-
被CTO推荐的SQL总结
更多文章欢迎关注公众号:stackoverflow,图片上传压缩后不清晰,可加微信isea_you,发PDF版给你😄
下面是关于SQL在引擎内部执行的顺序的简易版/必记版:
from 某表,group by 某字段,开窗 ,聚合函数,having,distinct , order by , limit ,尤其注意当group by 和 开窗相遇时,一定是分组groupBy优先
1️⃣ hive的架构
如下图是Hive的架构图,即解析器-编译器-优化器-执行器,区别于MySQL的,连接器-分析器-优化器-执行器

metastrore是存储元数据的数据库,默认使用的是derby,可以更改为MySQL,元数据指的是将结构化数据映射成一张表的表名,表所属的数据库(默认为default),表的拥有者,表的列,分区字段,表的类型(是否为外部表)表所在的目录等。Hive只是和RDB只是在SQL语句上有着类似之处
2️⃣ 一些hive中的函数
2.1-collect_x
在使用这个函数时,需要设置
set hive.map.aggr = false;否则可能会发生IllegalArgumentException Size requested for unknown type: java.util.Collection的异常1select collect_set(col_a) as set_a , collect_list(col_a) as list_a , sort_array(collect_list(col_a)) sort_list_a from ( select 'a' col_a union all select 'b' col_a union all select 'a' col_a union all select 'a' col_a ) t
2.2-日期/时区
select date_format('2019-02-10','yyyy-MM'); 2019-02 select date_add('2019-02-10',-1),date_add('2019-02-10',1); 2019-02-09 2019-02-11-- (1)取当前天的下一个周一 select next_day('2019-02-12','MO') 2019-02-18 -- 说明:星期一到星期日的英文(Monday,Tuesday、Wednesday、Thursday、Friday、Saturday、Sunday) -- (2)取当前周的周一 select date_add(next_day('2019-02-12','MO'),-7); 2019-02-11 -- (3)取当前周的周日 select date_add(next_day('2019-06-09','mo'),-1); 2019-06-09 -- (4)求当月最后一天日期 select last_day('2019-02-10'); 2019-02-28-- 将北京时间转为巴西时间 select from_utc_timestamp(to_utc_timestamp("2021-05-09 22:14:30",'GMT+8'),"GMT-3") 2021-05-09 11:14:30.0 select date_format(from_utc_timestamp(to_utc_timestamp("2021-05-09 22:14:30",'GMT+8'),"GMT-3"),'yyyy-MM-dd HH:mm:ss') 2021-05-09 11:14:30-- 求上个月 select substr(add_months(current_date(),-1),1,7) method_one , substr(date_sub(from_unixtime(unix_timestamp()), dayofmonth(from_unixtime(unix_timestamp()))), 1, 7) as method_two2.3-字符串处理
