-
SQL基础
linux指令
-- 修改文件权限,从红色变成绿色
chmod 777 文件名
-- 创建文件夹 文件夹名称mysql
mkdir mysql
-- 解压.tar文件到指定的mysql文件夹中
tar -xvf 文件名.tar -C mysql
tar -zxvf zookeeper-3.4.6.tar.gz -C /usr/local/
系统环境变量
右键【我的电脑】【属性】【高级系统设置】/搜索环境变量 ,【环境变量】【系统变量】增加变量。
MYSQL安装启动
管理员身份运行cmd
net start mysql80
net stop mysql80

客户端链接
方法一:MYSQL提供的客户端命令行工具
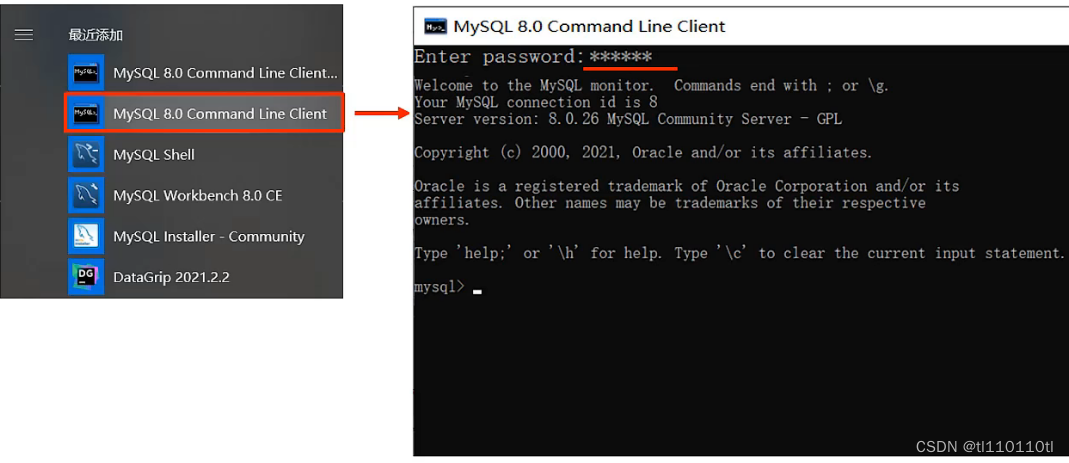
方法二:系统自带的命令行工具执行指令
mysql [-h 127.0.0.1] [-P 3306] -u root -p

- -- DDL 数据库,表,字段
- -- 查询
- show DATABASES;
- select DATABASE();
- -- 创建
- create database [if not exists] 数据库名 [DEFAULT CHAESET 字符集] [ COLLATE 排序规则];
- -- 删除
- drop database [if exists] 数据库名称
- -- 使用
- use database 数据库名
- -- 查询
- show TABLES
- desc 表名;
- SHOW create table 表名
- -- 创建表
- CREATE TABLE 表名(
- -- id int not null primary key auto_increment,
- 字段1 字段1类型[COMMENT 字段1注释],
- 字段2 字段2类型[COMMENT 字段2注释],
- 字段3 字段3类型[COMMENT 字段3注释],
- ......
- 字段n 字段n类型[COMMENT 字段n注释]
- )[COMMENT 表注释];
- -- 修改表
- -- 添加字段
- alter table 表名 ADD 字段名 类型[COMMENT 注释]
- -- 修改字类型
- alter table 表明 MODIFY 字段名 新数据类型;
- -- 修改字段名和字段类型
- ALTER table 表明 CHANGE 旧字段名 新字段名 类型 [COMMENT 注释] [约束];
- -- 删除字段
- ALTER TABLE 表明 DROP 字段名;
- -- 修改表名
- alter table 表明 RENAME to 新表明;
- -- 删除表
- Drop table [if exists] 表明
- truncate table 表名
- -- DML 增删改
- insert
- update
- delete
- -- 添加数据
- insert into 表名(字段1,字段2,...) values( 值1, 值2,...)
- insert into 表名 values( 值1, 值2,...)
- insert into 表名 values( 值1, 值2,...),( 值1, 值2,...),( 值1, 值2,...),( 值1, 值2,...)
- -- DCL 用户 ,数据库访问权限
- -- 查询用户
- use mysql;
- select * from user;
- -- 创建用户
- CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
- -- 主机名可以用 % 代替,这表示这个主机可以再任何地方访问
- -- 修改用户密码
- ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码';
- -- 删除用户
- DROP USER '用户名'@'主机名';
- -- 数据权限
- -- 查询权限
- SHOW GRANTS FOR '用户名'@'主机名';
- SHOW GRANTS FOR 'root'@'%';
- -- 授权
- GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名';
