-
Flink多流转换(一)
目录
8.1 分流
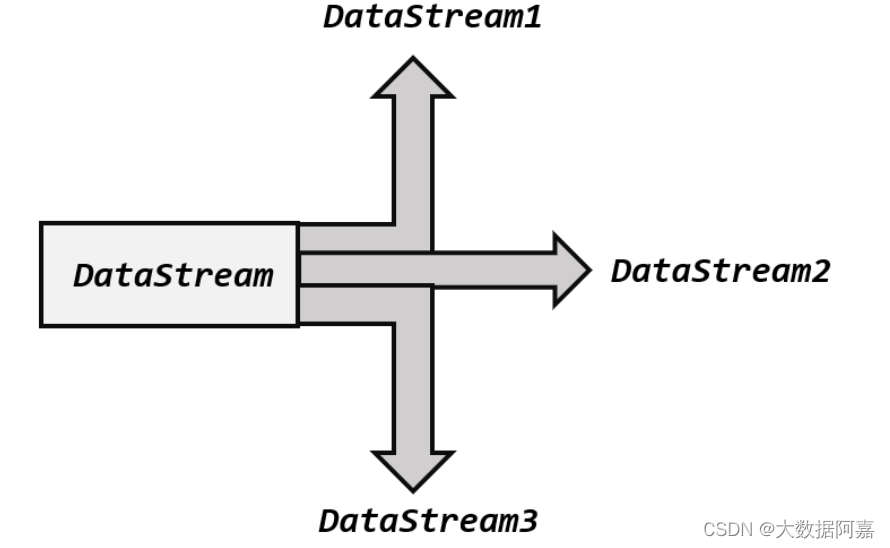
所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一个DataStream,得到完全平等的多个子 DataStream,如图 所示。一般来说,我们会定义一些 筛选条件,将符合条件的数据拣选出来放到对应的流里。
8.1.1 简单实现
其实根据条件筛选数据的需求,本身非常容易实现:只要针对同一条流多次独立调 用.filter()方法进行筛选,就可以得到拆分之后的流了。例如,我们可以将电商网站收集到的用户行为数据进行一个拆分,根据类型(type)的不 同,分为“Mary”的浏览数据、“Bob”的浏览数据等等。
- package com.atguigu.chapter08;
- import com.atguigu.chapter05.ClickSource;
- import com.atguigu.chapter05.Event;
- import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
- import org.apache.flink.api.common.eventtime.WatermarkStrategy;
- import org.apache.flink.api.java.tuple.Tuple2;
- import org.apache.flink.api.java.tuple.Tuple3;
- import org.apache.flink.streaming.api.datastream.DataStreamSource;
- import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.api.functions.ProcessFunction;
- import org.apache.flink.util.Collector;
- import org.apache.flink.util.OutputTag;
- import java.time.Duration;
- public class SplitStreamTest {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
- DataStreamSource
stream = env.addSource(new ClickSource()); - stream.assignTimestampsAndWatermarks(WatermarkStrategy.
forBoundedOutOfOrderness(Duration.ZERO) - .withTimestampAssigner(new SerializableTimestampAssigner
() { - @Override
- public long extractTimestamp(Event event, long l) {
- return event.timestamp;
- }
- }));
- //定义输出标签
- OutputTag
- OutputTag
- //
- SingleOutputStreamOperator
processedStream = stream.process(new ProcessFunction - @Override
- public void processElement(Event event, ProcessFunction
collector) - if (event.user.equals("Mary")) {//侧输出流1
- context.output(MaryTag, Tuple3.of(event.user, event.url, event.timestamp));
- } else if (event.user.equals("Bob")) {//侧输出流2
- context.output(BobTag, Tuple3.of(event.user, event.url, event.timestamp));
- } else {//主流
- collector.collect(event);
- }
- }
- });
- processedStream.print("else");
- processedStream.getSideOutput(MaryTag).print("Mary");
- processedStream.getSideOutput(BobTag).print("Bob");
- env.execute();
- }
- }
8.2 基本合流操作
既然一条流可以分开,自然多条流就可以合并。在实际应用中,我们经常会遇到来源不同 的多条流,需要将它们的数据进行联合处理。所以 Flink 中合流的操作会更加普遍,对应的API 也更加丰富。
8.2.1 联合(Union)
最简单的合流操作,就是直接将多条流合在一起,叫作流的“联合”(union),如图所示。联合操作要求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素, 数据类型不变。这种合流方式非常简单粗暴,就像公路上多个车道汇在一起一样。

在代码中,我们只要基于 DataStream 直接调用.union()方法,传入其他 DataStream 作为参 数,就可以实现流的联合了;得到的依然是一个 DataStream:
stream1.union(stream2, stream3, ...)注意:union()的参数可以是多个 DataStream,所以联合操作可以实现多条流的合并。
这里需要考虑一个问题。在事件时间语义下,水位线是时间的进度标志;不同的流中可能 水位线的进展快慢完全不同,如果它们合并在一起,水位线又该以哪个为准呢?
