-
Web服务无法响应但本地业务正常的故障排查记录
1. 问题背景描述
现场反馈我们的设备存在不定时的情况下,会出现Web服务
无法正常访问的情况。经过简单的现场排查,发现了呈现以下特点:a. 重启设备后,无法正常访问的情况能够解除。
b. 在出现问题的时候,设备本身的与WEB无关的业务是能够正常运行的.
c. 在出现问题的时候,有时候只是WEB服务无法访问,有时候所有通过私有协议交互端口均无法访问。
d. 在出现问题的时候,即便是有时候所有通过私有协议交互端口均无法访问的场景,过很长时间后,通过配置工具的连接还是能够恢复正常的,但WEB服务只要坏过就无法恢复了。2. 问题排查和分析
现场出现问题的时候,采用的数据流架构是如下图所示:
根据现场反馈,出问题的时候,有时候是WEB服务无法访问,有时候所有通过业务端口的访问均不能起效,但主控逻辑业务不受到影响。可能出现问题的情况在WEB服务的80端口上,也有可能出现在业务端口28234端口上。问题应该基本都仅仅只在于通信线程出现了异常导致通信线程阻塞或者异常停止运行,所以对通信以外的事情并不会产生影响。
3. 远程现场一探究竟
在现场设备出问题的时候,最开始现场同事每次去都是将设备网线直连到电脑上,后续
netstat的情况一切正常,所以我们认为可能问题的点,可能是在程序其他地方,在某种异常的情况下,会将通信线程弄死,但并不会有netstat痕迹。但这种情况,我们并没有好的思路继续走下去。后续当我们提到想测试一下现场设备的网络环境的时候,现场同事将设备网线接上,并且将电脑通过网线直接接到同一个路由后,过了一阵子设备故障再次出现的时候,
netstat出现了明显的问题。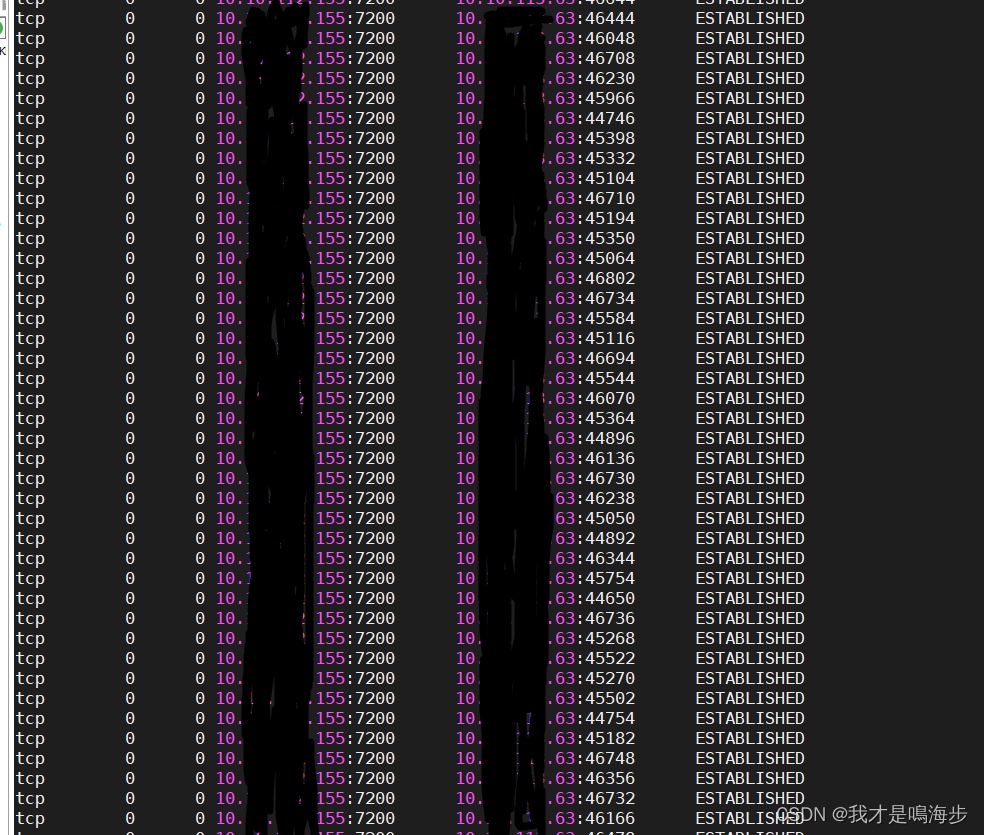
图中(
10.x.x.155)是我们的设备,10.x.x.63是另外一个其他的设备,而正常情况下,另外的设备和我们设备之间的TCP连接应该在10个以内,但现场的环境下,竟然有900+条建立成功的连接。3.1 回想为什么拔掉网线是好的
网线拔掉后,系统层可以接到网线断开的信号,从而通知应用将建立好的连接进行关闭。所以为什么之前每次让现场排查问题的时候,拔掉网线直连设备看上去什么问题都没有,因为拔掉网线这件事本身破坏了现场网络的环境。
但即便是现场这样的操作,在重新插回网线到设备上后,设备之前出现的故障并不会恢复,必须要重启设备后,才能恢复。从这个反馈的现象上看来,设备程序多少还是有一些问题存在的。
4. 关键信息的现象分析
根据这个比较明显的超量连接进入设备的原因,比较容易理解这可以等效是一个DDOS攻击
Distributed Denial of Service。而比较明显的900+的连接数,而且均是ESTABLISHED。让人不禁想到了我们设备最大能同时打开的设备节点数,马上查阅了一下对应节点,结果似乎吻合了起来。# ulimit -a -f: file size (blocks) unlimited -t: cpu time (seconds) unlimited -d: data seg size (kb) unlimited -s: stack size (kb) 8192 -c: core file size (blocks) 0 -m: resident set size (kb) unlimited -l: locked memory (kb) 64 -p: processes 1267 -n: file descriptors 1024 -v: address space (kb) unlimited -w: locks unlimited -e: scheduling priority 0 -r: real-time priority 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这里我们关注到,这个fd限制是1024,算上设备本身就会使用的一些其他非网络节点,这里很明显是触及到设备最大能够打开的fd上限了。
-n: file descriptors 1024
但奇怪的点,在于即便是达到了上限,为什么连接关闭后(也就是现场拔掉了网线之后又重新插上网线后),该不行的,还是不行呢?这就不是一个简单的1024达到上限能够解释的问题了。
4.1 结合现场问题环境本地复现
在本地自行制造DOS攻击的环境后,发现也会出现同样的问题。通过查阅代码后,发现原来是这样一段代码涉及
std标准库的出现了问题。我们使用了一个C++11的随机数生成器类 std::random_device,去生成一些随机数当做连接的key。
void generate_key() { std::random_device rd; unsigned int random = 0; int i = 0; do { random = rd(); key.append((const char *)&random, sizeof(random)); i += sizeof(random); } while (i < 1024); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这段看上去人畜无害的代码里,却出现了一个很低级的问题,我们忽略了这个类是会抛异常的。
仔细查看了cplusplus的解释后,发现了这样一段话。
Construct random device
Constructs a random_device object.