- GRANT all ON *.* TO 'root'@'%';
- -- 撤销权限
- REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';
- -- 函数
- -- 常见数值函数
- SELECT CEIL(3.1) -- 向上取整
- SELECT FLOOR(3.8) -- 向下取整
- MOD(6,2.2) -- 返回 x/y 的模余数
- RAND() -- 返回0~1内的随机数
- ROUND(12.3456,2) -- 求参数x 的四舍五入的值,保留y位小数
- -- 日期函数
- select CURDATE()
- select CURRENT_DATE()
- CURTIME()
- CURRENT_TIME()
- NOW()
- YEAR(date)
- MONTH(date)
- DAY(date)
- select DATE_ADD(NOW(),INTERVAL 70 DAY) -- 返回 now() 时间 加上 70 天 之后的时间
- DATEDIFF(expr1,expr2) -- 返回起始时间 expr1 和结束时间 expr2之间的天数
- -- 流程控制函数
- IF(value,t,f)
- IFNULL(value1,value2)
- case WHEN [value1] then [res1] ...... ELSE [default1] END
- case [expr] WHEN [val1] THEN [res1] ... ELSE [default1] END
- -- 字符串相关
- -- 常用函数
- CONCAT('ss','aa','as')
- LOWER('Hellow')
- UPPER('HEoolw')
- LPAD(empId,10,'0') -- 把empId 用字符0 从左边补到10位的长度
- RPAD(empId,10,'0') -- 把empId 用字符0 从 右 边补到10位的长度
- TRIM(' Hellow word ')
- SUBSTRING('Hello word',1,5) -- 从1【下标从1开始计数】截取,截取5位
- --外键约束
- NO ACTION -- 不允许 默认
- RESTRICT -- 同上
- CASCADE -- 级联
- SET NULL -- 子表设置为空
- SET DEFAULT -- 设置为默认值
- ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名(主表字段名)
- ON UPDATE CASCADE ON DELETE CASCADE; -- 主表数据更新时,从表相应数据更新,主表数据删除时,从表数据也删除(级联)
- 3. 如果你要真正的复制一个表。可以用下面的语句。
- CREATE TABLE newadmin LIKE admin;
- INSERT INTO newadmin SELECT * FROM admin;
没有DQL(查询相关)
- -- 表子查询,IN
- --
- select * from emp where (age,sarly) in (selct age,sarly from emp where name in ('',''))
- -- join
- select * from (select * from emp where entrydate > '20060101') e left join dept d
- on e.deptid = d.id;
- -- 最后改开头 select e.*,d.*
事务 MYsql
- -- 查询事务提交方式
- select @@autocommit;
- -- 将事务的提交方式设置为 手动提交
- set @@autocommit = 0;
- -- 提交事务
- Commit;
- -- 回滚数据
- ROLLBACK;
- -- 方式二
- -- 开启事务
- START TRANSACTION; 或者 BEGIN;
- -- 提交事务
- Commit;
- -- 回滚数据
- ROLLBACK;
- -- 查看当前系统的事务隔离级别
- select @@TRANSACTION_ISOLATION;
- -- 设置事务的隔离级别
