-
数据服务:冗灾容错,质量保障
一、UTS工作原理
1、日志模式缺陷:
UTS(统一数据传输系统)之前的数据库同步和ETL转档,大多都是基于操作日志进行的:由数据更新方,或者使用数据库触发器,填写详细操作记录日志,下载程序和ETL读取这些记录来处理相关的数据。这种方式有较大不足:
逻辑缺陷:网络/数据库异常等各种意外发生时,如果不做人工干预,继续处理下条日志,则本条信息将丢失,最终将导致目标数据与预期的不一致;
抗风险程度低:如果目标数据发生误操作(比如误删除),则整个数据体系存在崩溃风险,目标缺失的数据将很难补回来。
2、UTS工作原理:
UTS是基于时间戳技术设计的,通过对比源和目标数据库的时间戳差异,来判断出具体发生了何种操作。具体的判断逻辑和优势如下:
源时间戳
目标时间戳
操作判断
有
无
新增
无
有
删除
有
有,但主键不一致
更新
冗灾冗错,抗风险程度极高:每轮都在比对源和目标的时间戳差异,多删少补,本轮操作失败下轮继续,不怕事故,确保永远不会丢失数据;
简单易维护:不管是同步还是ETL,无需触发器,无需人工维护,无需写代码,一次配置永久有效;
普适性:广泛应用于证券金融行业,尤其一线数据商,常规和个性化需求已经集大成,该踩的雷都有人踩过了。
UTS的常见应用场景有:
二、应用场景一:数据库镜像传输
1、数据库异地传输:
数据商销售数据库给机构客户;
机构购买的数据库,自由多地部署;
机构和数据商,内部的数据库分钟级热备。
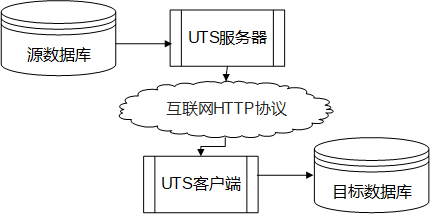
传输中,只有UTS的服务器接口暴露给客户端访问,起到了“中间件”的保护作用,源和目标的数据库都安全隐藏在后端;
时间戳冗灾容错的传输理念,确保了目标数据库与源数据库的完全镜像一致:即使目标数据库遭到了毁灭性破坏,也一样会尝试补齐缺失数据;
性能:日线行情表级别全表传输,1小时可以下载2000万条记录以上;日常增量同步检查,秒级完成。
2、数据库异构传输:
UTS通过各种底层的数据库访问技术(OLEDB/OCI/ODBC/MYSQL直连),将各数据库的变更数据整合成统一的中间集格式,再传输到客户端向目标数据写入。标准化的处理方式,兼容了mssql/mysql/oracle/db2等主流数据库交互传输:

异构传输,可以让数据商无视其客户的数据库类型,确保源数据在目标数据最大兼容;也可以让机构采购的数据库,有更多更复杂的应用场景;
异构传输,不以牺牲性能为代价,不同数据库间的传输,照样支持每小时数千万条记录级别的同步;
3、数据库集采与分发:
只要有时间戳,UTS就能将数据线路全部串接起来,数据可以一路传输下去。以机构为例,通过UTS,可以整合各数据源,生产自己的数据中心;生成好的数据,可以热备同步或分发到下个应用场景:

三、应用场景二:ETL数据转档
常见的ETL数据加工,有两个痛点:
工作量大,需要有开发团队支持,才能将各种复杂的多库合一/多表合一/一表拆多等等应用需求进行编码表述;
维护复杂,不仅需要维护需要的日志体系,还需要有专人职守监测ETL运行状态;如果出故障,如何补齐丢失数据将是一件非常头痛的工作。
UTS就不用那么麻烦,其支持的视图同步简单粗暴的可以替代绝大多数ETL工作:
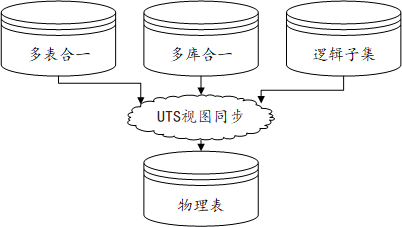
不用关心数据的具体处理步骤,只需要在源库写成视图,将各种多对一/一对多逻辑写清楚,UTS传输一次,在目标数据库就成为真正的表;
无需触发器,无需代码编写,极大的简化了维护和设计工作。也让ETL的实施成本和运维至少下降一大半,传统开发人员才能干的ETL工作,将主要由数据库dba承担。
最关键的,能分享到UTS绝对不丢失数据的优势,极大的提高了ETL转档的稳定性;
四、应用场景三:数据稽核
通过对比源和目标数据库时间戳的差异来进行同步,无形之中正好满足了机构的监测刚需:不用触发器和日志便可发现数据的所有变化,能广泛适应各种数据库环境,能普遍支持各大数据厂商的数据库。
所以新版UTS在较老版UTS同步速度提升6~100倍的基础上,加入了数据稽核的功能,为机构数据质量监测提供强有力的底层支持:

1、数据质量判断标准:
没有权威的信源作对比,如何判断数据的质量高低?UTS的思路是,将数据的修改和删除统计作为数据故障的参考:作为数据商,必然有着大量的客户在广泛使用,如果数据有差错,总归会有人反馈和投诉,倒逼数据商修正数据。如果数据商发布过来的数据,经常性的反复修改和删除,说明其生产流程有待提高,而机构使用这些经常出故障的数据,也要做好防雷的心理准备;如果故障率极低,说明其数据质量的过硬;
通过监测和统计修改/删除的数据故障率,就可以得出比较直观的结论:该数据商的数据质量到底高低如何。在选择使用同类型数据商数据的时候,也能做到扬长避短,最大可能的提高机构自身数据中心的质量;
精确到每条记录每个字段的变化明细,也给机构提供了扯皮的底气:)有理有据的数据质量报告,倒逼数据商将数据质量作为自己的生命;对于一些直接涉及投资的关键核心数据,下份合同签订时,也能有更多的数据做参考依据。
2、质量监测实现机制:UTS传一遍
UTS通过对比源和目标数据的时间戳差异来判断具体的数据变化:源头有目标没有的数据,说明发生了新增操作;源头没有目标有的,说明发生了删除操作;两边都有但时间戳不一致,说明发生了修改操作;
如果数据厂商本来就是用的UTS下载,那在下载的时候就可以直接生成数据更新明细;如果数据厂商使用其他工具或者老版UTS下载,那就再传一遍,将下载下来的数据,同步一次到镜像库,照样可以判断出发生了什么操作;
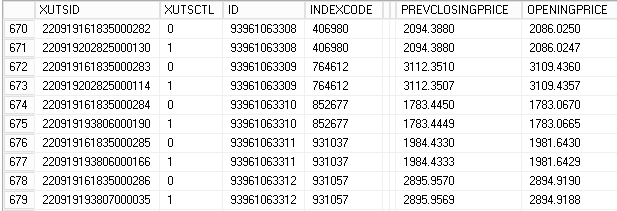
汇总统计所有表的故障率,即可得出相应的结论;详细分析每次修改和删除是对哪些数据和字段做的修改,直接解剖数据(商),想不知道数据商的质量都难了:(如下图,首次入库,16:18分的数值是2086.0250,到20:28分修改为2086.0247,以前可知?)
五、信创支持
基于安全的考虑,操作系统和数据库平台,国产化在未来将成为机构必选甚至是唯一的选择。UTS也做了相应的准备:
支持windows和linux跨平台,协议统一;
支持统信麒麟等国产操作系统;
支持达梦/巨杉等国产数据库。
安全上,支持反调试和反注入等防黑功能。
六、硬件需求
UTS采用C++开发(windows的vs2022,linux的gcc,一套代码跨平台自适应),数据库引擎均采用最底层但最高效的接口,所以对机器性能无特殊要求:
内存8G起,建议16G;磁盘空间取决于数据库需要的存储空间;双核CPU足够UTS运行:总而言之,即使最低配置的服务器甚至台式机,都不会影响UTS的稳定同步传输;
上述配置,单机可以支持100个数据库客户的同步下载;
每小时能同步2000条日线级数据。只要索引有效,UTS在分钟级别能检查完毕1000张表的常规数据更新。
-
相关阅读:
Linux服务器的性能监控与分析
docker小技能:部署mysql
SRE方法论之拥抱风险
springboot基于Java Web的华家医疗器械商城设计与实现毕业设计源码261620
2004-2023年中国研究生数学建模竞赛历年试题整理
电脑开机时报错No Bootable Device找不到索引的解决方法
linux下的文件重命名
win8和win10下,visual studio 2008 调试出现无响应的卡死问题解决
功率放大器的参数和应用场景是什么
非科班程序员逆袭:一个被称阿里“码神”,另一个颠覆软件生态
- 原文地址:https://blog.csdn.net/qing_lr/article/details/127118265