-
时间序列预测:用电量预测 06 长短期记忆网络LSTM
🌮开发平台:jupyter lab
🍖运行环境:python3、TensorFlow2.x
----------------------------------------------- 2022.9.16 测验成功 ----------------------------------------------------------------
1. 时间序列预测:用电量预测 01 数据分析与建模
2. 时间序列预测:用电量预测 02 KNN(K邻近算法)
3. 时间序列预测:用电量预测 03 Linear(多元线性回归算法 & 数据未标准化)
4.时间序列预测:用电量预测 04 Std_Linear(多元线性回归算法 & 数据标准化)
5. 时间序列预测:用电量预测 05 BP神经网络
6.时间序列预测:用电量预测 06 长短期记忆网络LSTM
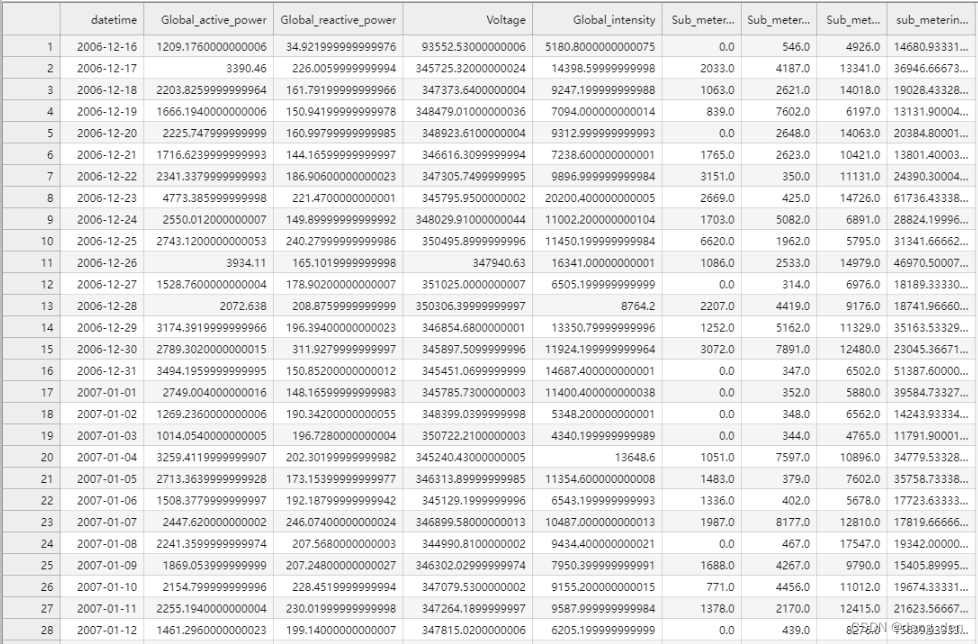
7. 时间序列预测:用电量预测 07 灰色预测算法说明:根据上述列表中 1.时间序列预测:用电量预测 01 数据分析与建模 进行数据整理,得到household_power_consumption_days.csv文件,部分数据展示如下:
时间序列预测:用电量预测 05 BP神经网络
1.导包
## LSTM 具有标准化和反标准化 ## 测试数据:训练数据、测试数据分别占比0.8,0.2 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import os import datetime from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import r2_score import tensorflow as tf from tensorflow.keras import Sequential, layers, utils, losses from tensorflow.keras.callbacks import ModelCheckpoint, TensorBoard import warnings warnings.filterwarnings('ignore')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2. 数据
2.1 数据获取
### 2.1 将日期变作index data = pd.read_csv('../1_Linear/household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime']) data.head() ### 2.2 查看data的关键字 dataset = data.copy() data.keys() ## out:Index(['Global_active_power', 'Global_reactive_power', 'Voltage','Global_intensity', 'Sub_metering_1', 'Sub_metering_2','Sub_metering_3', 'sub_metering_4'],dtype='object')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2 数据统一标准化
# 分别对字段'Global_active_power', 'Global_reactive_power', 'Voltage','Global_intensity'进行归一化 columns = ['Global_active_power', 'Global_reactive_power', 'Voltage', 'Global_intensity','Sub_metering_1', 'Sub_metering_2', 'Sub_metering_3','sub_metering_4'] for col in columns: scaler = MinMaxScaler() dataset[col] = scaler.fit_transform(dataset[col].values.reshape(-1,1))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.3 获取自变量和因变量
# 特征数据集 X = dataset.drop(columns=['sub_metering_4'], axis=1) # 标签数据集 y = dataset['sub_metering_4'] X.shape,y.shape #(1442, 7), (1442,)- 1
- 2
- 3
- 4
- 5
- 6
2.4 训练集、测试集划分
# shuffle=False 不能打乱 因为是时序预测 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False, random_state=111) X_train.shape,X_test.shape,X_test.shape,y_test.shape # (1153, 7), (289, 7), (289, 7), (289, 1)- 1
- 2
- 3
- 4
- 5
2.5 数据时序划分
## 1.按指定时间数划分数据 # seq_len=1 代表1个数据为一组 def create_dataset(X, y): features = [] targets = [] for i in range(0, len(X), 1): data = X.iloc[i] # 序列数据 data_x = [] data_x.append(data) label = y.iloc[i] # 标签数据 # 保存到features和labels features.append(data_x) targets.append(label) # 返回 return np.array(features), np.array(targets) ## 2.按照指定时间数划分训练集、测试集 # ① 构造训练特征数据集 train_dataset, train_labels = create_dataset(X_train, y_train) # ② 构造测试特征数据集 test_dataset, test_labels = create_dataset(X_test, y_test) # 1153 每个滑动窗口有1条数据 每条数据有7个特征 train_dataset.shape,train_labels.shape #out:(1153, 10 7), (1153,) test_dataset.shape,test_labels.shape #out:(289, 1, 7), (289,)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2.6 将训练集、测试集 自变量和因变量 捆绑在一起
def create_batch_dataset(X, y, train=True, buffer_size=1000, batch_size=128): batch_data = tf.data.Dataset.from_tensor_slices((tf.constant(X), tf.constant(y))) # 数据封装,tensor类型 if train: # 训练集 return batch_data.cache().shuffle(buffer_size).batch(batch_size) else: # 测试集 return batch_data.batch(batch_size) # 训练批数据 train_batch_dataset = create_batch_dataset(train_dataset, train_labels) # 测试批数据 test_batch_dataset = create_batch_dataset(test_dataset, test_labels, train=False)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.模型
3.1 模型构建,并训练
# 模型搭建--版本1 model = Sequential([ layers.LSTM(units=256, input_shape=train_dataset.shape[-2:], return_sequences=True), layers.Dropout(0.4), layers.LSTM(units=256, return_sequences=True), layers.Dropout(0.3), layers.LSTM(units=128, return_sequences=True), layers.LSTM(units=32), layers.Dense(1) ## 一个输出 ]) optimizer = tf.keras.optimizers.Adam(learning_rate=0.001) # 模型编译 model.compile(optimizer=optimizer,loss='mse') checkpoint_file = "best_model.hdf5" checkpoint_callback = ModelCheckpoint(filepath=checkpoint_file, monitor='loss', mode='min', save_best_only=True, save_weights_only=True) # 模型训练 history = model.fit(train_batch_dataset, epochs=50, validation_data=test_batch_dataset, callbacks=[checkpoint_callback])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28

