-
【论文翻译】分布式数据库中的并发控制方法:回顾与比较
Concurrency Control Methods in Distributed Database: A Review and Comparison
2017 International Conference on Computer, Communications and Electronics (Comptelix)
Manipal University Jaipur, Malaviya National Institute of Technology Jaipur & IRISWORLD, July 01-02, 2017

摘要:在过去的几年里,分布式数据库系统性能的能力有了显着的提高。分布式数据库由一些站点组成,这些站点通过网络连接相互连接。在这个系统中,如果不同事务之间没有很好的协调,可能会导致数据库不连贯。如今,由于许多站点及其连接方式的复杂性,很难在分布式数据库中串行扩展不同的模型。分布式数据库中并发控制的主要目标是确保不干扰不同站点对公共数据库的可访问性。已经建议在分布式数据库系统中使用不同的并发控制算法。 本文介绍并比较了分布式数据库并发控制的一些可用方法。关键字:分布式数据库,两阶段锁定协议,事务,并发
1 介绍
从过去的几年中,分布式数据库在数据库研究领域一直是非常重要的。分布式数据通过同时查询性能和负载平衡提供了提高性能的机会,以扩展数据的可用性。在当今的技术世界中,有效的数据处理是几乎每个科学组织都面临的基本且至关重要的问题。扩展一个高效的分布式数据库系统,需要传播安全性。
同样重要的是要强调与安全相关的每一个问题,例如多级访问控制、机密性、可靠性、完整性以及改进分布式数据库系统的相关问题。通常,并发性与在公共数据库系统上执行多个同时处理有关。并发控制涉及管理数据库中的同时操作,以防止 2 个用户干扰数据库访问。
分布式数据库系统是与保存数据副本的集中数据库相反,它们的数据从不同的地方或不同的站点分布和重复的系统。但两者都存在并发访问数据的问题。并发控制是一种引导事务对特定类型数据的并发访问以维护数据库一致性。一致性是指当一个事务到达执行时,数据库处于一致状态,当它离开系统时,数据库也应该处于一致状态,并且由此得出的结果必须是正确的。
这个问题在分布式数据库中会很复杂,因为数据没有保存在一个地方。用户可以从每个站点访问数据,并且控制机制可能无法在其他站点立即实现。在分布式数据库系统中,事务可能有权访问多个站点中保存的数据。
大多数分布式并发控制算法派生自 3 个现有的原理类。
- 锁算法
- 时间戳算法
- 乐观算法
在这里,已经对分布式数据库进行了研究,以及在访问不同类型的数据时如何提高其可访问性和灵活性,并讨论了几种并发控制算法。
2 分布式数据库回顾
首先,在这部分解释分布式数据库模型。
