-
【论文阅读】attention is all you need
1.论文链接
2.论文主要为了解决什么问题?
- 传统的RNN不能并行处理,如果想要有 h i h_{i} hi,必须要有 h i − 1 h_{i-1} hi−1作为输出
- 传统的CNN的跨度太大
- 以上两个不是很好的能够捕捉到很久之前的信息
3.模型流程

由于这个模型的过程比较多,因此只选择了部分有代表性的来说明layer normalization
首先常见的有batch normalization,就是对于特定特征 f e a fea fea,将其每一个样本 f e a i fea_i feai构成的集合,调整为均值为0,方差为1的序列。那我们为什么不这么选呢?首先我们会在没有数据的地方放置0,因此如果出现了一个特别长的序列,我们整个样本的值和可信度就会收到影响,因此我们选择layer normalization
layer normalization:对于一个单个样本 i i i,将其所有特征组成的集合调整为均值为0,方差为1的序列。
Scaled Dot-Product Attention

此处是用来计算QK的相似度的,除以 d k \sqrt{d_k} dk是因为经过softmax之后有的会很接近0,防止训练的时候梯度消失。MASK操作
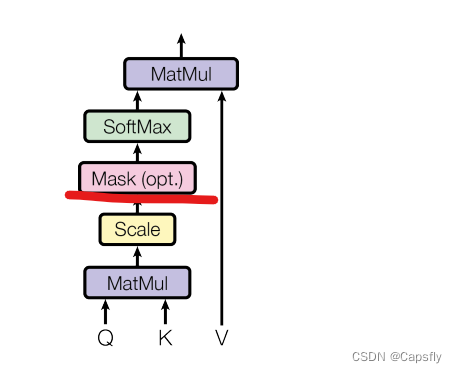
首先我们知道,transformer这个模型如果不去看postional encode的话是没有时序信息的。在encode的时候没有问题,我们能够看到完整的输入。但是在decode的时候就有问题了,他只能看到之前位置的输出结果。所以在decode的时候,将对应位置直接设置成一个非常小的数字,比如 1 e − 10 1e^{-10} 1e−10,这样经过softmax之后概率就是0.
Positional Encoding

因为我们没有位置信息,所以我们要编码一个位置信息放进去。
4.论文创新点
- 直接放弃了传统的RNN和CNN的结构,全文用的都是attention机制,追求并行度。
- 虽然直接放弃了RNN结构,但是由于位置信息是非常重要的,他又加入了Positional Encoding保留位置信息
- 用点积作为相似度
- 没用batchnorm而用的是layernorm
5.本文可能潜在改进的地方
觉得算相似度可以直接用余弦值来计算(一个猜测)
6.本论文收到了哪些论文启发?
传统的RNN CNN
seq with attention7.参考链接
-
相关阅读:
视频监控这样做,简单又高效!
Unity和UE4两大游戏引擎,你该如何选择?
代码随想录打卡第四十四天|● 01 二维背包问题 ●一维背包问题-滚动数组 ● 416. 分割等和子集
Midjourney是个什么软件?midjourney订阅教程
【论文考古】联邦学习开山之作 Communication-Efficient Learning of Deep Networks from Decentralized Data
ADP出席第六届进博会跨境人才服务论坛|薪酬管理数字化加合规性,为跨境企业提升成本效率助长信心
2021年全国职业院校技能大赛(中职组)网络安全竞赛试题(1)详细解析教程
融合微平衡激活的小孔成像算术优化算法
js判断浏览器的类型及指定浏览器类型
C++之STL中vector模拟实现
- 原文地址:https://blog.csdn.net/capsnever/article/details/127100742