-
数据库中间件
一.基本概念
1.1 垂直切分
垂直切分包括垂直分表和垂直分库;
垂直分库就是根据业务耦合性,将关联度低的不同表存储在不同的数据库,类似于微服务项目中根据业务创建不同的服务
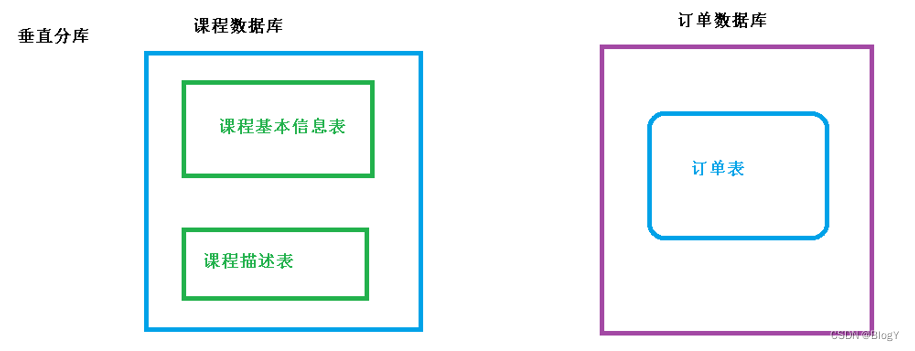
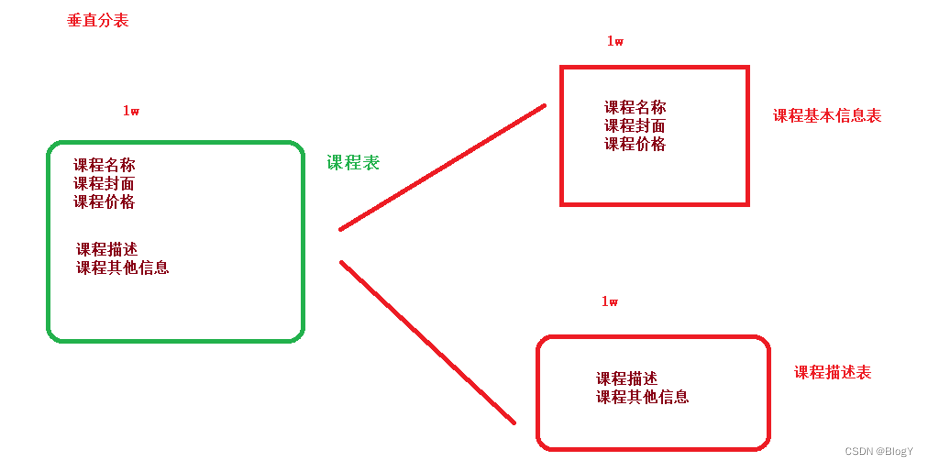
垂直分表是基于数据库中的"列"进行,某个表字段较多,可以新建一张扩展表,将不经常用或字段长度较大的字段拆分出去到扩展表中。
优缺点优点:
1.可根据业务进行拆分
2.便于对不同业务的数据进行管理和维护
3.高并发场景下,垂直切分一定程度的提升IO、数据库连接数、单机硬件资源的瓶颈缺点:
1.部分表无法join,只能通过接口聚合方式解决,提升了开发的复杂度
2.分布式事务处理复杂
3.依然存在单表数据量过大的问题(需要水平切分)1.2 水平切分
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平切分了。
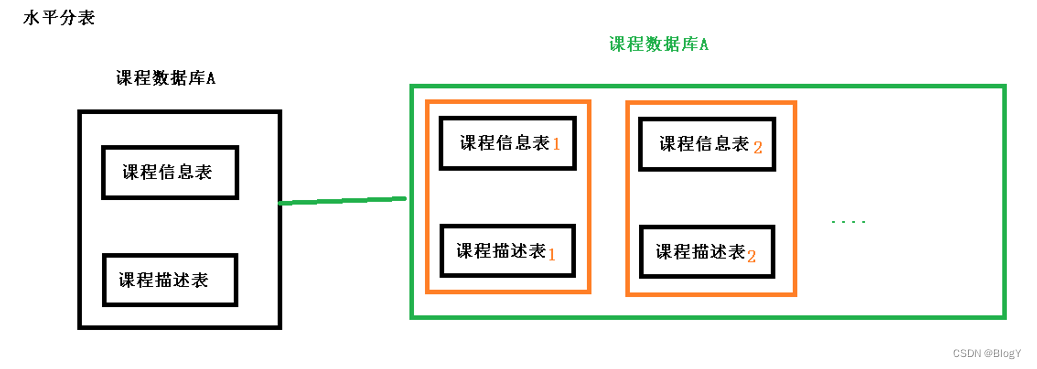
水平切分包括水平分表和水平分库;水平分表
将同一个表按不同的条件分散到多个表中,每个表中只包含一部分数据,从而使得单个表的数据量变小.
