-
Part15:Pandas怎样实现groupby分组统计
Pandas怎样实现groupby分组统计
类似SQL: select city,max(temperature) from city_weather group by city;
groupby:先对数据分组,然后在每个分组上应用聚合函数、转换函数本次演示:
一、分组使用聚合函数做数据统计
二、遍历groupby的结果理解执行流程
三、实例分组探索天气数据
- import pandas as pd
- import numpy as np
- #在jupyter notebook中展示matplot图表
- %matplotlib inline
- df=pd.DataFrame({
- 'A':['foo','bar','foo','bar','foo','bar','foo','foo'],
- 'B':['one','one','two','three','one','one','two','three'],
- 'C':np.random.randn(8),
- 'D':np.random.randn(8)
- })
- df

一、分组使用聚合函数做数据统计
1、单个列groupby,查询所有数据列的统计
- P=df.groupby('A').sum()
- #聚合操作后P仍然是一个Dataframe
- P

df.groupby('name').sum()
Ps: 1、将name列的不同名称作为索引
- 2、忽略df中不是数字列的一列
- 3、对是数字列的一列进行累加
- 4、统计在name不同名称下的,其他值的和
2、多个列groupby,查询所有数据列的统计
df.groupby(['A','B']).mean()
1、选取A、B两列的不同名称作为索引---在这里因为A列的bar没有B列中的two所以没有
2、对数字列进行求取平均值
3、统计在不同名下的平均值
4、将A、B变成二级索引
- #设置as_index=False,取消A、B作为二级索引
- df.groupby(['A','B'],as_index=False).mean()

3、同时查看多种数据统计
df.groupby('A').agg([np.sum,np.mean,np.std])
1、将name列的不同名称作为索引
- 2、忽略df中不是数字列的一列
- 3、对是数字列的一列进行操作
- 4、统计在name不同名称下的,其他值的和
列变成了多级索引
4、查看单列的结果数据统计
- #方法1:预过滤,性能更好
- df.groupby('A')['C'].agg([np.sum,np.mean,np.std])

- #方法2:
- df.groupby('A').agg([np.sum,np.mean,np.std])['C']

5、不同列使用不同的聚合函数
- df.groupby('A').agg({
- 'C':np.sum,
- 'D':np.mean
- })

二、遍历groupby的结果理解执行流程
for循环可以直接遍历每个group
1、遍历单个列聚合的分组
- g=df.groupby('A')
- g
- #相当于对A索引的不同值的列进行一个汇总,使数据看起来更加的清晰
- for name,group in g:
- print(name)
- print(group)
- print( )

可以获取单个分组的数据
g.get_group('bar')
2、遍历多个列聚合的分组
- g=df.groupby(['A','B'])
- for name,group in g:
- print(name)
- print(group)
- print( )
- #name 是一个2个元素的元组,代表不同的列

可以直接查询group后的某几列,生成Series或者子DataFrame
- g['C']
- for name,group in g:
- print(name)
- print(group)
- print( )

本质:所有的聚合统计,都是在dataframe和series上进行的
三、实例分组探索天气数据
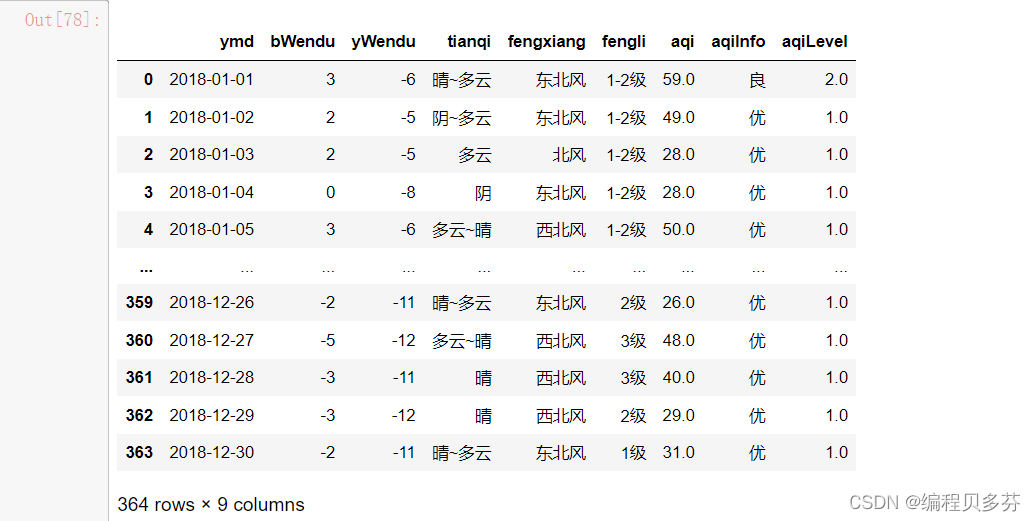
- fpath='./datas/beijing_tianqi/beijing_tianqi_2018.csv'
- df=pd.read_csv(fpath)
- df

- #替换掉温度后缀℃
- df.loc[:,'bWendu']=df['bWendu'].str.replace('℃','')
- df.loc[:,'yWendu']=df['yWendu'].str.replace('℃','')
- df

- df2=df.drop(labels=['bWendu','yWendu'], axis=0, inplace=False)
- df2
- df2.loc[:,'bWendu']=df2['bWendu'].astype('int32')
- df2.loc[:,'yWendu']=df2['yWendu'].astype('int32')
- df2.head()

- #新增一列为月份
- df['month']=df['ymd'].str[:7]
- df.head()

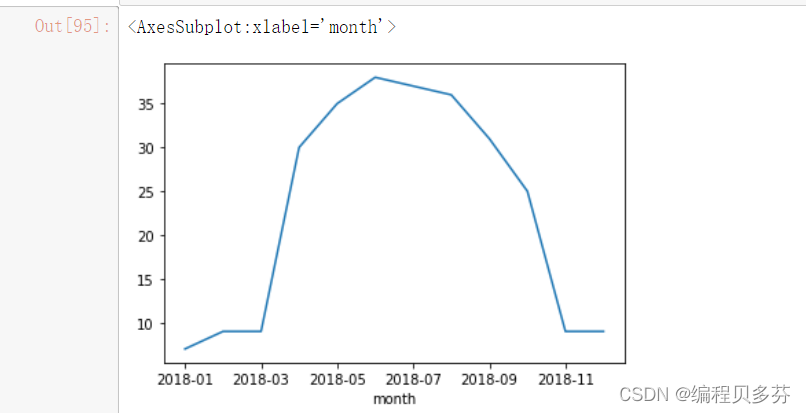
1、查看每个月的最高温度
- data=df.groupby('month')['bWendu'].max()
- data

- type(data)
- data=data.astype(float)
- data.plot()
2、查看每个月的最高温度、最低温度、平均空气质量指数
- df.head()
- group_data=df.groupby('month').agg({'bWendu':np.max,'yWendu':np.min,'aqi':np.mean})
- group_data


group_data.plot()
-
相关阅读:
PaddleOCR服务部署-并通过Java进行调用
vue集成mars3d后,basemaps加不上去
云课五分钟-07安装Opera失败-版本不匹配
mulesoft MCIA 易错题汇总解析
2023南京中医药大学计算机考研信息汇总
[技术发展-26]:新型信息与通信网络的数据安全
基于QT实现的图书室管理系统
接口性能优化的11个小技巧(荣耀典藏版)
可靠的自托管「GitHub 热点速览 v.22.37」
每天学习3个小时能不能考上浙大MBA项目?
- 原文地址:https://blog.csdn.net/qq_46044325/article/details/126904098