-
Databend 存储架构总览
目的
通过本篇文章带大家理解一下 Databend 的存储结构。Databend 内置的 Table 引擎为 Fuse table engine ,也是接下来要花重点篇幅要讲的。
另外,Databend 还支持外置的 Hive table 及 Icebreg Table ( 即将到来)。Fuse table 是 Databend 直接把数据存储到 S3 类对象存储上,从而让用户达到一个按需付费,无须关注存储的高可用及扩容,副本这些问题。
Hive Table 是利用 Databend 替换 Hive 的查询能力,从而减少 Hive 计算节点,起到降本增效的效果(该功能已经使用)。
Iceberg Table 正在规划中 https://github.com/datafuselabs/databend/issues/8216
Fuse Table Engine 基础概念
在 Fuse Table 中有一些基础概念先做一个解释方便更想 Databend Fuse Table 的存储结构。
1. 什么是 db_id?
这是 Databend 中的一个 internal 的标识(u64),不是暴露给用户使用,Databend 对于 create database 会在对应的 bucket/[root] 下面创建一个整数命名的目录。
2. 什么是 table_id?
这是 Databend 中的一个 internal 的标识 (u64),不是暴露给用户使用,Databend 对于 create table 会在/bucket/[root]/
/ 创建一个整数命名的目录。 3. Databend 的存 block 文件是什么?
Databend 最终存储 block 是以 Parquet 为格式存储,在存储上以表为单位,文件名为:[UUID].parquet ,存储路径为:/bucket/[root]/
/ /_b/<32 位 16 进制字符串 >_v0.parquet 如:d5ee665801a64a079a8fd2711a71c780_v0.parquet
4. Databend 中 segment 文件是什么?
Databend 中用于组织 Block 的文件。一个 segment 可以多含的 Block 块,文件是 json 格式: /bucket/[root]/
/ /_sg/<32 位 16 进制字符串 >_v1.json 。 如:3b5e1325f68e47b0bd1517ffeb888a36_v1.json
5. Snapshot 是什么?
snapshot 相当于每一个数据的一个版本号 (uuid,32 位 16 进制字符串)。每个写入动作都会有一个唯一的版本号, json 格式,内部包含对应的 segment 文件, /bucket/[root]/
/ /_ss/<32 位 16 进制字符串 >_v1.json。 如:e7ccbdcff8d54ebe9aee85d9fbb3dbcb_v1.json
6. Databend 支持什么索引?
Databend 目前支持三类索引:min/max index, sparse index, bloom filter index 。其中 min/max, sparse index 在 Block 的 parquet 及对应的:ss, segment 中都有存储,bloom fliter 是单独存储为 parquet 文件。
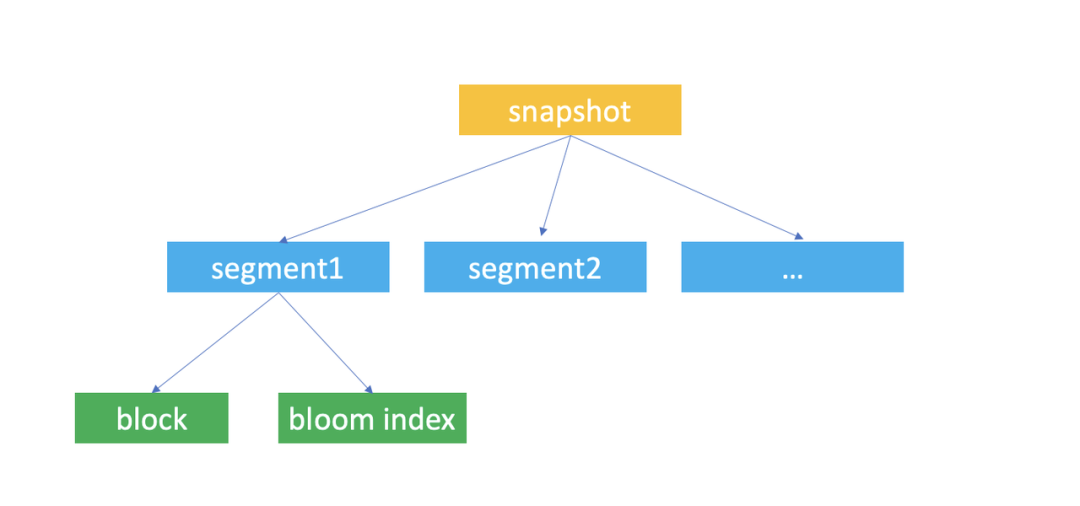
Databend 存储结构 Databend 整体上的存储结构大概如下:
/bucket/[root]/snapshot 下面有 N 多的 segment , 一个 segment 里包含至少一个 block, 最多 1000 个 block 。
存储配置Databend
存储配置
- [storage]
- # fs | s3 | azblob | obs
- type = "s3"
- # To use S3-compatible object storage, uncomment this block and set your values.
