-
Fast semi-supervised learning with anchor graph for large
基于锚图的大型高光谱图像快速半监督学习
摘要
由于高光谱图像(HSI)的标记样本非常稀少,并且标记样本花费太多时间和昂贵,半监督学习(SSL)在高光谱图像分类中有着重要的应用。大多数GSSL方法仍然不能处理大的HSI,因为它们的计算复杂度很高。提出了一种新的方法,称为带锚图的快速半监督学习(FSSLAG)来解决大规模HSI分类问题。在提出的FSSLAG算法中,首先构造了无参数、自然稀疏和尺度不变的锚图。然后可以通过图表推断样本的标签。FSSLAG的计算复杂度可以降低到O(ndm),这与需要O(n3)的传统基于图的SSL方法相比是一个显著的改进
介绍
HSI分类模型可分为监督分类,无监督分类和半监督分类[6]。监督分类通过标记样本训练模型,并使用其推断未标记样本的标记[5,6,14,22,29]。训练数据越多,分类效果越好。然而,HSI数据量巨大,标记大量训练数据需要大量时间和人力[28]。相反,无监督方法不需要任何标记数据来分割共相关组中的图像[10,17],而无法产生最佳分类结果[3,18]。因此,半监督学习方法通过有效利用有限的标记数据和大量的未标记数据构建预测模型,将标记从少量标记样本传播到大量未知数据,可以缓解上述问题。
在GSSL(基于图的Gssl)模型中,首先通过将所有样本视为顶点,将数据点之间的成对相似性视为边来构造无向加权图。然后,通过图[23]将标记数据的标记信息传播到未标记数据。
算法
记数据矩阵 X = [ x 1 , … , x l , x l + 1 , … , x n ] T ∈ R n × d X=[x_1,\dots,x_l,x_{l+1},\dots,x_n]^T∈ R^{n×d} X=[x1,…,xl,xl+1,…,xn]T∈Rn×d,其中n是数据的数量,d是维度, x 1 , … , x l {x_1,…,x_l} x1,…,xl是第一个l标记数据的集合。n个数据点对应于图G=(V,E)中的顶点V,其中E是一组边,每个边表示一对顶点的相似关系。x i和x j之间的边的权重定义为w ij,w={w i j}∈ ×n,∀ i、 j中∈ 1…n表示亲和图的相似性矩阵。
设 C = { 1 , … , C } C={1,…,C} C={1,…,C}表示一个标记类集,这意味着前 l l l点 x i ( i ≤ l ) x_i(i≤ l) xi(i≤l)标记为y i∈ C,剩余的t点 x l + 1 , … , x n {x_{l+1},…,x_n} xl+1,…,xn是未标记的,这里n=l+t,通常是l<
Y = [ Y 1 T , … , Y n T ] ∈ R n × c Y=[Y_1^T,…,Y_n^T]∈ R^{n×c} Y=[Y1T,…,YnT]∈Rn×c,其中 Y i T ∈ R c ( 1 ≤ i ≤ n ) Y_ i^T∈ R^c (1≤ i≤ n) YiT∈Rc(1≤i≤n)。对于标记数据,如果x i标记为j,则Y i j=1,否则Y i j=0。对于未标记数据,Y i j=0。设 F = [ F 1 T , … , F n T ] T ∈ R n × c F=[F_1^T,\dots,F_n^T]^T∈ R^{n×c} F=[F1T,…,FnT]T∈Rn×c是软标记矩阵,其中 F i T ∈ R c ( 1 ≤ i ≤ n ) F_i^T∈ R^c(1≤ i≤ n) FiT∈Rc(1≤i≤n)和F i中的每个元素 F i ∈ [ 0 , 1 ] F_i∈ [0, 1] Fi∈[0,1] 锚图构造


亲和矩阵 W = Z Λ − 1 Z T W=Z \Lambda ^{-1} Z^T W=ZΛ−1ZT Λ ∈ R m × m , \Lambda \in R^ {m \times m}, Λ∈Rm×m,是对角矩阵 每个元素是z的列向量
基于锚图的快速半监督学习
半监督学习的目标函数可以是:

∥ M ∥ F 2 = t r ( M T M ) \lVert M \rVert_F^2 = tr(M^TM) ∥M∥F2=tr(MTM)
第一项是平滑项,用于测量图上结果标签的平滑度,这意味着函数应使相邻点具有相似的语义标签。
第二项是一个拟合项,用于测量结果标签和初始标签分配之间的差异,这意味着一个好的分类函数不应在它们上发生太多变化。这两个竞争约束之间的权衡由u i控制,其中u i>0是第i个数据点x i的正则化参数。
简化上述式子:

其中U是对角矩阵,其中第i个条目是U i。L=D− W是拉普拉斯矩阵,度矩阵 D ∈ R n × n D∈R^{n \times n} D∈Rn×n是对角矩阵,其中第i个对角元素是w矩阵的每行和。W是一个双随机矩阵,并且是自动归一化的,因此度矩阵D=I和拉普拉斯矩阵L=I− w,其中I是单位矩阵。此外,W可以写成W=BB T,其中 B = Z Λ − 1 / 2 B=Z \Lambda^{-1/2} B=ZΛ−1/2.

最终的解可以从等式(7)求出为:

公式: ( A − U C V ) − 1 = A − 1 + A − 1 U ( C − 1 − V A − 1 U ) − 1 V A − 1 (A − U CV )^{−1} = A^{-1} + A^{-1} U (C^{-1} − V A ^{-1}U )^{-1} V A^{-1} (A−UCV)−1=A−1+A−1U(C−1−VA−1U)−1VA−1
定义 I a = ( I + U ) − 1 I_a=(I+U)^{-1} Ia=(I+U)−1,其中Ia是一个n×n对角矩阵,第i项为 a i = 1 1 + u i a_i = \frac{1}{1+u_i} ai=1+ui1, I β = I − I a I_β=I−I_a Iβ=I−Ia。最后的解决方案可以简化为
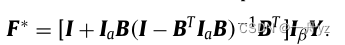

推导:

一旦我们获得了软标记矩阵F∗, 数据点x i的标签被指定为:
y i = a r g m a x j ≤ c F i j ∗ y_i= argmax_{j \leq c} F_{ij}^* yi=argmaxj≤cFij∗

-
相关阅读:
构建mono-repo风格的脚手架库
数值法求解最优控制问题(一)——梯度法
通达信l2行情接口怎么用?
gitlab上传文件
列的完整性约束——调整列的完整性约束
设计模式-工厂设计模式
qpoases解MPC控制
Qt 继承QAbstractListModel实现自定义ListModel
【前端】使用tesseract插件识别提取图片中的文字
总结一下vue中v-bind的常见用法
- 原文地址:https://blog.csdn.net/qq_45178685/article/details/127454913