库内分表只解决了单一表数据量过大的问题,但没有将表分布到不同机器的库上,因此对于减轻MySQL数据库的压力来说,帮助不是很大,大家还是竞争同一个物理机的CPU、内存、网络IO,最好通过分库分表来解决。
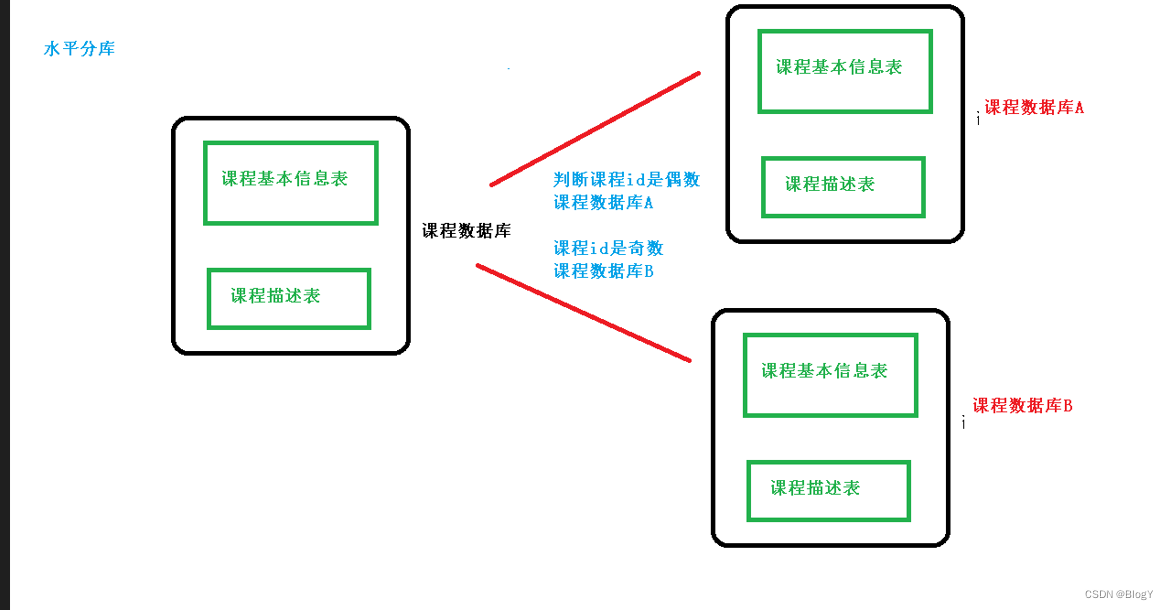
水平分库
优缺点
优点:
1.不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力
2.应用端改造较小,不需要拆分业务模块缺点:
1.跨分片的事务一致性难以保证
2.跨库的join关联查询性能较差
3.数据多次扩展难度和维护量极大1.3 应用
(1)在数据库设计时候考虑垂直分库和垂直分表
(2)随着数据库数据量增加,不要马上考虑做水平切分,首先考虑缓存处理,读写分离,使用索引等等方式,如果这些方式不能根本解决问题了,再考虑做水平分库和水平分表二. ShardingSphere-JDBC读写分离
2.1 一主多从配置
具体配置过程可参考下面文章
binlog格式说明:- binlog_format=STATEMENT:日志记录的是主机数据库的
写指令,性能高,但是now()之类的函数以及获取系统参数的操作会出现主从数据不同步的问题。 - binlog_format=ROW(默认):日志记录的是主机数据库的
写后的数据,批量操作时性能较差,解决now()或者 user()或者 @@hostname 等操作在主从机器上不一致的问题。 - binlog_format=MIXED:是以上两种level的混合使用,有函数用ROW,没函数用STATEMENT,但是无法识别系统变量
binlog-ignore-db和binlog-do-db的优先级问题:
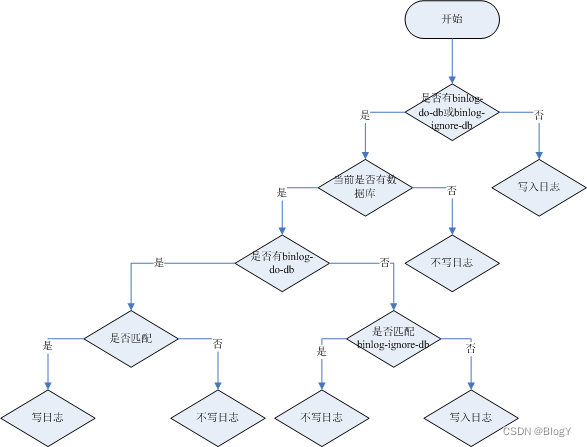
2.2 核心配置
# 应用名称 spring.application.name=sharging-jdbc-demo # 开发环境设置 spring.profiles.active=dev # 内存模式 spring.shardingsphere.mode.type=Memory # 配置真实数据源 spring.shardingsphere.datasource.names=master,slave1,slave2 # 配置第 1 个数据源 spring.shardingsphere.datasource.master.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.master.jdbc-url=jdbc:mysql://192.168.1.110:3307/test?useUnicode=true&characterEncoding=utf8 spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.master.username=root spring.shardingsphere.datasource.master.password=root # 配置第 2 个数据源 spring.shardingsphere.datasource.slave1.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.slave1.jdbc-url=jdbc:mysql://192.168.1.110:3308/test?useUnicode=true&characterEncoding=utf8 spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.slave1.username=root spring.shardingsphere.datasource.slave1.password=root # 配置第 3 个数据源 spring.shardingsphere.datasource.slave2.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.slave2.jdbc-url=jdbc:mysql://192.168.1.110:3309/test?useUnicode=true&characterEncoding=utf8 spring.shardingsphere.datasource.slave2.