摘要:相比于传统的软件开发,AI开发存在以下4个痛点:算法繁多;训练时间长;算力需求大;模型需手动管理,我们可以使用云上AI开发的方式来缓解以上4个痛点。
本文分享自华为云社区《git clone开启云上AI开发》,作者:ModelArts开发者。
已发布地址:https://developer.huaweicloud.com/develop/aigallery/article/detail?id=17052711-f3f5-4b53-bdbc-5d5c7cdc64fa
一、为什么需要云上AI开发?
相比于传统的软件开发,AI开发存在以下4个痛点:
1)算法繁多;
2)训练时间长;
3)算力需求大;
4)模型需手动管理
我们可以使用云上AI开发的方式来缓解以上4个痛点,云上AI开发的优势:
- 任意地点接入,在线开发;
- 云上环境预置多种主流深度学习框架,开“箱“即用;
- 云端充足算力、TB级数据存储,支持重型训练任务;
- 云端平台具备训练任务版本化管理,AI开发更可靠、可高效;
二、云上AI开发主要步骤

三、具体操作步骤
步骤一 Notebook调试
1.准备Python环境
进入ModelArts控制管理台,点击【开发环境】–> 【Notebook】,进入notebook列表页面,点击页面左上角“创建”按钮,新建一个notebook,填写参数,下图所示:


点击“立即创建”,确认产品规格后,点击提交,完成Notebook的创建。
返回Notebook列表页面,等待新创建Notebook状态变为“运行中”后,点击名称进入Notebook。
进入Notebook页面后,打开terminal,如下图所示:

输入如下命令,查看已安装Python环境信息
conda info -e
点此链接GitHub - IDEA-Research/DINO,下面将以此开源算法为例,演示如何在华为云Notebook上快速运行,算法详细介绍请参考 README.md 。
1)在terminal里继续输入如下命令,克隆仓库
git clone https://github.com/IDEACVR/DINO cd DINO
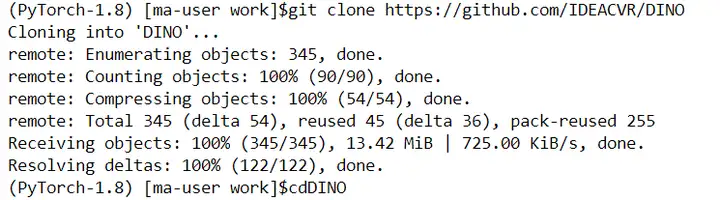
如上图所示,表示已完成代码克隆,点击左侧任务栏顶部刷新按钮,即可查看代码。
2)查看Pytorch版本
pip list | grep torch
3)安装其他需要的包
pip install -r requirements.txt
4)编译CUDA算子
cd models/dino/ops python setup.py build install # unit test (should see all checking is True) python test.py cd ../../.. # 回到代码主目录

2.准备数据和预训练参数文件
1)进入控制台,将光标移动至左边栏,弹出菜单中选择“服务列表”->“存储”->“对象存储服务OBS”,如下图所示:

点击“创建桶”按钮进入创建界面。

开始创建。配置参数如下:
① 复制桶配置:不选
② 区域:华北-北京四
③ 桶名称:自定义,将在后续步骤使用
④ 数据冗余存储策略:单AZ存储
⑤ 默认存储类别:标准存储
⑥ 桶策略:私有
⑦ 默认加密:关闭
⑧ 归档数据直读:关闭
单击“立即创建”>“确定”,完成桶创建。
点击创建的“桶名称”->“对象”->“新建文件夹”,创建一个文件夹,用于存放后续数据集。

2)下载COCO 2017数据集子集。该数据集包括train(5000张),val(5000张)及标注文件。进入下载详情页面,下载方式选择对象存储服务(OBS),目标区域选择华北-北京四,目标路径选择1中在OBS中创建的路径,用于数据集存储,如下图所示:

点击“确认”,跳转至我的下载页面,可以查看数据集下载详情,等待数据集下载完成,如下图所示:

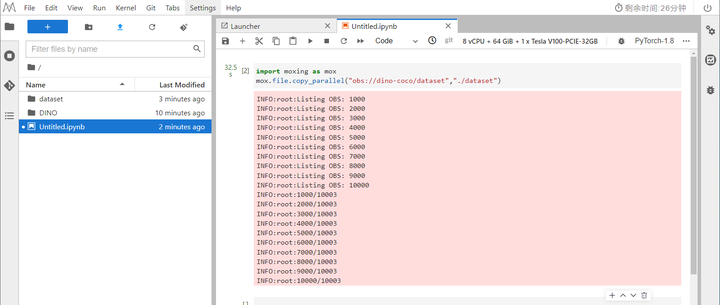
返回Notebook页面,新建一个ipynb文件,编写导入数据集脚本,运行代码,运行完毕后,点击任务栏上方“刷新”按钮,即可查看导入dataset,如下图所示:
import moxing as mox mox.file.copy_parallel({obs_path},{notebook_path})
说明:
{obs_path}为OBS存储数据集的位置
{notebook_path}为数据集在notebook中的存储路径
3)下载DINO 模型 checkpoint “checkpoint0011_4scale.pth”,下载完成后,返回Notebook页面,在DINO页面,创建文件夹ckpts,用于存放下载的checkpoint。

进入文件夹,点击任务栏上方”上传“按钮,选择下载完成的checkpoint 路径,文件大小超过100MB,需选择OBS中转,等待数据上传完毕,如下图所示:

3.运行代码
1)执行下面的命令,评估预训练模型,你可以期待得到最终的AP大约49.0。
bash scripts/DINO_eval.sh /path/to/your/COCODIR /path/to/your/checkpoint
说明:
/path/to/your/COCODIR 为Notebook数据集的存储路径
/path/to/your/checkpoint 为Notebookcheckpoint存储路径
如下图所示:

整个过程约等待13分钟左右,运行结果如下:

2)推理及可视化
打开DINO目录下的inference_and_visualization.ipynb,选择Kernel Pytorch-1.8,如下图所示:

修改代码:
... model_checkpoint_path = "ckpts/checkpoint0011_4scale.pth" # 修改checkpoint路径 ... args.coco_path = "../dataset" # 修改coco数据集路径
运行代码查看推理结果。

步骤二 运行训练作业
1.保存镜像
1)返回ModelArts管理控制台,在左侧菜单栏中选择**“开发环境 > Notebook”**,进入新版Notebook管理页面。在Notebook列表中,点击名称进入创建的Notebook详情页

2)点击右侧“更多”,选择“保存镜像”

3)在保存镜像对话框中,设置组织、镜像名称、镜像版本和描述信息。单击“确认”保存镜像。
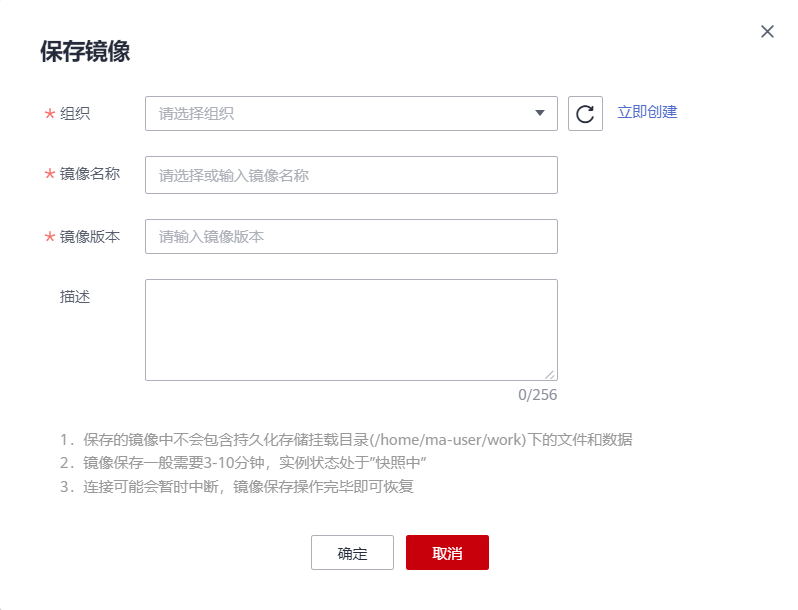
在“组织”下拉框中选择一个组织。如果没有组织,可以单击右侧的“立即创建”,创建一个组织。创建组织的详细操作请参见创建组织。
同一个组织内的用户可以共享使用该组织内的所有镜像。
4)镜像会以快照的形式保存,保存过程约5分钟,请耐心等待。此时不可再操作实例(对于打开的JupyterLab界面和本地IDE 仍可操作)。
5)镜像保存成功后,实例状态变为**“运行中”**,用户可在“镜像管理”页面查看到该镜像详情。
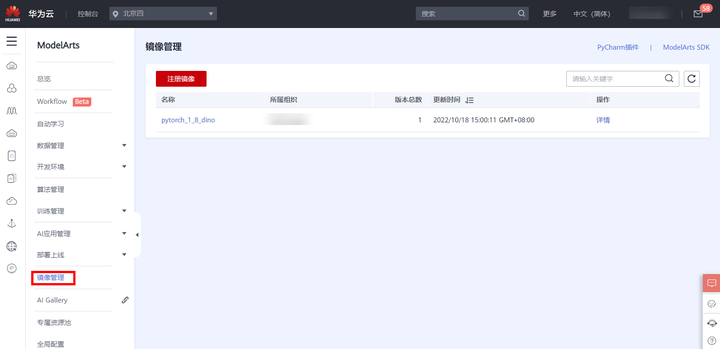
6)单击镜像的名称,进入镜像详情页,可以查看镜像版本/ID,状态,资源类型,镜像大小,SWR地址等。
7)还可在左侧菜单栏中选择**“镜像管理”**,查看镜像列表及详情,如下图所示:
2.上传训练代码
返回Notebook页面,在新建的ipynb中输入以下代码,完成代码上传至OBS桶中
mox.file.copy_parallel("./DINO/","obs://dino-coco/DINO")
如下图所示:

3.创建训练作业
1)在左侧菜单栏中选择**“训练管理 > 训练作业”**,点击右上角“创建训练作业”,如下图所示:

2)参数配置
创建方式:自定义算法
启动方式:自定义,选择已保存镜像
启动命令:
cd ${MA_JOB_DIR}/DINO && python main.py -c config/DINO/DINO_4scale.py --options dn_scalar=100 embed_init_tgt=TRUE dn_label_coef=1.0 dn_bbox_coef=1.0 use_ema=False dn_box_noise_scale=1.0
训练输入:选择OBS桶内上传代码路径
训练输出:选择创建的OBS桶,点击新建文件夹,创建一个文件夹,用于存放训练输出,如下图所示:

资源池:公干资源池
资源类型:GPU
规格: GPU: 1*NVIDIA-V100(32GB) | CPU: 8 核 64GB 3200GB
永久保存日志:开启,选择OBS桶,新建文件夹,用于存放训练日志,如下图所示:

事件通知:开启,可监控训练作业的事件的状态,可短信通知。
主题名:如不存在点击右侧“创建主题”。主题是消息发布或客户端订阅通知的特定事件类型。它作为发送消息和订阅通知的信道,为发布者和订阅者提供一个可以相互交流的通道。
事件:全部勾选
自动停止:可开启(训练时长大于1小时)
如下图所示:


3)参数设置完成之后,点击提交,确认训练信息,点击“确认”

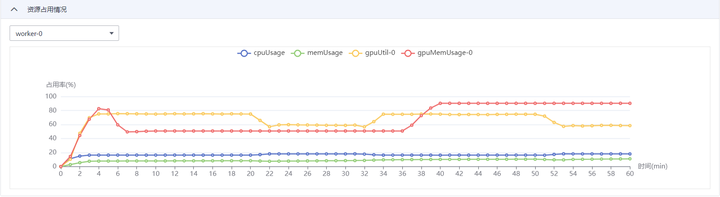
跳转至训练作业列表,等待创建的训练作业,可点击训练作业名称,查看详细信息,系统日志,及资源占用情况,如下图所示:

4)在训练任务跑完之后,可在“代码目录”处在线编辑代码,保存之后,可再次进行训练模型,如下图所示:

4.训练输出
训练完成之后,可在配置的OBS训练输出路径查看训练结果


10月27日19:00-20:30直播讲解《git clone开启云上AI开发》,预约报名:https://bbs.huaweicloud.com/live/cloud_live/202210271900.html