If the random_device cannot be initialized, an exception derived from the standard exception class is thrown.原来这个类是会抛异常的,但一个随机数生成器是怎么抛异常的呢,为什么会和fd达到上限的时候有关呢?
原来构造函数里也解释的很清楚了:
token
An identifier of a system-specific source of randomness.
The default value is a valid source for the system.
For example, on some implementations for linux systems, this parameter is interpreted as a filesystem path, and has a default value of “/dev/urandom”.
string is a standard instantiation of basic_string.原来标准库也是打开了随机数生成器的设备节点,然后进行操作。那么接下来的一切就非常明了了,在fd达到上限的时候,
random_devcie构造函数无法正常打开随机数生成器,所以抛出了异常了。由于我们的通信线程使用的架构是,ASIO的单线程的IO复用方式,通信采用的是函数自递归方式实现持续交互,所以当某个通信的session异常后,这个session后续的交互就会停止了。但由于我们在最外成增加了异常捕获,所以即便某个session出现异常后,后续session只要能再连入,并不会对业务造成影响。
4.2 为什么现场WEB服务坏了就没办法再好
回顾一下架构图,这里 我们平常的内部WEB服务和主控业务代码是通过内部SDK连接的,这个SDK是自带重连功能的,但在服务端抛出异常的时候,实际上虽然这个session本身异常了,但这条TCP连接并不会损坏,在客户端(WEB服务程序)看来,只是对端不回复消息了,所以这个重连机制并不会因为这种不回复消息而产生重连,仅会继续等待对端回复消息,因为连接本身没有异常,还是ESTABLISHED的。
而退一步说,正常情况下,最开始我们发现的异常点,仅会在SDK首次登陆的设备的时候触发,奇怪点在于设备主控和WEB服务在上电后,就会建立连接,那么理论上建立好连接后,就不会再触发这个问题。
只是让我们没想到的是,在网页登陆验证密码的过程中,我们又用了同样的
std::random_device。这下,现场所有的现象均能够得到解释了。
4.3 完成故障流程分析
整体故障流程源于这样的过程。
a. 设备除了业务端口28234外,还监听另一个业务端口7200。
b. 现场使用7200端口的设备,对我们设备进行了DDos攻击,导致设备所有fd达到上限,无法再开打新的节点。
c. 打开网页和配置工具连入设备,需要使用80或者28234端口进行socket连接,但这个时候达到上限后无法连入,在碰巧连入后,也会因为通信线程中埋入的异常,造成session假死。
d. 在达到上限的时候,进行新的网页登陆,会造成WEB服务的session触发主控对应session的random_device异常,导致这条连接虽然不响应WEB消息,但还是建立成功的,SDK重连机制由于连接未断开,而无法触发断线重连。5. 本问题的处理方式以及后续需要注意的要点
这个问题的解决方式很直接,所有异常都应该被妥善的try catch处理好,但同样有几个点,值得我们进一步反思和回想。
a. SDK的重连机制,仅仅在断线的时候才会触发。SDK并没有做业务层心跳,导致TCP层没死但实际上对端不回复消息的时候,并不能有效的及时进行重连,这是一个机制层面的漏洞。
b. 现场处理网络相关问题的时候,应该尽量不要破坏现场的网络环境。
c. 任何一个非自己开发的类,均需要万分确认,这个类是否会抛出异常,以及什么时候会抛出异常。
d. 所有的异常均应该妥善处理。
-
相关阅读:
React源码分析3-render阶段(穿插scheduler和reconciler)
-找树根-
第三章——MySQL数据管理
《Effective Objective-C 2.0》读书笔记——对象、消息、运行期
P1095 [NOIP2007 普及组] 守望者的逃离
【机器学习】使用scikitLearn进行决策树分类与回归:DecisionTreeClassifier及DecisionTreeRegressor
C++11新特性(一)
SAE J1939协议
【无标题】
商标注册初审公告后可以使用吗?
- 原文地址:https://blog.csdn.net/aiyanzielf/article/details/127454805