-
TorchDrug教程--分子生成
TorchDrug教程–分子生成
教程来源TorchDrug开源
目录
分子图生成是药物发现的一个基本问题,受到越来越多的关注。这个问题是具有挑战性的,因为它不仅需要生成化学上有效的分子结构,同时还要优化它们的化学性质。
在本教程中,我们将实现两个图形生成模型GCPN和GraphAF。我们首先在ZINC250k数据集上预训练两个模型。从预训练的检查点开始,我们用强化学习对两个模型进行微调,以优化生成分子的两个属性(即
QED和惩罚logP评分)。准备预训练数据集
我们使用ZINC250k数据集进行预训练。该数据集包含
25万个类药物分子,最大原子数为38。它有9种原子类型和3种边类型。首先,让我们
donwload、load和预处理数据集,这大约需要3-5分钟。建议您转储预处理数据集,以节省时间供将来使用。import torch from torchdrug import datasets dataset = datasets.ZINC250k("~/molecule-datasets/", kekulize=True, node_feature="symbol") # with open("path_to_dump/zinc250k.pkl", "wb") as fout: # pickle.dump(dataset, fout) # with open("path_to_dump/zinc250k.pkl", "rb") as fin: # dataset = pickle.load(fin)定义模型:GCPN
该模型由图表示模型和图生成模块两部分组成。我们定义了一个关系图卷积网络(RGCN)作为我们的表示模型。我们使用模块GCPNGeneration作为GCPN的训练任务。
预训练和生成:GCPN
现在我们可以训练我们的模型了。我们为模型设置了一个优化器,并将所有内容放到一个Engine实例中。这里我们只训练模型1个epoch,然后将预训练的模型保存到一个目录中。
from torch import nn, optim optimizer = optim.Adam(task.parameters(), lr = 1e-3) solver = core.Engine(task, dataset, None, None, optimizer, gpus=(0,), batch_size=128, log_interval=10) solver.train(num_epoch=1) solver.save("path_to_dump/graphgeneration/gcpn_zinc250k_1epoch.pkl")在预训练过程中,我们可能会得到一些如下的日志,这些日志报告了动作预测的准确性。
edge acc: 0.896366 edge loss: 0.234644 node1 acc: 0.596209 node1 loss: 1.04997 node2 acc: 0.747235 node2 loss: 0.723717 stop acc: 0.849681 stop bce loss: 0.247942 total loss: 2.25627在预训练模型之后,我们可以从检查点加载参数,如下所示。让我们从预训练的GCPN模型中生成一些小分子。
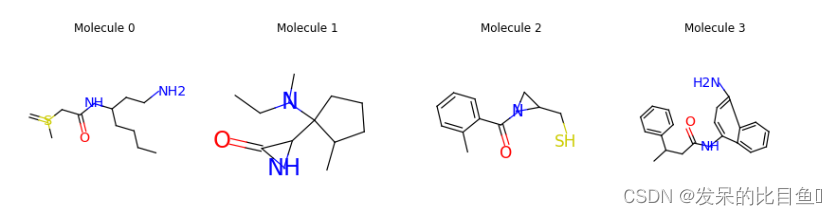
solver.load("path_to_dump/graphgeneration/gcpn_zinc250k_1epoch.pkl") results = task.generate(num_sample=32, max_resample=5) print(results.to_smiles())结果如下
C=S(C)CC(=O)NC(CCN)CCCC CCN(C)C1(C2NC2=O)CCCC1C CC1=CC=CC=C1C(=O)N1CC1CS CN=NC1=NC=CC2=CC=C(C=C2)CCNC(=O)C1 CC(CC(=O)NC1=CC=C(N)C2=CC=CC=C12)C1=CC=CC=C1 ...让我们想象一些生成的分子。
基于强化学习的目标导向分子生成:GCPN
对于药物的发现,我们需要优化生成分子的化学性质。在这一部分,我们介绍了如何微调生成图模型与强化学习,以优化生成分子的性质。我们实现了GCPN和GraphAF的近端策略优化(PPO)算法。为了用强化学习调整预训练模型,我们只需要修改任务初始化中的几行代码。我们将在下面的小节中提供所有用于微调的代码。
对于
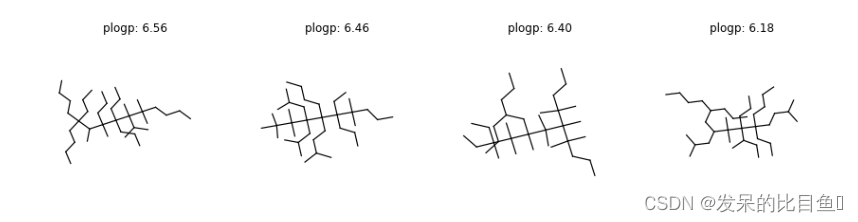
encrypted logP优化,代码如下:import torch from torchdrug import core, datasets, models, tasks from torch import nn, optim from collections import defaultdict dataset = datasets.ZINC250k("~/molecule-datasets/", kekulize=True, node_feature="symbol") model = models.RGCN(input_dim=dataset.node_feature_dim, num_relation=dataset.num_bond_type, hidden_dims=[256, 256, 256, 256], batch_norm=False) task = tasks.GCPNGeneration(model, dataset.atom_types, max_edge_unroll=12, max_node=38, task="plogp", criterion="ppo", reward_temperature=1, agent_update_interval=3, gamma=0.9) optimizer = optim.Adam(task.parameters(), lr=1e-5) solver = core.Engine(task, dataset, None, None, optimizer, gpus=(0,), batch_size=16, log_interval=10) solver.load("path_to_dump/graphgeneration/gcpn_zinc250k_1epoch.pkl", load_optimizer=False) # RL finetuning solver.train(num_epoch=10) solver.save("path_to_dump/graphgeneration/gcpn_zinc250k_1epoch_finetune.pkl")结果如下
