-
Java多关键词分级搜索实现
一、背景
公司修改了上次的多关键词搜索方案,要求输入多个关键词并找到对应的业务路径。比如有一个业务路径为1、2、3、4级分别为 充值缴费->信用卡办理->账单记录->修改账单 ,可以输入1-4个关键词进行搜索,4个级在数据库中属于同一条数据,没有分表。
输入一个关键词,不用考虑路径只要把该级包含有关键词的数据展示出来即可,类似全局模糊查询。输入两个,12、13、14、23、24、34级中找到分别两个关键词时,展示所有查询出的结果——必须至少要有两个级别的八级分类有且只有一个对应的关键词,且关键词不同,录入关键词顺序不影响搜索结果,如搜索关键词"a、b",如果在第1级中有一个选项为a,一个选项为b,两个关键词在同一级别,则不满足查询规则;在第1 级中有a,对应的该子级中有a,也不满足查询规则;如第1级有b,该子集中有a,满足查询规则;如第1级有a,第2级有b(前者子级),第1级有a,第3级有b,则结果呈现12、23两个路径。如第1级有a,第2级有b(前者子级),第3级有b(为2子级或者1子子级),呈现12、13两条路径。
非常麻烦,产品描述都不太清楚,这里记录一下思路。二、涉及的相关知识
java常量池、堆
排列组合思想
分类筛选思想三、本人解决思路
一开始在讨论怎么把所有情况列出来,怎么匹配查询出来的数据和关键词,后面发现排列组合思想可以解决这个问题。比如输入两个关键词A和B,因为有4级路径,所以会出现以下12种情况
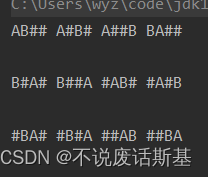
#代表任意字符,属于填充位实现方法为
//一、这里queryItemName为前端传过来的关键词字符数组 String[] array=new String[4]; for (int n=0;n<queryItemName.length;n++){ array[n]=queryItemName[n]; } array[2]="#"; array[3]="#"; List<路径实体类> itemList=new ArrayList<>();//存放篩選后所有符合條件的結果 List<单个各层路径的Name实体类> namesList2=new ArrayList<>();// 放關鍵詞的所有排列情況 SysCallNatureName natureName=new SysCallNatureName(); //二、排列组合核心代码实现 for(int i=0;i<array.length;i++){ for(int j=0;j<array.length;j++){ if(j==i)//除去j==i的情况,下同 continue; for(int k=0;k<array.length;k++){ if(k==j||k==i) continue; for(int h=0;h<array.length;h++){ if(h==k||h==j||h==i) continue; natureName.setItemName4(array[i]); natureName.setItemName5(array[j]); natureName.setItemName6(array[h]); natureName.setItemName7(array[k]); namesList.add(natureName); natureName=new SysCallNatureName(); } } } } //三 namesList2=namesList2.stream().distinct().collect(Collectors.toList());- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
有些小白可能不明白第一部分的意义,这里说明一下,首先String[]数组的长度在创建的时候就定义好了不能更改,所以要新开一个长度为4的字符串数组。array[2]=“#”;和 array[3]=“#”;是为了填充数组,为了下面可以实现A4取2的效果,也就是说这字符串数组2和3的值必须是相同的,重复的。
第三部分呢是去重,如果不去重就会是下面这样,因为2和3两个元素是重复的嘛。这里也很容易发现长度为4的数组A4取4,如果里面有两个元素是重复的,那么去重以后就是A4取2的结果

