-
【deepstream部署Yolov6】
项目路径:GitHub - egbertYeah/YOLOv6 at dev
0. 介绍
Arxiv:https://arxiv.org/abs/2209.02976
Github: https://github.com/meituan/YOLOv6
yolov6 是美团发布的一款面向工业应用的2D目标检测算法,在检测精度和推理效率上都有所提升。yolov6 在Backbon、Neck、Head等方面都进行了改进,基于RepVGG style设计了EfficientRep BackBone 和Rep-PAN Neck,此外,优化设计了更简洁的Efficient Decouple Head.
现阶段,在Yolov6的开源项目中提供多种部署方案,本文,基于现有的TensorRT部署方案,来完成Yolov6在Deepstream框架上的推理。

1. 生成Engine
基于现有的TensorRT部署方案来生成 Yolov6n的 TensorRT Engine 文件,具体细节可参考TensorRT的部署链接,大体步骤如下:
测试环境:
- pytorch 1.8
- TensorRT 8.0
- ONNX 1.12.0
Step 1:pth 转 ONNX
- python ./deploy/ONNX/export_onnx.py \
- --weights yolov6n.pt \
- --img 640 \
- --batch 1
Step 2:生成Engine
- python3 onnx_to_tensorrt.py --fp16 --int8 -v \
- --max_calibration_size=${MAX_CALIBRATION_SIZE} \
- --calibration-data=${CALIBRATION_DATA} \
- --calibration-cache=${CACHE_FILENAME} \
- --preprocess_func=${PREPROCESS_FUNC} \
- --explicit-batch \
- --onnx ${ONNX_MODEL} -o ${OUTPUT}
以 Yolov6n为例:
python3 onnx_to_tensorrt.py --fp16 --onnx ${ONNX_MODEL} -o ${OUTPUT}2. 网络结构
当生成TensorRT Engine文件之后,需要对网络的输入和输出进行分析,来编写处理输出的脚本。
如下图所示,为Yolov6n ONNX文件的输入输出信息,从图中可以看出,网络只有一个输入和输出,输入就是图像经过预处理之后的数据,输出为预测框的信息。

下图为文章Deepstream的Yolov3使用流程 中描述的一般Yolo系列目标检测算法的流程,在这个图中网络的输出为3个不同尺度的预测框信息,在这之后需要对预测的目标框进行decode处理,使得此时的目标框的位置信息都是相对于网络输入尺度而言,最后对所有的目标框按类别进行NMS得到最后的结果。
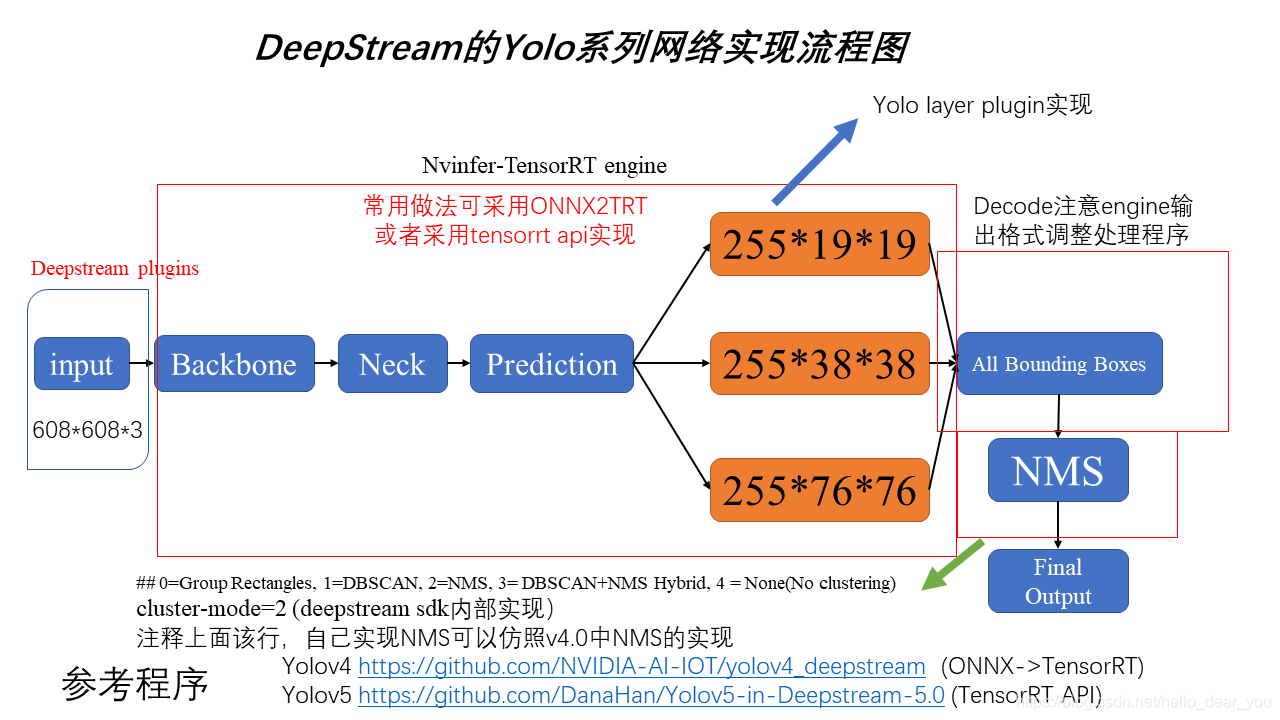
但是,此次采用Yolov6的TensorRT 方案将decode步骤包含在模型中完成,因此输出为decode之后的目标框信息,所以此时目标框的位置是相对于原图而言的。输出的维度为【batch,目标框的个数,目标框的信息】,其中目标框的个数为8400,由80×80+40×40+20×20得到,目标框的信息为85,等于4个目标位置信息+1个目标置信度+80个类别置信度。具体形式如下图所示。

