-
ACM MM 2022 Oral | PRVR: 新的文本到视频跨模态检索子任务

作者: 陈先客
方向: 跨模态检索
学校: 浙江工商大学概览
本文介绍一篇ACM MM 2022 Oral的工作。基于传统的跨模态文本-视频检索(Video-to-Text Retrieval, T2VR)任务,该工作提出了一个全新的文本到视频跨模态检索子任务,即部分相关的视频检索(Partially Relevant Video Retrieval, PRVR)。
PRVR任务旨在从大量未剪辑的长视频中检索出与查询文本部分相关的对应视频。若一个未经剪辑的长视频中存在某一片段与给出的查询文本相关,则认为该长视频与给出的查询文本呈部分相关的关系。
而在传统的T2VR任务中,视频都是预剪辑后的短视频,且通常希望检索得到整个视频与文本查询完全相关。相比之下,PRVR任务更加符合实际应用场景,且更具有挑战性。
作者将PRVR任务视为一个多示例学习的问题,将视频同时视为由多个片段以及视频帧所组成的包。若文本与长视频的某帧或者某个片段相关,则视为文本与该长视频相关。基于此,作者设计了多尺度多示例模型,该模型分别对视频进行片段尺度和帧尺度的特征表示,并引入了以关键片段为向导的注意力聚合方法,模型整体以从粗到细的方式学习文本-视频间的相似度关系。该模型除了在PRVR任务上表现较好之外,也可用于提高视频库片段检索(Video Corpus Moment Retrieval,VCMR)模型的性能。

论文:Partially Relevant Video Retrieval
收录:ACM MM 2022 (Oral Paper)
主页:http://danieljf24.github.io/prvr/
代码:https://github.com/HuiGuanLab/ms-sl
1. 背景与挑战
当前的文本到视频检索(T2VR)方法通常是在面向视频描述生成任务的数据集(如MSVD、MSR-VTT和VATEX)上训练和测试的。这些数据集存在共同的特性,即其包含的视频通常是以较短的持续时间进行预剪辑得到,同时提供的对应文本能充分描述视频内容的要点。因此,在此类数据集中所给出的文本-视频对呈完全相关的关系。
然而在现实的视频检索场景中,由于查询文本是未知的,预先剪辑好的视频可能不包含足够的内容来完全满足查询文本。这表明现阶段在学术研究的T2VR与实际应用存在一定的鸿沟。