2.1 分布式数据库模型
图 1 显示了一个模型的常见结构。此模型中的每个节点都有四个部分。产生事务并维护节点事务信息级别的来源。对事务的执行处理进行建模的事务管理器。实现特殊并发控制算法细节的并发控制管理器和为节点建模 CPU 和 I/O 源的资源管理器。除了这些每个节点的组件之外,该模型还有一个网络管理器,用于对网络通信行为进行建模。

1)事务管理器工作负载中的每个事务,都会有一个主从进程、一些队列组和更新程序。主进程占据提供事务的站点。每批队列向已保存在该站点中的一个或多个文件发送读取或写入请求。由一组或一组群组组成的事务存在于需要访问数据的每个站点中。
当队列组获得访问重复数据及其更新程序所需的写入权限时,他们会连接到他们的更新程序。事务可以顺序或并行执行,这与事务类算法有关。
2)资源管理器
资源管理器可以假定为一个站点的操作系统模型,它指导该站点的物理资源,包括 CPU 和磁盘。资源管理器为事务管理器和并发控制管理器提供 CPU 和 I/O 服务,还提供使用 CPU 资源的消息传递服务。
事务管理器使用 CPU 和 I/O 资源来读取和写入磁盘以及发送消息。并发控制管理器也使用 CPU 资源来处理请求和发送消息。
3)网络管理器
网络管理器封装了网络连接模型。网络模型非常简单。对于将消息从一个站点路由到另一个站点,它只作用于一个交换机。网络属性在此模型中被隔离。
4)并发控制管理器
并发控制管理器,涉及并发控制的含义,它是一个只应从一种算法转换到另一种算法的模型,负责支持由写和读访问请求组成的事务管理器发出的并发控制请求。请求包括提交事务的权限。
在图 2 中,对分布式数据库模型进行了更精确的观察。

2.2 分布式事务处理模型
为了理解并发控制算法是如何工作的,一个简单的分布式数据库管理模型如图 3 所示。分布式数据库系统是一组通过网络相互连接的节点。

TM 是事务管理器,DM 是数据管理器。在这里拥有安全的网络连接很重要。这意味着如果节点A 向节点 B 发送消息,它应该到达目的地而没有任何错误。1)事务分配
下图4是一个分布式数据库系统场景。

2.3 分布式数据库系统中的并发控制算法
1)两相锁定分布式协议 2PL
前两相锁定分布式算法的意思是“Read any and write all”。事务在需要更新的项目上设置读锁并将这些锁转换为写锁。对于阅读项目,在该项目的副本上设置阅读锁就足够了。所以本地版本被锁定。为了更新一个项目,必须在所有版本上应用写锁。正在建立写入锁,直到更新项目的所有版本。在事务成功完成或给出错误消息之前,所有锁都被确认。
有可能发生死锁。每当事务被阻塞时,就会调查本地死锁,事务会发送 ABORT 消息并再次重新启动。支持本地死锁是通过一个“snoop”处理来完成的,它定期向所有站点的信息发送 WAIT 要求,然后消除本地死锁。这种处理称为“SNOOP”,它的职责是在节点之间移动。没有节点遭受公共死锁成本。