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.slave2.username=root spring.shardingsphere.datasource.slave2.password=root # 读写分离类型,如: Static,Dynamic spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.type=Static # 写数据源名称 spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.write-data-source-name=master # 读数据源名称,多个从数据源用逗号分隔 spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.read-data-source-names=slave1,slave2 # 负载均衡算法名称 spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.load-balancer-name=alg_round # 负载均衡算法配置 # 负载均衡算法类型 spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_round.type=ROUND_ROBIN spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_random.type=RANDOM spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.type=WEIGHT spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave1=1 spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave2=2 # 打印SQl spring.shardingsphere.props.sql-show=true- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
2.3 事务
为了保证主从库间的事务一致性,避免跨服务的分布式事务,ShardingSphere-JDBC的
主从模型中,事务中的数据读写均用主库。- 不添加@Transactional:insert对主库操作,select对从库操作
- 添加@Transactional:则insert和select均对主库操作
- 注意:在JUnit环境下的@Transactional注解,默认情况下就会对事务进行回滚(即使在没加注解@Rollback,也会对事务回滚)
三.ShardingSphere-JDBC垂直分片
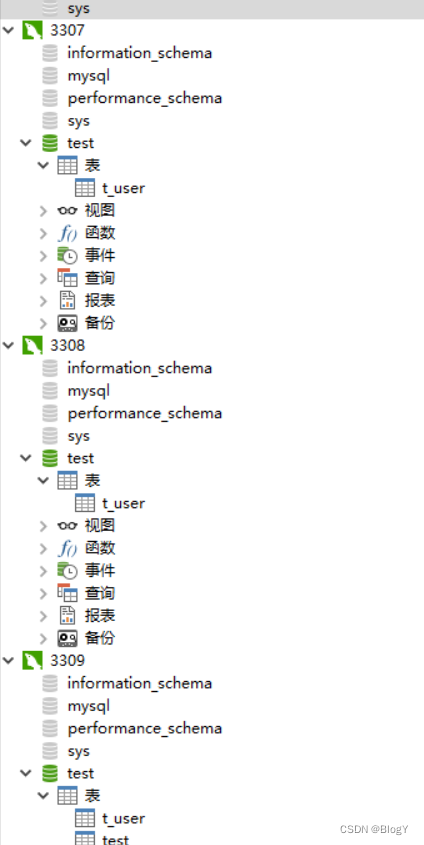
3.1 数据库
3.2 核心配置
# 应用名称 spring.application.name=sharding-jdbc-demo # 环境设置 spring.profiles.active=dev # 配置真实数据源 spring.shardingsphere.datasource.names=user,order # 配置第 1 个数据源 spring.shardingsphere.datasource.user.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.user.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.user.jdbc-url=jdbc:mysql://192.168.1.110:3307/test?useUnicode=true&characterEncoding=utf8 spring.shardingsphere.datasource.user.username=root spring.shardingsphere.datasource.user.password=root # 配置第 2 个数据源 spring.shardingsphere.datasource.order.