-
创建并运行一个 Spring项目
创建并运行一个 Spring项目
第一个 Spring 项目
步骤

1. 创建一个 spring 项目
(1) 创建一个 maven 项目
spring 是基于 maven 项目的,所以我们首先就要选择 maven 项目。

(2) 添加 spring 框架支持 ( spring-context + spring-beans )
注意:
从 maven 仓库中找到这两个依赖,最好将两者的版本选择一样的。
<dependency> <groupId>org.springframeworkgroupId> <artifactId>spring-contextartifactId> <version>5.3.18version> dependency> <dependency> <groupId>org.springframeworkgroupId> <artifactId>spring-beansartifactId> <version>5.3.18version> dependency>(3) 配置国内源
我需要事先声明,配置国内源的时候,应在网络良好的情况下配置,否则在后续运行 spring 项目的过程中,可能会出现奇奇怪怪的异常。

settings.xml 文件中的内容:
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd"> <pluginGroups> pluginGroups> <proxies> proxies> <servers> servers> <mirrors> <mirror> <id>alimavenid> <name>aliyun mavenname> <url>http://maven.aliyun.com/nexus/content/groups/public/url> <mirrorOf>centralmirrorOf> mirror> mirrors> <profiles> profiles> settings>里面最重要的就是设置国内镜像,我当前设置的是 " 阿里云 "。

(4) 创一个启动类并添加 main 方法
2. 将 bean 对象存储到 spring 容器中
(1) 在 spring 项目中添加配置文件
在 【 resources 】目录下创建【 spring-config.xml 】文件,并往里面放入代码。
注意:
这里的【 resources 】目录不能选错,而 " xml 文件 " 的名字可以自定义,但是最好和我一样,顾名思义,它代表 " spring 配置文件 ",这是一种规范。
【 spring-config.xml 】代码:
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> beans>(2) 创建一个 bean 对象
假设我们创建一个 User 类,并计划外面往里面传入一个 name 参数。
(3) 将 bean 对象通过配置文件注册到 spring 中
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id="user" class="beans.User"> bean> beans>将 bean 标签中的," id " 和 " class " 想象成一种 Map 键值对结构,后续通过 " id ",就可以得到 " class " 类种的一些信息。
注意:
" class " 的写法是固定的,精确到哪个包下的哪个类。
" id " 的写法是非固定的,但是最好写成小驼峰,并与类的名字联系起来。这样有两点好处,一是对外规范;二是下次利用 " id " 从 spring 容器中取对象的时候,可以很好地记忆。
3. 将 bean 对象从 spring 中取出来
(1) 在启动类中,先得到 spring 上下文对象
(2) 通过上下文对象提供的方法,获取我们自己需要使用的 bean 对象
(3) 使用 bean 对象public class Run { public static void main(String[] args) { // 1. 得到 spring 上下文对象 ApplicationContext context = new ClassPathXmlApplicationContext("spring-config.xml"); // 2. 根据上下文对象提供的方法获取到 bean User user = (User) context.getBean("user"); // User user1 = new User(); // 传统写法 // 3. 使用 user.hello("李明"); } }展示结果:

注意
注意1
1. 在上面的代码中,我们和以往的做法不同,以往是通过 new 一个 User 类,来创建一个 user 对象。而当前的做法是,我们先往 spring 容器中放对象,然后再将对象取出来。
至于为什么要这么做,我的上一篇博客就介绍到了它的关键之处:解耦。
我们平时利用 new 的方式创建一个对象,当我们对于类的构造方法进行改变时 ( 比方说临时加一个参数 ),那么,一个项目中所有用到 User 类的其他类,就统统需要修改。然而,利用 spring 容器作为中间介质,情况就不同了,从 spring 取出来的对象,是不依赖原始类的,也就是说,当我们之前的 User 类发生了改变,与 spring 中的对象毫无关联。
注意2
2. 在 main 方法中,一些关于 spring 配置文件的参数,在传入方法的时候,不能出错,否则就会出现这样那样的异常。所以,在我们之前配置 " xml " 文件的时候,就需要保持规范。
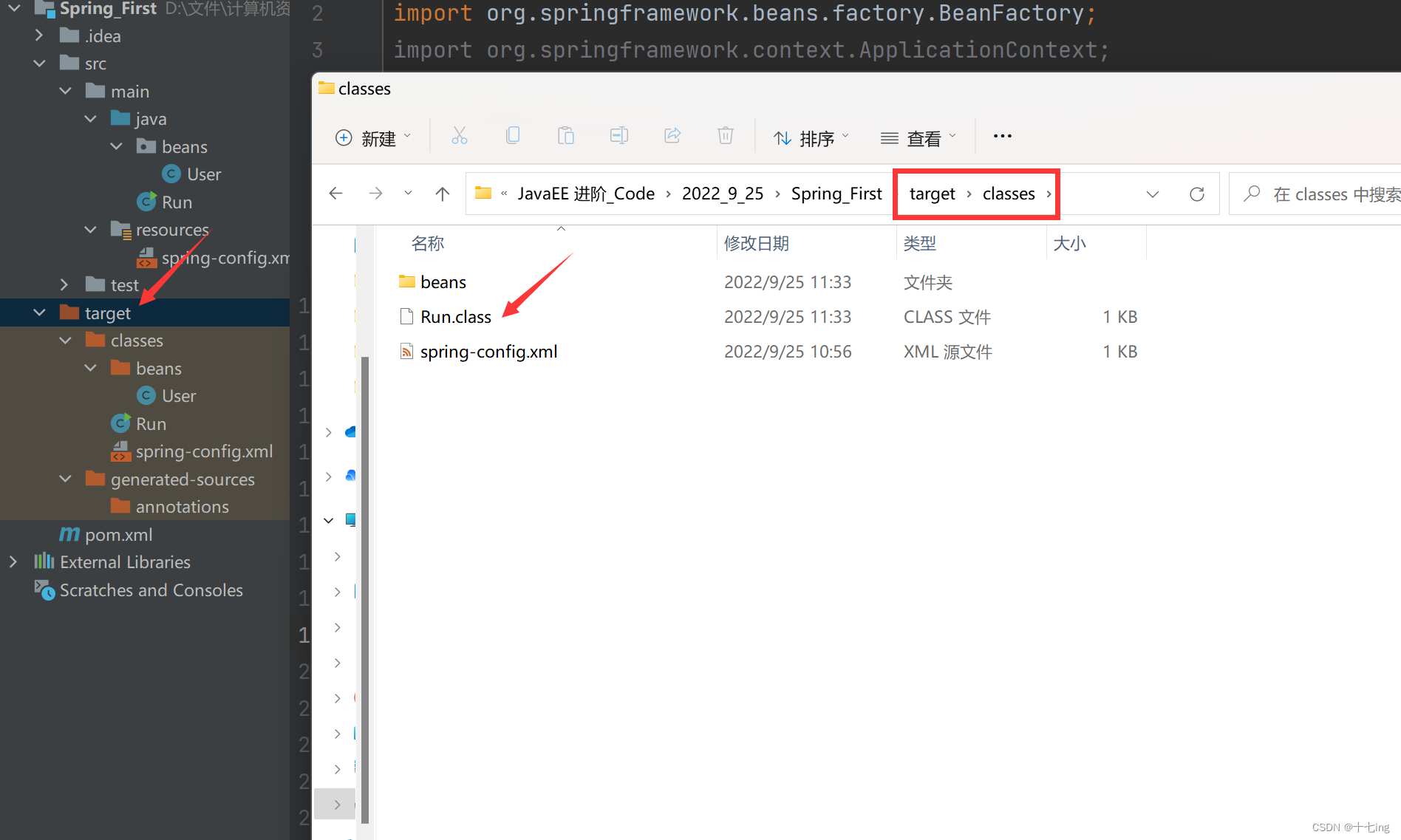
如果修改之后,编译过程的代码没问题,但依旧出现了异常,这可能就是缓存的问题。这时候,我们就需要手动删除 【target】目录下的所有文件,再次编译。因为 JVM 实际上最终运行的是 " .class " 文件,我们只需要把之前缓存的 " .class " 文件清空,再次利用 IDEA 编译的时候,就会重新生成 " .class " 文件,这样就可能有效果。
注意3 ( 经典面试题 )
3. 在上面的例子中,我们获取 spring 上下文对象,是通过 ApplicationContext 这个类来完成的,实际上,我们也可以通过 BeanFactory 这个类 来作为 spring 的上下文对象。
public class Run { public static void main(String[] args) { // 1. 得到 spring 上下文对象 BeanFactory beanFactory = new XmlBeanFactory(new ClassPathResource("spring-config.xml")); // 2. 根据上下文对象提供的方法获取到 bean User user = (User) beanFactory.getBean("user"); // 3. 使用 user.hello("杰克"); } }展示结果:

就因为上面的两个不同的获取对象方法,所以引入了一个经典面试题:
谈谈 ApplicationContext 和 BeanFactory 之间的区别和联系。
(1) 相同点:都可以利用 " getBean 方法 ",从容器中获取 bean 对象。
(2) 不同点:
① ApplicationContext 属于 BeanFactory 的子类,BeanFactory 只提供了基础访问Bean 的方法,而 ApplicationContext 除了拥有 BeanFactory 的所有功能之外,还拥有一些独立的特性,比如对国际化的支持、资源访问的支持、以及事件和传播等方面的支持。因为在 Java 中,一般来说,子类继承父类,那么子类直接就会拥有父类的功能,然而,对于父类来说,子类拥有的独立特性,父类很多是没有的。因为这些独立的特性,就是子类衍生出来的,也是作为区分父类的一种表现形式。
② 从性能方面来说二者是不同的,BeanFactory 是按需加载,它很像单例模式中的懒懒汉模式,当我们需要用到了某个 bean 对象,它才会临时加载。
然而,ApplicationContext 是饿汉模式,在我们创建此类的时候,它会一次性地将所有的 bean 对象都加载起来,以备后续使用。怎么验证呢?我们可以再创建一个 " Admin " 类,然后在 " Admin " 和 " User " 的构造方法中,做一些打印处理,然后在启动类的 main 方法中,看看两个类的加载的现象即可。结果就是,ApplicationContext 直接加载了 " Admin " 和 " User " ,而 BeanFactory 什么也没做。
③ 二者并无好坏,只能说根据场景自由选择吧,但是,ApplicationContext 确实是我们日常开发中,用的最多的情况。
注意4
4. 上述的 " getBean 方法 " 有很多重载,传入的参数可以由我们自己控制。
// 1 User user = (User) context.getBean("user"); // 2 User user = context.getBean(User.class); // 3 User user = context.getBean("user", User.class);第二种不建议使用,虽然写法简单,但容易出问题。当同一个类多次被注入到 spring 中的时候,就会出现异常。
第三种建议使用,因为它指明了当前需要找寻的是哪个类,所以就避免了强制转换这样的麻烦事。
第二个 Spring 项目
在上面的第一个 Spring 项目中,我们是通过将 bean 对象通过配置文件注册到 spring 中,之后再从配置文件中取出对象来,这一部分需要我们手动去输入 " id " 和 " class " 属性。
而在我们即将实现的第二个 Spring 项目中,我们是完全通过注解的方式进行了,这样一来,就可以更简单的存储对象和读取对象了。
如果说第一个 Spring 项目是一个手动挡的汽车,那么第二个 Spring 项目就是一个自动挡的汽车,因为实际上,一个注解就只有一行代码而已,通过注解这样的方式,很多工作并不需要我们自己动手去做,而是交给 spring 框架去做。
1. 搭建项目环境
(1) 创建一个 maven 项目
(2) 添加 spring 框架支持 ( spring-context + spring-beans )
(3) 配置国内源
(4) 创一个启动类并添加 main 方法
(5) 配置 " spring-config.xml " 文件前 4 步,在第一个 spring 项目中,已经体现出来了。现在,我们来实现第 5 步。
我们在 spring-config.xml 添加如下配置:
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:content="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd"> <content:component-scan base-package=" "> content:component-scan> beans>其中有一个 " base-package " 这样的属性十分重要!它表明了我们所有存放到 spring 中的 bean 的根路径。
如下图所示,只要我们涉及 spring 的类,就必须放在当前的 " beans " 包下,或者重新创建一个包 " abc " ,把类放在 " abc " 包下,但是 " abc " 包也应该在 " beans " 包下。也就是说," beans " 目录可以是 spring 类的父级目录,也可以是 " 爷爷目录 ",依然可以是 " 祖先目录 " …但不能是子孙目录。