如图1所示,上半部分的图取自传统T2VR数据集MSR-VTT,由于视频长度较短,场景单一,所以对应的文本"两个男人在开车的同时进行交谈"能够很好地概括视频的所有内容。而在下半部分取自TV show Retrieval数据集的长视频场景多变,持续时间较长。文本"豪斯使用记号笔在玻璃表面写字"仅能表述视频中的某一片段。在现实世界中的检索场景大多符合后者。
为了弥补这一鸿沟,作者提出了一种新的T2VR子任务——部分相关的视频检索(Partially Relevant Video Retrieval, PRVR)。PRVR任务旨在从大量未剪辑的长视频中检索出与查询文本部分相关的对应视频。若一个未经剪辑的长视频中存在某一片段与给出的查询文本相关,则认为该长视频与给出的查询文本呈部分相关的关系。

图1 传统T2VR任务中文本-视频对的相关关系与现实世界的差别 虽然PRVR任务和传统的T2VR任务的目标均为从视频库中检索出查询文本的对应视频,但在PRVR任务中视频通常比较长,同时文本查询对应的片段在原视频中的时长占比分布较广。如图3所示,在TVR和Charades-STA数据集中,时长占比大多分布在50%以下;Activitynet数据集的占比则在1%-100%之间均有分布。这就代表若简单地将视频表示为单一向量,会大量丢失与查询文本相关的关键信息。同时查询文本在对应长视频的相关时刻起始位置和持续时间都是未知的,需要模型具备在没有时刻标签指导下建模出文本和对应长视频间部分相关关系的能力,所以PRVR任务相较于传统的T2VR任务更具挑战性。
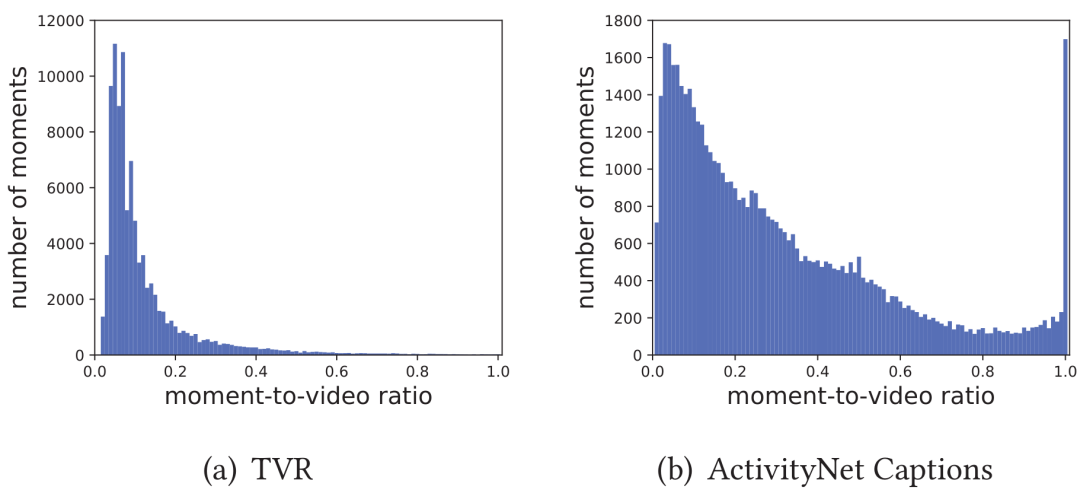
图3 不同数据集中片段时长占比分布 2. 方法
作者将PRVR定义为多示例学习(Multiple Instance Learning, MIL)问题。
多示例学习是弱标注数据学习的经典框架,并被广泛用于分类任务。在多示例学习中,一个样本被视为由大量示例所组成的包,若包中的某一个或多个示例为正样本时,则该包为正样本;反之则该包为负样本。作者将长视频整体视为一个包,视频中的各帧或由不同大小帧组成的片段则被视为不同示例。若文本与长视频的某帧或者某个片段相关,则视为文本与该长视频相关。
此外,由于不同查询文本与长视频的相关时刻持续时长区别较大,所以作者在多个时间尺度进行视频表示,进一步提出了多尺度相似性学习来度量查询文本和长视频间的部分相关性。

