-
基于Tensorflow的图像特效合成算法研究
目 录
摘 要 I
ABSTRACT II
第一章 绪论 1
1.1 课题简介及目的 1
1.2 课题研究意义 2
1.3 研究现状和发展趋势 2
1.4 本文的结构安排 3
第二章 算法的开发环境简介 4
2.1 Python 4
2.2 Ubuntu 4
2.3 Visual Studio Code 4
2.4 ROCm GPU加速器 5
2.5 TensorFlow-ROCm 5
2.6 Keras 5
2.7 Scipy 5
第三章 算法所需技术介绍 6
3.1 卷积神经网络(CNN) 6
3.2 生成对抗网络(GAN) 7
3.3 Pix2pix模型 11
3.4 CycleGAN网络 14
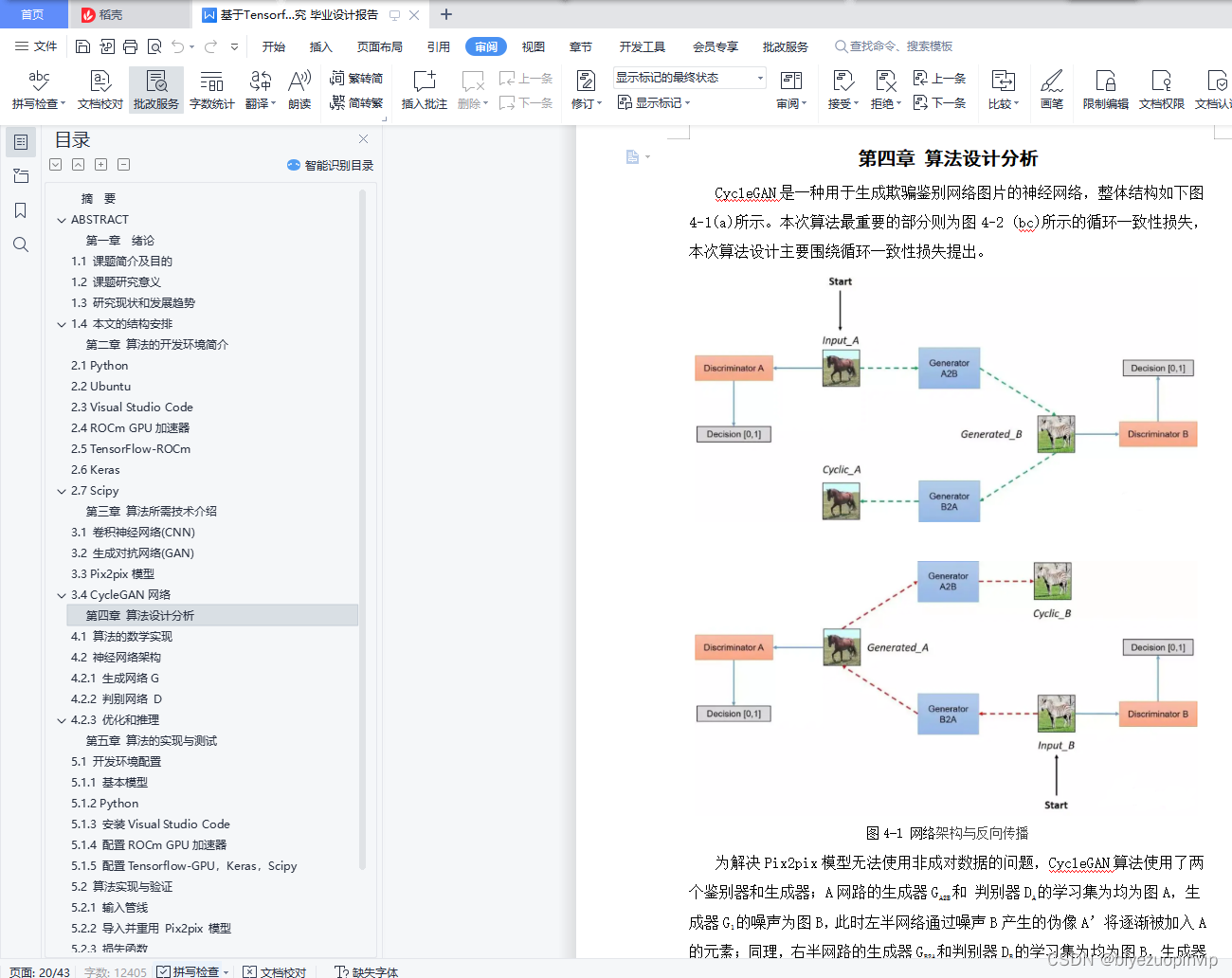
第四章 算法设计分析 17
4.1 算法的数学实现 18
4.2 神经网络架构 19
4.2.1 生成网络G 19
4.2.2 判别网络 D 20
4.2.3 优化和推理 21
第五章 算法的实现与测试 22
5.1 开发环境配置 22
5.1.1 基本模型 22
5.1.2 Python 22
5.1.3 安装Visual Studio Code 22
5.1.4 配置ROCm GPU加速器 23
5.1.5 配置Tensorflow-GPU,Keras,Scipy 24
5.2 算法实现与验证 26
5.2.1 输入管线 26
5.2.2 导入并重用 Pix2pix 模型 29
5.2.3 损失函数 31
5.2.4 模型训练 33
第六章 总结与未来展望 38
参考文献 39
致谢 40
第三章 算法所需技术介绍
本章节将介绍本文中使用的几种神经网络技术,主要包括主要用于判别器的卷积神经网路CNN、用于生成器的生成对抗网络GAN以及本文使用的参考的pix2pix和CycleGAN两种神经网络模型。
3.1 卷积神经网络(CNN)
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,对于大型图像处理有出色表现,卷积神经网络的神经元具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification)。
CNN是由一个或多个卷积层以及顶部的全连接层(对应于经典神经网络)组成的,同时还包括关联权重和池化层。这种结构使得卷积神经网络可以充分利用输入数据的二维结构。在图像和语音识别中,卷积神经网络比其它深度学习方法具有更好的识别效果。该模型还可以用反传算法进行训练。与其它深度、前馈神经网络相比,卷积神经网络考虑的参数较少,因而成为一种吸引人的深度学习结构。
传统神经网络和卷积神经网络的结构如图3-1 3-2:
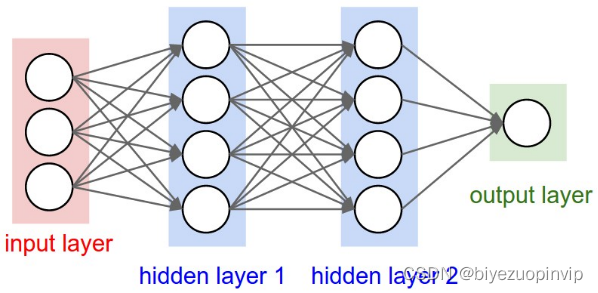
图3-1 传统神经网络模型

图3-2 卷积神经网络模型
卷积神经网络的输入和输出均为三维:width, height, depth(注意这个 depth并非神经网络的深度,而是用于描述神经元),例如,输入图像的尺寸为(32,32,3),那么输入神经元的维数为32323。卷积神经网络的激励函数包含多种,但不是全部都拥有参数。
利用损失函数L1和L2建立的图像是比较模糊的,也就是说,L1和L2不能很好地恢复图像中较清晰的部分(例如:图像的边缘),但却能很好地恢复颜色部分(例如,图像中的色块)。
一般来说图像的高频与低频是对图像各个位置之间强度变化的一种度量方法。图片的高频部分主要是图像边缘和轮廓,低频部分为图像的色块。所以L1和L2两个损失函数对图像的高频部分处理并不理想。
本文判别网络部分基本沿用Pix2pix的判别网络,采用 PatchGAN结构,即将图像等分为若干个固定大小的 Patch,分别判断每个 Patch的真假,最后取平均值作为判别器D的最终输出结果。
这样做的好处:
1.判别器D的输入变小,计算量小,训练速度快。