substr,replace等就不赘述了-- 1) select regexp_extract('http://a.m.taobao.com/i41915173660.html', 'i([0-9]+)', 0) , regexp_extract('http://a.m.taobao.com/i41915173660.html', 'i([0-9]+)', 1) -- i41915173660 , 41915173660 -- 0是显示与之匹配的整个字符串; 1是显示第一个括号里面的 -- 2) select regexp_replace('a1b2c3d4', '[0-9]', '-'); -- a-b-c-d- -- 3) -- 某字符串是另外一个字符串的子串 instr(string string, string substring) -- 返回查找字符串string中子字符串substring出现的位置,如果查找失败将返回0,如果任一参数为Null将返回null,位置为从1开始。2.4-除数为0处理
这里我们将比较不同的引擎是如何处理除数为0的问题的,如下图:

对于除数为0问题,优先使用
nullif函数来进行处理,但是该函数Hive2.2才有对应实现3️⃣ 一些hive中的语法
3.1-sum() + over()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IDCihZXQ-1664462446005)(img/hive/6.jpg)]
- over() 全局求和
- over(order by) 全局累积求和
- over(partition by ) 分区内全局求和
- over(partition by order by) 分区内累积求和
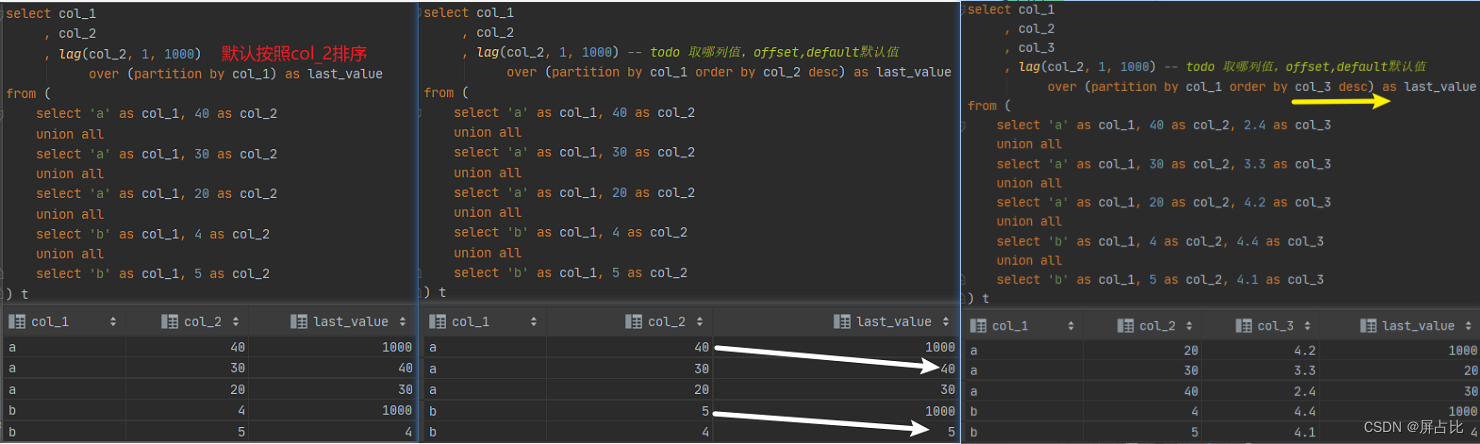
内网环境下,下面的脚本分别在impala,hive,holo,pg , mysql ,执行以下,看下是什么情况
with tmp1 as ( select 'a' as a,1 as b union all select 'a' as a , 2 as b union all select 'b' as b , 10 as b ) select a , avg(b) over(partition by a order by b) x , sum(b) over(partition by a order by b) y from tmp1 ;关于聚合函数+窗口函数的描述,GreeksforGreeks上的那个博文是错的
3.2-侧写视图(lateral view)
🎈侧写试图主要用来处理行转列的问题
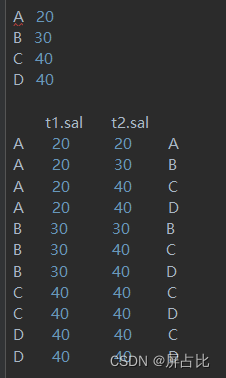
select col_b,col_c from ( select 'a/b/c/d' as col_b ) t lateral view explode(split(col_B, '/')) x as col_ccol_b col_c a/b/c/d a a/b/c/d b a/b/c/d c a/b/c/d d 3.3-lag+over的使用
- lag 落后是获取上一个
- lead 领导是获取下一个
