-
vgg16猫狗识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:365天深度学习训练营-第8周:猫狗识别(训练营内部成员可读)
- 🍖 原作者:K同学啊|接辅导、项目定制
我的环境:
- 语言环境:Python3.8
- 编译器:jupyter lab
- 深度学习环境:TensorFlow2.5
- 参考文章:本人博客(60条消息) 机器学习之——tensorflow+pytorch_重邮研究森的博客-CSDN博客
● 难度:夯实基础⭐⭐
● 语言:Python3、TensorFlow2
● 时间:9月12-9月16日🍺 要求:
- 了解
model.train_on_batch()并运用(✔) - 了解tqdm,并使用tqdm实现可视化进度条(✔)
🍻 拔高(可选):
- 本文代码中存在一个严重的BUG,请找出它并配以文字说明(✔)
🔎 探索(难度有点大)
- 修改代码,处理BUG(✔)
目录
一 前期工作
环境:python3.7,1080ti,tensorflow2.5(网上租的环境😂😂)
由于电脑问题,现在在jupytr上跑了,所以代码风格发生变化。
1.设置GPU或者cpu
设置cpu(电脑gpu跑不动就用这个将就一下)
- from tensorflow import keras
- from tensorflow.keras import layers, models
- import os, PIL, pathlib
- import matplotlib.pyplot as plt
- import tensorflow as tf
- import numpy as np
- import tensorflow as tf
- import tensorflow as tf
- import os,PIL
- # os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
- #os.environ['CUDA_VISIBLE_DEVICES']='0'
- os.environ['CUDA_VISIBLE_DEVICES']='2'
- # os.environ['TF_CPP_MIN_LOG_LEVEL']='2'#屏蔽通知和警告信息
- import os,PIL
- os.environ['TF_XLA_FLAGS'] = '--tf_xla_enable_xla_devices'
- from tensorflow import keras
- keras.backend.clear_session()
设置gpu
- from tensorflow import keras
- from tensorflow.keras import layers,models
- import os, PIL, pathlib
- import matplotlib.pyplot as plt
- import tensorflow as tf
- import numpy as np
- gpus = tf.config.list_physical_devices("GPU")
- if gpus:
- gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
- tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
- tf.config.set_visible_devices([gpu0],"GPU")
- gpus
2.导入数据
- import matplotlib.pyplot as plt
- # 支持中文
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
- plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
- import os,PIL,pathlib
- #隐藏警告
- import warnings
- warnings.filterwarnings('ignore')
- data_dir = "./365-7-data"
- data_dir = pathlib.Path(data_dir)
运行3.查看数据
- image_count = len(list(data_dir.glob('*/*')))
- print("图片总数为:",image_count)
二 数据预处理
1.加载数据
设置数据尺寸
- batch_size = 8
- img_height = 224
- img_width = 224
运行设置dataset
- """
- 关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
- """
- train_ds = tf.keras.preprocessing.image_dataset_from_directory(
- data_dir,
- validation_split=0.2,
- subset="training",
- seed=12,
- image_size=(img_height, img_width),
- batch_size=batch_size)
- """
- 关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
- """
- val_ds = tf.keras.preprocessing.image_dataset_from_directory(
- data_dir,
- validation_split=0.2,
- subset="validation",
- seed=12,
- image_size=(img_height, img_width),
- batch_size=batch_size)
关于image_dataset_from_directory()的详细介绍可以参考文章:(7条消息) tf.keras.preprocessing.image_dataset_from_directory() 简介_K同学啊的博客-CSDN博客_tf.keras.preprocessing.image

输出经过image_dataset_from_directory()分类后的标签
- class_names = train_ds.class_names
- print(class_names)
2.可视化数据
打印部分图片
