-
面试如何准备Redis的问题(含缓存穿透,持久化和数据一致性等知识点)
前言
Redis能用来展示缓存方面的技能,而且也不难准备,在本文里,就讲详细讲讲Redis面试该如何准备。
在介绍项目的时候,就说,我们项目用到了Redis做缓存,同时我还解决过了缓存穿透等方面的问题,如果按本文的方式准备到位,还可以加一句,本人还了解Redis的细节内容。
当然按照本人在之前文章里给出的引导做法,在项目介绍时不必展开,之后面试官自然会细问。这时大家就可以按如下的方法展开。
先结合项目业务介绍Redis的用法。在我们项目的仓库查询系统中,由于在一定时刻的并发量比较大,此时如果把请求全压到数据库里,就会压垮数据库,所以就引入缓存。
缓存里用到了货物ID作为键,用List的方式来存储货物信息,同时在设置时需要设置超时时间为1个小时。我们是用RedisTemplate在Spring Boot(或SSM等)框架里使用Redis。
刚才还讲到了解决了缓存穿透问题,如果面试官问起,你可以按如下的思路来说明。
一般缓存整合数据库的做法是,每次查询前先用键到Redis里去读数据,如果读到了就不走数据库,这样能提升性能,如果找不到再走数据库,每次在数据库里找到数据后,会把这条数据写入缓存,这样下次找该条数据,就能从缓存中找,而不必走数据库,这样能提升性能。
而缓存穿透是指,大量请求在查找数据时,这些数据的键值对不存在于缓存,这样每次请求都会走数据库,就像缓存不存在那样,这样在大并发量的前提下,依然会压垮数据库。
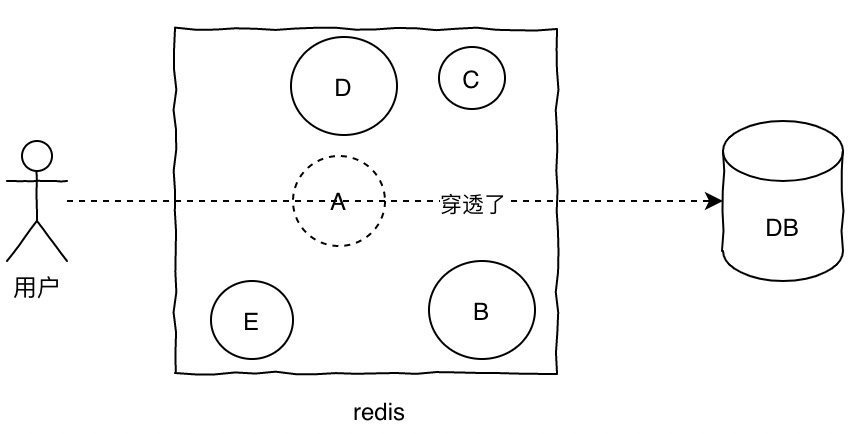
当然用布隆过滤器可以解决此类问题,不过如果面试者Java方面的能力一般,想准备些基础些的说辞,那可以这样说,我们项目里,遇到在数据库里找不到的数据,也会缓存到数据库里,比如键是该ID值,对应的值是null,或者是empty,或是一个不存在的值,但需要设置个较短的超时时间。这样下次找这个不存在的数据时,虽然还是找不到,但不会走数据库,直接从缓存这里就打回去了,所以依然能提升数据库层面的性能。
再准备些Redis数据结构方面的问题。
当你说好你是用Redis列表来缓存数据,那么面试官就有可能问,你还知道Redis哪些数据结构?你就可以说出如下的一些话。
redis的数据结构有字符串对象string、列表对象list、哈希对象hash、集合对象set、有序集合对象zset。
同时,Redis底层的数据结构如下:
- 字符串:redis是自己实现了名为简单动态字符串SDS的抽象类型。SDS则保存了长度信息,这样将获取字符串长度的时间由O(N)降低到了O(1),同时避免了缓冲区溢出和减少修改字符串长度时所需的内存分配次数。
- 链表linkedlist:这是个双向的非环状的链表结构,每个链表节点由一个listNode结构来表示&#x
-
相关阅读:
Python+大数据-知行教育(二)-访问咨询主题看板_全量流程
计算机基础 CMOS
QT页面布局方法大全
Selenium常用操作之单选复选框、下拉列表、键盘、截屏、断言、(显式隐式)等待
dotnet 探究 SemanticKernel 的 planner 的原理
js中正则的使用总结
Python中的shape[0]、shape[1]和shape[-1]分别是什么意思(附代码)
WZOI-354找子串
【 C++ 】智能指针
1.稀疏数组
- 原文地址:https://blog.csdn.net/mfmfmfo/article/details/126947506