-
SQL日常练习3-简单记录5问
1 统计每个用户累计访问
需求:

目标:
SQL:select *, sum(sum1) over (partition by userId order by visitMonth) as num2 ( select userId, substr(visitDate,0,6) as visitMonth, sum(visitCount) as sum1 from test1 group by userId, substr(visitDate,0,6) ) order by userId, visitDate;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
备注partition by和group by用法区别问题:
partition by是开窗函数内使用sum等函数时,不会改变结果行数,如sum是逐次累加显示 而group by则改变了返回结果行数,如sum id,则每个id只有一个sum结果,不是逐次累加- 1
- 2
2 统计店铺UV

问题1:

UV SQL:
方式2是用于对方式1 distinct的优化处理
问题2:
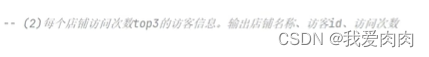
所有涉及TOP N问题,都可以用row_number函数排序取值来解决

方法2:用with as优化多层嵌套问题
3 指定条件下的数据筛选

问题:给出2017年2月新客数量(指2月之前没出现过的user_id数量)思路:先求出每个用户user_id的第一次出现的dt时间(也就是group by后dt最小的),然后选择dt为2月的就是需要的结果

4 根据年龄段对观影次数进行排序



期望结果
思路:先查询log表计算每个用户的url次数,然后age表划分每个用户的年龄段,最后join并根据年龄段sum
SQL:
with ti as ( select user_id, count(url) as cnt, from log group by user_id ), t2 as ( select user_id, age, case when age >= 0 and age <= 10 then "0-10" when age >= 10 and age <= 20 then "10-20" when age >= 20 and age <= 30 then "20-30" end age_phase from age ), t3 as ( select age_phase, sum(cnt) sum1 from t1 join t2 on t1.user_id = t2.user_id group by t2.age_phase ) 备注优化:大量的case when可以改成 concat( floor(age/10)*10,'-',floor(age/10+1)*10 ) as x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
5 所有用户的活跃用户总数和平均年龄

期望结果:
思路:1 所有用户的总数和平均年龄

2 活跃用户的总数和平均年龄 (活跃用户指连续两天访问的用户)
先打上rn标签如下图- 1


打上标签rn- 1

标签时间相减- 1

相减为1则为连续的天数,连续>=2则为活跃用户- 1

最后查询- 1

6 所有用户十月份第一次购买商品金额

7 访问接口top10的IP地址
问题

SQl:
8 查询每个区组下充值额最大的账号
问题:

SQL:
9 查询各自区组money排名前十的账号
问题:

SQL:
-
相关阅读:
91. 存钱罐
我真的从测试转成了开发......
Systrace系列10 —— Binder 和锁竞争解读
【低码】asp.net core 实体类可生产 CRUD 后台管理界面
PHP智云物业管理平台微信小程序系统源码
基于 SPI 的增强式插件框架设计
java学习一
初级算法_字符串 --- 字符串中的第一个唯一字符
TIPC messaging3
RepGhost
- 原文地址:https://blog.csdn.net/weixin_40503364/article/details/126532350