2)锁算法 受伤-等待协议
二向锁算法具有“Read all things, write all”的规律,与2PL不同的是,它支持死锁。每个事务都根据开始时间进行编号,避免了因为新事务而延迟旧事务。如果一个较旧的事务请求锁定并且导致较旧的事务等待较年轻的事务,则较年轻的事务受到伤害。较年轻的事务再次重新启动。较年轻的事务可以等待较旧的事务以消除死锁的可能性。
3)时间戳序列(BTO,基本时间戳排序算法)
第三种算法是基本的时间戳算法。与之前的算法一样,它使用事务开始的时间戳,但使用方式不同。该算法不是锁定方法,而是与所有最近可用的数据项共享时间戳,并且通过事务对数据的访问是按时间戳序列执行的。尝试访问的事务数据不按顺序重新启动。当收到对某个项目的读取请求时,读取时间戳可以与写入时间戳不同。
实际上,如果申请人时间戳小于项目写入时间戳,则简单地删除更新操作。对于重复的数据,read any 和 write all,使用的方法是向所有可能的发送一个读请求,直到一个写请求被发送并被所有版本批准。算法的集体性由 COMMIT 队列完成。这意味着编写者将他们的更新程序保存在特定的工作空间中直到提交时间。
4)分布式认证(OPT,Optimium协议)
该算法是分布式的,基于时间戳。最优并发控制算法是在认证信息变化的基础上运行的。对于每个数据项,都会保留一个读取时间戳和一个写入时间戳。事务可以自由地读取数据项或更新项,并将每次更新保存在本地工作空间中,直到 COMMIT 时间。对于每次读取,事务应该记住与读取项相关的标识符版本,例如(写入时间戳)。然后,当所有事务队列都完成并报告给 MASTER 时,事务被分配一个唯一的时间戳。这个时间戳被发送到每个事务,并带有准备好的 COMMIT 消息,事务在本地批准每个读取和写入。如果读取的版本仍然是项目当前版本,并且最近本地没有新时间戳的写入请求没有被批准,则读取请求被批准。
如果下一次读没有被批准和提交并且下一次读最近在本地也没有被批准,则写入请求被批准。
2.4 基于时间戳RCTO(可恢复时间戳排序 Recoverable Timestamp Ordering)的算法
该算法基于 COMMIT 操作时间戳的原理操作。每个数据项 X 有两个向量:一一个写入向量 wv,它为每个读取或写入操作注册写入时间戳,以及一个名为 cv 的 COMMIT 向量,如果到达的 COMMIT 操作的时间戳不等于 wv 中第一个保存项目的时间戳,则注册成功的事务操作。循环函数移动 wv 元素,wv 中的第一个元素移到最后一个元素,其他元素根据下图移动到顶部。

该算法包括 3 种不同的操作。读操作、写操作和成功的事务消息操作。在定义此操作之前,我们指出不同事务对同一项目的 COMMIT 操作时间戳如下代码。
