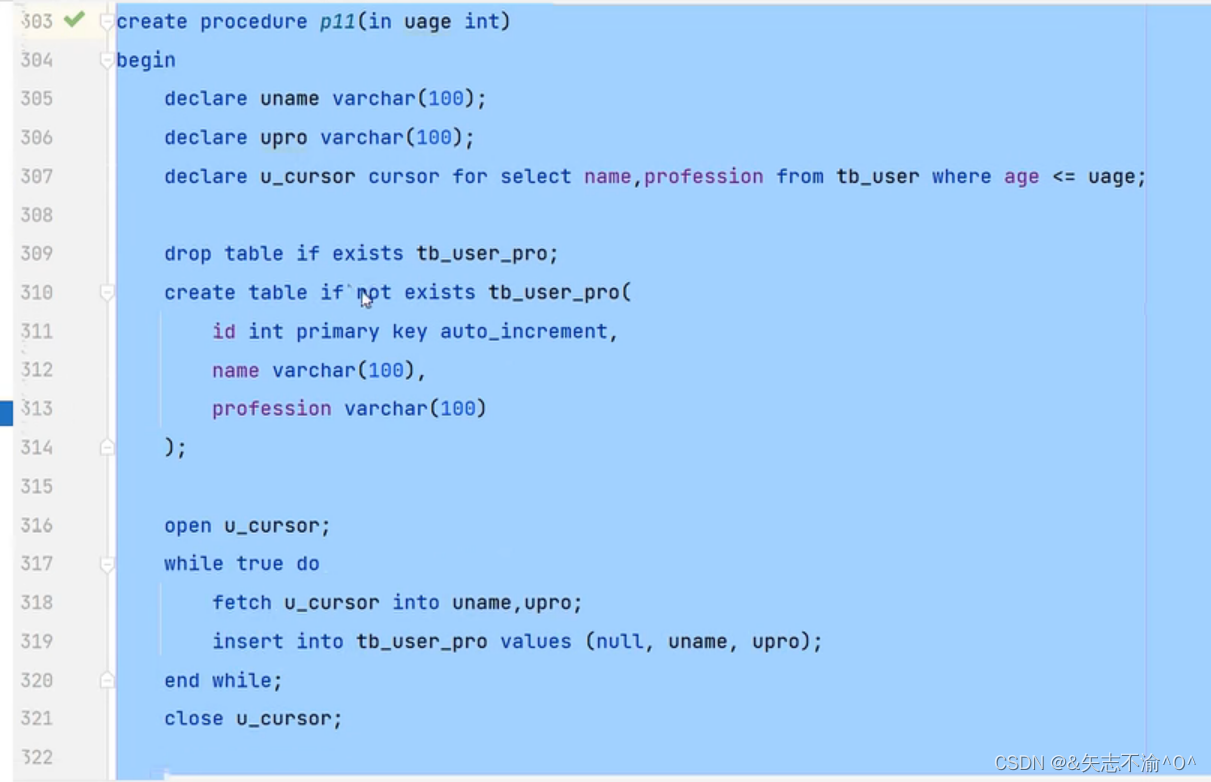
最后的end不要忘了哦

最后结果会发现用call来调用失败,通过查询结果可以发现表tb_user_pro其实已经存在,只不过是循环条件有问题。由此引出下面的条件引出程序:
条件处理程序:


在声明游标下面加上这一句定义,但出现02000报错的时候就退出并关闭游标。这样调用call就可以使用了。这种是使用状态码的方法
同样可以结合上图,把SQLSTATE ‘02000’改变为NOT FOUND等。
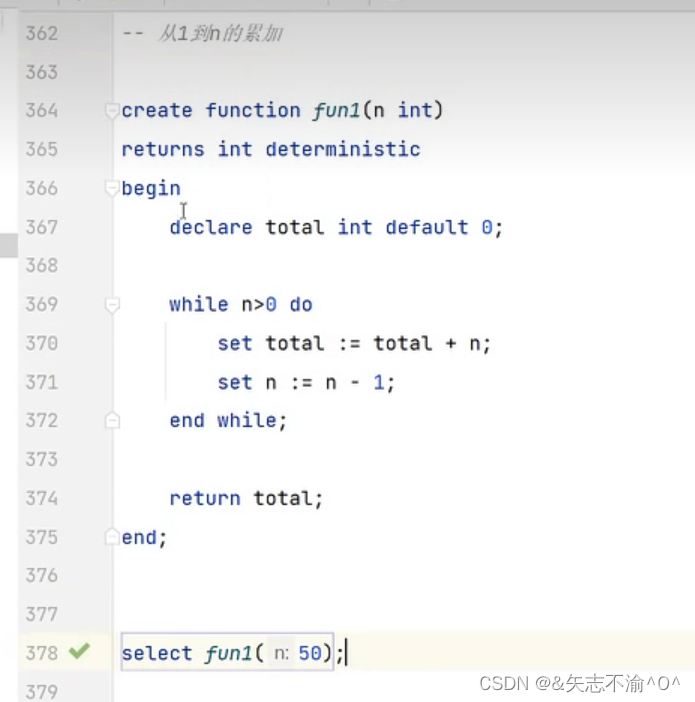
存储函数:

有关MySQL进阶之SQL优化、视图、存储过程的内容就分享到这了。
-
相关阅读:
《第一行代码Andorid》阅读笔记-第一章
C++ 异常处理 重新throw变量时的事件
Dubbo之参数配置(一)
MFC-TCP网络编程客户端-Socket
判断素数/质数的快速算法
【Python Web】Flask框架(九)前端+python+MYSQL案例
Spring Boot实现热部署有哪几种方式
【Azure API 管理】解决API Management添加AAD Group时遇见的 Failed to query Azure Active Directory graph due to error 错误
FineReport----报表模板入门
【Spring篇】Bean的三种配置和实例化方法
- 原文地址:https://blog.csdn.net/m0_63932570/article/details/127333960