-
Hadoop1_hadoop概览
1 大数据技术简介
1.1 大数据






1.2 Hadoop(两件事:海量数据存储和计算)





1.3 Hadoop和Hive、Spark的区别

1.4 Hadoop的3部分组成



1.4.1 HDFS架构3部分(目录-数据-备份)

1.4.2 YARN

1.4.3MapReduce
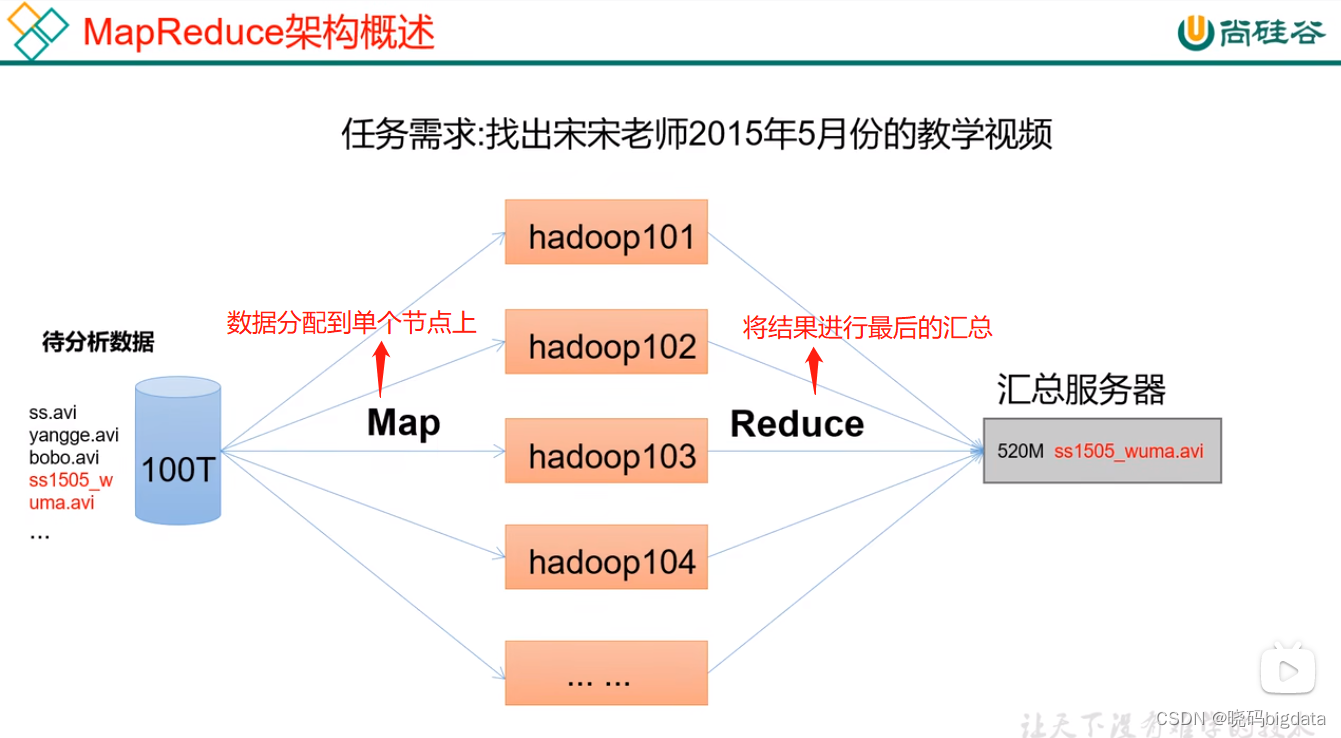
1.5 集群和节点
一个节点就是1台服务器
一个集群就是多台服务器,连成局域网多个服务器组合在一起称为集群,一般指应用服务器;存储型的服务器集群指得是:数据一个服务器放不下,分别放到不同机器中,这些机器称为集群。
一个或多个节点集合组成一个集群,集群上的节点可以存储数据,并提供跨节点的索引和搜索功能。
一个节点就是一个服务(实例),可以实现存储数据,索引并且搜索的功能。
每个节点都有一个唯一的名称作为身份标识;如果没有设置名称,默认使用 UUID 作为名称。推荐定义有意义的名称,便于更好的在集群中区分与管理。节点通过设置集群名称,在同一网络中发现具有相同集群名称的节点,组成集群。如果在同一网络中只有一个节点,则这个节点成为一个单节点集群,即此节点集群中每个节点都是功能齐全的服务。
1.6 hadoop在window上安装
Hadoop-3.0.0版本Windows安装_DELICACY.的博客-CSDN博客
https://blog.csdn.net/mr_yuntuo/article/details/907281742 HDFS(和操作mysql是一个道理)
在linux上面操作hdfs集群和mysql是一个道理,操作mysql是打开了mysql软件,让mysql软件执行一些命令,操作hdfs也是打开了hdfs软件,让hdfs软件执行一些命令。具体的文件还是存在你电脑上,只不过你看不懂,但是mysql和hdfs是可以看懂它存的文件的