- [storage.s3]
- bucket = "testbucket"
- root = "20221012"
- endpoint_url = "url"
- access_key_id = "=user"
- secret_access_key = "mypassword"
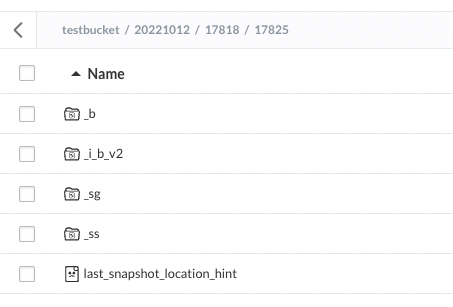
上面这段配置的作用:以 s3 方式把文件存到 testbucket 下面的 20221012 目录, 最终会形成如下的结构:
其中配置中 root 可以省略。
例如:/testbucket/20221012/17818/17825 对应的是 /bucket/root/db_id/table_id 这样一个结构。
table_id 里面每个目录的意义
目录 意义 _b 用于存储数据的真正block, 以parquet 格式存储 _i_b_v2 数据本身的 bloom fliter 索引,以 parquet 格式存储 _sg 全称:segment 用于管理 block 组成,json 文件格式, 一个 sg 文件最少包含一个 block ,最多包含 1000 个 block _ss 全称:snapshot, 用于关联一个版本对应的 segment last_snapshot_location_hint 指向最后一个 snapshot 存储的位置 验证环境
验证1 ss/sg/_b/_i_b_v2 关系
为了分析他们的关系,这里通过一个 create database/ create table / insert 例子来看看他们是怎么生成的。
- create database wubx;
- use wubx;
- create table tb1(id int, c1 varchar);
- insert into tb1 values(1, 'databend');
- show create table tb1;
最后通过 show create table 可以看到:
- CREATE TABLE `tb1` (
- `id` INT,
- `c1` VARCHAR
- ) ENGINE=FUSE SNAPSHOT_LOCATION='17818/17825/_ss/e7ccbdcff8d54ebe9aee85d9fbb3dbcb_v1.json'
这里可以看到:
- wubx 的 db_id 是:17818
- tb1 的 table_id 是:17825
- 对应的第一个 snapshot 文件是:17818/17825/_ss/e7ccbdcff8d54ebe9aee85d9fbb3dbcb_v1.json
1.查询对应的 snapshot
- MySQL [wubx]> select snapshot_id, snapshot_location from fuse_snapshot('wubx','tb1')\G;
- *************************** 1. row ***************************
- snapshot_id: e7ccbdcff8d54ebe9aee85d9fbb3dbcb
- snapshot_location: 17818/17825/_ss/e7ccbdcff8d54ebe9aee85d9fbb3dbcb_v1.json
- 1 row in set (0.005 sec)
2.接下来我们看一下,这个 snapshot 中包含那些 segment:
- MySQL [wubx]> select * from fuse_segment('wubx','tb1', 'e7ccbdcff8d54ebe9aee85d9fbb3dbcb')\G;
- *************************** 1. row ***************************
- file_location: 17818/17825/_sg/3b5e1325f68e47b0bd1517ffeb888a36_v1.json
- format_version: 1
- block_count: 1
- row_count: 1
- bytes_uncompressed: 28
- bytes_compressed: 296
- 1 row in set (0.006 sec)
从这个查询中可以看到 snapshot: e7ccbdcff8d54ebe9aee85d9fbb3dbcb 只包含一个 segment: 17818/17825/_sg/3b5e1325f68e47b0bd1517ffeb888a36_v1.json, 而这个 segment 只有一个 1 block,这个 Block 只有 1 行数据。对应的 JSON 文件:
- {
- "format_version": 1,
- "blocks": [
- {
- ...