1. if ts(Ci)=ts(wv[i]) { 2. Execute Ci, 3. Delete the contents of wv[i], 4. Move up the remaining valus of wv }- 1
- 2
- 3
- 4
- 5
- 6
上面的代码对向量 wv 和 cv 都进行了操作。图 6 解释了包括以下操作的时间表:

C3C4C5 是一组三个 COMMIT 事务,在 COMMIT 向量中保存三个值 t1、t2 和 t3。 w2(x)w4(x)w1(x) 是对同一个对象 x 的一组写操作,该对象 x 已保存在三个事务的写向量中。当 c4 和 w4 保存在同一行时,同时从 wv 和 cv 中删除。 W2、c3、w1 和 c5 操作向上移动一行。
当读取操作 Ri 到达时,执行以下代码。
1. For each received read operation i { 2. Let z=i*random number 3. If ts(Ri) is already in wv Then 4. Store z instead of Ri; Else 5. Store z at the end of wv }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
假设下一个读取操作是 R2(x)。此操作导致已存在的表转换为下图右侧的表。由于读取操作的时间戳已经存储在 wv 中,因此 wv 的内容乘以一个随机值。
这个过程的原始好处是实现了从写到读的操作,避免了读操作执行的延迟。图 7 显示 R2 操作到达,然后乘以一个随机值。

当读取操作 wi 到达时,将执行以下代码。1. For each received read operation i { 2. If ts(Wi) is not stored in wv then 3. Save ts(Wi) in wv. Else 4. Save i*random number in wv }- 1
- 2
- 3
- 4
- 5
- 6
- 7
写入操作将时间戳保存在向量 wv 中。图 8 显示了进行新操作 w3(x) 后的 wv 和 cv 值。
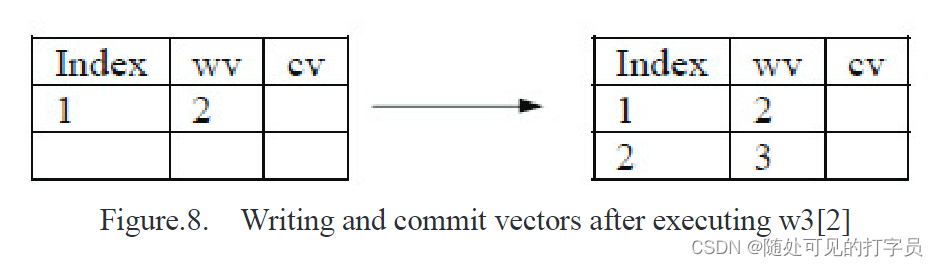
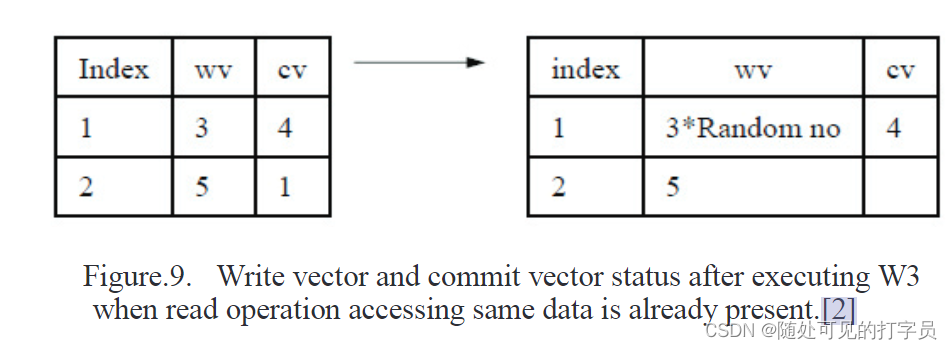
在图 9 中,当 w3(x) 在 R3(x) 之后到达时,已经显示了写入向量和 COMMIT 向量值。
COMMIT 操作是最原始的操作,它将 ts(ci) 与 wv 中的第一个组件进行比较,以保持 cv 中的 COMMIT 操作。各自的代码如下:
1. Let K is the index of the first empty available position in cv. 2. For each received Commit operation Ci { 3. If (ts(Ci)=wv[0]) or (ts(Ci)=wv[k}) { 4. Execute Ci; 5. Delete wv[0] or Delete wv[k]; 6. Move up all the remaining values in wv and cv simultaneously } Else { 7. record Ci at the first empty cell in cv } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
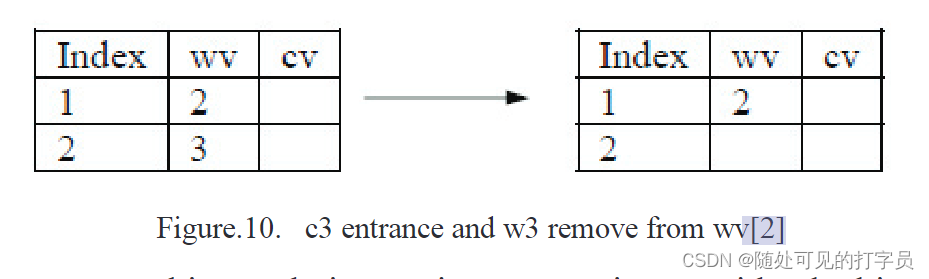
该操作的优点是延迟每一个过早的提交,强制写期间的提交事务操作被执行在读期间的提交事务操作。图 10 显示了到达 c3 后的 COMMIT 操作。最近 w3 值已保存在 wv 向量中。已执行 COMMIT 操作并删除 wv 值。
3 现有方法的比较与分析
以上列举了四种方法用于分布式数据库的并发控制机制。
在两相锁定算法中,我们存在并发弱点、顺序拒绝以及发生死锁和饥饿等问题。在算法受伤-等待中,观察算法的时间优先级。在基于时间戳的协议中,保证了冲突顺序能力,不会发生死锁。但是可能会发生顺序受伤或饥饿,并且不能保证执行计划的可恢复性。但是关于乐观算法或批准技术应该说:
- 在所有以前的技术中,系统在对数据库进行操作之前都会进行一些检查。
- 在被称为乐观技术的批准技术中,之前没有进行任何检查。
- 与锁定技术相比,这种技术提供了更多的并发性。
- 在这种技术中,写入操作不是直接在数据库中完成的,除非事务执行已经完成。
- 相反,在执行过程中,所有更新都是在相关数据的本地版本上完成的。
- 在事务执行结束时,在审批阶段,检查是否有任何损害进入执行计划的可串行化或无效。
- 如果未观察到可串行化,则拒绝事务以重新启动。
- 如果没有对可序列化造成损害,则稳定的事务和数据库将从本地版本更新。
4 模拟和测试结果
针对资源对三种并发控制算法性能影响的不同假设效应研究进行了多次模拟测试。在有限的资源假设下对三种算法的效率进行了调查。
4.1 无限资源
与资源相关的第一个测试是在资源无限的假设下,调查不同级别多规划的三种策略的性能特征。在一些无限资源的情况下,在没有数据竞争的情况下吞吐率应该是多编程级别的非下降函数。然而,对于具有特殊大小的数据库,增加多编程级别的冲突概率会增加。对于锁定,冲突概率的增加将表现为由于拒绝锁定请求而增加阻塞的数量和由于死锁而增加重新启动的次数。对于基于重启的策略,更多的冲突概率将导致更多的重启次数。图 11 显示了第一个测试的吞吐量结果。