图4 模型框架图 2.1 文本特征表示
由于当前模型的重点并不在于文本编码,所以作者使用了一个较为简单且有效的文本编码框架,它也可以被任意当下热门的文本编码框架替代。
具体地,给定一句由个单词所组成的查询文本,使用预训练的RoBERTa模型来提取每个单词的特征向量作为文本的初始特征。之后通过全连接层进行特征降维后,使用一层的标准Transformer模块对其进行进一步编码得到。最终通过注意力模块得到句子级别的特征表示,既:
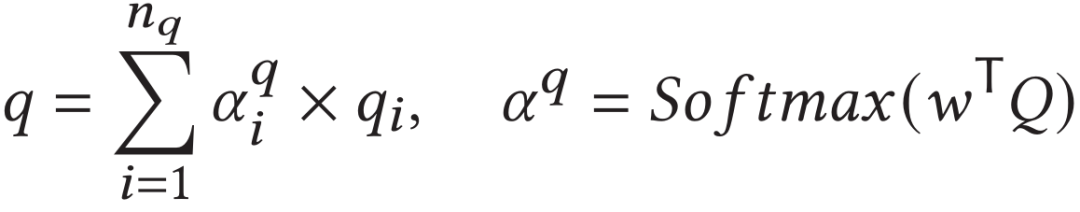
2.2 视频特征表示
对于输入的长视频,首先使用预训练的CNN对其进行特征预提取,作为视频的初始特征向量。进一步地,作者分别从片段尺度和帧尺度分别对视频初始特征向量进行编码。
2.2.1 视频的片段尺度编码
在对视频初始特征向量进行片段尺度编码前,作者将其降采样为长度为的特征,以减少初始特征序列的长度,并有助于降低编码模块的计算复杂度。
之后,将降采样后的特征使用全连接层进行特征降维后,输入到一层的标准Transformer中捕捉其上下文信息:
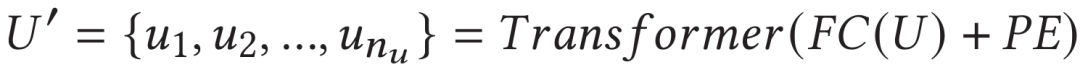
由于上文提到PRVR任务中查询文本在对应长视频的起止时刻是未知的,作者采用滑动窗口的方法生成不同长度的候选视频片段。具体地,作者使用不同尺寸的滑动窗口以步长为1的幅度遍历,在遍历过程中通过对落在滑动窗口内的特征进行平均池化来获得对应大小的视频段特征序列。其形象化过程如上图中片段构造模块所示。通过同时使用大小从的滑动窗口,得到视频段特征序列集合,将其展开后得到最终的视频片段尺度特征序列,。
2.2.2 视频的帧尺度编码
由于视频初始特征向量是独立提取的,因此它们缺乏上下文的时序信息。作者使用Transformer模块捕捉丢失的时序依赖关系。首先简单地对初始特征使用全连接层进行特征降维,并输入到一层标准Transformer,来得到视频的帧尺度特征表示:
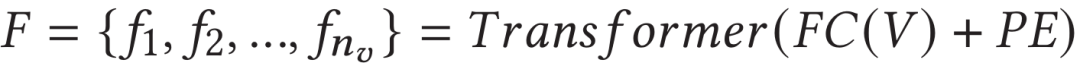
2.4 多尺度相似性学习
由于在PRVR中视频比较长,直接在计算视频文本相似性难度较大。
作者认为如果模型简单地知道与查询文本相关的大致内容,它将有助于模型在更细粒度的范围内准确地找到更相关的内容。