2.因为生成器G全由反卷积组成,所以对没有图片大小限制。而D是按照Patch去处理图像,所以也对图像大小没有限制。本文转载自http://www.biyezuopin.vip/onews.asp?id=13248所以整个 Pix2pix 程序架构并没有限制图像尺寸,增强了算法的泛用性。
CycleGAN原论文[1]中将判别器D看成另一种形式的纹理损失或样式损失,但由于本文中利用PatchGAN代替了原有的VGG19判别器所以需要更改输入输出的尺寸。在具体实验中,发现选择28283的尺寸比较合理。
4.2.3 优化和推理
训练使用神经网络标准方法交替训练 D 和 G;使用了比较常规的随机梯度下降(SGD) 和Adam两种优化器。
分离测试集和学习集,不使用学习集进行测试,防止网络过拟合;并且在测试和最终阶段使用 dropout 和 batch normalization使神经网络训练速度加快,更容易收敛。def random_crop(image): cropped_image = tf.image.random_crop( image, size=[IMG_HEIGHT, IMG_WIDTH, 3]) return cropped_image # 将图像归一化到区间 [-1, 1] 内。 def normalize(image): image = tf.cast(image, tf.float32) image = (image / 127.5) - 1 return image # 调整大小为286*286*3 def random_jitter(image): image = tf.image.resize(image, [286, 286], method=tf.image.ResizeMethod.NEAREST_NEIGHBOR) # 随机裁剪到 256 x 256 x 3 image = random_crop(image) # 随机镜像 image = tf.image.random_flip_left_right(image) return image def preprocess_image_train(image, label): image = random_jitter(image) image = normalize(image) return image def preprocess_image_test(image, label): image = normalize(image) return image 数据集选用Tensorflow_ datasets中的horse2zebra数据集,以下为加载数据集和创建输入管线的代码: dataset, metadata = tfds.load('cycle_gan/horse2zebra', with_info=True, as_supervised=True) train_horses, train_zebras = dataset['trainA'], dataset['trainB'] test_horses, test_zebras = dataset['testA'], dataset['testB']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35















-
相关阅读:
Mac环境下,简单反编译APK
C#单元测试入门举例
uniapp项目笔记
IDM(Internet Download Manager)2024中文版下载工具软件
【Redis面试】基础题总结(下)
【Unity】U3D TD游戏制作实例(五)防御塔设计:对象排序、锁定敌人、攻击敌人、防御塔特色功能实现
多层感知机(PyTorch)
spring学习笔记-IOC,AOP,事务管理
CSS属性: 过度效果属性transition
Vue项目实战之人力资源平台系统(二)登录模块
- 原文地址:https://blog.csdn.net/newlw/article/details/127405301