- set [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED| READ COMMITTED | REPEATABLE READ | SERIALIZABLE}
存储引擎-
MyISAM
介绍--
MyISAM 是 MySql早期的默认存储引擎
特点--
不支持事务,不支持外键
支持表锁,不支持行锁
访问速度快
文件--
xxx.MYD 存储数据
xxx.MYI 存储索引
xxx.sdi 存储表结构
Memory
介绍--
Memory引擎的表数据是存储在内存中的,由于受到硬件、断电问题的影响,只能将这些表作为临时表或者缓存使用。
特点--
内存存放
hash索引(默认)
文件--
xxx.sdi:存储表结构信息

安装数据库服务。
链接数据库,rpm文件安装,数据库默认给一个随机密码。再文件 /var/log/mysqld.log 中
可用cat 命令,或 vi 命令查找出。
设置密码强度为最低档 0 。设置密码长度最低可为4位
set global validate_password.policy=0;
set global validate_password.length=4;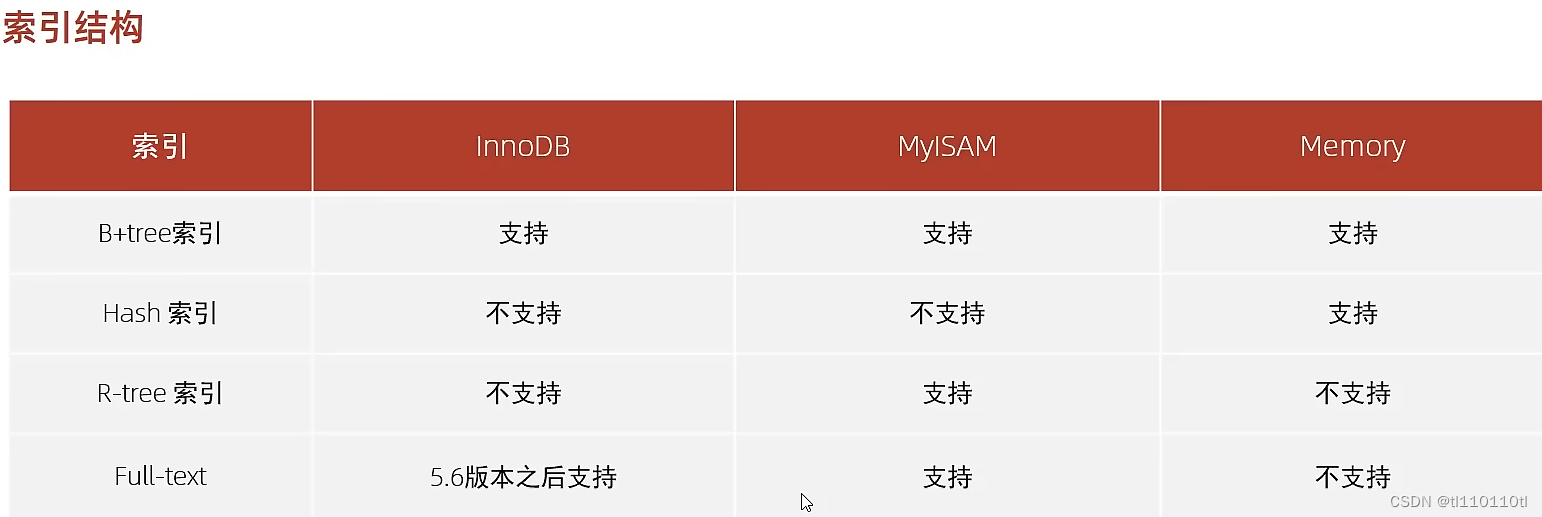
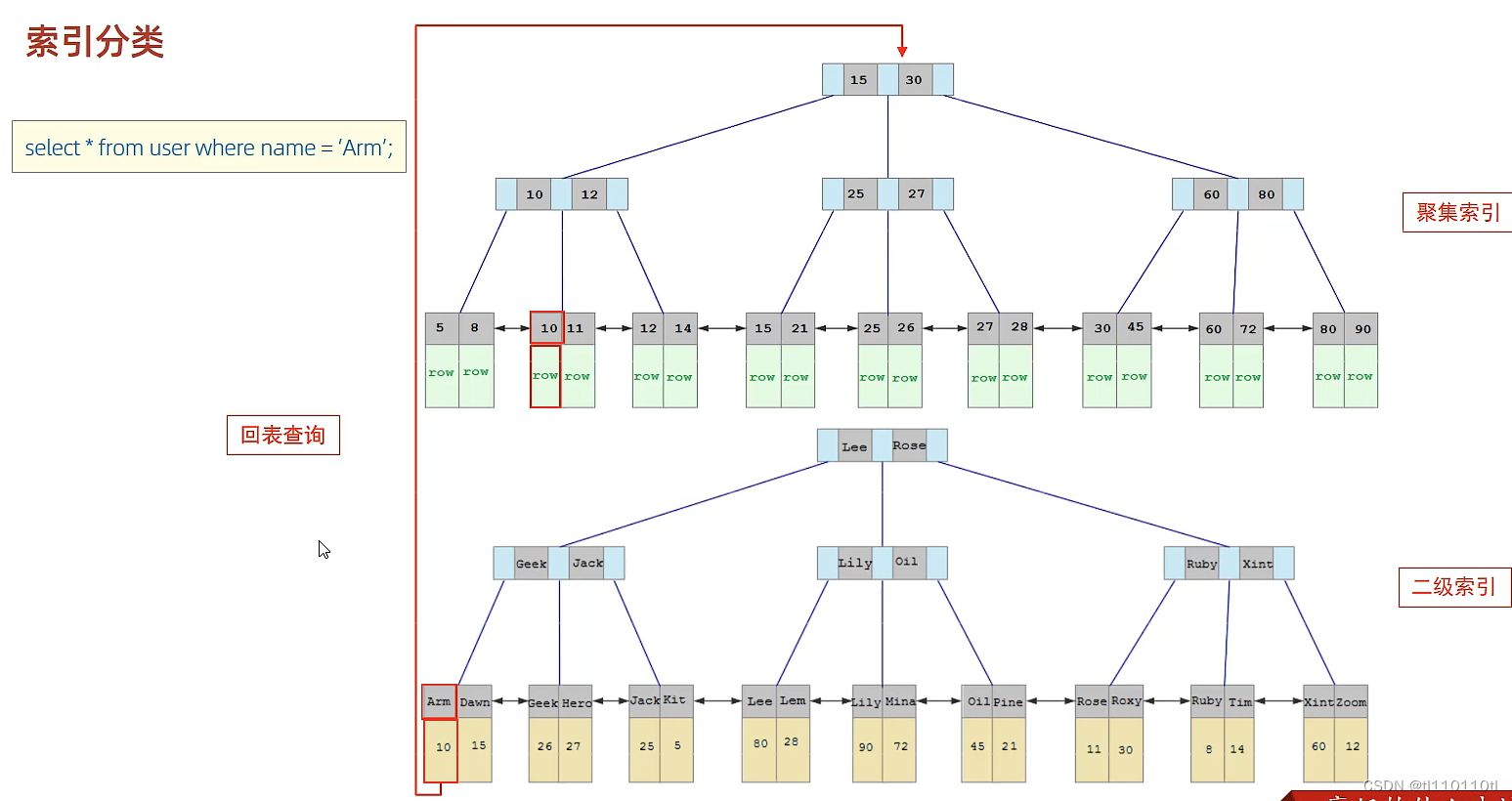
- -- 创建索引
- CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name(index_col_name);
- -- 查看索引
- SHOW INDEX FROM table_name;
- -- 删除索引
- DROP INDEX index_name ON table_name;
SQL性能分析
如何确定给数据库加不加索引,首先要看SQL执行频率,到底当前所选择的数据库,insert 、update 、select 的频率如何
show global status like 'Com_______';【7个下划线】
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_binlog | 0 |
| Com_commit | 0 |
| Com_delete | 0 |
| Com_import | 0 |
| Com_insert | 22 |
| Com_repair | 0 |
| Com_revoke | 0 |
| Com_select | 790 |
| Com_signal | 0 |
| Com_update | 40 |
| Com_xa_end | 0 |
+---------------+-------+
11 rows in set (0.00 sec)可以看出select 频率高,所以可以加索引
慢查询日志
show variables like 'slow_query_log';
定位哪些SQL语句执行时间超出了指定参数(long_query_time 单位秒,默认10)的所有日志
MySql 的慢查询日志默认不开启,需要在配置文件(/etc/my.cnf)中配置:
# 开启MYSQL 慢日志开关
slow_query_log=1
# 设置慢日志的时间为2秒。SQL语句执行时间超过2秒就会被记录
long_query_time=2
配置完毕后,通过以下指令重启MYSQL服务进行测试,查看慢日志
systemctl restart mysqld
/var/lib/mysql/localhost-slow.log
通过命令,查看文件尾部最新内容 tail -f 文件名.后缀
profile详情
刚才超过2秒,才记录,但是如果有的查询耗时1.8秒,还经常执行。如何定位?
查看当前MYSQL数据库是否支持profile
select @@have_profiling;【yes就是支持】
虽然支持,但是默认是关闭状态,需要通过set 语句再session/global 级别开启profiling;1.看看数据库支持么
select @@have_profiling
2.局部开启
set session profiling = 1
3.执行想要执行得sql语句
select........
insert.....