SQLStructuredQueryLanguage标准认为当前行的上一个行是后面,下一行是前面,即

3.4-一周内连续3天活跃

with tmp1 as( select 0 as mid_id,'2020-02-12' as dt union all select 0 as mid_id,'2020-02-16' as dt union all select 0 as mid_id,'2020-02-17' as dt union all select 0 as mid_id,'2020-02-18' as dt union all select 1 as mid_id,'2020-02-11' as dt union all select 1 as mid_id,'2020-02-13' as dt union all select 1 as mid_id,'2020-02-14' as dt union all select 1 as mid_id,'2020-02-17' as dt ) , tmp2 as ( select mid_id , dt , row_number() over (partition by mid_id order by dt) rk , date_sub(dt, row_number() over (partition by mid_id order by dt)) diff from tmp1 where dt between date_sub('2020-02-18', 7) and '2020-02-18' ) select mid_id from tmp2 group by mid_id,diff having count(*) >=3 ;对于类似的连续X天的问题,最优的解决方案是使用开窗函数,另外的一种解题思路是自关联,关联时,使用
t1.mid_id = t2.mid and t1.dt = date_sub(t2.dt,x)的方式3.5-left semi join
关于
left semi join注意2点:🅰️
left semi join要严格区分于left outer join(left join)🅱️
t1 left semi join t2选列时,不允许出现t2 的字段select t1.id, t1.fieldA from `table_A` t1 where t1.id in ( select id from `table_B` ); -- A 和 B的 交集 -- 可改写为exists的方式 select t1.* from `table_A` t1 where exists ( select t2.id from `table_B` t2 where t1.id = t2.id ) -- 还可改写为 select t1.* from `table_A` t1 left join `table_B` t2 on t1.id = t2.id where t2.id is not null -- A 和 B 的交集 ; -- 改写为 ,这种方式更加高效 select t1.* -- 不允许出现t2 的字段 from `table_A` t1 left semi join `table_B` t2 on t1.id = t2.id;同理对于