2. 将 bean 对象存储到 spring 容器中
要想简单地将对象存储在 Spring 中,有如下两种注解类型可以实现。
必须明确,两种注解都是 spring 框架提供的,也就是从我们之前从 maven 仓库引入的依赖所提供的。两种注解实际上在底层就是对应着各自的 " .class " 文件。(1) 类注解:
@Controller、@Service、@Repository、@Component、@Configuration.(2) 方法注解:
@Bean.(1) 类注解
创建一个 UserController 类,作为 bean 对象。

在 UserController 类的上方,添加一个 " @Controller " 注解。
@Controller public class UserController { public void hello() { System.out.println("你好,Controller"); } }在启动类中,我们通过 " getBean " 方法进行测试,结果发现并没有问题。
public class Run { public static void main(String[] args) { // 1. 得到 spring 上下文对象 ApplicationContext context = new ClassPathXmlApplicationContext("spring-config.xml"); // 2. 根据上下文对象提供的方法获取到 bean UserController userController = context.getBean("userController", UserController.class); // 3. 使用 userController.hello(); } }
注意
注意1 五个类注解之间的联系
1. 在上面的程序中,我只测试了一个 " @Controller " 注解,如果我们使用其他四个类注解,在当前的打印功能上,它们其实都是一样的,我就不额外展示了。
但是我们应该着重理解这五个类注解,到底都是什么意思?能用来干什么?它们之间有什么区别和联系?
如下图所示,在一个企业项目中,最少会有下面的四层,或许会比四层多,但一定不会比下面的四层少。这四层,我们利用这四个注解来进行解释。

@Configuration:配置层
配置层用于存放当前项目的所有配置,其实在我们日常学习的时候,感受不到配置文件的分层问题,因为,平时我们可能不做项目,就将一个项目的所有文件放在一个目录下。而在实际的工作开发中,一个项目,可能有成千上万个文件,多数情况下,这些目录并不仅仅只有你的代码,也有你同事的代码。而配置层就可以通过一些配置类,来管理这些文件。当我们需要对当前项目的一些配置进行修改、维护的时候,只需要利用这一层来实现即可。
@Controller:控制层
控制层主要用作前端参数校验。比方说,现在我们通过前端登录一个网站,那么我们至少需要输入账号和密码这两个参数供后端验证,那么此时,就可以利用控制层来实现登录逻辑,验证成功后,才能到达下一层 " @Service ",验证失败,直接返回错误给前端用户。
举个例子:这就和当下疫情一样,当你的健康码是绿码的时候,你才能通行,否则,就可能需要马上去做核酸…那么控制层的作用就体现出来了,它就像安检关卡一样。
@Service:服务层
服务层主要实现了数据的组装和接口调用。
@Repository:数据持久层 ( DAO 层 )
数据持久层直接与数据库打交道,在这一层,可以实现数据库的增删查改。
@Component:上面四个注解的 " 父亲 "
查看上面四个注解的源码,就可以发现,它们四个都有 " @Component ",说明它们本身就是基于 " @Component " 实现的,换句话说,它们四个就是 " @Component " 的 " 孩子 "。