4.展示sql语句所消耗得时间
show profiles
为什么执行的SQL语句耗时长
如果其中一条执行得语句耗时很长,通过如下方法查看耗时再了什么地方
一般情况下,都是执行阶段耗时(跟没说一样),也有可能是CPU影响等
#查看每一条SQL的耗时基本情况
show profiles
#查看指定query_id 的sql语句各个阶段的耗时情况
show profile for query query_id
#查看指定query_id 的SQL 语句CPU的使用情况
show profile cpu for query query_id
Explain
这用来具体查看这条SQL语句有没有用到索引等条件。
explain/desc SQL语句
ID:select 查询的序列号,表示查询中执行select 子句或者是操作表的顺序(id相同,执行顺序从上到下;ID不同,值越大越先执行)
select_type:表示select的类型,常见的取值有simple(简单,即不使用表链接或者子查询)、primary(主查询,即外层的查询)、nuion(union中的第二个或者后面的查询语句)、subquery(select/where之后包含了子查询)等 【参考意义不大】
type:访问的类型。性能由快到慢->NULL,system、const、eq_ref、ref、range、index、all。
查询使用唯一索引,是const
非唯一索引 ref
使用索引,但是扫描了所有索引,是index
possible_key:
显示可能应用在这张表上的索引,一个或者多个。
Key:实际用到的索引,如果为NULL,则没有使用索引
Key_len:
使用到的索引的字节数,索引字段最大使用长度,并非实际使用长度。在不损失精确性的前提下,越短越好
rows:查询的行数。只是个估计值
filtered:返回结果行数占需读取行数的百分比,filtered 越大越好
Extra:额外查询的数据
重点关注的字段已经用红色标识出来
索引小姿势
最左原则:
1.字段ABC顺序组合为一个组合索引,如果where 条件中没有字段A,那么select 语句无法用到这个索引。
2.如果有ABC,无论顺序先where 谁,都会执行此符合索引。(ABC必须包含等号,包括>=,<=)
3.如果只有AC,则使用部分符合索引,使用的是A的。
4.就算ABC都有,但是如果B字段使用了范围查询(>号,<号),只使用部分索引AB两个字段。
索引失效:
索引列在where条件中,不要运算,运算索引列导致此索引失效
字符串索引,在where 条件中匹配此字段的值不加引号,索引失效。【例:字段status是varchar(10),查询语句 where status=200 将会全表扫描】
模糊匹配中:开头模糊将会造成索引失效。
OR 分割的条件,只有两侧条件都有索引的时候,索引才会生效
数据分布影响:如果mysql评估,使用索引比全表更慢,则不用索引当索引
例:当使用索引列进行where 筛选时,筛选出的结果,大于一半,则不使用索引
SQL提示
给查询语句一个提示,让SQL语句听我们的建议。(是优化数据库的一种重要手段)
use index(建议使用这个索引)
explain select * from tableA use index(idx_tableA_pro) where pro='条件'
ignore index(不建议使用这个索引)
force index(必须使用这个索引)
覆盖索引
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到),减少select *
Extra中:
using index condition:查找使用了索引,但是需要回表查询数据
using where; using index:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询。
前缀索引
当字段类型为字符串(varchar,text等)时,如果存储了一篇文章(文字较多时),查询会浪费大量的磁盘IO,影响查询效率。此时可以只将字符串的一部分前缀,建立索引,以节约空间,提升效率
语法:create index idx_xxx on table_name( column(N) );N 提取前几个字符来构建索引
前缀长度:尽量让索引选择性的值高一些。(不重复索引值(基数)和数据表总记录数的比值)
select count( distinct goods_name ) / count(*) from sp_goods; 1.00
select count( distinct substring(goods_name,1,5) ) / count(*) from sp_goods;0.8166索引设计原则
1.针对数据量较大,且查询比较频繁的表建立索引。(一般百万级就要建立索引了)
2.针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
3.尽量选择区分度高的列作为索引【参考-索引失效-数据分布影响】,尽量建立唯一索引,区分度越高,使用索引的效率越高。【状态字段,逻辑删除字段,性别字段等,就算创建了索引效率也不高,因为很容易触发索引失效】
4.字符串类型的字段,字段长度较长,可以针对字段特点,建立前缀索引。
5.尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表查询,提高查询效率
6. 控制索引数量,索引会影响表的增删改效率,还会占用磁盘空间
7.如果某一列在存储的时候,一定不会有NULL值,请在建表的时候,用 NOT NULL 来约束它。因为有 NOT NULL 加持的字段在建立所以后,优化器才能更好的来选择查询用的索引。
优化
插入优化
1.尽量用批量插入
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
2.手动提交事务
start transaction; // 或者 begin
insert into tb_test values(1,'Tom1');
insert into tb_test values(2,'Tom2');
insert into tb_test values(3,'Tom3');
commit;
3.主键顺序插入性能高--设计到 Mysql 的数据组织结构
量级如果很大(百万级),可以使用 load 指令
mysql --local-infile -u root -p
set global local_infile = 1;//查询此参数值可以用select @@global local_infile;
load data local infile '/root/sql1.log' into table 'tb_test' fields terminated by ',' lines terminated by '\n';
排序:
数据库将数据查询出来后,放入排序缓冲区进行排序,排序完毕后,再返回结果
有覆盖索引的字段(索引默认asc排序),如果select 的字段,覆盖索引都包含,那么不会进行排序缓冲区排序。
如果没办法,要select * (毕竟不可能所有字段都有索引,必将会进入排序缓冲区),此时数据量又很大。可以适当修改排序缓冲区大小来提高速度
show variables like 'sort_buffer_size'; //262144 默认256KB
例如:set @@sort_buffer_size = 524288主键优化
主键尽量有序,可以避免页分裂,(页合并)
Order by 优化、group by 优化,和select 差不多。
Limit 优化
以100000,10 为例,limit 的操作是先排序100010 条数据,然后取后10条。然后舍弃剩余数据,每次都排序这么多,造成性能浪费以及全表扫描。
select t.* from tb_sku t , (select id from tb_sku limit 100000,10) a where t.id=a.id
当以uuid 为主键时,非常不好,才160W数据,查询 limit 1000000,10 时,就算用上面的思路查询,也需要消耗30多秒。
Count 优化
MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行count(*) 的时候会直接返回这个数,效率很高。(这是没有where 条件的时候。)
InnoDB引擎就麻烦了,它执行count(*) 的时候,需要把数据一行一行地从引擎里面读取出来,然后累计计数。
优化思路:自己计数(在一些内存数据库中,记录一些key value值,当数据库增删操作的时候,更改对应的value,以实现快速记录总数。但这也不能实现 where 条件下的count 快速查询)
查询速度,mysql专门对 count(*) 进行了优化
Count (*) >= Count(1) > Count(主键) > Count(字段)
Update 优化
当 执行 update 的时候,where 跟的条件如果有索引且不能失效, 则此时对此行进行 行锁。
如果没有索引,则对此表进行表锁
视图存储过程触发器等
视图
创建视图
create [or replace] view sp_goods_v_1 as
select count( distinct substring(goods_name,1,6) ) / count(*) from sp_goods;查看视图
show create view sp_goods_v_1; // 查询这个视图的创建sql
select * from sp_goods_v_1; // 将视图当作表一样用。
修改视图
方法一:create [or replace] view sp_goods_v_1 as select 语句
方法二:Alter View sp_goods_v_1 as select 语句
删除视图
drop View [if exists] 视图名称
with check option
- create or REPLACE view test_pop
- as select primaryid,accountid,agentAccountId,groupid,childGroupId ,projectid,participationStatus,accessIP,createDateTime
- from POP
- limit 1000
- with CASCADED check option
- with local check option