not existselect t1.* from `table_A` t1 left join `table_B` t2 on t1.id = t2.id where t2.id is null -- A中有B中没有 ; -- 我们换成下面的写法 select t1.* from `table_A` t1 where not exists ( select t2.id from `table_B` t2 where t1.id = t2.id ) -- A中有B中没有 -- 或者换成下面的写法 select t1.* from `table_A` t1 where not in ( select t2.id from `table_B` t2 where t1.id = t2.id ) -- A中有B中没有3.6-distinct
🅰️ distinct 和 order by 的结合
先执行distinct ,后执行order by ,最后limit

🅱️ distinct 多个字段
distinct多个字段对所有字段都起作用,并不是一个;如select distinct field_a,field_b from table;a1,b1; a1,b2; a2,b2; -- 只要有不同就会被选择出来3.7-limit offset
limit x offset y, y y y是 x x x的倍数出现,可以恰好将数据取完,limit x offset y等效于limit y,x
select * from ( select 1 a union all select 2 a union all select 3 a union all select 4 a union all select 5 a ) t order by a desc limit 3 offset 3;最后一个截图的SQL语句,我在Hive2.1.1中的执行结果是:
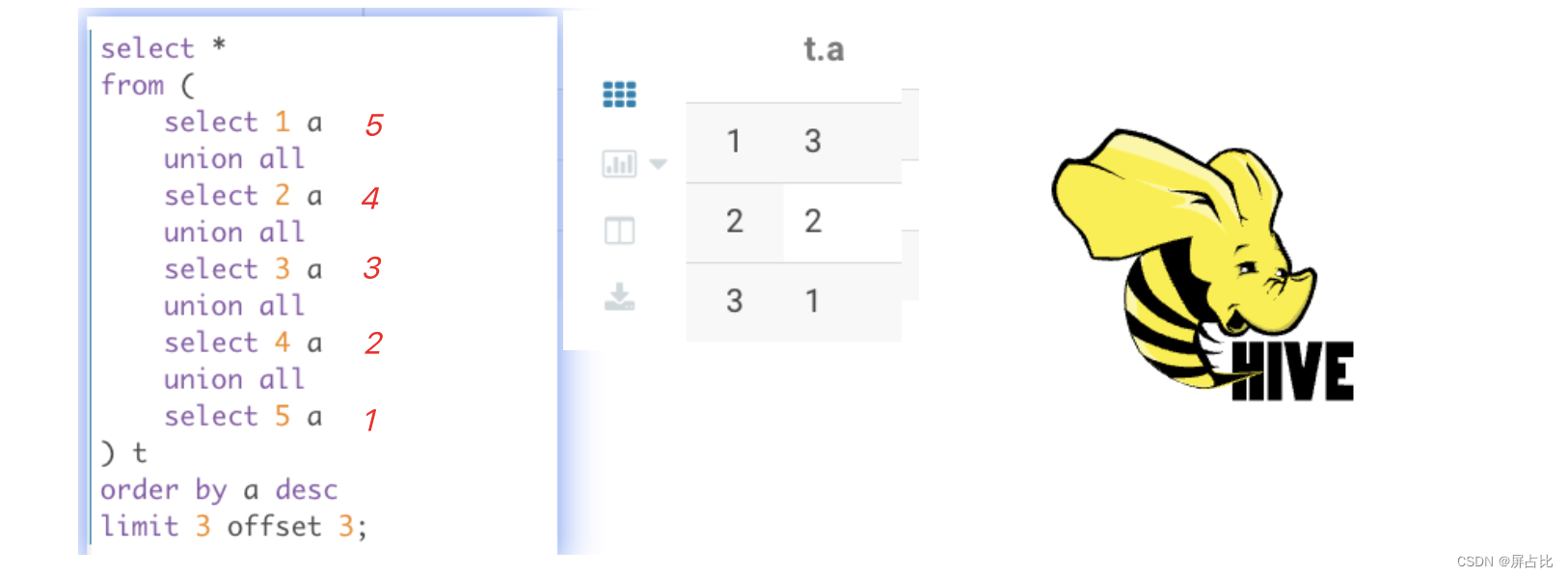
说明在Hive中
offset的排序是从1开始的x取0等于于x=13.8-ntile+over
ntile(x)将数据划均分为x个桶,并且返回桶编号,如果有多的元素,优先进入第一个桶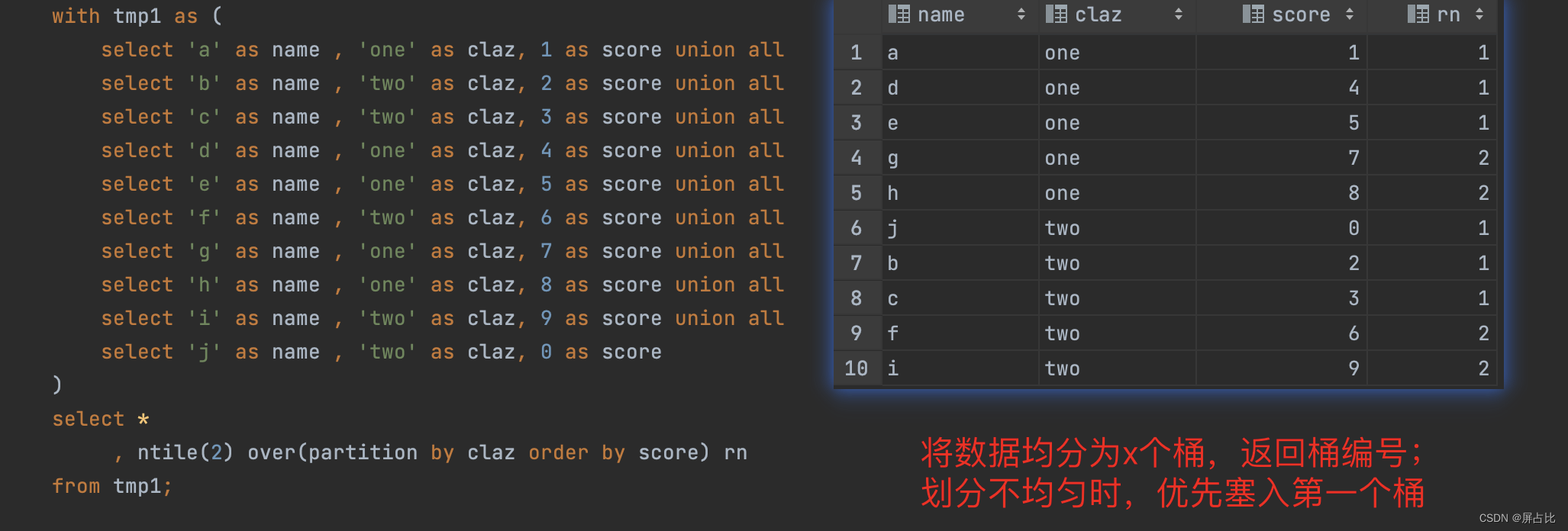
with tmp1 as ( select 'a' as name , 'one' as claz, 1 as score union all select 'b' as name , 'two' as claz, 2 as score union all select 'c' as name , 'two' as claz, 3 as score union all select 'd' as name , 'one' as claz, 4 as score union all select 'e' as name , 'one' as claz, 5 as score union all select 'f' as name , 'two' as claz, 6 as score union all select 'g' as name , 'one' as claz, 7 as score union all select 'h' as name , 'one' as claz, 8 as score union all select 'i' as name , 'two' as claz, 9 as score union all select 'j' as name , 'two' as claz, 0 as score ) select * , ntile(2) over(partition by claz order by score) rn from tmp1;3.9-like多个字段

第一个截图是
mysql3.10-窗口函数的范围选择
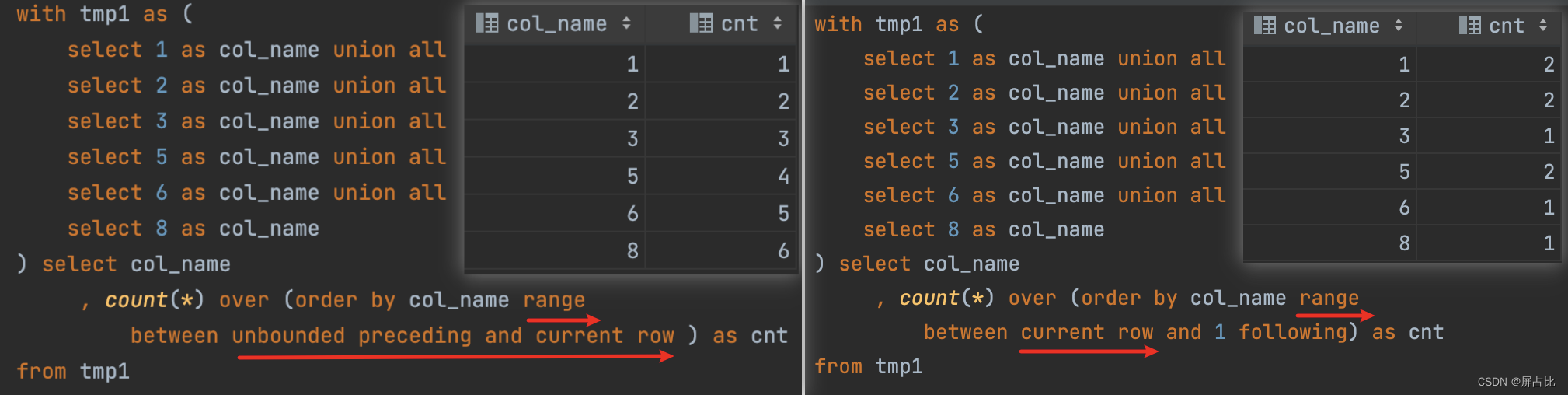
注意