(6.56, 'CCCCC(CCC)(CCCC)C(C)C(C)(CCC)C(CCC)(CCC)C(C)(C(C)C)C(C)(C)CCCC') (6.46, 'CCCCC(CCC(C)C)(C(CC)(CCC)C(C)(C)CCC)C(CC(C)C)(CC(C)C)C(C)(C)C(C)(C)C') (6.40, 'CCCC(CCC)CC(C)(C(C)(C)C(C)(CC)CC)C(C)(C)C(C)(C(C)(C)CCC)C(C)(C)CCC') (6.18, 'CCCCC(CCC)CC(CC(C)C)C(C)(C)C(CCC)(C(C)CC)C(CCC)(CCCC)CCC(C)C') ...让我们想象一些分子有大的惩罚logP分数(> 6)。
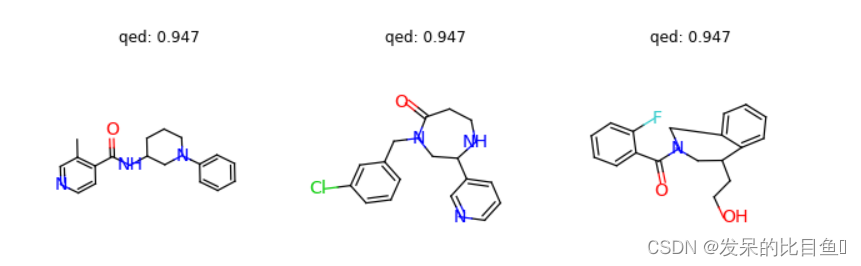
对于QED优化,任务初始化如下task = tasks.GCPNGeneration(model, dataset.atom_types, max_edge_unroll=12, max_node=38, task="qed", criterion=("ppo", "nll"), reward_temperature=1, agent_update_interval=3, gamma=0.9)结果如下:
(0.948, 'C1=CC=C(CNC2=NC=NCC3=CN2C(C2=COCC2)=C3)C=C1') (0.948, 'CCC1=CC=CC=C1NC(=O)C12CC(=O)N(C1)C1=CC=CC=C12') (0.947, 'O=C1CCNC(C2=CC=CN=C2)CN1CC1=CC=CC(Cl)=C1') (0.947, 'CC1=C(C(=O)NC2CCCN(C3=CC=CC=C3)C2)C=CN=C1') (0.947, 'CCNC1CCC2=CC=CC(=C2)N(C(=O)C2=CC=CC=N2)C1') (0.946, 'O=C(C1=CC=CC=C1F)N1CC2=CC=CC=C2C(CCO)C1') ...让我们想象一些具有较大QED分数的分子(> 0.945)。
定义模型:GraphAF
该模型由图表示模型和图生成模块两部分组成。我们定义了一个关系图卷积网络(RGCN)作为我们的表示模型。我们使用AutoregressiveGeneration模块作为graphhaf的训练任务。该任务由节点流模型和边缘流模型组成,它们定义了节点/边缘类型和噪声分布之间的可逆映射。
from torchdrug import core, models, tasks from torchdrug.layers import distribution model = models.RGCN(input_dim=dataset.num_atom_type, num_relation=dataset.num_bond_type, hidden_dims=[256, 256, 256], batch_norm=True) num_atom_type = dataset.num_atom_type # add one class for non-edge num_bond_type = dataset.num_bond_type + 1 node_prior = distribution.IndependentGaussian(torch.zeros(num_atom_type), torch.ones(num_atom_type)) edge_prior = distribution.IndependentGaussian(torch.zeros(num_bond_type), torch.ones(num_bond_type)) node_flow = models.GraphAF(model, node_prior, num_layer=12) edge_flow = models.GraphAF(model, edge_prior, use_edge=True, num_layer=12) task = tasks.AutoregressiveGeneration(node_flow, edge_flow, max_node=38, max_edge_unroll=12, criterion="nll")预训练和生成:GraphAF
现在我们可以训练我们的模型了。我们为我们的模型设置了一个优化器,并将所有内容放在一个 Engine 实例中。这里我们将模型训练 10 个 epoch,然后将预训练的模型保存到一个目录中。
from torch import nn, optim optimizer = optim.Adam(task.parameters(), lr = 1e-3) solver = core.Engine(task, dataset, None, None, optimizer, gpus=(0,), batch_size=128, log_interval=10) solver.train(num_epoch=10) solver.save("path_to_dump/graphgeneration/graphaf_zinc250k_10epoch.pkl")模型经过预训练后,我们可以从检查点加载参数。然后让我们从预训练的 GraphAF 模型中生成一些小分子。
from collections import defaultdict solver.load("path_to_dump/graphgeneration/graphaf_zinc250k_10epoch.pkl") results = task.generate(num_sample=32) print(results.to_smiles())结果如下:
CC(C)C=C(Cl)NC1=CC=CC=C1 CCOC(=NNCC(C=CC(C)=CC=CC=CC(C)=CC=O)(CO)CO)C(C)C CCC(C)(NC(C)Cl)C1=CC=CNC#CO1 O=C1NC2=CC(=CC=S)C1=CC=CC=C2 C=[SH]1(CC)C#SC(=NC(C)=C(C)Cl)C1N ...微调:GraphAF
对于 Penalized logP 优化,代码如下:
import torch from torchdrug import core, datasets, models, tasks from torchdrug.layers import distribution from torch import nn, optim from collections import defaultdict dataset = datasets.ZINC250k("~/molecule-datasets/", kekulize=True, node_feature="symbol") model = models.RGCN(input_dim=dataset.num_atom_type, num_relation=dataset.num_bond_type, hidden_dims=[256, 256, 256], batch_norm=True) num_atom_type = dataset.num_atom_type # add one class for non-edge num_bond_type = dataset.num_bond_type + 1 node_prior = distribution.IndependentGaussian(torch.zeros(num_atom_type), torch.ones(num_atom_type)) edge_prior = distribution.IndependentGaussian(torch.zeros(num_bond_type), torch.ones(num_bond_type)) node_flow = models.GraphAF(model, node_prior, num_layer=12) edge_flow = models.GraphAF(model, edge_prior, use_edge=True, num_layer=12) task = tasks.AutoregressiveGeneration(node_flow, edge_flow, max_node=38, max_edge_unroll=12, task="plogp", criterion="ppo", reward_temperature=20, baseline_momentum=0.9, agent_update_interval=5, gamma=0.9) optimizer = optim.Adam(task.parameters(), lr=1e-5) solver = core.Engine(task, dataset, None, None, optimizer, gpus=(0,), batch_size=64, log_interval=10) solver.load("path_to_dump/graphgeneration/graphaf_zinc250k_10epoch.pkl", load_optimizer=False) # RL finetuning solver.train(num_epoch=10) solver.save("path_to_dump/graphgeneration/graphaf_zinc250k_10epoch_finetune.pkl")结果如下:
(5.63, 'CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=C(I)C(C)(C)C') (5.60, 'CCC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC(C)(C)CCC') (5.44, 'CC=CC=CC=CC(Cl)=CC=CC=CC=CC=CC=C(C)C=CC=CC=C(C)C=CC(Br)=CC=CCCC') (5.35, 'CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=C(CC)C(C)C') ...task = tasks.AutoregressiveGeneration(node_flow, edge_flow, max_node=38, max_edge_unroll=12, task="qed", criterion={"ppo": 0.25, "nll": 1.0}, reward_temperature=10, baseline_momentum=0.9, agent_update_interval=5, gamma=0.9)结果如下:
(0.948, 'O=S(=O)(NC1=CC=CC=C1Br)C1=CC=CC=N1') (0.947, 'CC1CCNC(C2=CC=CC=C2)N1S(=O)(=O)C1=CC=CC=C1') (0.947, 'O=C(NCC1=C(Br)C=CC=C1F)C1=CC=CN=C1') (0.947, 'COC1=C(C2=C(Cl)C=CC(S(N)(=O)=O)=C2)C=CC=C1') (0.946, 'O=S(=O)(NC1=CC=CC=C1)C1=CC=C(Br)C=C1') (0.945, 'O=S(=O)(NC1=CC=CC(Br)=C1)C1=CC=CC=C1') ... -
相关阅读:
QT QSpinBox 整数计数器控件 使用详解
英特尔OpenVINO工程师认证答案及解析(初级✔/中级/高级)
vue中预览epub文件
springboot如何集成swagger,swagger如何为所有API添加token参数,swagger常用注解,简介明了,举例说明
一级造价工程师(安装)- 计量笔记 - 重点必考考点
230页10万字智慧城管系统整体建设方案
MyBatis学习:使用占位符#
docker-compose部署Atomci(云原生CICD平台)
框架设计:PC 端单页多页框架如何设计与落地
若依集成mybatisplus报错找不到xml
- 原文地址:https://blog.csdn.net/weixin_42486623/article/details/127039117