- "location": [
- "17818/17825/_b/d5ee665801a64a079a8fd2711a71c780_v0.parquet",
- 0
- ],
- "bloom_filter_index_location": [
- "17818/17825/_i_b_v2/d5ee665801a64a079a8fd2711a71c780_v2.parquet",
- 2
- ],
- "bloom_filter_index_size": 470,
- "compression": "Lz4Raw"
- }
- ],
- "summary": {
- ...
- }
- }
原始文件较长,有兴趣的可以详细阅读一个原文件。
3.对应的 block 查询
- MySQL [wubx]> select * from fuse_block('wubx','tb1')\G;
- *************************** 1. row ***************************
- snapshot_id: e7ccbdcff8d54ebe9aee85d9fbb3dbcb
- timestamp: 2022-10-14 06:53:55.147359
- block_location: 17818/17825/_b/d5ee665801a64a079a8fd2711a71c780_v0.parquet
- block_size: 28
- bloom_filter_location: 17818/17825/_i_b_v2/d5ee665801a64a079a8fd2711a71c780_v2.parquet
- bloom_filter_size: 470
- 1 row in set (0.006 sec)
验证1 总结:
- 任何一次写入都会生成对应的 snapshot (用于 time travel )
- 生成的 block 会被 Segment 引用,一个写入产生的 block 数量在小于 1000 个的情况下都会属于一个 segment 中,如果超过 1000 个 block 会生成多个 segement (这个操作太大了,就不证明了)
- 如果上面情况,一次 insert 也会生成:一个 snapshot , 一个 segment ,一个 block,一个 bloom fliter block
基于上面的原理:
对于 Databend 写入推荐使用批量写入,不推荐单条的 insert 做生成中的数据生成。在 Databend 海量数据写入推荐使用 copy into,streaming_load ,clickhouse http handler 这三种方法, 其中前两种吞吐能力最好。
验证2 理解 snapshot
多次重复制执行:Insert into tb1 select * from tb1;共执行 10 次,加上原来 1 次,总共会形成 11 个 snapshot:

接下来看 tb1 的 snapshot 指向:17818/17825/_ss/5a0ba62a222441d3acd2d93549e46d82_v1.json
- show create table tb1;
- CREATE TABLE `tb1` (
- `id` INT,
- `c1` VARCHAR
- ) ENGINE=FUSE SNAPSHOT_LOCATION='17818/17825/_ss/5a0ba62a222441d3acd2d93549e46d82_v1.json'
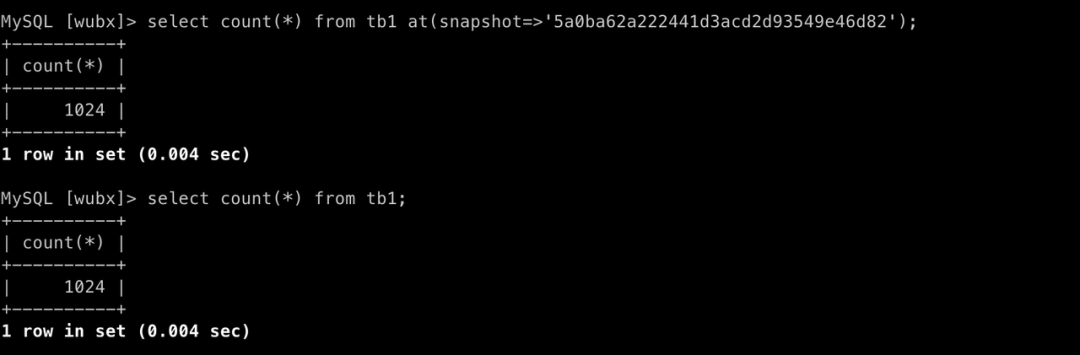
Q1:snapshot 主要用来做什么?
Databend 基于 snapshot 获取相应版本的数据,Databend 也是基于 snapshot 实现事务的 RR 隔离级别。
例如:Select count(*) from tb1;相当于:select count(*) from tb1 at(snapshot=>'5a0ba62a222441d3acd2d93549e46d82');
这个 at 语句是 time travel 的一个特性,对于 time travel 可以参考:https://databend.rs/doc/reference/sql/query-syntax/dml-at#obtaining-snapshot-id-and-timestamp
Q2:snapshot 是否可以被清理?