range和rows之间的使用区别agg_func over(order by col_name rows between 1 proceding and 1 following) -- col_name的前后1行 agg_func over(order by col_name range between 1 proceding and 1 following) -- col_name值的(+/- 1) 的值 agg_func over(order by col_name rows between unbounded preceding and unbounded following) -- 全部行 agg_func over(order by col_name rows between unbounded preceding and current row) -- 开头到当前行
4️⃣ 引擎的一些不同
4.1-select 非 group by 字段
MySQL支持,Hive,Impala,PostgreSQL 不支持
对于下面这一段SQL
select dept , emp , max(sal) as max_sal from ( select 'A' as dept, 'a1' as emp, 10 as sal union all select 'A' as dept, 'a2' as emp, 20 as sal union all select 'B' as dept, 'b2' as emp, 100 as sal union all select 'B' as dept, 'b1' as emp, 200 as sal ) t group by dept1️⃣MySQL 通过
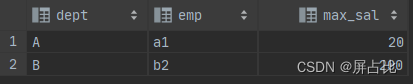
MySQL 选择记录中的第一个记录(从实验结果来看,是记录的第一行)2️⃣postgreSQL:
[42803] ERROR: column "t.emp" must appear in the GROUP BY clause or be used in an aggregate function3️⃣Hive:
Error while compiling statement: FAILED: SemanticException [Error 10025]: line 2:7 Expression not in GROUP BY key 'emp'4️⃣Impala:
AnalysisException: select list expression not produced by aggregation output (missing from GROUP BY clause?): emp4.2-having过滤是否支持别名
MySQL和Hive是支持的, impala和postgreSQL不支持
select a, count(*) as cnt from ( select 5 as a union all select 4 as a union all select 4 as a union all select 3 as a union all select 3 as a ) t group by a having cnt > 1;上述的SQL在MySQL 和 hive中执行都是没问题的,在impala和postgreSQL报错
column "cnt" does not exist,需要下面的写法select a, count(*) as cnt from ( select 5 as a union all select 4 as a union all select 4 as a union all select 3 as a union all select 3 as a ) t group by a having count(*) > 1;🎈:推荐无论何时都不使用别名进行分组后过滤