因此作者提出了多尺度相似性学习,以从粗到细的方式计算文本与视频间的相似度。它首先检测视频中最可能与查询文本相关的关键片段,然后在关键片段的指导下衡量每帧的重要性。通过联合考虑查询文本与关键片段和各帧的相似度来计算最终的文本-视频相似度。
2.4.1 片段尺度相似度
在部分相关的检索任务中,若文本与视频中的某一片段相关,则认为文本与该视频相关。
因此作者首先计算视频段特征序列中每个片段与文本特征表示之间的相似度,并将文本与片段最大的相似度作为文本与整个视频的相似度。对于相似度取值,作者认为取平均值会使得相关片段信息被大部分的低相似度片段模糊,所以取最大值作为视频片段尺度相似度。
此外,作者将相似度最高的视频段特征作为关键视频段特征。
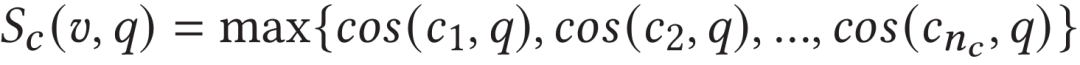
2.4.2 帧尺度相似度
检测到长视频中与文本最相关的关键片段后,作者以关键片段为进一步指导,在细粒度的时间尺度上衡量长视频每帧的重要性。
具体地,作者借鉴了Multi-head Attention的编码方式,将关键片段特征作为query,视频的帧尺度特征序列作为key和value。分别计算出中各特征的权重并对其进行聚合,并计算与文本特征表示的余弦相似度作为视频帧尺度相似度:
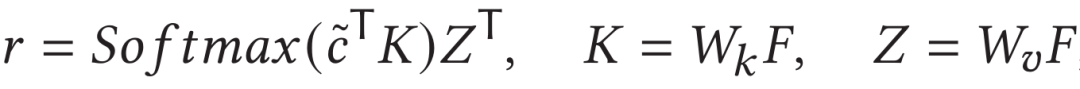
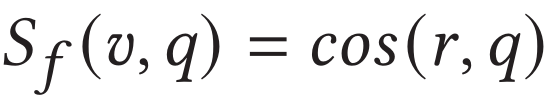
2.5 训练和测试
在模型训练阶段,作者同时使用了三元组损失和对比学习损失进行模型优化。在测试阶段,作者同时使用片段尺度相似度和帧尺度相似度以不同权重共同度量文本和视频间的最终相似度:

3. 实验结果
3.1整体性能对比实验
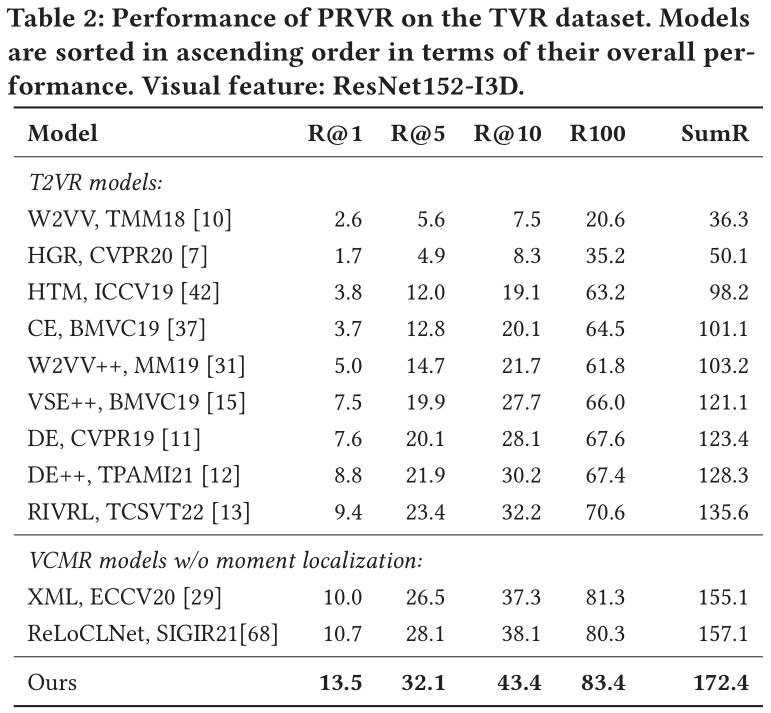
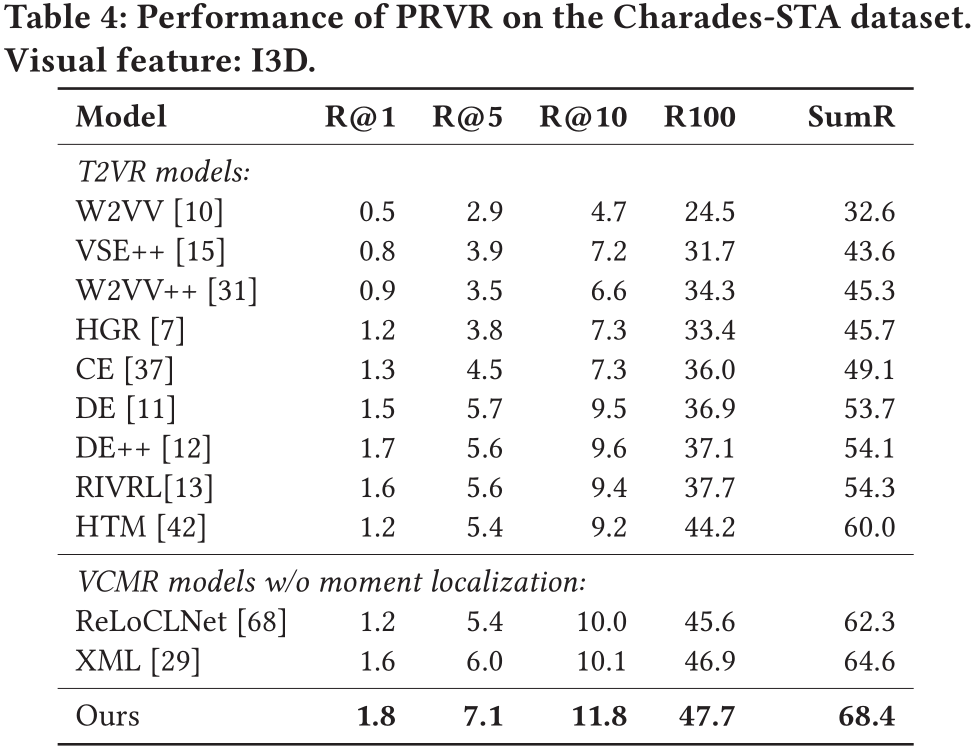
由于在上文提到,T2VR任务的传统数据集并不适用与PRVR任务,所以作者使用了被用于单视频定位任务(Single Video Moment Retrieval, SVMR)和视频库定位任务(Video Corpus Moment Retrieval, VCMR)的数据集,分别是TV show Retrieval、Activitynet Captions以及Charades-STA。
在以上三个数据集中,文本仅与视频中的某一片段相关,且视频的相对持续时间更长,符合PRVR任务的检索要求。
