-
谣言检测论文精读——3.Detect Rumor and Stance Jointly by Neural Multi-task Learning
1.Abstract
谣言帖子经常在参与用户中引发多变的、主要是有争议的立场。 因此,确定相关帖子的立场可能与成功检测谣言有关。我们提出了一个联合框架,统一了两个高度相关的任务,即谣言检测和立场分类。 基于深度神经网络,我们使用权重共享联合训练两个任务以提取共同和任务不变的特征,而每个任务仍然可以学习其特定于任务的特征。
然而,据观察,反对谣言的怀疑和反对声音总是随着谣言的传播而出现,作为表明信息真实性的有用指标。识别谣言以及分析对相关信息的各种立场,对于早期预防谣言传播以尽量减少其负面影响是有意义和有益的。
我们的想法是基于人们的立场与相关信息的真实性密切相关的观察。 我们假设在这两个任务之间可以建立一些积极的相互反馈:对声明的指示性立场有助于揭穿谣言,而验证声明的真实性反过来又有助于推断所涉及帖子的立场。
下图是使用基于从我们的数据集中随机抽样的 100 个真实世界谣言事件的统计数据的直觉,可以看出,用户在虚假谣言中比在真实谣言中更倾向于表达否认立场而不是支持立场,而在真实谣言的推文中则相反,这表明相关推文中的立场可能是根据谣言类型推断出来的。

因此,受多任务学习 [5, 26] 成功的启发,我们试图通过统一架构中的相互反馈来加强谣言检测和立场分类。我们提出了统一的多任务模型,该模型学习了一组与两个任务相关的共同的、双边友好的特征,以促进它们的交互,同时每个任务也可以学习加强它们的交互。 通过相互学习的过程实现特定于任务的功能。
我们的贡献包括三个方面:- 据我们所知,这是第一项旨在以基于多任务学习的统一方法同时处理谣言检测和立场分类的工作,该方法成功地学会了对数据进行表示和分类 两个核心任务共同完成。
- 我们提出了两种基于RNN 的多任务架构,用于从两个任务中捕获共享的共同特征,并且还表明我们的模型不仅紧凑,而且能够敏捷开发除微博之外的新闻报道等新信息源平台。
- 我们通过对来自 Twitter 和新闻报道的真实世界数据集的广泛实验,对我们提出的方法进行实证评估,证明我们的多任务方法同时显着提高了两项任务的性能。
2.Related work
该部分简要回顾了与我们在三个主要领域相关的研究:谣言检测、立场分类和多任务学习。
下面简要概括每个部分与前期研究相比 我们的侧重点或者前期研究的不足
谣言检测
在这项工作中,我们将通过利用两个相关任务的特征学习能力来学习更好的谣言表示,这可以被认为是先前基于 RNN 的谣言检测方法的两个任务扩展
立场分类
现有方法的一个缺点是他们只认为推文是以目标为条件的,而忽略了立场也以目标的真实性为条件。
多任务学习
在大多数这些模型中,多任务架构基本上在所有任务中共享一些较低层以确定共同特征,而其余层是特定于任务的。 我们的模型受到基于 RNN 的多任务学习的通用共享结构的启发 。 我们的主要挑战在于设计一种有效的共享加权方法,通过增强谣言相关任务之间的交互来获得更好的任务特定表示。3.PROBLEM FORMULATION
我们的目标是制定一个多任务模型,该模型联合学习谣言检测和立场分类模型,其中一个任务可能使用或可能不使用与另一个相同来源的数据。 例如,考虑到训练数据的可用性和特定设置,我们通常可以在谣言检测中使用推文,但在立场分类中使用新闻报道。
因此声明通常与与其相关的帖子集合相关联。 因此,我们将 Twitter 数据建模为一组声明 {C1, C2, · · · , C | C | },其中每个声明 Ci = {(xij , tij )} 由一组相关推文组成,xij 是在时间 tij 发布的帖子。
rumor detection:我们将此任务表述为一个有监督的序列分类问题,它从标记的声明中学习一个分类器 f,每个声明 Ci 对应于其相关帖子 xi1xi2 的输入序列。 . . xiTi ,即 f : xi1xi2 。 . . xiTi → Yi ,其中 Yi 采用四个可能的类别标签之一:非谣言、真实谣言、虚假谣言和未经证实的谣言 (NTFU)。
Stance Classification:此任务是指确定每个单独的帖子或文件对声明的真实性表达的方向类型。我们根据特定的输入类型将其表述为序列标记或序列分类问题:- 当输入声明 Ci 由一系列帖子 xi1xi2 组成时。 . . xiTi ,它建模为序列标记,即 ä : xi1xi2 。 . . xiTi → yi1yi2 。 . . yiTi ,其中每个 yi j 是支持、否认、质疑或评论(SDQC)之一的标签。
- 当立场检测应用于假新闻检测等应用程序时,输入声明(或标题)可以与单个新闻文章相关联。 因此,它被认为是将新闻文章正文分类为上述四个类别之一。 让 xi1xi2 。 . . xiTi 是文章的句子序列对应于一个声明或标题 Ci ,问题就变成了序列分类,即 ä’ : xi1xi2 。 . . xiTi → yi ,其中 yi 取 SDQC 之一。
4.JOINT RUMOR AND STANCE DETECTION
该部分介绍联合谣言和立场检测
通过考虑任务间的相关性,可以共享在一个任务中学习的表示并用于加强另一个任务的特征学习,从而通过统一框架内的相互反馈提高两个任务的整体性能。
受基于 RNN 的神经多任务模型的启发,我们提出了两种基于 RNN 的具有共享层的深度架构。 第一个模型仅包含一个共享隐藏层,第二个模型通过考虑除共享层之外的其他特定于任务的隐藏层来增强Uniform Shared-Layer Architecture
不同的任务共享相同的隐藏层,每个任务都有自己的特定于任务的输入和嵌入