- for images, labels in train_ds.take(1):
- for i in range(8):
- ax = plt.subplot(5, 8, i + 1)
- plt.imshow(images[i])
- plt.title(class_names[labels[i]])
- plt.axis("off")

3.再次检查数据
输出数据的尺寸
- for image_batch, labels_batch in train_ds:
- print(image_batch.shape)
- print(labels_batch.shape)
- break
4.配置数据集
shuffle:打乱数据集
prefetch:加速处理
- AUTOTUNE = tf.data.AUTOTUNE
- def preprocess_image(image,label):
- return (image/255.0,label)
- # 归一化处理
- train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
- val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
- train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
- val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
三 搭建网络
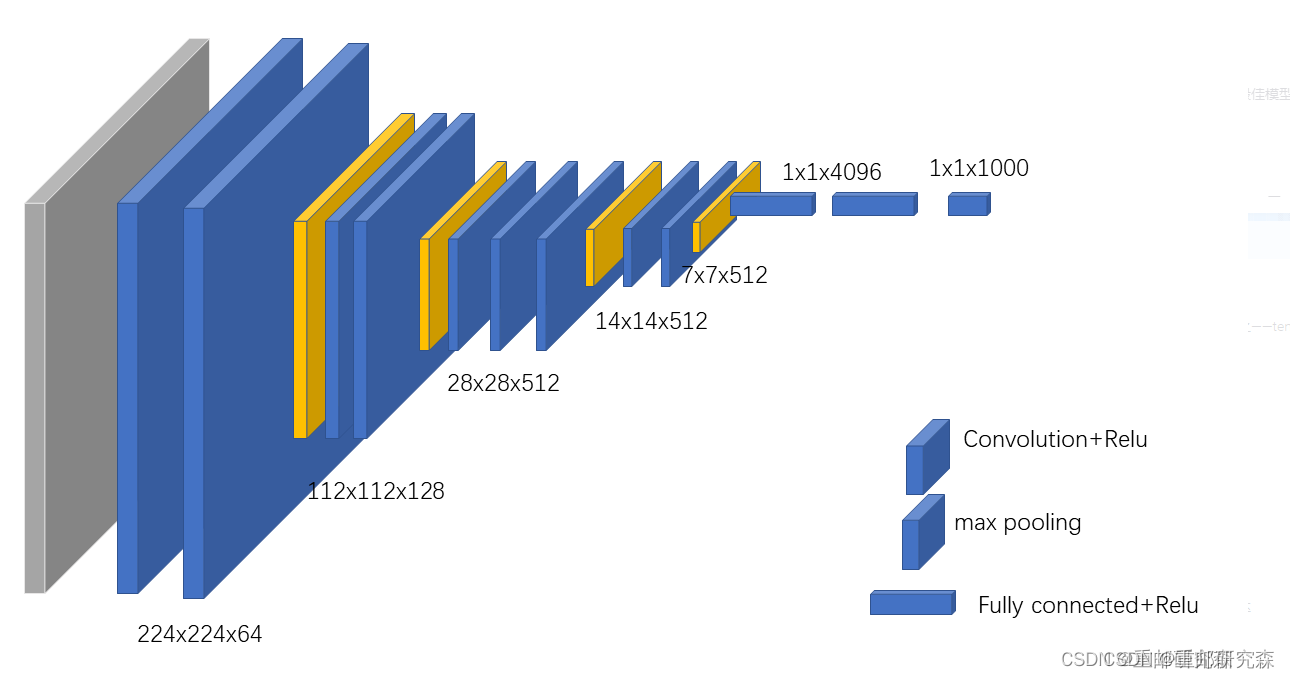
本文神经网络为官方vgg16模型,我们需要做的是对最后一层按我们的类别进行分类即可。
调用官方
- model = keras.applications.VGG16(include_top=False,weights='imagenet')
- global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
- prediction_layer1 = tf.keras.layers.Dense(1024,activation='relu')
- prediction_layer2 = tf.keras.layers.Dense(512,activation='relu')
- prediction_layer3 = tf.keras.layers.Dense(len(class_names),activation='softmax')
- model = tf.keras.Sequential([
- model,
- global_average_layer,
- prediction_layer1,
- prediction_layer2,
- prediction_layer3
- ])
- model.summary()

关于VGG16函数参考下面文章
(7条消息) keras 自带VGG16 net 参数分析_vola9527的博客-CSDN博客
我们对vgg16前部分卷积层没有改变,而是不选择官方的dense层,因为我们需要根据自己的数据进行输出,官方输出为1000种分类,我们只有2种,因此按照这个写法即可。
自己搭建
- model = models.Sequential([
- layers.experimental.preprocessing.Rescaling( 1. ,input_shape=(img_height, img_width, 3)),
- layers.Conv2D(filters=64, kernel_size=(3, 3), padding='same'), # 卷积层1
- #layers.BatchNormalization(), # BN层1
- layers.Activation('relu'), # 激活层1
- layers.Conv2D(filters=64, kernel_size=(3, 3), padding='same', ),
- #layers.BatchNormalization(), # BN层1
- layers.Activation('relu') , # 激活层1
- layers.MaxPool2D(pool_size=(2, 2), strides=2, padding='same'),
- #layers.Dropout(0.2), # dropout层
- #
- layers.Conv2D(filters=128, kernel_size=(3, 3), padding='same'),
- #layers.BatchNormalization(), # BN层1
- layers.Activation('relu'), # 激活层1
- layers.Conv2D(filters=128, kernel_size=(3, 3), padding='same'),
- #layers.BatchNormalization(), # BN层1
- layers.Activation('relu'), # 激活层1
- layers.MaxPool2D(pool_size=(2, 2), strides=2, padding='same'),
- #layers.Dropout(0.2), # dropout层
- #
- layers.Conv2D(filters=256, kernel_size=(3, 3), padding='same'),
- #layers.BatchNormalization() , # BN层1
- layers.Activation('relu'), # 激活层1
- layers.Conv2D(filters=256, kernel_size=(3, 3), padding='same'),
- #layers.BatchNormalization() , # BN层1
- layers.Activation('relu') , # 激活层1
- layers.Conv2D(filters=256, kernel_size=(3, 3), padding='same'),
- # layers.BatchNormalization(),
- layers.Activation('relu'),
- layers.MaxPool2D(pool_size=(2, 2), strides=2, padding='same'),
- #layers.Dropout(0.2),
- #
- layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same'),
- # layers.BatchNormalization() , # BN层1
- layers.Activation('relu') , # 激活层1
- layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same'),
- #layers.BatchNormalization() , # BN层1
- layers.Activation('relu'), # 激活层1
- layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same'),
- #layers.BatchNormalization(),
- layers.Activation('relu'),
- layers.MaxPool2D(pool_size=(2, 2), strides=2, padding='same'),
- #layers.Dropout(0.2),
- #
- layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same'),
- # layers.BatchNormalization() , # BN层1
- layers.Activation('relu'), # 激活层1
- layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same'),
- #layers.BatchNormalization(), # BN层1
- layers.Activation('relu'), # 激活层1
- layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same'),
- # layers.BatchNormalization(),
- layers.Activation('relu'),
- layers.MaxPool2D(pool_size=(2, 2), strides=2, padding='same'),
- #layers.Dropout(0.2),
- layers.Flatten(), # Flatten层,连接卷积层与全连接层
- layers.Dense(4096, activation='relu'), # 全连接层,特征进一步提取
- layers.Dense(4096, activation='relu'), # 全连接层,特征进一步提取
- layers.Dense(len(class_names),activation='softmax') # 输出层,输出预期结果
- ])
- model.summary()
四 训练模型
模型训练时,需要完成如下设置
损失函数(loss):衡量模型准确率
优化器(optimizer):根据损失函数进行优化更新
指标(metrics):监控训练过程,保存最优模型
1.设置学习率
- model.compile(optimizer="adam",
- loss ='sparse_categorical_crossentropy',
- metrics =['accuracy'])
注意损失函数不要用错了!
对于损失函数可以参考下面文章
(7条消息) tensorflow损失函数详解_重邮研究森的博客-CSDN博客
此外,需要注意在dataset设置中label_model的设置会影响loss
2.早期与保存最佳模型参数
关于ModelCheckpoint参考下面文章(7条消息) ModelCheckpoint 讲解【TensorFlow2入门手册】_K同学啊的博客-CSDN博客_modelcheckpoint的filepath
2.模型训练
- from tqdm import tqdm
- import tensorflow.keras.backend as K
- epochs = 10
- lr = 1e-4
- # 记录训练数据,方便后面的分析
- history_train_loss = []
- history_train_accuracy = []
- history_val_loss = []
- history_val_accuracy = []
- for epoch in range(epochs):
- train_total = len(train_ds)
- val_total = len(val_ds)
- """
- total:预期的迭代数目
- ncols:控制进度条宽度
- mininterval:进度更新最小间隔,以秒为单位(默认值:0.1)
- """
- with tqdm(total=train_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=1,ncols=100) as pbar:
- lr = lr*0.92
- K.set_value(model.optimizer.lr, lr)
- train_loss = []
- train_accuracy = []
- for image,label in train_ds:
- """
- 训练模型,简单理解train_on_batch就是:它是比model.fit()更高级的一个用法
- 想详细了解 train_on_batch 的同学,
- 可以看看我的这篇文章:https://www.yuque.com/mingtian-fkmxf/hv4lcq/ztt4gy
- """
- # 这里生成的是每一个batch的acc与loss
- history = model.train_on_batch(image,label)
- train_loss.append(history[0])
- train_accuracy.append(history[1])
- pbar.set_postfix({"train_loss": "%.4f"%history[0],
- "train_acc":"%.4f"%history[1],
- "lr": K.get_value(model.optimizer.lr)})
- pbar.update(1)
- history_train_loss.append(np.mean(train_loss))
- history_train_accuracy.append(np.mean(train_accuracy))
- print('开始验证!')