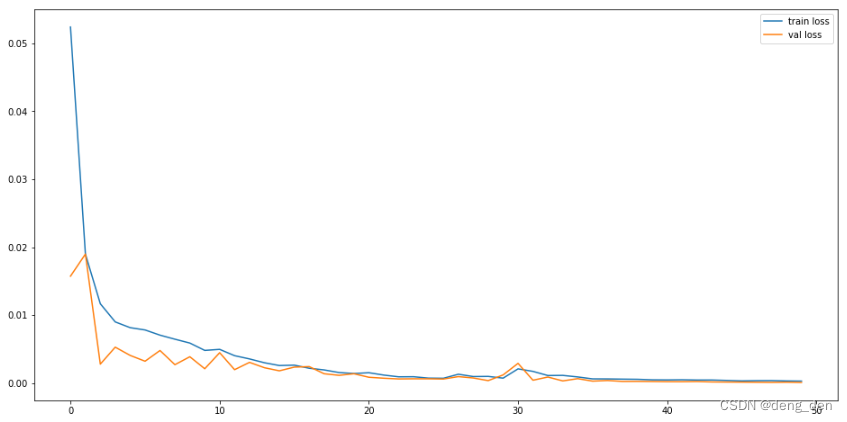
3.2 模型损失loss和val_loss对比图
# 显示训练结果 plt.figure(figsize=(16,8)) plt.plot(history.history['loss'], label='train loss') plt.plot(history.history['val_loss'], label='val loss') plt.legend(loc='best') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
3.3 数据预测
## 预测 test_preds = model.predict(test_dataset, verbose=1) ## 计算r2值 score = r2_score(test_labels, test_preds) print("r^2 值为: ", score) # out: r^2 值为: 0.9768187762301508 len(test_labels),len(test_preds) # out: (289, 289)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.数据展示
4.1 以可视化图的形式 对比 测试集原始目标数据和预测目标数据(未反标准化)
# 绘制 预测与真值结果 plt.figure(figsize=(16,8)) plt.plot(test_labels[:300], label="True value") plt.plot(test_preds[:300], label="Predicte value") plt.legend(loc='best') plt.show()- 1
- 2
- 3
- 4
- 5
- 6

4.2 以可视化图的形式对比测试集原始目标数据和预测目标数据(反标准化后的数据)
### 1.转换格式,用于反标准化后 真实值和预测值对比图 y_test = pd.DataFrame(y_test) # 2.test_preds,y_test反标准化 # 通过原有数据训练,实现反标准化 ## fit训练的是原本未归一化的y_test数据 scaler.fit(data[['sub_metering_4']]) y_new = scaler.inverse_transform(y_test) y_new_pred = scaler.inverse_transform(test_preds) len(y_new),len(y_new_pred) #out:(289, 289) # 3.绘制 预测与真值结果 plt.figure(figsize=(16,8)) plt.plot(y_new[:300], label="True value") plt.plot(y_new_pred[:300], label="Predicte value") plt.legend(loc='best') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

-
相关阅读:
C语言基础知识入门
2022年9月5号 每周任务
人工智能驱动的个性化学习:技术如何彻底改变教育
MySQL——使用mysqldump备份与恢复数据
JavaScript对象中数组对象和字符串对象的常用举例和使用
java反射大白话
页面元素和属性汇总
【C++】STL之String模拟实现
多元共进|科技促进艺术发展,助力文化传承
使用路网数据完成数据库专题训练
- 原文地址:https://blog.csdn.net/d_eng_/article/details/126909893