with CASCADED check option 【默认】【进行级联递归检查】【例:v2(有 cascaded) 依赖 v1(无 check option),会检查v2的where条件,如果满足能过,会继续检查v1的where条件并判断是否满足 】
with local check option 【也会级联递归检查】【但是,级联检查时。如果上一层的视图没有check option则不进行条件判断。】
视图的作用,可以辅助数据库权限控制,将权限控制在字段级别。
也可以让一个复杂的联合查询,在应用起来变得简单
存储过程
创建、调用存储过程
- create procedure 存储过程名([参数列表])
- BEGIN
- -- SQL语句
- END;
- -- 调用
- CALL 存储过程名([参数列表]);
在linux 控制台中创建存储过程时,会遇见一个问题,控制台中默认将分号;当作一条sql语句的结束,遇见直接执行。为了避免还未输入完sql语句就被执行,我们可以用
delimiter
delimiter $$
create procedure p1()
begin
select count(*) from tableA;
end$$-- 此时控制台会将 $$看作结束符,不遇到这两个符号不执行sql语句
查看存储过程
-- 查询指定数据库的存储过程及状态信息
select * from information_schema.ROUTINES where routine_schema='数据库名称'-- 查询某个存储过程的定义
SHOW CREATE PROCEDURE 存储过程名;删除存储过程
drop PROCEDURE 存储过程名;
存储过程中的变量
系统变量是Mysql服务器提供,不是用户定义的,属于服务器层面。分为全局变量(GLOBAL)、会话变量(SESSION)。
查看系统变量
show [ session | global ] variables; -- 查看所有系统变量
show [ session | global ] variables like '......'; -- 可以通过like 模糊匹配方式查找变量
select @@[session | global] 系统变量名; -- 查看指定变量的值
设置系统变量
set [ session | global ] 系统变量名 = 值;
set @@[ session | global ]系统变量名 = 值;
注意:
如果没有指定session/global,默认是session,会话变量
mysql服务器重启之后,所设置的全局参数会失效,要想不失效,可以在/etc/my.cnf中配置
用户定义变量是用户根据需要自己定义的变量,用户变量不用提前声明,在用的时候直接用"@变量名"使用就可以。其作用域为当前链接。
赋值:
set @var_name = expr;
set @var_name:=expr; -- 强烈推荐 因为=号不仅赋值用,还可以用来比较。
select @var_name:=expr [,@var_name2:=expr2]...;
select 字段名 into @var_name from 表明;
使用
select @var_name;
注意:
用户自定义的变量不需要初始化或者赋值,只不过拿到的是 NULL 罢了。
局部变量是根据需要定义的在局部生效的变量,访问之前,需要 DECLARE 声明。可用作存储过程内的局部变量和输入参数,局部变量的范围是在其内声明的 BEGIN ... END 块。
声明:
DECLARE 变量名 变量类型 [DEFAULT ... ];
变量类型就是数据库字段类型:INT、BIGINT、CHAR、VARCHAR、DATE、TIME等。
赋值:
SET 变量名=值;
SET 变量名:=值;
select 字段名 into 变量名 from 表名...;
- create procedure p2()
- begin
- declare stu_count int default 0;
- -- set stu_count := 1;
- select count(*) into stu_count from table_STU;
- select stu_count;
- end;
例:
- create procedure p3()
- begin
- declare score int default 58;
- declare result varchar(10);
- if score >= 85 then
- set result:='优秀';
- elseif score >=60 then
- set result:='良好';
- else
- set result:='及格';
- end if;
- select result;
- end;
- call p3
存储过程的参数 类型 含义 备注 IN 该类参数作为输入,也就是需要调用时传入值 默认 OUT 该类参数作为输出,也就是该参数可以作为返回值 INOUT 即可作为输入参数也可作为输出参数 - CREATE PROCEDURE 存储过程名称([IN/OUT/INOUT 参数名 参数类型])
- BEGIN
- -- SQL语句
- END;
- create procedure p4(in score int,out result varchar(10))
- begin
- if score >= 85 then
- set result:='优秀';
- elseif score >=60 then
- set result:='良好';
- else
- set result:='及格';
- end if;
- end;
- call p4(98,@result);
- select @result;
- CREATE PROCEDURE p5(INOUT score DOUBLE)
- BEGIN
- set score := score * 0.5;
- END;
- set @score = 160;
- call p5(@score);
- select @score;
case 分支语句
- create procedure p6(in mth int)
- begin
- declare result varchar(10);
- case
- when mth >=1 and mth <=3 then
- set result := '第一季度';
- when mth >=4 and mth <=6 then
- set result := '第二季度';
- when mth >=7 and mth <=9 then
- set result := '第三季度';
- when mth >=10 and mth <=12 then
- set result := '第四季度';
- else
- set result := '未知季度';
- end case;
- select concat('输入的是',mth,'。属于',result) as 'res';
- end;
- call p6(12)

while 循环语法
- -- 从1 累加到n
- create procedure p7(in n int)
- begin
- declare total int default 0 ;
- while n>0 do
- set total := total + n;
- set n:=n-1;
- end while;
- select total;
- end;
- call p7(2)
-- 进行循环的时候,一定先循环一次,再去判定边界条件
repeat
SQL 逻辑
UNTIL 条件
end repeat;
游标
- create PROCEDURE p8()
- begin
- declare pid_str varchar(36);
- declare aid_str varchar(36);
- -- 游标的声明必须再其他变量之后,即最后
- declare u_cursor cursor for select primaryId,accountid from ProjectManagement_Online_ParticipationRecord where participationStatus<18;
- -- 退出游标
- declare exit handler for SQLSTATE '02000' close u_cursor;
- drop table if exists a_temp_testList;
- create table if not exists a_temp_testList(
- id int primary key auto_increment,
- primaryid varchar(36),
- accountid varchar(36)
- );
- -- 打开游标
- open u_cursor;
- while true do
- FETCH u_cursor into pid_str,aid_str;
- insert into a_temp_testList(primaryid,accountid) values(pid_str,aid_str);
- end while ;
- close u_cursor;
- end;
条件处理程序
- DECLARE handler_action HANDLER FOR condition_value [,condition_value]... statement;
- handler_action
- CONTINUE:继续执行当前程序
- EXIT:终止执行当前程序
- condition_value
- SQLSTATE sqlstate_value:状态码,如02000
- SQLWARNING:所有以01开头的SQLSTATE代码简写
- NOT FOUND:所有以02开头的SQLSTATE代码简写
- SQLEXCEPTION:所有没有被SQLWARNING或NOT FOUND捕获的SQLSTATE代码的简写
- -- 例:
- DECLARE exit HANDLER FOR SQLSTATE '02000' close u_cursor;
存储函数
存储函数是有返回值的存储过程,存储函数的参数只能是IN类型的。具体语法如下:
只要存储函数能实现的,存储过程也可以,并且存储函数必须有返回值,一般我们如果用,都会用存储过程,而非存储函数
- CREATE FUNCTION 存储函数名称([参数列表])
- RETURNS type [characteristic...]