总结:一个 spring 项目为什么要分层呢?
举个例子,当我们去某家公司面试,公司会有 Java 面试的地方、前端面试的地方、C++ 面试的地方,这些地方我们可以理解为【配置层】分配好的区域。假设我们去面试 Java 后端工程师,首先,我们需要通过安检,出示我们的健康码,如果是绿码才能正常进入公司,此时这个安检就可以理解为【控制层】。当我们通过了安检,可能就会有服务人员告诉你,Java 面试在某某楼、某某房间,你需要通过他给你的提示路线,才能找到具体的面试地点,此时服务人员就可以理解为【服务层】。只有你到达了最终目的地,面试官才能面试你,那么最后一步,我们才能视为【持久层】。
再回到上面的问题,在实际项目中,我们不可能通过一次执行,就直接对数据库进行操作,这不符合权限、也不安全,更不科学。
注意2 BeanName 的命名规则
打开下面的一个类文件,查看底层类的源码,滑动到页面最后,打开 " decapitalize " 方法,再看其源码。

这一段源码核心地方在于下面的红框部分,如果第一个字母和第二个字母都是大写,那么直接返回;否则,就会将第一个字母变成小写,再返回。 现在,我们使用 " getBean " 方法,传入的参数就有依据了。
此外,值得注意的是,这是 JDK 提供的标准。

在下面,对源码进行测试,最终发现与我们理解的是一致的。
public class test { public static void main(String[] args) { String str1 = "UserController"; String str2 = "APIController"; System.out.println(Introspector.decapitalize(str1)); System.out.println(Introspector.decapitalize(str2)); } }
综上所述,我们在今后使用 " getBean " 方法的时候,就只应该注意我们自己定义类的前两个字母即可,如果前两个字母都是大写,传入的就是原类名;反之,就将第一个字母变成小写即可。
UserController userController = context.getBean("userController", UserController.class); APIController apiController = context.getBean("APIController", APIController.class);(2) 方法注解
@Controller public class UserBean { @Bean public User user1() { User user = new User(); user.id = 1; user.name = "露丝"; return user; } @Bean(name = {"user", "userinfo"}) public User user2() { User user = new User(); user.id = 2; user.name = "杰克"; return user; } }注意
(1) " @Bean " 需要和五大类注解配合使用,才能生效。
(2) " @Bean " 只能放在方法上面,将当前方法返回的对象,存储到 spring 容器中。
(3) 使用 " @Bean " 存储到 spring 容器后,再从容器中取出来 bean 对象时,对传入 " getBean " 方法的参数,也有讲究。如果当前没有重命名,就传入 " @Bean " 注释的方法名;如果对 " @Bean " 重命名了,那么就只能使用新的名字,原来的方法名失效。重命名的规则很简单,在 " @Bean " 后面加上 name 数组即可,可以重新使用多个名字。
对上面的程序进行验证:
User user = context.getBean("user1", User.class); // true User user = context.getBean("user2", User.class); // false User user = context.getBean("user", User.class); // true User user = context.getBean("userinfo", User.class); // true3. 对象装配来获取 bean 对象
以往我们是通过 new 一个对象的传统写法,来从一个类中拿到外部类的对象。现在,我们使用对象装配的方式将一个类的对象放到另一个类中。对象装配也叫做对象注入,实际上就是将 bean 对象取出来放到某个类中,接着就可以在这个类中,直接使用 bean 对象了。
对象注入的实现方法有下面三种:
(1) 属性注入
(2) 构造方法注入
(3) Setter 注入(1) 属性注入 bean 对象 ( 字段注入 )
我们往 " UserController " 类中,注入 " UserService " 类的对象,之后,我们就可以通过 " UserController " 类拿到 " UserService " 类的字段、方法等数据了。下面的 Run 启动类,只是用来测试一下,对象装配是否成功。