后面就是一堆筛选了,这里用了双重for循环,将数据库查询出来的数据逐一匹配12中排列组合结果,因为输入的关键词顺序不能影响结果(输入a,b和输入b,a结果一样),所以采用三元运算将数组每个位置的数据都匹配一次,这里的核心思想就是判断两个集合是否相同。
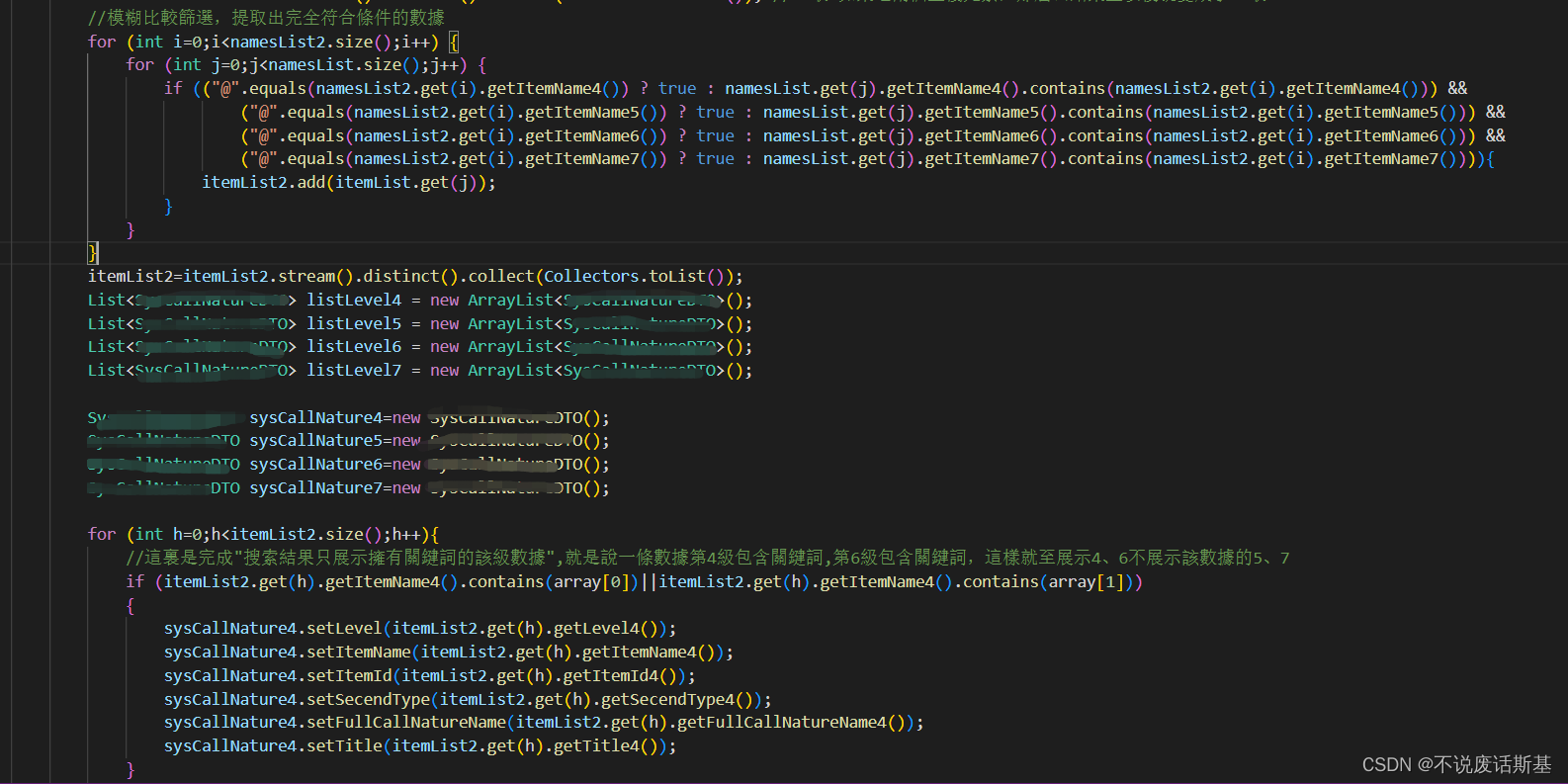
四、坑和解决过程中有趣的东西
①、这里有两个坑,第一个就是三元运算每次结果必须用括号括起来,不加括号会变成
1==1?true:(false&&1==2?true:false)所以结果一直都是true,这个属于是我粗心太菜了

②、第二个坑是地址指向问题。如下图,在往list添加数据之后,不让name地址指向新的实体类的话,在list里面的数据将会全部都是重复的,都是最后一次的排列结果。循环里每次赋值给name都会覆盖掉list里面的name的值,因为他们的地址都是指向同一个Name实体类,list.add的效果就是就是将实体类的地址存储到List集合中嘛。

③、内存溢出以前经常看网上在说,这次自己遇上了。debug了下发现是我有个方法过过滤数据的方法,创建太多对象了,所以出现这个问题。可以通过Java堆可以通过Xmx和Xms两个参数指定最大内存,指定完之后要重启服务。



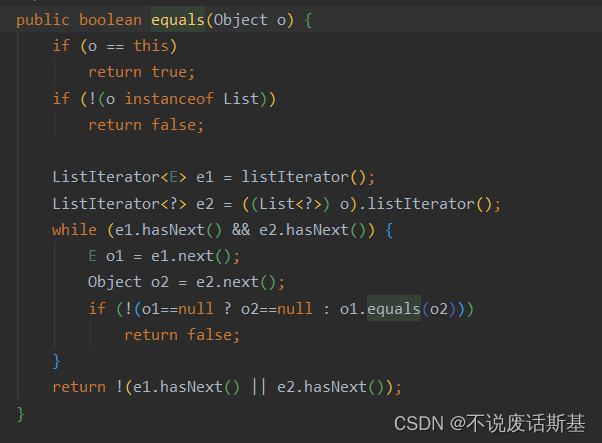
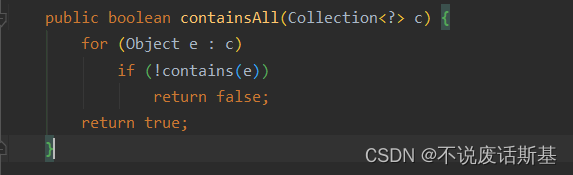
这边的破电脑,分配了内存也没用,最后是通过优化筛选数据解决的。建议用完以后不再用的资源手动释放掉,还有关闭不再用的IO连接等来减少内存消耗,比如System.gc()、xxx.clear(),xxxIo.close()。④当时筛选时想过怎么判断两个list集合是否相同,试了equals和containAll发现equals不仅里面的内容要相同而且顺序也要一致,containAll则只需要内容相同就行。

-
相关阅读:
如何拼接两张图片?
html--宠物
Android 底层新增按键系统上层适配详解
【k8s管理--集群日志管理elk】
面向对象编程(Object-Oriented Programming,OOP)编程思想
elasticsearch10-查询文档处理
关于nacos的配置获取失败及服务发现问题的排坑记录
记录在使用OpenCVSharp在netcore3.1框架下做视觉处理遇到的坑及解决过程
Rainbond插件扩展:基于Mysql-Exporter监控Mysql
python气象科研学习路线和常用技巧
- 原文地址:https://blog.csdn.net/AsFarmer/article/details/127413164