可以的。
清理 snapshot 命令:optimize table tb1; 或是 optimize table tb1 purge;
- MySQL [wubx]> optimize table tb1;
- Query OK, 0 rows affected (0.013 sec)
- MySQL [wubx]> select snapshot_id, snapshot_location from fuse_snapshot('wubx','tb1');
- +----------------------------------+----------------------------------------------------------+
- | snapshot_id | snapshot_location |
- +----------------------------------+----------------------------------------------------------+
- | 5a0ba62a222441d3acd2d93549e46d82 | 17818/17825/_ss/5a0ba62a222441d3acd2d93549e46d82_v1.json |
- +----------------------------------+----------------------------------------------------------+
- 1 row in set (0.005 sec)
但清理后,time travel 功能需要针对后面的数据才能生效,前面的 time travel 数据已经丢掉。
Q3:是否可以创建一个不带 time travel 的表?
可以的。
Databend 支持:CREATE TRANSIENT TABLE .. 创建的表
参考:https://databend.rs/doc/reference/sql/ddl/table/ddl-create-table#create-transient-table-
该方式创建的表存在一个缺点:在高并发写入读取中,容易造成正在读取的 snapshot 被回收及报错的问题。
存储优化Tips
Q1:大量小的 block 文件,是不是可以进行合并?
可以合并的。
目前需要用户进行手工触发。
optimize table tbname compact;这个命令的作用:
- 把原有的 block 块 max_threads 进行并发合并,生成一份最佳的 Block size 文件列表每个
- thread 任务对应一个 segment 文件,超过 1000 个 block 会生成多个 segment
- 最终生成一个 snapshot 文件
经过 Compact 的最佳的 Block 块,后续在运行 compact 动作会直接跳过。
Q2: 什么时间决定需要运行 tb 的 compact?
目前 Databend 对于 Block 判定要执行 compact 的条件:
- 单个 block 块里行数少于 80 万行且block 小于 100M会进行合并
- 单个 block 块超过 100万行,block 会被拆分。
可以用一个简单的条件来判断
a. Block 数量大于 max_threads* 4 倍
select count(*) from fuse_block('db','tb');b.表里block 数据少于 100M 且行数低于80万的数量超过 100 个
select if(count(*)>100,'你需要运行compact','你的block大小非常合理') from fuse_block('db','tb') where file_size <100*1024*1024 and row_count<800000;Q3: 当出现大量的 segment 文件,是不是需要对 segment 文件合并?
是的。
对于 segment 合并也可以引入一条简单的规则
select count(*),avg(block_count),if(avg(block_count)<500,'need compact segment','segment file is ok') from fuse_segment('db','tb','snapshot_id');如果 segment 总数超过 1000 ,而且每个 segment 平均 block 数小于 500 需要运行:
optimize table tb compact segment;对于频繁写入的场景建议定期运行一下 compact segment ,这样来压缩一下 ss 及对 segemnt 文件的大小,方便 meta 信息进行缓存。
Q4:进行合并操作后文件占用空间比较大,如何释放?
Databend 是一个多版本及支持 Time travel 特性的云数仓,随着历史增长,会出现挺多的版本数据,对于存在的历史版本数据可以使用
optimize table table_name purge;现在 purge 动作会把当前的 snapshot 之外的版本全部清理掉,造成 time travel 失效的问题。后续 purge 会支持传入 snapshot 或是时间指定清理到什么位置。
Q5:如何进行 compact 和同时清理过旧的数据 ?
optimize table table_name all;这个命令相当于:optimize table table_name compact; optimize table table_name purge;
Q6:如何真正删除一张表?
Databend 中 Drop table 为了支持 undrop table 不会所表直正删除,如果你需要立即 Drop 一张表建议使用:
drop table table_name all;目前需要删除一个 Database 也面临这样的问题,需要先做表的删除,再删 Database 。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
- Databend 文档:https://databend.rs/
- Twitter:https://twitter.com/Datafuse_Labs
- Slack:https://datafusecloud.slack.com/
- Wechat:Databend
- GitHub :https://github.com/datafuselabs
-
相关阅读:
弹性数据库连接池探活策略调研(一)——HikariCP
python 最快多长时间学完?
相对位置编码之RPR式:《Self-Attention with Relative Position Representations》论文笔记
基于C++的社交应用的数据存储与实现
搞定面试官 - 可以讲一下你平时是如何进行 SQL 性能分析的嘛?
设计模式
七个步骤 从零到servlet第一个hello
工商管理专业的毕业论文怎么选题?
【MySQL】第13章_约束
【Java基础面试十】、何对Integer和Double类型判断相等?
- 原文地址:https://blog.csdn.net/Databend/article/details/127451885