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.order.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.order.jdbc-url=jdbc:mysql://192.168.1.110:3306/gu?useUnicode=true&characterEncoding=utf8 spring.shardingsphere.datasource.order.username=root spring.shardingsphere.datasource.order.password=root # 标准分片表配置(数据节点) # spring.shardingsphere.rules.sharding.tables.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
3.3 测试
@Test public void testInsertOrderAndUser(){ User user = new User(); user.setUname("强哥"); userMapper.insert(user); Order order = new Order(); order.setMoney("100"); orderMapper.insert(order); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
四.ShardingSphere-JDBC水平分片
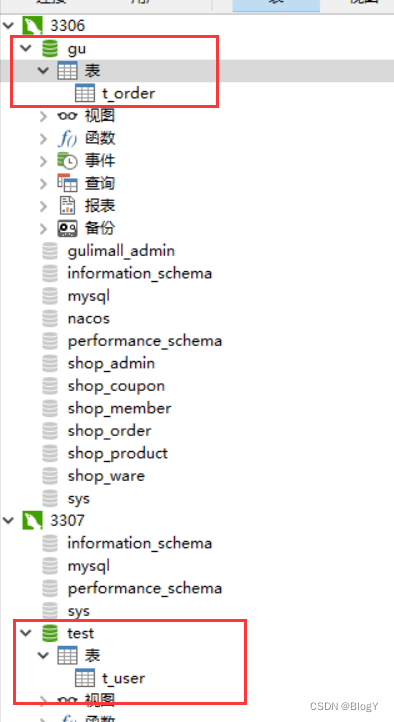
4.1 数据库

注意:水平分片的id需要在业务层实现,不能依赖数据库的主键自增4.2 基本配置
#========================基本配置 # 应用名称 spring.application.name=sharging-jdbc-demo # 开发环境设置 spring.profiles.active=dev # 内存模式 spring.shardingsphere.mode.type=Memory # 打印SQl spring.shardingsphere.props.sql-show=true #========================数据源配置 # 配置真实数据源 spring.shardingsphere.datasource.names=server-user,server-order0,server-order1 # 配置第 1 个数据源 spring.shardingsphere.datasource.server-order0.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.server-order0.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.server-order0.jdbc-url=jdbc:mysql://192.168.1.110:3306/gu?useUnicode=true&characterEncoding=utf8 spring.shardingsphere.datasource.server-order0.username=root spring.shardingsphere.datasource.server-order0.password=root # 配置第 2 个数据源 spring.shardingsphere.datasource.server-order1.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.server-order1.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.server-order1.jdbc-url=jdbc:mysql://192.168.1.110:3307/test?useUnicode=true&characterEncoding=utf8 spring.shardingsphere.datasource.server-order1.username=root spring.shardingsphere.datasource.server-order1.password=root # 配置第 3 个数据源 spring.shardingsphere.datasource.server-user.