此外,作者采用R@1、R@5、R@10、R@100以及Recall Sum等性能指标来衡量模型。同时,由于当前并没有模型是面向PRVR任务的,作者选取了在传统T2VR任务上表现较好的模型作为baseline并在以上三个数据集上进行重新训练,以此进行性能对比。
在所有数据集上,论文提出的模型性能远超各baseline。这表明论文提出的模型相较于传统视频检索模型能够更好地解决PRVR任务。

3.2 分组性能对比实验
由于在上述的性能对比实验中仅反映了模型检索数据集中所有文本-视频对的整体性能,为了在更加细粒度的方面探索各模型对不同相关性的文本-视频对的检索性能,作者定义了片段时长/视频时长比(M/V)这一概念,它以通过查询文本所对应的正确片段持续时间除以整个视频的持续时间来衡量。
M/V越小,表示对应视频与查询文本相关的内容越少,反之则越多。此外, M/V越小,查询文本与其对应视频的相关性越低,而M/V越大,相关性越高。根据M/V的大小,作者将TVR数据集上的10895个测试查询文本分为六组,并报告了在不同分组上的性能。
作者所提出的模型在所有分组中始终表现最好。从左到右观察下图,12个比较模型的平均性能随着M/V的增加而增加。最低M/V组的表现最差,而最高M/V组的表现最好。
这表明,传统的视频检索模型能够更好地应对与相应视频具有更大相关性的查询文本。相比之下,作者所提出的模型在所有M/V组中取得的成绩更为平衡。这一结果表明,作者提出的模型对视频中的无关内容不太敏感。

3.3 消融实验
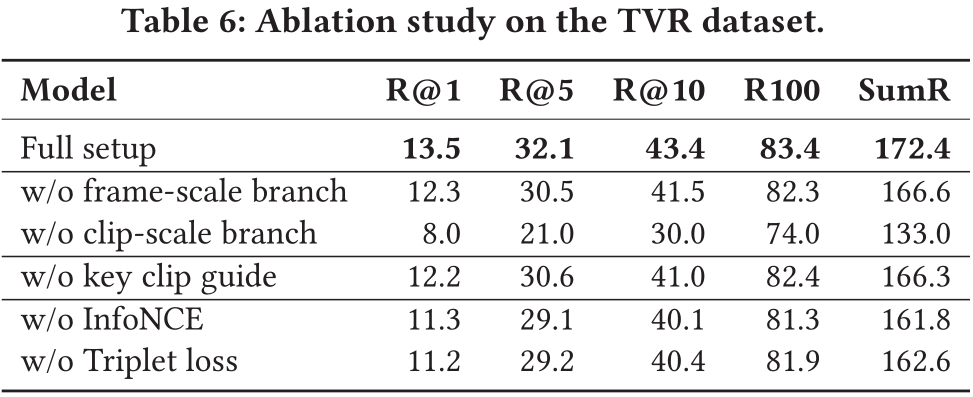
对于提出的多尺度多示例模型的不同组成部分,作者进行了消融分析。
模型单独使用帧尺度或片段尺度特征表示分支时,性能都不如两分支相结合。同时基于关键片段的注意力机制也能为模型带来较大的性能提升。由于在模型训练阶段同时使用了三元组损失和对比学习损失,作者也对两损失结合使用的有效性进行了论证。
3.4 对VCMR模型的性能提升
VCMR任务旨在给定查询文本后,在视频库中检索出对应视频,并且确定查询文本在对应视频中的起止时刻。当前用于VCMR任务的主流模型通常拥有两个阶段的工作流程。第一阶段为从视频库中检索出k个候选视频,第二阶段为从候选视频中检索出准确的起止时刻。作者选取了当前性能较高的模型,XML和ReLoCLNet,将以上两个模型在TVR数据集上的第一阶段检索结果替换为作者所提出模型的检索结果,从下图可以看出在进行替换后能给上述两模型带来VCMR任务上的性能提升。