4.3-order by 字符串
select a from ( select 'a' as a union all -- 97 select '' as a union all -- 66 select ' ' as a union all -- 32 select null as a -- 0 ) t order by a desc ;对于以上查询和排序,Hive和MySQL认为NULL是最小;Impala和PostgresSQL认为NULL最大,如果使用
explain命令查看SQL的执行计划的话,会明显看到编译器会给SQL添加1个null first / null last的明亮,这个取决于具体的引擎,感兴趣的读者可以自己test下,比如Hive会将null设为最小,impala会将null设为最大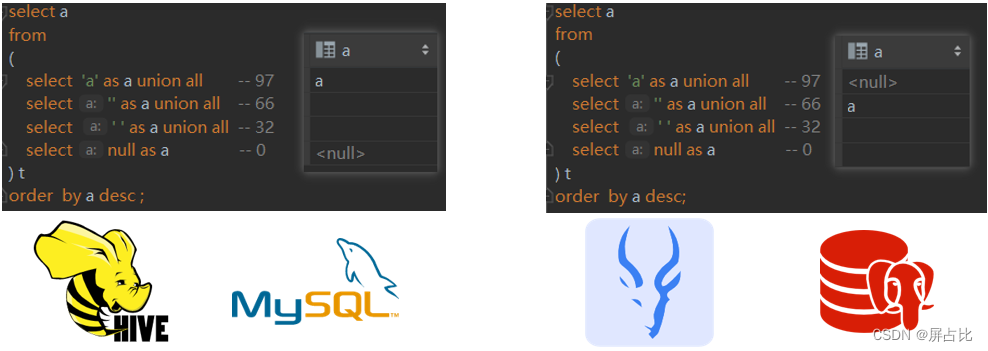
4.4- 24 / 5 24/5 24/5的结果
DB/Program Language value Java / PostgreSQL 4 Hive / Impala / MySQL 4.8 4.5-窗口函数是否支持
distinctselect A, B , count( distinct A) over() from ( select 1 as A ,'a' as B union all select 2 as A ,'b' as B union all select 1 as A ,'c' as B union all select 3 as A ,'d' as B ) t比如以上的SQL查询:Hive是支持的,Impala,MySQL,PostgreSQL暂时没有实现
4.6-窗口嵌套
窗口函数的嵌套,只Hive2.1.1中是支持的,PostgreSQL(
window functions are not allowed in window definitions),MySQL,Impala 中只能多嵌套一层
4.7-字符串写入数值类型
create table if not exists business ( name stirng, order_date string, cost float ); insert into business values('xioaming','2021-08-22','');Hive 会将字符串转为null写入;Impala,MySQL,PostgreSQL会进行类型检查(即报错)
5️⃣ 一些注意点
5.1-
null,x关联
在任何SQL(MySQL,PostgreSQL,Hive,Impala)引擎中,
null和任意值都无法关联无法相互关联,包括其本身PostgreSQL中有类型探测,执行以上关联会发生:Failed to find conversion function from unknown to text
5.2-返回1行&返回0行

如左图所示5.3-union all 的类型
任何引擎,
union all的类型必须保持一致5.4-组合主键非
null对于
test01表,字段a和字段b在作为联合主键时,在字段a为null,字段b非null的时候1️⃣
kudu将不会写入该记录,不会抛异常2️⃣
mysql插入时抛出异常 类似(primary key not null)3️⃣
postgresql插入时抛出异常 类似(primary key not null)5.5-时间戳
