-
人工智能算法一&逻辑回归
简介
逻辑回归学习笔记
公式推导人工智能算法一&逻辑回归
概念引入

特殊处理二分类
两种分类的概率加起来为一。

二级分类函数推导
如果d大于0那么f=1,d<0的时候f=0。满足二级分类。

但是上面的情况有很多的不住,比如在一些特殊的情况存在误判,我们如果想要知道它的其他百分比不太好上面的公式。

我们平滑处理以后的图形如下:

可以看到,如果d=0的时候,f可以等于百分之50,比起百分之百,会更加的接近实际。要得到上面的图形,那么我们就需要特殊的公式。下图的公式就很符合上面的图形情况。

得到下面的图形:
下面的图形可以看到,当d特别小的时候对f的影响不大,d特别大的时候对于f的影响也不太大。可以看到f对于d的导数相识于正态分布。

下图对比线性回归公式:
他们的共同点还是动态的调整w的值得到误差最小的模型。


逻辑回归,就是想找到最适合w然后找到合适的直线把数据进行分类。

下图是求概率的公式和上面的分界线产生联系。
说明,当d越大的时候f也越大,也就是如果d越大f越接近1,如果d=0的时候,那么点就落在直线上面,那么f的概率就是百分之50,d越小,f的概率也就越小。

那么上面的逻辑就可以简化成下面的情况。找到合适的w,得到f的值和结果值y做比较得到最优的w。

对比下线性回归模型。求mse,如果mse越小,那么越接近真实的模型。

KL引入
但是逻辑回归不能使用mse进行判断相关性。因为对于逻辑回归求的是概率。求的是预测值和真实值之间的概率距离,那么我们就需要找其他符合条件的公式。那么这个也叫做KL距离。公式如下。

公式简化例子。

这里以 硬币的情况进行讲解KL公式的n就是硬币的情况n=2,那么下面这一段是正面的情况。

下面是反面的情况带入公式。

KL示例
如果两个硬币的概率一样,那么求出来的KL距离就是0,那么表示表示两个硬币没有差异,如果KL距离越大,那么表示两个硬币差异越大。

KL距离没有对称性

KL重点知识
由KL公式推导如下,如果想距离最小,那么p(x1)*log(gx1)越大才行,那么怎么越大呢? 当p(x1)越大的时候log(gx1)越大越好,当p(x1)越小,那么log(gx1)无所谓。也就是影响不大。

下面表示了在log(gx1)取值的时候,尽量的和p(x1)的最高峰接近,那么得到的KL才是最小的。下面的图相当于正太分布。

下面是对称的情况分析。


下面的1和2总会有一个地方为0。

公式推导结果
fi是预测值,yi是实际值,那么我们保证KL距离最短的时候,那么模型就越好,预测的也就越准确。那么怎么让KL距离最小,这里也是根据改变w的值得到KL的最小值,那么就用到了求导数的思想。动态(机器学习模型)调整w的值,得到KL的最小值。