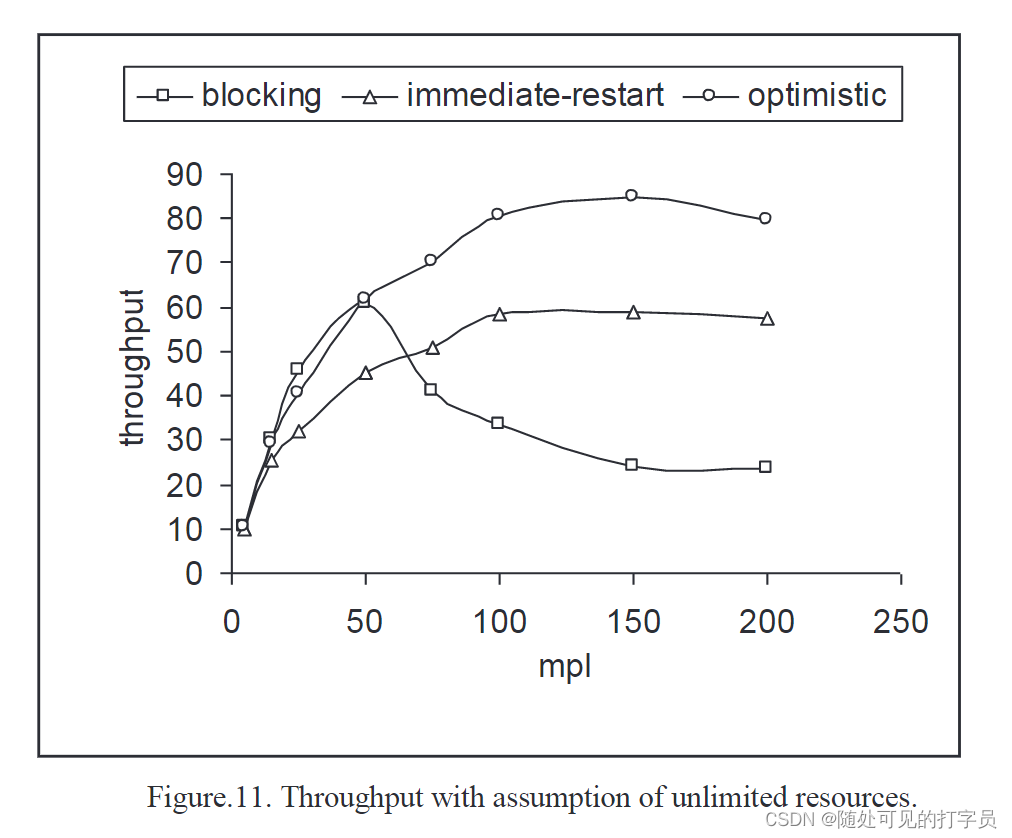
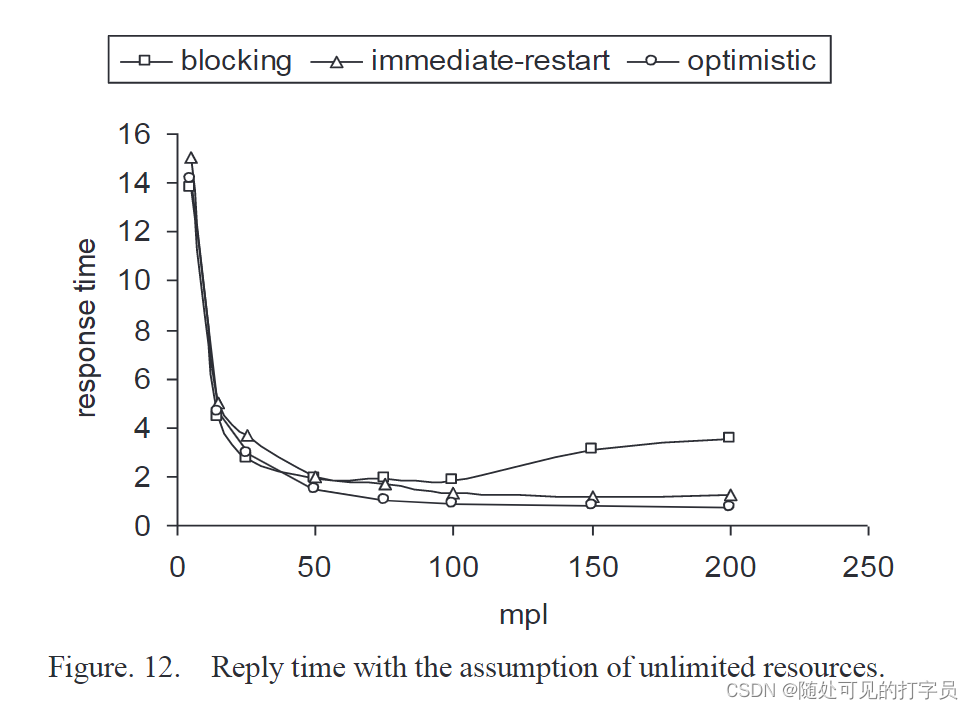
延迟时间是自适应的,等于执行事务的平均响应时间。由于这种自适应延迟,立即重启算法会到达一个点,即所有高于重新启动延迟位置或终端认为位置的非活动事务。当系统有如此多的活动事务以致新事务与活动事务冲突并因此立即重新启动并延迟时,我们会得到这一点。因此重启平均延迟时间增加,导致竞争活跃方式的事务减少,结果,冲突概率降低。当到达一个常数点时,就绪数组中没有等待事务,多编程级别的增加在该点没有影响。图 12 显示了算法的响应时间。
4.2 有限资源
在第二次测试中,研究了有限资源对三种并发控制算法性能的影响。已为该测试发现了一个带有处理器和两张光盘的数据库。图 13 显示了此状态下 3 种算法的吞吐量。注意每三种算法的吞吐量曲线表明当多编程级别增加时发生抖动。吞吐量首先增加,然后达到高潮,最后减少或修复。

当多编程级别增加时,起初每 3 个算法的吞吐量增加,因为在多编程低级别没有足够的事务数来分配资源。图 14 显示了 3 种策略的响应时间。

5 结论
在本文中,我们指出了分布式数据库中的四种并发控制算法,并介绍了一个基于时间戳的算法示例。最后,在上一部分比较了这四种算法后,我们得出结论,乐观算法和基于认证的低工作负载比其他算法具有更低的中止率,在低工作负载下,它的响应时间增加最少,因为重复性和并发性比锁定技术更高,并且之前也没有对数据库进行过检查。
一般来说,乐观算法被选为分布式数据库中最好的并发控制机制。
-
相关阅读:
Puppeteer国产镜像配置
Apache DolphinScheduler在中国信通院“2023 OSCAR开源尖峰案例”评选中荣获「尖峰开源项目奖」!
LeetCode 1608. 特殊数组的特征值
目标检测YOLO实战应用案例100讲-面向辅助驾驶的道路目标检测(中)
GitHub 最新发布的这份 Java 面试导图 + 面试手册,真不是吹的
flutter3-macOS桌面端os系统|flutter3.x+window_manager仿mac桌面管理
JAVA JSP javaweb小区物业管理系统源码 小区管理系统 jsp小区物业服务管理系统
【kubernetes】【基础资源使用】kubernetes中的Deployment使用
深度优先搜索(dfs)和广度优先搜索(bfs)
#systemverilog# 关键字之 `include(3)`include vs import 用法区别
- 原文地址:https://blog.csdn.net/qq_40948559/article/details/127435528