- with tqdm(total=val_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=0.3,ncols=100) as pbar:
- val_loss = []
- val_accuracy = []
- for image,label in val_ds:
- # 这里生成的是每一个batch的acc与loss
- history = model.test_on_batch(image,label)
- val_loss.append(history[0])
- val_accuracy.append(history[1])
- pbar.set_postfix({"val_loss": "%.4f"%history[0],
- "val_acc":"%.4f"%history[1]})
- pbar.update(1)
- history_val_loss.append(np.mean(val_loss))
- history_val_accuracy.append(np.mean(val_accuracy))
- print('结束验证!')
- print("验证loss为:%.4f"%np.mean(val_loss))
- print("验证准确率为:%.4f"%np.mean(val_accuracy))
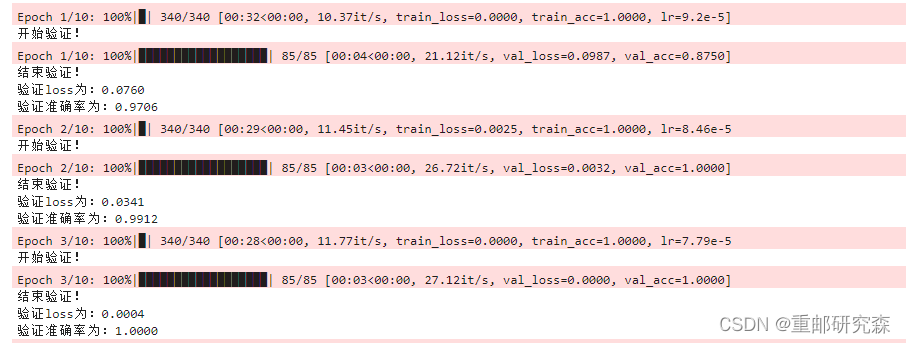
五 模型评估
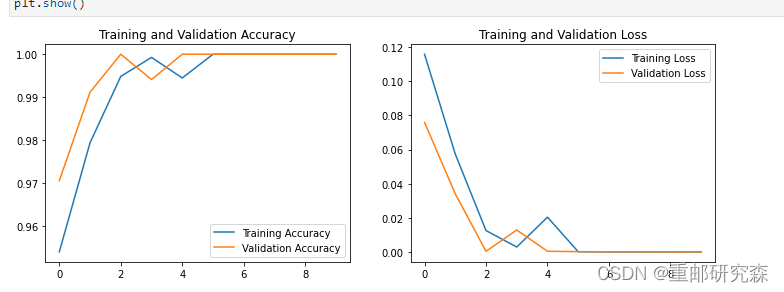
1.Loss和Accuracy图
2.指定图片进行预测
- import numpy as np
- # 采用加载的模型(new_model)来看预测结果
- plt.figure(figsize=(18, 3)) # 图形的宽为18高为5
- plt.suptitle("预测结果展示")
- for images, labels in val_ds.take(1):
- for i in range(8):
- ax = plt.subplot(1,8, i + 1)
- # 显示图片
- plt.imshow(images[i].numpy())
- # 需要给图片增加一个维度
- img_array = tf.expand_dims(images[i], 0)
- # 使用模型预测图片中的人物
- predictions = model.predict(img_array)
- plt.title(class_names[np.argmax(predictions)])
- plt.axis("off")

3.总结
1.了解了一种新的训练方式train_on_batch,我个人感觉看起来很麻烦!!!还是fit友好。
对于该方法可以参考下面这个文章。目前我个人认为还用不到这个方法。
model.train_on_batch介绍【TensorFlow2入门手册】 · 语雀 (yuque.com)
2.了解了python中的tqdm。简单来说就是对于一个循环,我们可以把它的信息通过进度条的方式打印下来。该方法可以参考下面文章
python进度条库tqdm详解 - 知乎 (zhihu.com)
3. 由于习惯之前写法,于是我又重新按照之前的模式写了。官方模型准确率:100%
4.关于错误问题:如下所示,之前会把每次的loss和val赋值给之前的值,而现在则是插入结果。

-
相关阅读:
【3etcd+3master+3woker+2lb】k8s实验环境搭建二:部署etcd服务
危重病入院镁浓度与乳酸酸中毒的关系
Vue学习——Vue-Cli创建Vue项目(19)
如何成为提示词工程师(精简版)
记录如何用php将敏感文字内容替换为星号的方法
刷题记录:牛客NC22598Rinne Loves Edges
批处理中的%~语法
【数字图像处理】1.绪论(mooc)
Rust You Don’t Know
行为型:迭代器模式
- 原文地址:https://blog.csdn.net/m0_60524373/article/details/126940637