-
Python回归预测建模实战-线性回归预测房价
机器学习在预测方面的应用,根据预测值变量的类型可以分为分类问题(预测值是离散型)和回归问题(预测值是连续型),前面我们介绍了机器学习建模处理了分类问题(具体见之前的文章),接下来我们以波斯顿房价数据集为例,做一个回归预测系列的建模文章。
实现功能:
使用sklearn线性回归(LinearRegression)的API对波士顿房价数据集进行预测,并尝试将预测结果进行可视化。
实现代码:
from sklearn.linear_model import LinearRegression from sklearn.datasets import load_boston import pandas as pd import matplotlib.pyplot as plt # 加载数据集 boston=load_boston() df=pd.DataFrame(boston.data,columns=boston.feature_names) df['target']=boston.target #查看数据项 features=df[boston.feature_names] target=df['target'] #数据集划分 split_num=int(len(features)*0.8) X_train=features[:split_num] Y_train=target[:split_num] X_test=features[split_num:] Y_test=target[split_num:] # 线性回归建模预测 clf_lin_reg=LinearRegression().fit(X_train,Y_train) y_lin_reg_pred=clf_lin_reg.predict(X_test) # 可视化部分 plt.rcParams['font.sans-serif']='SimHei' plt.rcParams['axes.unicode_minus']=False plt.rc('font',size=14) # plt.figure(figsize=(15,4)) plt.plot(list(range(0,len(X_test))),Y_test,marker='o') plt.plot(list(range(0,len(X_test))),y_lin_reg_pred,marker='*') plt.legend(['真实值','预测值']) plt.title('Boston房价线性回归预测值与真实值的对比') plt.show()实现效果:
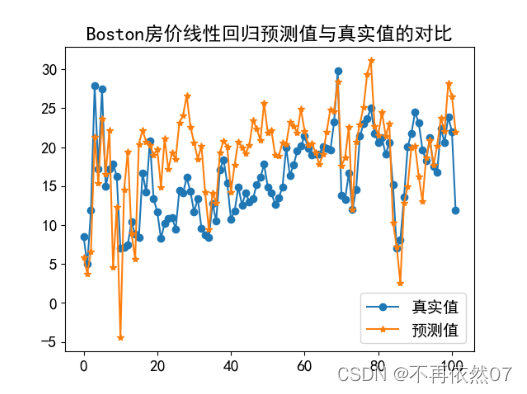
本人读研期间发表5篇SCI数据挖掘相关论文,会不定期分享一些关于python机器学习、深度学习、数据挖掘基础知识与案例,致力于以最简单的方式理解和学习它们,欢迎关注(订阅号:数据杂坛)一起交流讨论。
1、邀请三个朋友关注本订阅号或2、分享/在看任意订阅号的三篇文章
即可在后台联系我获取相关数据集和源码,送有关数据分析、数据挖掘、机器学习、深度学习相关的电子书籍。
-
相关阅读:
高质量床上用品类网站带手机端的pbootcms模板
【剑指Offer】16.数值的整数次方
Docker镜像详解(手拉手教你上传至阿里云,发布到私有库)
人机融合需要在事实与价值之间构建新型的拓扑关系
.net第七章------类成员
Java语言高级-10MySQL-第4节数据库的CRUD操作
【饭谈】写简历,新手最容易犯的一个致命问题
英语单词: truncate;截断警告
SpringCloud Stream消息驱动代码实战
华米Zepp小程序开发入门
- 原文地址:https://blog.csdn.net/sinat_41858359/article/details/127445206