3. 解析函数实现
从章节2中,可以知道模型的输出为经过decode操作之后的所有目标框信息,因此,解析函数中主要的功能是对所有的目标框信息,按类别进行NMS,得到最后的输出,如下图所示。

在Deesptream中的nvinfer插件中提供了一个接口来处理TensorRT Engine的输出,因此只需要实现一个接口函数,并在Nvinfer 的配置文件中正确设置即可。
NMS的具体实现请参考parsebbox_YoloV6v2.cpp文件,这里就不作过多的解释。
4. 配置文件
在Deepstream中推理Yolov6需要设置两个配置文件,一个nvinfer的配置文件,一个是deepstream-app的配置文件,下面就一些主要的参数内容进行介绍。
config_infer_prinary_yoloV6.txt nvinfer的配置文件,详细配置参数含义请参考链接。
1. 图像预处理相关参数
- net-scale-factor=0.0039215697906911373
- maintain-aspect-ratio=1
- symmetric-padding=1
- scaling-filter=1
- scaling-compute-hw=0
- #0=RGB, 1=BGR
- model-color-format=0
2. 设置模型的信息
- model-engine-file=yolov6n.trt
- force-implicit-batch-dim=1
- batch-size=1
- ## 0=FP32, 1=INT8, 2=FP16 mode
- network-mode=2
- num-detected-classes=80
- gie-unique-id=1
- # Integer 0: Detector 1: Classifier
- network-type=0
3. NMS类型设置
- ## 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
- cluster-mode=4
- # lib path
- parse-bbox-func-name=NvDsInferParseCustomYoloV6 # nms实现的函数名
- custom-lib-path=nvdsparsebbox_YoloV6/libnvdsinfer_custom_impl_Yolov6.so
ds_app_config_yoloV6.txt deepstream-app的配置文件,具体配置参数含义请参考链接。
- 输入配置
- [source0]
- enable=1
- #Type - 1=CameraV4L2 2=URI 3=MultiURI
- type=3 # 输入数据的类型
- uri=file://./sample_1080p_h264.mp4 # 输入数据的URI
- num-sources=1
- gpu-id=0
- # (0): memtype_device - Memory type Device
- # (1): memtype_pinned - Memory type Host Pinned
- # (2): memtype_unified - Memory type Unified
- cudadec-memtype=0
- 输出设置
- [sink0]
- enable=1
- #Type - 1=FakeSink 2=EglSink 3=File
- type=3 # 输出结果类型
- sync=0
- source-id=0
- gpu-id=0
- nvbuf-memory-type=0
- container=1
- codec=1
- bitrate=4000000
- iframeinterval=30
- output-file=output_yolov6.mp4 # 输出结果路径
- 指定nvinfer推理的模型配置文件
- # config-file property is mandatory for any gie section.
- # Other properties are optional and if set will override the properties set in
- # the infer config file.
- [primary-gie]
- enable=1
- gpu-id=0
- #model-engine-file=model_b1_gpu0_int8.engine
- labelfile-path=labels.txt
- batch-size=1
- #Required by the app for OSD, not a plugin property
- bbox-border-color0=1;0;0;1
- bbox-border-color1=0;1;1;1
- bbox-border-color2=0;0;1;1
- bbox-border-color3=0;1;0;1
- interval=2
- gie-unique-id=1
- nvbuf-memory-type=0
- config-file=config_infer_prinary_yoloV6.txt # 指定nvinfer的配置文件路径
5. Run
本次测试采用的是deepstream中提供的sample_1080p_h264.mp4,具体运行命令如下:
deepstream-app -c ds_app_config_yoloV6.txt配置文件中设置的输出为视频,因此在同路径下会得到一个output_yolov6.mp4的文件。这里给一个输出结果截图,hhhh。

6. Yolov6n模型的mAP
基于Yolov6中的TensorRT 部署方案,在数据精度为FP16和INT8的情况下,分别测试了Yolov6n在COCO2017 val上的性能,具体效果如下图所示。

Yolov6n FP16下的mAP 
Yolov6n IN8下的mAP 可以看到在FP16精度下,mAP几乎没有损失,而对应INT8精度下,mAP值下降较多。此外,Yolov6过程中,还提供了RepOpt的方式来实现面向工业应用。
-
相关阅读:
算法打卡 Day19(二叉树)-平衡二叉树 + 二叉树的所有路径 + 左叶子之和 + 完全二叉树的节点个数
ApiSix网关环境搭建及简单使用(Windows)
怎么对电脑屏幕进行远程控制
解决pycharm里import rospy报红线但是导入的系统环境有rospy的问题
DataGrip操作Oracle
玩转云端 | 天翼云电脑的百变玩法
什么是DNS解析DNSPod?它有哪些功能和优势?
计算机网络:组帧
SpringBoot入门
2023/10/28 JAVA学习
- 原文地址:https://blog.csdn.net/hello_dear_you/article/details/127072989