3.5 可视化展示
下图作者给出了一些模型检索过程中的可视化实例,分别给出了查询文本在其对应视频中由模型检测出的关键片段范围与关键片段和所有视频帧之间的相似度曲线。
在前两个查询实例中,模型检测出的关键片段与正确相关片段完全重合。在后两个查询实例中,检测出的关键片段较为不准确,但是正确片段所包含的帧均具有较高的注意力权重。
这表明帧尺度相似度学习分支可以帮助片段尺度相似度学习分支在一定程度上补齐缺失信息,进一步反映了模型设计双分支相似度学习模块的合理性。

4. 结论
在本文中,针对传统T2VR任务在现实中的局限性,作者提出了一个全新的文本到视频跨模态检索子任务PRVR。在PRVR中,查询文本与对应视频均呈部分相关关系而非传统T2VR任务中的完全相关关系。对于PRVR,作者将其定义为多示例学习问题,并提出多尺度多示例网络,它以从粗到细的方式计算查询文本和长视频在片段尺度和帧尺度上的相似性。在三个数据集上的实验验证了作者所提出的模型对于PRVR任务的有效性,并表明它也可以用于提升VCMR任务模型的性能。
📝论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
COLING'22 | SelfMix:针对带噪数据集的半监督学习方法
ACMMM 2022 | 首个针对跨语言跨模态检索的噪声鲁棒研究工作
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注~
-
相关阅读:
java计算机毕业设计海城同泽中学图书仓库管理系统MyBatis+系统+LW文档+源码+调试部署
重绘(Repaint)和回流(Reflow)(重排),以及如何优化?
月薪10k,20k,40k的Java工程师,差别到底在哪?
vue2 项目中引入iconfont
HTTP 消息头
【React Hooks原理 - useRef】
【web-攻击会话管理】(4.1)会话状态:状态要求、会话替代方案
Python 元类详解
【IC设计】边沿检测电路(上升沿、下降沿、双沿,附带源代码和仿真波形)
如何在 JavaScript 中使用三元运算符
- 原文地址:https://blog.csdn.net/qq_27590277/article/details/127438001