-
easyRL蘑菇书阅读笔记(一)
RL智能体的类型
- 基于价值的智能体,基于策略的智能体,演员-评论员智能体
策略:随机性策略+确定性策略,是一个函数,用于把输入的状态变成动作。
价值函数:价值函数的值是对未来奖励的预测,用于评估状态的好坏。
模型:基于策略的强化学习+基于价值的强化学习(第10页)
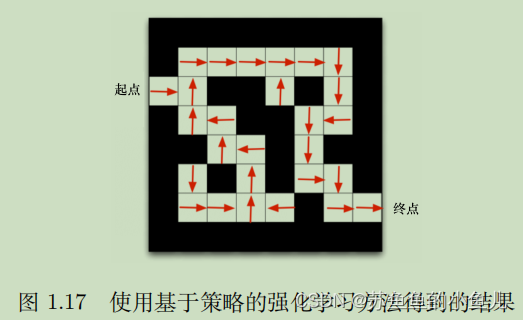
如果我们采取基于策略的强化学习(policy-based RL)方法,当学习好了这个环境后,在每一个状态,我们都会得到一个最佳的动作。如图 1.17 所示,比如我们现在在起点位置,我们知道最佳动作是往右走;在第二格的时候,得到的最佳动作是往上走;第三格是往右走… 通过最佳的策略,我们可以最快地到达终点。

如果换成基于价值的强化学习(value-based RL)方法,利用价值函数作为导向,我们就会得到另外一种表征,每一个状态会返回一个价值。如图 1.18 所示,比如我们在起点位置的时候,价值是 -16,因为我们最快可以 16 步到达终点。因为每走一步会减 1,所以这里的价值是 -16。当我们快接近终点的时候,
这个数字变得越来越大。在拐角的时候,比如现在在第二格,价值是 -15,智能体会看上、下两格,它看到上面格子的价值变大了,变成-14 了,下面格子的价值是 -16,那么智能体就会采取一个往上走的动
作。所以通过学习的价值的不同,我们可以抽取出现在最佳的策略。基于策略的强化学习算法:policy gradient
基于价值的强化学习算法:Q-learning、Sarsa- 有模型强化学习智能体(model-based)、免模型(model-free)强化学习智能体
强化学习任务表示为四元组 < S, A, P, R >,即状态集合、动作集合、状态转移函数和奖励函数。如果这个四元组中所有元素均已知,且状态集合和动作集合在有限步数内是有限集,则智能体可以对真实环境进行建模,就可以采用有模型强化学习;通常情况下,状态转移函数和奖励函数很难估计,这时就需要采用免模型强化学习,免模型强化学习没有对真实环境进行建模,智能体只能在真实环境中通过一定的策略来执行动作。
有模型强化学习相比免模型强化学习仅仅多出一个步骤,即对真实环境进行建模。免模型强化学习通常属于数据驱动型方法,需要大量的采样来估计状态、动作及奖励函数,从而优化动作策略,有模型的深度强化学习可以在一定程度上缓解训练数据匮乏的问题,大部分深度强化学习方法都采用了免模型强化学习。
关键词
探索(exploration):在当前的情况下,继续尝试新的动作。其有可能得到更高的奖励,也有可能一无
所有。
开发(exploitation):在当前的情况下,继续尝试已知的可以获得最大奖励的过程,即选择重复执行
当前动作。强化学习的基本结构:本质上是智能体与环境的交互。具体地,当智能体在环境中得到当前时刻状态后,其会基于此状态输出一个动作,这个动作会在环境中被执行并输出下一个状态和当前这个动作得到的奖励。智能体在环境里存在的目标是最大化期望累积奖励。
状态&观测:状态是对环境的完整描述,不会隐藏环境信息。观测是对状态的部分描述,可能会遗漏一些信息。在深度强化学习中,我们几乎总是用同一个实值向量、矩阵或者更高阶的张量来表示状态和观测。
-
相关阅读:
基于51单片机的信号发生器设计
Matlab-resample
Verilog:【3】边沿检测器(edge_detect.sv)
高级深入--day41
翻译: 详细图解Transformer多头自注意力机制 Attention Is All You Need
Debezium Mysql BinLog同步引擎的内存爆满,频繁GC导致CPU爆高
【SpringMVC】运行过程
如何写出匹配Java方法注释的正则表达式
LNMP及论坛的搭建
C++ Reference: Standard C++ Library reference: C Library: cwchar: btowc
- 原文地址:https://blog.csdn.net/qq_36846729/article/details/126975179