注意
以往我们是通过 new 一个对象的传统写法,来从一个类中拿到外部类的对象。
UserService userService = new UserService();现在,我们是通过属性注入的方式,拿到外部类的 bean 对象。
但使用属性注入的前提是,我们需要保证被注入的对象是一个 bean 对象,也就是说,它得包含五大类注解才行。@Autowired private UserService userService;这就像:一个容器里面装了一个大盒子,这个大盒子又装了一个小盒子。
当我们从 Spring 容器中,将 UserController 这个大盒子取出来的时候,UserService 这个小盒子,也会被取出来。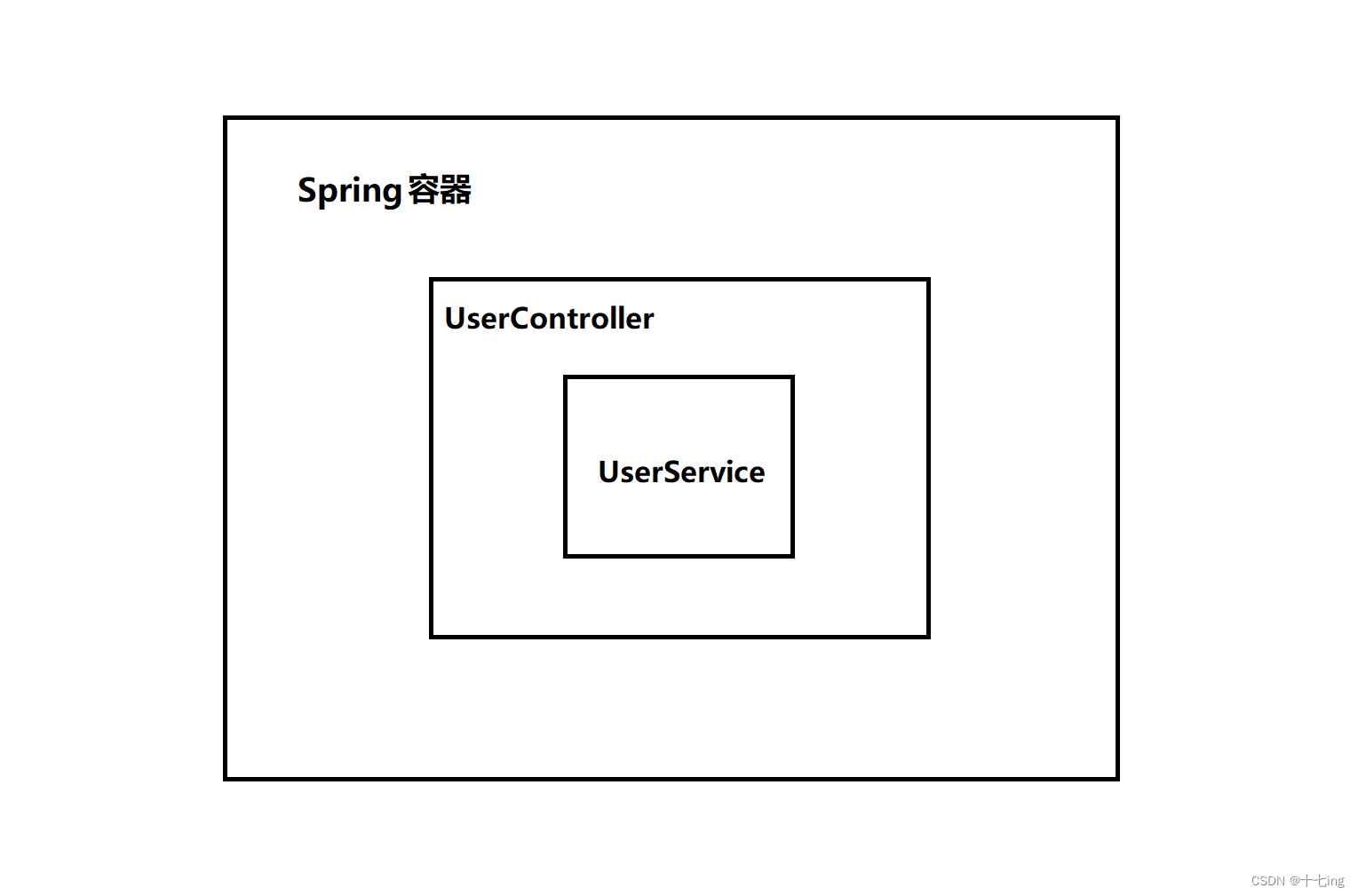
(2) 构造方法注入 bean 对象
我们往 " UserController2 " 类中,注入 " UserService " 类的对象,之后,我们就可以通过 " UserController2 " 类拿到 " UserService " 类的字段、方法等数据了。下面的 Run 启动类,只是用来测试一下,对象装配是否成功。