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.server-user.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.server-user.jdbc-url=jdbc:mysql://192.168.1.110:3308/test?useUnicode=true&characterEncoding=utf8 spring.shardingsphere.datasource.server-user.username=root spring.shardingsphere.datasource.server-user.password=root- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
4.3 标椎分片表配置
#========================标准分片表配置(数据节点配置) # spring.shardingsphere.rules.sharding.tables.- 1
- 2
- 3
- 4
- 5
- 6
- 7
测试:保留上面配置中的一个分片表节点分别进行测试,检查每个分片节点是否可用
/** * 水平分片:插入数据测试 */ /** * 水平分片:插入数据测试 */ @Test public void testInsertOrder(){ Order order = new Order(); order.setMoney("11111"); orderMapper.insert(order); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.4 分片算法配置
#========================标准分片表配置(数据节点配置) # spring.shardingsphere.rules.sharding.tables.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
分库分表测试
/** * 水平分片:分库分表插入数据测试 */ @Test public void testInsertOrderTableStrategy(){ for (long i = 1; i < 5; i++) { Order order = new Order(); order.setMoney("ATGUIGU" + i); order.setUserId(1L); orderMapper.insert(order); } for (long i = 5; i < 9; i++) { Order order = new Order(); order.setMoney("ATGUIGU" + i); order.setUserId(2L); orderMapper.insert(order); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
通过userId(2)取余之后,ATGUIGU5~8分配在server-order0的库,然后通过money列取哈希之后分配在不同的表
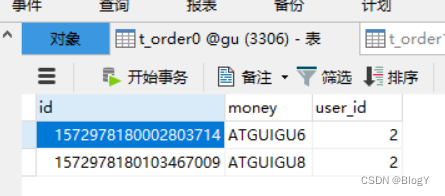
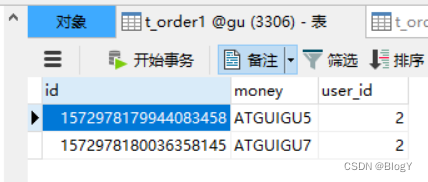
通过userId(1)取余之后,ATGUIGU5~8分配在server-order0的库,然后通过money列取哈希之后分配在不同的表
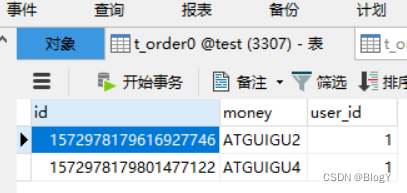
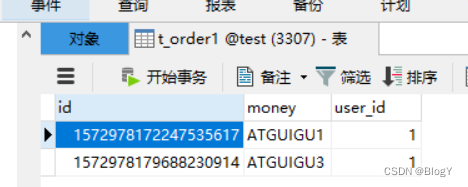
查询测试/** * 水平分片:根据user_id查询记录 * 查询了一个数据源,每个数据源中使用UNION ALL连接两个表 */ @Test public void testShardingSelectByUserId(){ QueryWrapper<Order> orderQueryWrapper = new QueryWrapper<>(); orderQueryWrapper.eq("user_id", 1L).or().eq("user_id", 2L); List<Order> orders = orderMapper.selectList(orderQueryWrapper); orders.forEach(System.out::println); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