- BEGIN
- -- SQL语句
- RETURN...;
- END;
- characteristic说明:
- DETERMINISTIC:相同的输入参数总是产生相同的结果
- NO SQL : 不包含SQL语句。
- READS SQL DATA: 包含读取数据的语句,但不包含写入数据的语句
- create function AddN(n int)
- RETURNS int DETERMINISTIC
- BEGIN
- declare total int default 0;
- while n>0 do
- set total:=total+n;
- set n:=n-1;
- end while;
- return total;
- END;
- select AddN(50);
触发器
介绍
触发器是与表有关的数据库对象,指在insert、update、delete之前或之后,触发并执行触发器中定义的SQL语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性,日志记录,数据校验等操作。
使用别名 OLD 和 NEW 来引用触发器中发生变化的记录内容,这与其他的数据库是相似的。现在触发器还只支持行级触发,不支持语句级触发。
触发器类型 NEW 和 OLD INSERT 型触发器 NEW表示将要或者已经新增的数据 UPDATE 型触发器 OLD 表示修改之前的数据,NEW 表示将要或已经修改后的数据 DELETE 型触发器 OLD 表示将要或者已经删除的数据 行级:一条UPDATE 语句更新了5条数据,触发器将被触发5次。
语句级:一条UPDATE 语句更新了5条数据,触发器将被触发1次。
创建触发器
CREATE TRIGGER trigger_name
BEFORE/AFTER INSERT/UPDATE/DELETE
ON tbl_name FOR EACH ROW -- 行级触发器
BEGIN
trigger_stmt;
END;查看触发器
SHOW TRIGGERS;
删除
DROP TRIGGER [schema_name.]trigger_name;
-- 如果没有指定schema_name,则默认当前数据库锁
全局锁
典型例:备份全表数据到一个.sql 文件。【多个表有关联时,可以确保数据的一致性】
-- 加全局锁(只能查不能增删改)
flush tables with read lock;
-- 直接在windows 下的命令行执行
mysqldump -h 192.168.1.2 -uroot -p1234 db01 > D:db01.sql;
-- 解全局锁
unlock tables;
在InnoDB引擎中,我们可以在备份时加上参数 --single-transaction 参数来完成不加锁的一致性数据库备份。【快照读实现】
mysqldump --single-transaction -h 192.168.1.2 -uroot -p1234 db01 > D:db01.sql;
表锁
加锁:lock tables 表名... read/write
解锁:unlock tables / 客户端断开连接元数据锁(Meta data lock,MDL)
MDL加锁过程是系统自动控制,无需显示使用,在访问一张表的时候会自动加上。MDL锁主要作用是维护表元数据的数据一致性,在表上有活动事务的时候,不可对元数据进行写入操作。
架构内存结构
show variables like '%log_buffer_size%' -- 默认16MB
show variables like '%flush_log%' --1:日志在每次事务提交时写入并刷新到磁盘
0:每秒将日志写入并刷新到磁盘一次
2:日志在每次事务提交后写入,并每秒刷新到磁盘一次。
如果MYSQL单独有一台服务器,几乎 80%的内存都会被分配给MYSQL的缓冲区(buffer pool),以此来提高MYSQL的效率。
当前读: select * from table lock in share mode ;
快照读:简单的select 就是快照读,读取的是记录的可见版本,有可能是历史数据,不加锁,是非阻塞读。
Read Committed :每次select,都生成一个快照读。
Repeatable Read:开启事务后第一个select语句才是快照读的地方。【默认】
Serializable:快照读退化为当前读。
MYSQL管理
mysql安装完毕后,自带4个数据库,以8.0以后为例
information_schema --元数据
mysql -- 正常运行需要的信息(时区、主从、用户、权限等)
performance_schema --提供一个底层监控,收集服务器性能参数
sys --方便开发人员利用performance_schema来进行调优和诊断的视图
MYSQL中常用工具
工具指令例:
mysql -h127.0.0.1 -P3306 -uroot -padmin mydb -e "select * from sp_user;"
mysqladmin -uroot -padmin create/drop db01
mysqlbinlog -s RM-10430-bin.000026/binlog.000011
mysqlbinlog [参数选项] logfilename
参数选项:
-d 指定数据库名称,只列出指定的数据库相关操作
-o 忽略掉日志中的前n行命令
-v 将行事件(数据变更)重构为SQL语句
-vv 将行事件(数据变更)重构为SQL语句,并输出注释信息
mysqlshow -uroot -padmin --count (展示有多少数据库,每个数据库有多少表,一共多少行)
mysqlshow -uroot -padmin mydb --count(mydb这个数据库有哪些表,都有多少列,每个表多少行数据)
mysqlshow -uroot -padmin mydb user --count(这个user表有哪些字段都是什么类型等)
mysqlshow -uroot -padmin mydb user -i (这个表的运行状态)
mysqldump
客户端工具用来备份数据库或者在不同数据库之间进行数据迁移。备份内容包含创建表,及插入表的SQL语句。
语法:
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all -databases/-A
连接选项:
-u,--user=name 指定用户命
-p,--password[=name] 指定密码
-h,--hos=name 指定服务器ip或域名
-P,--port=# 指定链接端口
输出选项:
--add-drop-database 在每个数据库创建语句前加上 drop database 语句
--add-drop-table 在每个表创建语句前加上drop table 语句
默认开启;不开启(--skip-add-drop-table)
-n,--no-create-db 不包含数据库的创建语句
-t,--no-create-info 不包含数据表的创建语句
-d,--no-data 不包含数据
-T,--tab=name 自动生成两个文件:一个.sql文件,创建表结构的
语句;一个.txt文件,数据文件
mysqldump -uroot -padmin mydb > mydb.sql (记得先切换到要保存的目录)
经常用 -t(只备份数据),或者 -d(只备份表结构)
-T 可以一次将表结构和数据都分开备份,具体用法如下
mysql -uroot -padmin -e "show variables like '%secure_file_priv%';" --查询安全目录
cmd 切换到安全目录
mysqldump -uroot -padmin -T /var/lib/mysql-flies/ db01 score
windows 中,需要cmd切换到安全目录后,执行
mysqldump -uroot -padmin123 -T ./ db01 score
mysqlimport 是客户端数据导入工具,专门导入mysqldump 加 -T 参数导出的文本文件
语法:
mysqlimport [options] db_name textfile1 [textfile2...]