对于任务 m,给定输入声明的一系列帖子或句子 {xm t },一个简单的策略是使用一个 RNN 将每个输入单元 xm t 在时间步 t 映射到一个固定大小的向量,我们采用 GRU作为隐藏表示。 对于每个 t,GRU 转换方程如下:

其中 xm t 是第 t 个帖子,Em 表示特定于任务的嵌入矩阵,[W s ∗ ,Us ∗ ] 是 GRU 内部的权重连接,在不同任务之间共享。 正如标准 GRU 中定义的那样,hmt 和 hmt-1 分别指的是当前状态和先前状态; ⊙ 表示逐元素乘法; 重置门 rm t 确定如何将当前输入 xm t 与先前的记忆相结合,而更新门 zmt 定义了有多少来自先前帖子的先前记忆被级联到当前时间步; ̃ hmt 表示隐藏状态 hmt 的候选激活。Enhanced Shared-Layer Architecture
Uniform Shared-Layer Architecture的缺点:它忽略了一些模式在一项任务中应该比在另一项任务中更重要的事实。
为了解决这个问题,我们通过在每个任务的架构中添加一个额外的任务特定层来扩展模型。每个任务采用两个隐藏层:一个用于通过共享参数提取公共模式,另一个用于通过单独的参数捕获任务特定的特征。每个任务都分配有一个共享的 GRU 层和一个特定于任务的 GRU 层,它们有望用于捕获不同任务的共享和本地表示。

具体来说,对于任务 m,共享层在时间步 t 的输出计算为 hst = GRU (hst -1, xm t ),其中函数 GRU (·) 是等式的简写。 1. 为了增强任务特定层和共享层之间的交互,我们重新定义了 Eq。 1 并让 t 处的隐藏输出取决于来自共享层 hst 的隐藏状态、来自任务特定层 hmt-1 的先前隐藏状态以及当前输入 xm t 。 因此,任务 m 的任务特定层的隐藏状态可以计算为:

其中 xm t 是任务 m 的第 t 个输入,U s→m ∗ 表示连接共享层和任务特定层的权重矩阵。 其他设置与标准 GRU 相同。5.THE TRAINING PROCEDURE
该部分介绍模型架构的训练
对于任务的输入序列,其由增强架构发出的特定于任务的表示最终可以馈送到不同的输出层进行预测。 相反,对于统一架构,由于缺少任务特定层,来自共享层的隐藏状态可以直接馈送到输出层。
在谣言检测任务中,我们将其任务索引标记为 m = 1,并在最后一个时间步 hm=1 T 使用隐藏向量表示声明的整个帖子序列。 因此,索赔的最终分类决策在概率上被表述为 softmax:

其中 y 是不同谣言类别的预测概率向量,V m=1 是输出层的权重,bm=1 是可训练偏差,这两者都是谣言检测任务的特定任务参数。
在立场分类任务中,我们标记索引 m = 2 并让 hm=2 1 和 {hm=2 t }Tt=2 是声明(或标题)的低维任务特定表示,它们位于 第一个时间步和其余的帖子(或句子)的顺序时间步长分别被分类。 然后,我们将它们输入具有 softmax 激活函数的全连接层,以生成每个帖子(或文章 )的预测:
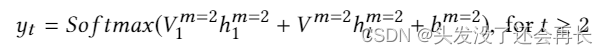
其中 yt 是在时间 t ≥ 2 时不同立场类别的预测概率,V m=1 1 和 V m=1 分别表示声明(或标题)和推文(或句子)的输出层的权重,以及 bm=2 是一个偏置项。 它们都是用于立场检测的特定于任务的参数。
对每个任务提出的多任务模型的参数进行训练,以最小化预测分布和地面实况分布的交叉熵:

其中,gc t 和 yc t 分别是在时间步 t 对应于第 c 个类别的 ground truth 和预测概率。 这里 L2 正则化器权衡了模型的误差和规模,Θ 是所有模型参数,λ是权衡系数。 请注意,对 t 的求和在不同情况下有不同的形式:对于序列分类(即谣言检测或基于文章的立场分类),t 采用最后一个时间步 T,因为只有 atT 的输出; 对于序列标记(即推文立场检测),2 ≤ t ≤ T 因为从第 2 步到 T 的每一步都有一个输出。多任务模型的训练过程:

在每次迭代中,随机选择一个任务,并根据任务特定的目标更新模型。 更具体地说,1)模型参数以均匀分布进行经验初始化,并通过反向传播[11]利用损失的导数进行更新; 2)我们使用AdaGrad算法[15]来加速收敛。 3)我们将词汇量固定为 5,000,嵌入和隐藏单元的大小为 100。 4)我们运行算法 1,直到每个任务的损失值收敛或达到最大 epoch 数。6.EXPERIMENTS AND RESULTS
该部分介绍实验和结果
对于谣言检测任务: 我们根据流行的谣言揭穿网站(例如,Snopes.com、Emergent.info 等) 采用的真实性标签,使用四个 NTFU 标签更细化了真实标签集。 此外,不同类型的谣言在现实世界中所占的比例是不平衡的。 根据我们自 2015 年 1 月以来基于 Snopes.com 的统计,NTFU 类别下的文章比例如下:非谣言 76.0%,虚假谣言 16.5%,真实谣言 3.4%,未经证实的谣言 4.1%。因此,我们通过实施 Liu 等人描述的推文收集方法来丰富数据集以符合此类分布。 表 (a) 给出了这个扩展数据集的统计数据,该数据集被命名为 LIU+。