4.5 分布式序列算法
雪花算法:
水平分片需要关注全局序列,因为不能简单的使用基于数据库的主键自增。这里有两种方案:一种是基于MyBatisPlus的id策略;一种是ShardingSphere-JDBC的全局序列配置。
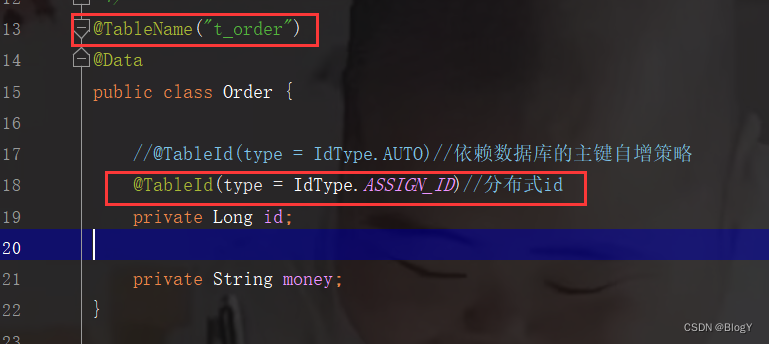
基于MyBatisPlus的id策略:将Order类的id设置成如下形式@TableId(type = IdType.ASSIGN_ID) private Long id;- 1
- 2
基于ShardingSphere-JDBC的全局序列配置:#------------------------分布式序列策略配置 # 分布式序列列名称 spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=id # 分布式序列算法名称 spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=alg_snowflake # 分布式序列算法配置 # 分布式序列算法类型 spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE # 分布式序列算法属性配置 #spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.xxx=- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
此时,需要将实体类中的id策略修改成以下形式:
//当配置了shardingsphere-jdbc的分布式序列时,自动使用shardingsphere-jdbc的分布式序列 //当没有配置shardingsphere-jdbc的分布式序列时,自动依赖数据库的主键自增策略 @TableId(type = IdType.AUTO)- 1
- 2
- 3
4.6 多表关联
创建关联表
在
server-order0、server-order1服务器中分别创建两张订单详情表t_order_item0、t_order_item1我们希望
同一个用户的订单表和订单详情表中的数据都在同一个数据源中,避免跨库关联,因此这两张表我们使用相同的分片策略。那么在
t_order_item中我们也需要创建order_no和user_id这两个分片键CREATE TABLE t_order_item0( id BIGINT, order_no VARCHAR(30), user_id BIGINT, price DECIMAL(10,2), `count` INT, PRIMARY KEY(id) ); CREATE TABLE t_order_item1( id BIGINT, order_no VARCHAR(30), user_id BIGINT, price DECIMAL(10,2), `count` INT, PRIMARY KEY(id) );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- binlog_format=STATEMENT:日志记录的是主机数据库的
-
相关阅读:
ROS1 学习11 坐标系tf 管理系统 简介及demo示例
logback日志级别动态切换的终极方案(Java ASM使用)
python随手小练1
牛客网刷题-括号匹配问题
【融合ChatGPT等AI模型】Python-GEE遥感云大数据分析、管理与可视化及多领域案例实践应用
自媒体视频剪辑中的视频素材是从哪里找的?
html 标签简介
Kotlin协程:协程上下文与上下文元素
闭关之 C++ 并发编程笔记(一):线程与锁
【Stm32-F407】Keil uVision5 的安装
- 原文地址:https://blog.csdn.net/weixin_45081813/article/details/126735752