还以要考虑水位线的本质含义,是“之前的所有数据已经到齐了”;所以对于合流之后的 水位线,也是要以最小的那个为准,这样才可以保证所有流都不会再传来之前的数据。换句话 说,多流合并时处理的时效性是以最慢的那个流为准的。我们自然可以想到,这与之前介绍的 并行任务水位线传递的规则是完全一致的;多条流的合并,某种意义上也可以看作是多个并行 任务向同一个下游任务汇合的过程。
- package com.atguigu.chapter08;
- import com.atguigu.chapter05.ClickSource;
- import com.atguigu.chapter05.Event;
- import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
- import org.apache.flink.api.common.eventtime.WatermarkStrategy;
- import org.apache.flink.streaming.api.datastream.DataStreamSource;
- import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.api.functions.ProcessFunction;
- import org.apache.flink.util.Collector;
- import java.time.Duration;
- public class UnionTest {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env =
- StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
- SingleOutputStreamOperator
stream1 = env.socketTextStream("hadoop102", 7777) - .map(data -> {
- String[] field = data.split(",");
- return new Event(field[0].trim(), field[1].trim(),
- Long.valueOf(field[2].trim()));
- })
- .assignTimestampsAndWatermarks(WatermarkStrategy.
forBoundedOutOfOrderness(Duration.ofSeconds(2)) - .withTimestampAssigner(new SerializableTimestampAssigner
() { - @Override
- public long extractTimestamp(Event element, long
- recordTimestamp) {
- return element.timestamp;
- }
- })
- );
- stream1.print("stream1");
- SingleOutputStreamOperator
stream2 = env.socketTextStream("hadoop103", 7777) - .map(data -> {
- String[] field = data.split(",");
- return new Event(field[0].trim(), field[1].trim(),
- Long.valueOf(field[2].trim()));
- })
- .assignTimestampsAndWatermarks(WatermarkStrategy.
forBoundedOutOfOrderness(Duration.ofSeconds(5)) - .withTimestampAssigner(new SerializableTimestampAssigner
() { - @Override
- public long extractTimestamp(Event element, long
- recordTimestamp) {
- return element.timestamp;
- }
- })
- );
- stream2.print("stream2");
- // 合并两条流
- stream1.union(stream2)
- .process(new ProcessFunction
- @Override
- public void processElement(Event value, Context ctx, Collector
out) throws Exception { - out.collect(" 水 位 线 : " + ctx.timerService().currentWatermark());
- }
- })
- .print();
- env.execute();
- }
- }
这里为了更清晰地看到水位线的进展,我们创建了两条流来读取 socket 文本数据,并从 数据中提取时间戳作为生成水位线的依据。用 union 将两条流合并后,用一个 ProcessFunction来进行处理,获取当前的水位线进行输出。我们会发现两条流中每输入一个数据,合并之后的 流中都会有数据出现;而水位线只有在两条流中水位线最小值增大的时候,才会真正向前推进。
我们可以来分析一下程序的运行:
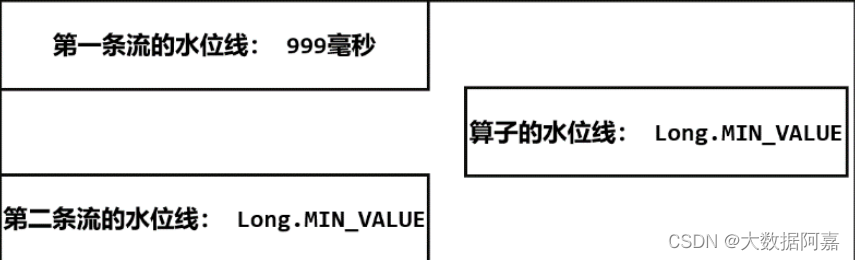
在合流之后的 ProcessFunction 对应的算子任务中,逻辑时钟的初始状态如图所示。
(初始状态)