⚠️时间是人可识别的,时间戳基本是机器识别的,比如2022-01-01 00:00:001640966400,前者是时间,后者是时间戳
1️⃣ 获取时间戳
--mysql select unix_timestamp('2022-01-01 00:00:00'); -- hive select unix_timestamp('2022-01-01 00:00:00');2️⃣获取时间
-- mysql select now(); -- hive select from_unixtime( unix_timestamp()); -- impala select now(), utc_timestamp(),current_timestamp(),from_unixtime( unix_timestamp()); -- pg select now() , current_timestamp;5.6-去掉文本中的换行符/回车符/制表符/空格
select regexp_replace(input_content,'\\s+','') as after_content由于特殊字符导致表错位串行的问题描述

select '1\r2\t\3\n4\0015' ,regexp_replace('1\r2\t\3\n4','\\s+','') ,regexp_replace('1 \r2\t\3\n4\0015','\\s+','') ,regexp_replace('1 \r2\t\3\n4\0015','\t|\n|\001|\r','')5.7-impala upsert
本质是
insert+update的结合- 主键存在时,全字段更新
- 主键不存在时,插入
5.8-不使用
order by找到工资第二的员工select e.emp_no, salary, last_name, first_name from employees e inner join salaries s on e.emp_no = s.emp_no where s.to_date = '9999-01-01' and s.salary = ( select s1.salary from salaries s1 inner join salaries s2 on s1.salary <= s2.salary where s1.to_date = '9999-01-01' and s2.to_date = '9999-01-01' group by s1.salary having count(distinct s2.salary) = 2 )更多文章欢迎关注公众号:stackoverflow
改参数设置map的聚合为false , 在map端聚合还可能会引发内存溢出的问题,详情可查看:http://dev.bizo.com/2013/02/map-side-aggregations-in-apache-hive.html ↩︎
-
相关阅读:
树莓派(一)树莓派的4种登陆方式
【JavaScript实现 百元买百鸡问题】
[附源码]SSM计算机毕业设计智能视频推荐网站JAVA
网络基本概念
【Linux】进程
HCIP知识点
2022下半年电商市场爆火的商业模式——2+1链动招商模式
使用Process Explorer查看线程的函数调用堆栈去排查程序高CPU占用问题
史上最全 Appium 自动化测试从基础到框架实战精华学习笔记(一)
VTN4系列多通道振弦模拟信号采集仪模拟通道值和振弦传感器温度通道值修正
- 原文地址:https://blog.csdn.net/qq_31807385/article/details/127115325