示例:
mysqlimport -uroot -p1234 testdb /tmp/city.txt
如果要恢复.sql文件,可以用source命令。
需要mysql -uroot -p之后,
执行:
use mydb;
source E:\codeTest\test\mydb_user.sql (可以不用是安全目录)
binlog日志的功能
1.可以用来紧急恢复数据
2.可以用来做主从复制

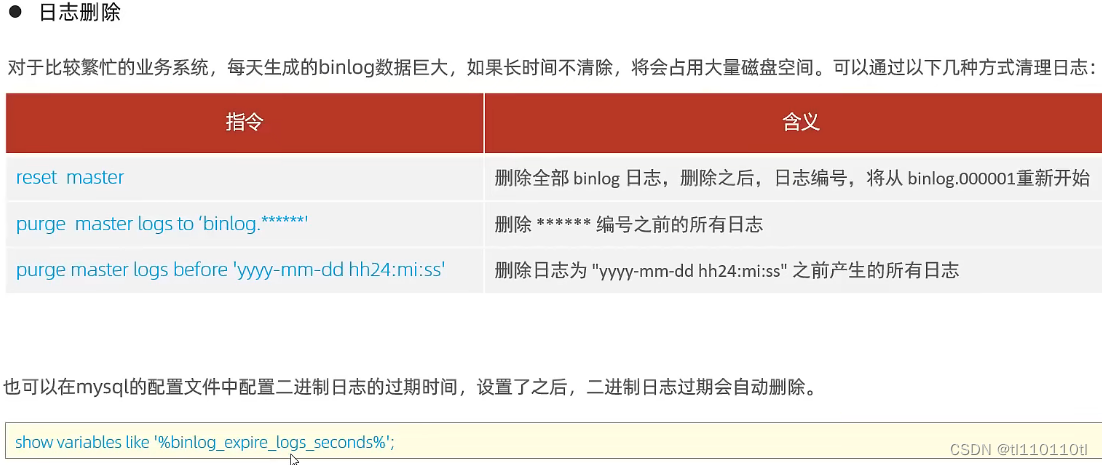
查询日志:一般用不上,因为所有的SQL语句都记录,文件太大,默认关闭,如需开启如下
general-log=1
general_log_file="myquery.log"
慢查询日志
记录了所有执行之间超过参数long_query_time设置值并且扫描记录数不小于min_examined_row_limit的所有的SQL语句的日志,默认未开启。long_query_time默认为10秒,最小为0,精度可以到微秒。
#慢查询日志
show_query_log=1
#执行时间参数
long_query_time=2
vim /etc/my.cnf 编辑mysql配置文件
systemctl restart mysqld 重启mysql服务
localhost-slow.log
默认情况下不记录管理语句,和不用索引的慢查询语句。可以通过一下配置开启
#记录执行较慢的管理语句
log_slow_admin_statements=1
#记录执行较慢的未使用索引的语句
log_queries_not_using_indexes=1
2.主从复制


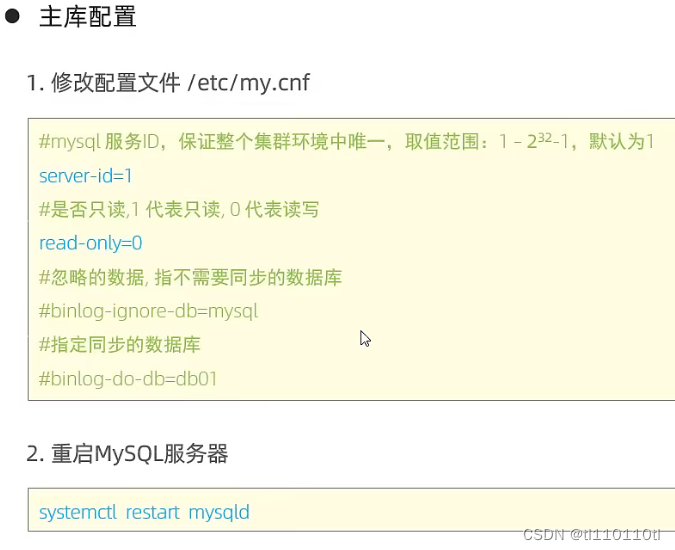

super-read-only=1 设置此项后可以让超级管理员权限也只读



MYCAT 介绍:8066
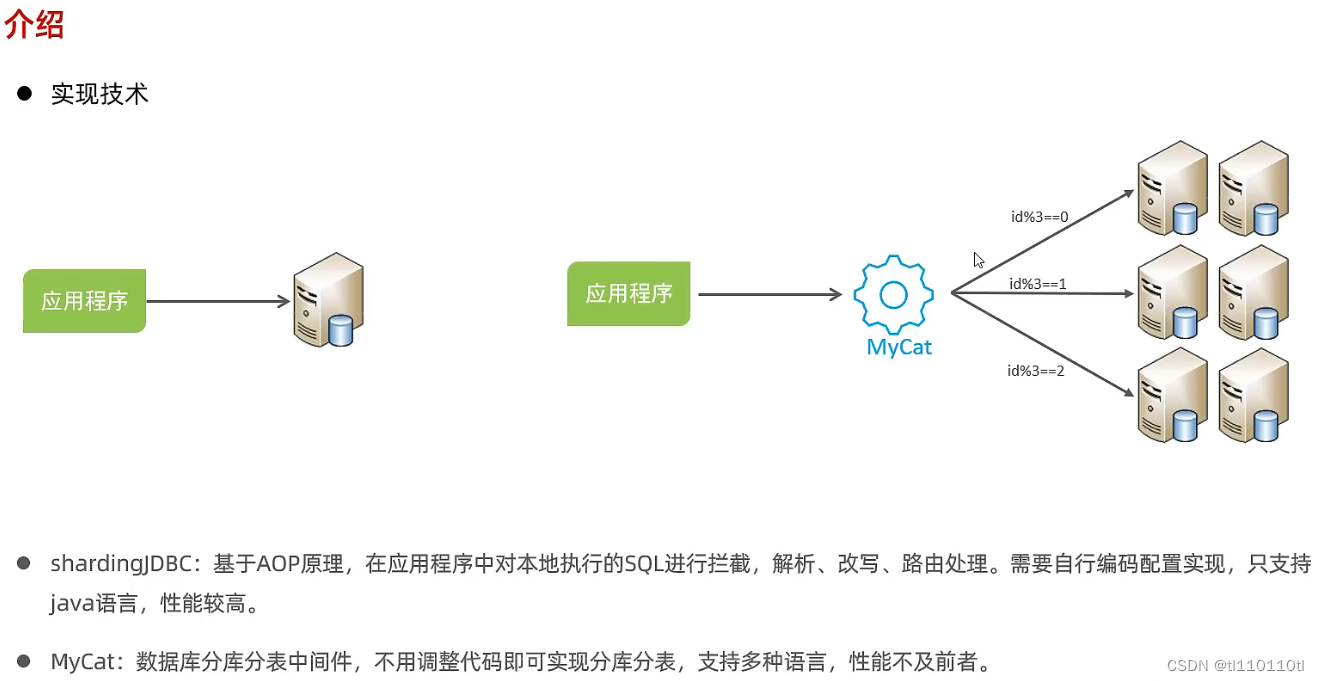


安装:
将mycat包上传服务器并解压(即算安装完毕)
需要注意的是,如果链接的是8.0以后的mysql数据库,需要将
【mysql-connector-java-XXX.jar】删除,并更换为mysql对应版本
例:【mysql-connector-java-8.0.22.jar】
并更新权限未777 【chmod 777 mysql-connector-java-8.0.22.jar】
测试使用
1.将所有涉及数据库中创建db01数据库。
2.编辑 [安装目录]/mycat/conf/schema.xml 文件,来配置mycat
【notepad++的插件名称为NppFTP】
- "1.0"?>
- mycat:schema SYSTEM "schema.dtd">
- <mycat:schema xmlns:mycat="http://io.mycat/">
- <schema name="DB01" checkSQLschema="true" sqlMaxLimit="100">
- <table name="TB_ORDER" dataNode="dn1,dn2" rule="auto-sharding-long" />
- schema>
- <dataNode name="dn1" dataHost="dhost1" database="db01" />
- <dataNode name="dn2" dataHost="dhost2" database="db01" />
- <dataHost name="dhost1" maxCon="1000" minCon="10" balance="0"
- writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
- <heartbeat>select user()heartbeat>
- <writeHost host="master" url="jdbc:mysql://10.21.31.107:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="123456" />
- dataHost>
- <dataHost name="dhost2" maxCon="1000" minCon="10" balance="0"
- writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
- <heartbeat>select user()heartbeat>