由于 Flink 会在流的开始处,插入一个负无穷大(Long.MIN_VALUE)的水位线,所以合 流后的 ProcessFunction 对应的处理任务,会为合并的每条流保存一个“分区水位线”,初始值 都是 Long.MIN_VALUE;而此时算子任务的水位线是所有分区水位线的最小值,因此也是Long.MIN_VALUE。
我们在第一条 socket 文本流输入数据[Alice, ./home, 1000] 时,水位线不会立即改变,只 有到水位线生成周期的时间点(200ms 一次)才会推进到 1000 - 1 = 999 毫秒;这与我们在 7.3.2小节中对事件时间定时器的测试是一致的。不过即使第一条水位线推进到了 999,由于另一条 流没有变化,所以合流之后的 Process 任务水位线仍然是初始值。
(第一条流数据到达)
如果这时我们在第二条 socket 文本流输入数据[Alice, ./home, 2000],那么第二条流的水位线会随之推进到 2000 – 1 = 1999 毫秒,Process 任务所保存的第二条流分区水位线更新为 1999; 这样两个分区水位线取最小值,Process 任务的水位线也就可以推进到 999 了。
(第二条流数据到达)

进而如果我们继续在第一条流中输入数据[Alice, ./home, 3000],Process 任务的第一条流分 区水位线就会更新为 2999,同时将算子任务的时钟推进到 1999。
(第一条流数据再次到达)

8.2.2 连接(Connect)
流的联合虽然简单,不过受限于数据类型不能改变,灵活性大打折扣,所以实际应用较少 出现。除了联合(union),Flink 还提供了另外一种方便的合流操作——连接(connect)。顾名 思义,这种操作就是直接把两条流像接线一样对接起来。
1. 连接流(ConnectedStreams)
为了处理更加灵活,连接操作允许流的数据类型不同。但我们知道一个 DataStream 中的 数据只能有唯一的类型,所以连接得到的并不是 DataStream,而是一个“连接流” (ConnectedStreams)。连接流可以看成是两条流形式上的“统一”,被放在了一个同一个流中; 事实上内部仍保持各自的数据形式不变,彼此之间是相互独立的。要想得到新的 DataStream, 还需要进一步定义一个“同处理”(co-process)转换操作,用来说明对于不同来源、不同类型 的数据,怎样分别进行处理转换、得到统一的输出类型。所以整体上来,两条流的连接就像是 “一国两制”,两条流可以保持各自的数据类型、处理方式也可以不同,不过最终还是会统一到 同一个 DataStream 中。

在代码实现上,需要分为两步:首先基于一条 DataStream 调用.connect()方法,传入另外 一条 DataStream 作为参数,将两条流连接起来,得到一个 ConnectedStreams;然后再调用同处 理方法得到 DataStream。这里可以的调用的同处理方法有.map()/.flatMap(),以及.process()方法。
- package com.atguigu.chapter08;
- import com.atguigu.chapter05.Event;
- import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
- import org.apache.flink.api.common.eventtime.WatermarkStrategy;
- import org.apache.flink.streaming.api.datastream.ConnectedStreams;
- import org.apache.flink.streaming.api.datastream.DataStreamSource;
- import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.api.functions.co.CoMapFunction;
- import java.time.Duration;
- public class ConnectTest {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env =
- StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
- DataStreamSource
stream1 = env.fromElements(1, 2, 3); - DataStreamSource
stream2 = env.fromElements(4L, 5L, 6L,7L); - ConnectedStreams
- connectedStream.map(new CoMapFunction
- @Override
- public String map1(Long aLong) throws Exception {
- return "Long:"+aLong.toString();
- }
- @Override
- public String map2(Integer integer) throws Exception {
- return "Integer:"+integer.toString();
- }
- })
- .print();
- env.execute();
- }
- }
上面的代码中,ConnectedStreams 有两个类型参数,分别表示内部包含的两条流各自的数据类型;由于需要“一国两制”,因此调用.map()方法时传入的不再是一个简单的 MapFunction, 而是一个 CoMapFunction,表示分别对两条流中的数据执行 map 操作。这个接口有三个类型 参数,依次表示第一条流、第二条流,以及合并后的流中的数据类型。需要实现的方法也非常 直白:.map1()就是对第一条流中数据的 map 操作,.map2()则是针对第二条流。这里我们将一 条 Integer 流和一条 Long 流合并,转换成 String 输出。所以当遇到第一条流输入的整型值时, 调用.map1();而遇到第二条流输入的长整型数据时,调用.map2():最终都转换为字符串输出, 合并成了一条字符串流。