注意
注意1
下面这行代码,并不是属性注入,因为它上面并没有 " @Autowired " 这样的注解,所以很明显,它就是是一个值为 null 的一个字段而已。
private UserService userService;接着,由于构造方法在外部 new 的时候,第一时间就能够使用,也就是说,构造方法的优先级很高。所以,通过构造方法注入,就是将原先值为 null 的 userService 字段,赋值了新的对象,这就好像激活了 UserService 类一样。
@Autowired public UserController2(UserService userService) { this.userService = userService; }注意2
利用构造方法注入 bean 对象的时候,如果被注入的类出现了多个构造方法,我们只能使用一个构造方法来进行 bean 对象的注入,也就是只将其中一个构造方法设置为注解 " @Autowired "。
(3) Setter 注入 bean 对象
我们往 " UserController3 " 类中,注入 " UserService " 类的对象,之后,我们就可以通过 " UserController3 " 类拿到 " UserService " 类的字段、方法等数据了。下面的 Run 启动类,只是用来测试一下,对象装配是否成功。

注意
Setter 方法注入和构造方法注入的思想基本相同,这里我就不展开介绍了。但是它们之间也略有不同,因为构造方法可能根据参数不同,所以会有多个构造方法,然而,Setter 方法则不同,它只有唯一一个,它只针对于某个字段进行设置。
经典面试题1
对象注入的方式有哪些?
属性注入、构造方法注入、Setter 注入三者的区别?答:
① 属性注入:写法最简单,但通用性较差,它只能用于 IOC 容器,如果是用于非 IOC 容器下,就会出现空指针异常。
② 构造方法注入:通用性好,此外,由于构造方法是一个类的优先级最高的成员,所以使用构造方法注入,就能够确保注入对象不会出差错,这也是现阶段官方推荐的写法。但是,由于构造方法可能根据参数不同,所以会有多个构造方法,如果多个构造方法用到了同样的对象注入,那么程序就会显得比较冗余。
③ Setter 注入:官方早期的推荐写法,但通用性依旧较构造方法差,因为在 Java 中的 Setter 方法,放在其他语言之中,可能就行不通了。
④ 官方推荐的写法是一种理论,我们在实际开发中,只要符合对应场景,用到最多的还是属性注入,因为理论和实践还是不一样的,实践以高效、实用为主。
经典面试题2
在进行对象注入时,除了可以使用 " @Autowired " 注解之外,我们还可以使用 " @Resource " 进行注入。
对象注入可以使用的哪两种注解 / 哪两种关键字?
① 出身不同:" @Autowired " 来自于 Spring 框架,而 " @Resource " 来自于 JDK.
② 用法不同:注解 " @Autowired " 支持属性注入、构造方法注入 和 Setter 注入,然而,注解 " @Resource " 不支持构造方法注入。
③ 支持的参数不同:" @Autowired " 只支持 required 参数设置,而 " @Resource " 支持更多的参数设置,比如 name、type 设置。
同一个类型的对象注入多次的问题
创建一个 User 类,作为待存储的类。
public class User{ public int id; public String name; @Override public String toString() { return "User{" + "id=" + id + ", name='" + name + '\'' + '}'; } }在 UserBean 类下,通过注解 " @Bean " ,将 User 类的对象往 spring 容器中注入了两次,一个 beanName 为 " user1 ",一个 beanName 为 " user2 ".
@Controller public class UserBean { @Bean public User user1() { User user = new User(); user.id = 1; user.name = "露丝"; return user; } @Bean public User user2() { User user = new User(); user.id = 2; user.name = "杰克"; return user; } }创建一个 UserController4 类,进行 User 类的对象注入。
@Controller public class UserController4 { @Autowired private User user; public void hello() { System.out.println("你好," + user.name); } }利用 Run 启动类,进行测试。
public class Run { public static void main(String[] args) { ApplicationContext context = new ClassPathXmlApplicationContext("spring-config.xml"); UserController4 userController4 = context.getBean("userController4", UserController4.class); userController4.hello(); } }通过 Run 类测试,我们发现,如果我们直接注入一个 beanName 为 " user " 的一个对象,就会出现如下错误。这其实很好理解,因为当初存入的对象,一个名为 " user1 " ,一个名为 " user2 ",现在,我们却让 spring 容器为我们找一个名称不匹配的对象,自然是找不到的,因为容器中 User 类的对象不唯一。