对于立场分类任务,我们使用了 PHEME 数据集 [49],其中包含对应于 8 个突发事件的 297 个声明提供推文级别的立场注释。 我们遵循先前工作 [30, 48] 的常见做法,该工作使用该数据集根据 [30] 中提出的一组规则将原始标签转换为 SDQC 集。 在这项任务中,我们还检查了基于 2017 年假新闻挑战赛 (FNC, www.fakenewschallenge.org) 发布的新闻文章的附加数据集,该数据集旨在根据标题中的内容对新闻文章正文中的文本进行分类 . 立场必须分为四类:同意、不同意、讨论和无关。 我们在表 (b)中总结了两个立场数据集的统计数据。

我们使用微观平均和宏观平均 F1 分数作为这两个任务的评估指标。 我们在每个数据集中保留 10% 的实例用于模型调整,对于其余的实例,我们在所有实验中执行 5 折交叉验证。实验结果:

实验对比后的结论:
rumor detection- 当我们查看特定类别时,会发现在 Micro-F1(例如 DTC、SVM-TS、RFC)中表现更好的基线仅在多数类别(即非谣言)上表现更好,我们所提出的方法总体上具有优势,特别是对较难分类的三种少数谣言类型,并且可以更好地处理谣言检测中不平衡的类流行度。
- SVM-TS 和 RFC 似乎比其他基于特征的基线更好,因为它们都利用了一组广泛的特征,尤其是关注时间特征。 但它们比所有基于 RNN 的模型都要糟糕得多,后者可以通过捕获隐藏的非线性相关性来学习响应式推文的高级表示。 这表明复杂信号的有效性,表明谣言超出了通常在基线模型中使用的表面信号或浅层模式。
- MT-US 优于所有基线,包括将立场信息作为特征的模型。 这是因为所提出的多任务框架不能仅通过神经模型有效地学习谣言检测任务本身的表示,也可以通过从立场检测任务中转移一些有用的表示来加强学习的特征。
Stance Classification- 多任务提案的优势是显而易见的,因为 MT-US 和 MT-ES 在 Macro-F1 分数和大多数类的 F1 分数方面比所有基线产生更好的结果。
- 据观察,多数投票的 Micro-F1 非常高。 由于非常不平衡的类流行率,这不足为奇:大多数实例属于“评论”(或“无关”)类。 我们的模型在谣言检测任务中的较低 Micro-F1 分数同样证明了这一点
- 与其他基线相似,HP 只是利用 N-gram 等表面形式特征来表示内容,而我们的方法可以学习隐藏模式以获得更好的表示。
- 所有基于神经网络的基线(即 MT-single、BiGRU、CNN)的性能都比我们的两个多任务模型差,因为它们都是单任务模型,尽管它们具有强大的特征捕获能力。 在我们的多任务模型中,MT-ES 的性能优于 MT-US,这表明通过在共享层上的每个任务中添加特定于任务的层来提高效率。
- 有趣的是,所有模型在 FNC 上的表现都比 PHEME 数据集差。 这是因为大多数现有的立场分类方法都是为处理社交媒体数据而设计的。 然而,我们的多任务模型做出的巨大改进,尤其是在 FNC 数据集上,表明从不同数据平台学习的模式可以相互补充。 这表明我们提出的方法可以更有效地部署到社交媒体平台以外的新闻领域。
总
该工作尝试基于统一的神经多任务学习框架来联合优化这两个任务,采用两种基于 RNN 的多任务架构来对使用不同数据集的任务之间的信息共享和表示强化进行建模。
-
相关阅读:
洛谷 P6268 [SHOI2002]舞会(二分图最大独立集)
【无标题】
SPA单页面应用
Kubernetes的资源动态调度设计研究
优思学院|精益六西格玛中的8大浪费是什么?
如何用ChatGPT学或教英文?5个使用ChatGPT的应用场景!
Android SDK目录结构
web立体相册
pytorch UserWarningfault grid_sample; Python opencv Qt报Current thread的新解决方法
[NLP]LLM--使用LLama2进行离线推理
- 原文地址:https://blog.csdn.net/m0_51474171/article/details/126893783