值得一提的是,ConnectedStreams 也可以直接调用.keyBy()进行按键分区的操作,得到的 还是一个 ConnectedStreams:
connectedStreams.keyBy(keySelector1, keySelector2);2. CoProcessFunction
对于连接流 ConnectedStreams 的处理操作,需要分别定义对两条流的处理转换,因此接口 中就会有两个相同的方法需要实现,用数字“1”“2”区分,在两条流中的数据到来时分别调 用。我们把这种接口叫作“协同处理函数”(co-process function)。与 CoMapFunction 类似,如 果是调用.flatMap()就需要传入一个 CoFlatMapFunction,需要实现 flatMap1()、flatMap2()两个 方法;而调用.process()时,传入的则是一个 CoProcessFunction。
抽象类 CoProcessFunction 在源码中定义如下:
- public abstract class CoProcessFunction
- AbstractRichFunction {
- ...
- public abstract void processElement1(IN1 value, Context ctx, Collector
- out) throws Exception;
- public abstract void processElement2(IN2 value, Context ctx, Collector
- out) throws Exception;
- public void onTimer(long timestamp, OnTimerContext ctx, Collector
out) throws Exception {} - public abstract class Context {...}
- ...
- }
下面是 CoProcessFunction 的一个具体示例:我们可以实现一个实时对账的需求,也就是
app 的支付操作和第三方的支付操作的一个双流 Join。App 的支付事件和第三方的支付事件将 会互相等待 5 秒钟,如果等不来对应的支付事件,那么就输出报警信息。程序如下:
- package com.atguigu.chapter08;
- import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
- import org.apache.flink.api.common.eventtime.WatermarkStrategy;
- import org.apache.flink.api.common.state.ValueState;
- import org.apache.flink.api.common.state.ValueStateDescriptor;
- import org.apache.flink.api.common.typeinfo.Types;
- import org.apache.flink.api.java.tuple.Tuple;
- import org.apache.flink.api.java.tuple.Tuple3;
- import org.apache.flink.api.java.tuple.Tuple4;
- import org.apache.flink.configuration.Configuration;
- import org.apache.flink.streaming.api.datastream.DataStreamSource;
- import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
- import org.apache.flink.util.Collector;
- import java.time.Duration;
- public class BillCheckExample {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
- //来自app的支付日志
- SingleOutputStreamOperator
- Tuple3.of("order-1", "app", 1000L),
- Tuple3.of("order-2", "app", 2000L),
- Tuple3.of("order-3", "app", 3500L)
- ).assignTimestampsAndWatermarks(WatermarkStrategy.
- .withTimestampAssigner(new SerializableTimestampAssigner
- @Override
- public long extractTimestamp(Tuple3
- return stringStringLongTuple3.f2;
- }
- }));
- //来自第三方支付平台的支付日志
- SingleOutputStreamOperator
- Tuple4.of("order-1", "third-party", "success", 3000L),
- Tuple4.of("order-3", "third-party", "success", 4000L)
- ).assignTimestampsAndWatermarks(WatermarkStrategy.