训练模型例子
准备数据
- [[5.072824661881029, 0.9554537337012714], [1]]
- [[4.188466461361219, 0.5667718021758161], [1]]
- [[8.553753236611271, 1.2311797292411786], [1]]
- [[8.399890910172047, 5.218741141312262], [1]]
- [[4.6696214756092225, 0.8588349524602856], [1]]
训练代码
- # -*- encoding:utf-8 -*-
- from sklearn import datasets
- from sklearn.model_selection import train_test_split
- from sklearn.linear_model import LogisticRegression
- from sklearn.model_selection import cross_val_predict
- from numpy import shape
- from sklearn import metrics
- from sklearn.metrics import log_loss
- import numpy as np
- def read_data(path):
- with open(path) as f :
- lines=f.readlines()
- lines=[eval(line.strip()) for line in lines]
- X,y=zip(*lines)
- X=np.array(X)
- y=np.array(y)
- return X,y
- def curve(x_train,w,w0):
- results=x_train.tolist()
- for i in range(0,100):
- x1=1.0*i/10
- x2=-1*(w[0]*x1+w0)/w[1]
- results.append([x1,x2])
- results=["{},{}".format(x1,x2) for [x1,x2] in results]
- return results
- # [[5.072824661881029, 0.9554537337012714], [1]]
- # [[4.188466461361219, 0.5667718021758161], [1]]
- # [[8.553753236611271, 1.2311797292411786], [1]]
- # [[8.399890910172047, 5.218741141312262], [1]]
- # [[4.6696214756092225, 0.8588349524602856], [1]]
- X_train,y_train=read_data("train_data")
- # 得到的数据为X_train
- #[[5.072824661881029, 0.9554537337012714],[4.188466461361219, 0.5667718021758161]]
- # 得到的数据为y_train
- #[[1],[1]]
- X_test,y_test=read_data("test_data")
- model = LogisticRegression()
- model.fit(X_train, y_train)
- print ("w",model.coef_)
- print ("w0",model.intercept_)
- y_pred = model.predict(X_test)
- print (y_pred)
- # y_pred=model.predict_proba(X_test)
- # print (y_pred)
- #loss=log_loss(y_test,y_pred)
- #print "KL_loss:",loss
- #loss=log_loss(y_pred,y_test)
- #print "KL_loss:",loss
- '''
- curve_results=curve(X_train,model.coef_.tolist()[0],model.intercept_.tolist()[0])
- with open("train_with_splitline","w") as f :
- f.writelines("\n".join(curve_results))
- '''
测试数据集
- [[2.0302730822301243, 8.500674268294649], [0]]
- [[5.41598580690089, 3.409921657890002], [1]]
- [[2.815123502020228, 9.852594446340593], [0]]
- [[8.873339534995086, 1.2717021691735864], [1]]
- [[0.1584904464785053, 6.756524714523492], [0]]
- [[4.563656663493982, 7.1748207697532855], [0]]
二类区分
得到结果,可以看到实际值和预测值很像,说明模型训练得很好
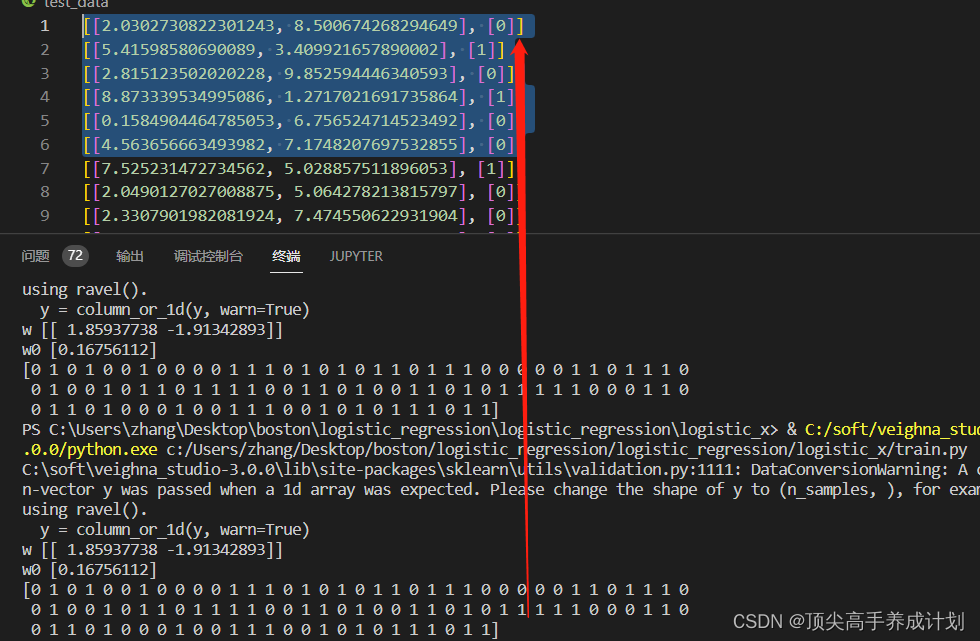
二类区分概率表示
逻辑回顾可以处理分类的问题 。
- # -*- encoding:utf-8 -*-
- from sklearn import datasets
- from sklearn.model_selection import train_test_split
- from sklearn.linear_model import LogisticRegression
- from sklearn.model_selection import cross_val_predict
- from numpy import shape
- from sklearn import metrics
- from sklearn.metrics import log_loss
- import numpy as np
- def read_data(path):
- with open(path) as f :
- lines=f.readlines()
- lines=[eval(line.strip()) for line in lines]
- X,y=zip(*lines)
- X=np.array(X)
- y=np.array(y)
- return X,y
- def curve(x_train,w,w0):
- results=x_train.tolist()
- for i in range(0,100):
- x1=1.0*i/10
- x2=-1*(w[0]*x1+w0)/w[1]
- results.append([x1,x2])
- results=["{},{}".format(x1,x2) for [x1,x2] in results]
- return results
- # [[5.072824661881029, 0.9554537337012714], [1]]
- # [[4.188466461361219, 0.5667718021758161], [1]]
- # [[8.553753236611271, 1.2311797292411786], [1]]
- # [[8.399890910172047, 5.218741141312262], [1]]
- # [[4.6696214756092225, 0.8588349524602856], [1]]
- X_train,y_train=read_data("train_data")
- # 得到的数据为X_train
- #[[5.072824661881029, 0.9554537337012714],[4.188466461361219, 0.5667718021758161]]
- # 得到的数据为y_train
- #[[1],[1]]
- X_test,y_test=read_data("test_data")
- model = LogisticRegression()
- model.fit(X_train, y_train)
- print ("w",model.coef_)
- print ("w0",model.intercept_)
- y_pred = model.predict(X_test)
- # print (y_pred)
- #打印出概率百分比
- y_pred=model.predict_proba(X_test)
- print (y_pred)
- #loss=log_loss(y_test,y_pred)
- #print "KL_loss:",loss
- #loss=log_loss(y_pred,y_test)
- #print "KL_loss:",loss
- '''
- curve_results=curve(X_train,model.coef_.tolist()[0],model.intercept_.tolist()[0])
- with open("train_with_splitline","w") as f :
- f.writelines("\n".join(curve_results))
- '''

结果

用途
广告点击预测

文章审阅

多分类模型
多分类的时候可以使用二分类以后,然后排序得到最大的,那么这个x就属于哪一个类别。

数据不均衡的问题
逻辑回归形象的比较, 所有的点都把线往外面推知道平衡为止。

出现数据不平衡的时候,对于少出现的数据,增大数据量的方式。

逻辑回归评测
准确率和召回率
不妨举这样一个例子:某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
不妨看看如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%

AOC和ROC

AOC是ROC内部的面积,AOC越大区分度越高,上面model1正式0.4负是0.2,中间可以用0.3区分,下面的就不能够区分正负。
结论

-
相关阅读:
零基础入门JavaWeb——HTML相关知识
YOLOv8血细胞检测(12):EMA基于跨空间学习的高效多尺度注意力、效果优于ECA、CBAM、CA | ICASSP2023
公共供水管网漏损治理智能化管理系统解决方案
嵌入式分享合集52
java中拦截器和过滤器的区别和联系?
协程: Flow 异步流 /
生产者消费者模型
nlp之加载电商评论集
vue3.0项目实战系列文章 - 登录页面
Pytorch框架的模型pth文件转换成C++ OpenVINO框架的bin和xml文件并运行
- 原文地址:https://blog.csdn.net/S1124654/article/details/127038104