-
[平台运维、Hadoop]kafka streams概述

目录
一、 kafka streams概述
Kafka Streams是Apache Kafka开源项目的一个流处理框架,它是基于Kafka的生产者和消费者,为开发者提供了流式处理的能力,具有低延迟性.高扩展性、高弹性、高容错性的特点,易于集成到现有的应用程序中。
KafkaStreams是一套处理分析Kafka中存储数据的客户端类库,处理完的数据可以重新写回Kafka,也可以发送给外部存储系统。作为类库,可以非常方便地嵌人到应用程序中,直接提供具体的类供开发者调用,而且在打包和部署的过程中基本没有任何要求,整个应用的运行方式主要由开发者控制,方便使用和调试。
二、kafka streams开发单词计数应用
(步骤一)编写代码
①创建名为LogProcessor的Java class

② 编写LogProcessor.java代码
- package cn.itcast;
- import org.apache.kafka.streams.processor.Processor;
- import org.apache.kafka.streams.processor.ProcessorContext;
- import java.util.HashMap;
- public class LogProcessor implements Processor<byte[],byte[]> {
- //上下文对象
- private ProcessorContext processorContext;
- @Override
- public void init(ProcessorContext processorContext) {
- //初始化方法
- this.processorContext=processorContext;
- }
- @Override
- public void process(byte[] key, byte[] value) {
- //处理一条消息
- String inputOri = new String(value);
- HashMap
- int times = 1;
- if(inputOri.contains(" ")){
- //截取字段
- String [] words = inputOri.split(" ");
- for (String word : words){
- if(map.containsKey(word)){
- map.put(word,map.get(word)+1);
- }else{
- map.put(word,times);
- }
- }
- }
- inputOri = map.toString();
- processorContext.forward(key,inputOri.getBytes());
- }
- @Override
- public void close() {}
- }
③ 创建名为App的Java class
④ 编写App.java代码
- import org.apache.kafka.streams.KafkaStreams;
- import org.apache.kafka.streams.StreamsConfig;
- import org.apache.kafka.streams.Topology;
- import org.apache.kafka.streams.processor.Processor;
- import org.apache.kafka.streams.processor.ProcessorSupplier;
- import java.util.Properties;
- public class App {
- public static void main(String[] args) {
- //声明来源主题
- String fromTopic = "testStreams1";
- //声明目标主题
- String toTopic = "testStreams2";
- //设置参数
- Properties props = new Properties();
- props.put(StreamsConfig.APPLICATION_ID_CONFIG,"logProcessor");
- props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"master:9092,slave1:9092,slave2:9092");
- //实例化StreamsConfig
- StreamsConfig config = new StreamsConfig(props);
- //构建拓扑结构
- Topology topology = new Topology();
- //添加源处理节点,为源处理节点指定名称和它订阅的主题
- topology.addSource("SOURCE",fromTopic)
- //添加自定义处理节点,指定名称,处理器类和上一个节点的名称
- .addProcessor("PROCESSOR", new ProcessorSupplier() {
- @Override
- public Processor get() {//调用这个方法,就知道这条数据用哪个process处理,
- return new LogProcessor();
- }
- },"SOURCE")
- //添加目标处理节点,需要指定目标处理节点的名称,和上一个节点名称。
- .addSink("SINK",toTopic,"PROCESSOR");//最后给SINK
- //实例化KafkaStreams
- KafkaStreams streams = new KafkaStreams(topology,config);
- streams.start();
- }
- }

(步骤二)执行测试
① 在master节点创建testStreams1和testStreams2主题
$ bin/kafka-topics.sh --create --topic testStreams1 --partitions 3 --replication-factor 1 --zookeeper master:2181,slave1:2181,slave2:2181$ bin/kafka-topics.sh --create --topic testStreams2 --partitions 3 --replication-factor 1 --zookeeper master:2181,slave1:2181,slave2:2181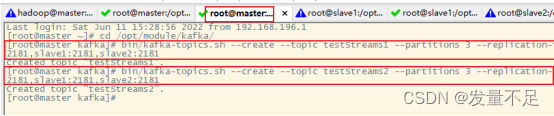
② 启动生产者服务命令
bin/kafka-console-producer.sh --broker-list master:9092,slave1:9092,slave2:9092 --topic testStreams1
③ 启动消费者服务命令
bin/kafka-console-consumer.sh --from-beginning --topic testStreams2 --bootstrap-server master:9092,slave1:9092,slave2:9092
④ 再运行App.java程序
⑤ 在master节点输入任意数据,按enter键发送,在slave1节点上可以查看到消息
输入内容如下:Hello itcast hello spark hello kafka,结果如下图


-
相关阅读:
为什么别人家的ChatGPT比我家的更聪明?
【JS】Chapter11-正则&阶段案例
Hadoop生态之hive
MySQL高级学习笔记(二)
【PPT制作】基础篇
halcon自定义函数基本操作
最长算术(暑假每日一题 11)
性能测试常见问题总结
在 VMware vSphere 中构建 Kubernetes 存储环境
代码随想录-015-剑指Offer206. 反转链表
- 原文地址:https://blog.csdn.net/m0_57781407/article/details/127131830