- .withTimestampAssigner(new SerializableTimestampAssigner
- @Override
- public long extractTimestamp(Tuple4
- return stringStringStringLongTuple4.f3;
- }
- }));
- //检测统一支付单在两条流中是否匹配,不匹配就报警
- /*
- appStream.keyBy(data -> data.f0)
- .connect(thirdPartStream.keyBy(data -> data.f0));
- */
- appStream.connect(thirdPartStream)
- .keyBy(data -> data.f0,data -> data.f0)
- .process(new OrderMatchResult())
- .print();
- env.execute();
- }
- //自定义实现CoProcessFunction
- public static class OrderMatchResult extends CoProcessFunction
- //定义状态变量,用来保存已经到达的事件
- private ValueState
- private ValueState
- @Override
- public void open(Configuration parameters) throws Exception {
- appEventState =getRuntimeContext().getState(
- new ValueStateDescriptor
- );
- thirdPartEventState=getRuntimeContext().getState(
- new ValueStateDescriptor
- );
- }
- @Override
- public void processElement1(Tuple3
collector) - //来的是app event,看另一条流中事件是否来过
- if(thirdPartEventState.value() !=null){ //来过
- collector.collect("对账成功"+stringStringLongTuple3+" "+thirdPartEventState.value());
- //清空状态
- thirdPartEventState.clear();
- }else {
- //更新状态
- appEventState.update(stringStringLongTuple3);
- //注册一个定时器,开始等待另一条流的事件
- context.timerService().registerEventTimeTimer(stringStringLongTuple3.f2+5000L);
- }
- }
- @Override
- public void processElement2(Tuple4
out) - if (appEventState.value() != null){
- out.collect("对账成功:" + appEventState.value() + " " + value);
- // 清空状态
- appEventState.clear();
- } else {
- // 更新状态
- thirdPartEventState.update(value);
- // 注册一个 5 秒后的定时器,开始等待另一条流的事件
- context.timerService().registerEventTimeTimer(value.f3 + 5000L);
- }
- }
- @Override
- public void onTimer(long timestamp, CoProcessFunction
out) - //定时器触发,判断状态,如果某个状态不为空,说明另一条流中事件没来
- if(appEventState.value()!=null){
- out.collect("对账失败"+appEventState.value()+" "+"第三方支付平台信息未到");
- }
- if(thirdPartEventState.value()!=null){
- out.collect("对账失败"+thirdPartEventState.value()+" "+"app信息未到");
- }
- appEventState.clear();
- thirdPartEventState.clear();
- }
- }
- }
在程序中,我们声明了两个状态变量分别用来保存 App 的支付信息和第三方的支付信息。
App 的支付信息到达以后,会检查对应的第三方支付信息是否已经先到达(先到达会保存在对 应的状态变量中),如果已经到达了,那么对账成功,直接输出对账成功的信息,并将保存第 三方支付消息的状态变量清空。如果 App 对应的第三方支付信息没有到来,那么我们会注册 一个 5 秒钟之后的定时器,也就是说等待第三方支付事件 5 秒钟。当定时器触发时,检查保存app 支付信息的状态变量是否还在,如果还在,说明对应的第三方支付信息没有到来,所以输 出报警信息。
-
相关阅读:
基于Java毕业设计学籍管理系统源码+系统+mysql+lw文档+部署软件
【短文】【踩坑】可以在Qt Designer给QTableWidge添加右键菜单吗?
30个Python常用极简代码,拿走就用
深度优先与宽度优先搜索(python)
图的关键路径(含多支交叉路径分离输出)
PX4模块设计之三十九:Commander模块
乐信面试经历
java.lang.unsupportedClassVersionError
vue-element-admin后台前端解决方案(基于 vue 和 element-ui)
【洛谷 B2001】入门测试题目 题解(模拟算法+顺序结构)
- 原文地址:https://blog.csdn.net/JiaXingNashishua/article/details/126915629