备注: 如果在 Spring 容器中,同一个类型的对象只有一个,那么,就算我们对象注入的名字与那唯一对象的名字不匹配,也不影响 spring 能够找出来。然而,同一个类型,有多个对象,就算 spring 再智能,它也不知道你究竟想要哪个了。
解决方案
综上所述,我们就知道了,往 spring 中存入 " bean 对象 " 的时候,没有发生问题,但是,从 spring 中取出 " bean 对象 " 的时候,却发生了问题。那么,我们只需要修改【对象注入】的弊端即可。
方案1 精确描述 beanName
如果你想要 user1,属性注入的时候就直接注入 user1;
同样地,如果你想要 user2,就直接注入 user2.@Autowired private User user1; public void hello() { System.out.println("你好," + user1.name); }测试结果:

@Autowired private User user2; public void hello() { System.out.println("你好," + user2.name); }
方案2 通过 " @Resource " 设置 【name 参数】 来重命名
之前,我们提到 " @Autowired " 和 " @Resource ",发现 " @Resource " 在提供的参数方面,更胜一筹。所以我们直接利用其 【name 参数】进行重命名设置即可,这样,就相当于告诉了 spring 容器,你到底取的是哪个对象了。
@Resource(name = "user1") private User user; public void hello() { System.out.println("你好," + user.name); } // 你好,露丝@Resource(name = "user2") private User user; public void hello() { System.out.println("你好," + user.name); } // 你好,杰克方案3 通过 " @Autowired " + " @Qualifier " 的方式来限定名称
实际上, " @Qualifier " 注解只有一个参数,就是 value,可写可不写。但我们最好还是加上 value,因为这样更准确,此外,如果有一天,spring 框架升级了 " @Qualifier " 注解,让它不止一个参数,那么我们也能很好地预防意外。
@Autowired @Qualifier(value = "user1") private User user; public void hello() { System.out.println("你好," + user.name); } // 你好,露丝@Autowired @Qualifier(value = "user2") private User user; public void hello() { System.out.println("你好," + user.name); } // 你好,杰克总结
之前,我们说第一个 spring 项目需要依赖 " xml " 配置文件,来进行存储和取出 bean 对象的,这就像开手动挡的车一样。之后,在第二个 spring 项目中,我们又通过注解的方式,来进行存储和读取 bean 对象,这时候,就像开自动挡的车子一样了。
而实际上,这就是一个随着时代发展,技术升级的过程,后面还有更现代的框架可供使用。但是,我们需要记住一点,在当前的 spring 框架中,核心功能就是存储和读取 bean 对象,所以,项目不管以什么方式实现,牢记核心才是至上的。
-
相关阅读:
Filebeat+Kafka+ELK
3、Sentinel 动态限流规则
Navigation 组件(三) ViewModel,LiveData,DataBinding 组合使用
内地学生可以参加香港高考吗?3分钟教你走捷径拿香港身份远离内卷攻略!
【毕业设计】基于Stm32的家庭气象仪 天气监控系统 - 物联网 单片机 嵌入式
java 基于springboot+vue的居民社区健康管理平台
java版直播商城免费搭建平台规划及常见的营销模式+电商源码+小程序+三级分销+二次开发
一张图系列 - “position_embedding”
《数据库原理》期末考试题
【编程题】【Scratch三级】2021.06 绘制图形
- 原文地址:https://blog.csdn.net/lfm1010123/article/details/127034770