- <writeHost host="master" url="jdbc:mysql://10.21.27.7:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="123456" />
- dataHost>
- mycat:schema>
3.分片配置(server.xml)同上目录
- <user name="root" defaultAccount="true">
- <property name="password">123456property>
- <property name="schemas">DB01property>
- user>
- <user name="user">
- <property name="password">123456property>
- <property name="schemas">DB01property>
- <property name="readOnly">trueproperty>
- user>
4.启动测试mycat的分片操作(切换到Mycat的安装目录)
#启动
bin/mycat start
#停止
bin/mycat stop
#查看是否启动成功
tail -f logs/wrapper.log
5.会启动失败
一:jvm,即java目录不对,编辑mycat安装目录下conf目录下wrapper.conf文件
wrapper.java.command=java安装目录/bin/java
二:mycat默认3个分配规则,我们只设置了2个,会报错。
schema.xml中配置的schema节点下table节点中的rule规则为【auto-sharding-long】
此规则在rule.xml文件中进行搜索可得到rule节点下algorithm节点为【rang-long】,依然在rule.xml文件中搜索【rang-long】可找到function节点下property节点内容
【autopartition-long.txt】。找到并修改此文件内容为2部分即可
- # range start-end ,data node index
- # K=1000,M=10000.
- 0-500M=0
- 500M-1000M=1
- 1000M-1500M=2
- 变为
- # range start-end ,data node index
- # K=1000,M=10000.
- 0-500M=0
- 500M-1000M=1
至此即可启动成功








0:2,都指的是索引



/zookeeper-3.4.6/bin/zkServer.sh
- export JAVA_HOME=/datadrive/jdk1.8.0_171
- export PATH=$JAVA_HOME/bin:$PATH
- #!/usr/bin/env bash
- java环境符合要求
- 关于自己手动安装的Java的环境变量要求,网上有人说、etc/profile或者在、etc/environment中修改,自己在安装的时候都尝试过,最终还是修改了~/.bashrc才起作用,这个特别是在Ubuntu中,强烈建议修该~/.bashrc文件
- 打开该文件:vim ~/.bashrc
- 在文件的最后添加如下内容:
- export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_79
- export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:/usr/local/mysql/bin:$PATH
- export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASSPATH
- 运行命令使修改立即生效:source ~/.bashrc






-
相关阅读:
学习笔记|回顾(1-12节课)|应用模块化的编程|添加函数头|静态变量static|STC32G单片机视频开发教程(冲哥)|阶段小结:应用模块化的编程(上)
使用vite 搭建vue 3的项目
Spring Security 核心解读(一)整体架构
文件上传漏洞(1), 文件上传绕过原理
归并排序(java)
使用HBuilderX将vue或H5项目打包app
智慧构思:智能合约技术精髓与价值转化 ——华为云BCS区块链服务
蓝牙核心规范(V5.4)11.1-LE Audio 笔记之诞生的前世今生
现代 CSS 解决方案:数学函数 Round
纯函数 和 函数柯里化 ( 函数式编程 )05
- 原文地址:https://blog.csdn.net/tl110110tl/article/details/127422773