2.1 特点

2.2 组成



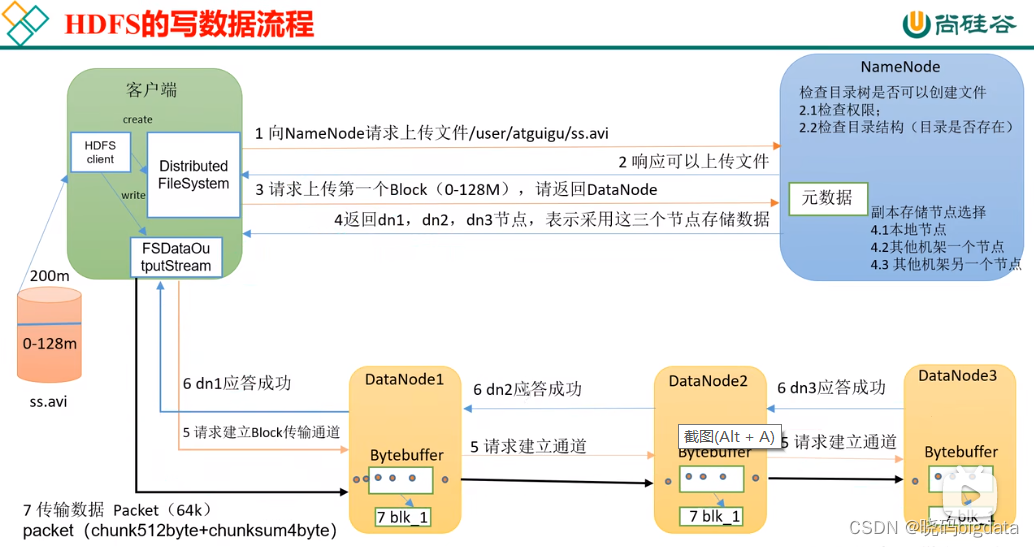
2.3 写数据
2.4 读数据

2.5 DataNode工作机制



3 MapReduce
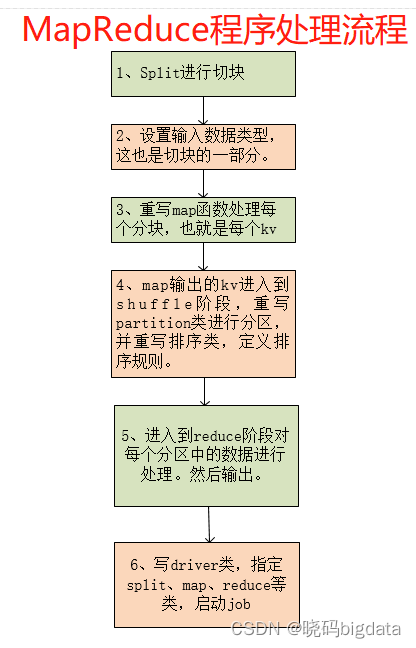

3.1 MapReduce执行原理
读取HDFS中的文件。每一行解析成一个
有几个分块就有几个k,v就有几个mapper。
split分块 ——(k,v)——mapper

3.2 执行的时候一般分为3个类(8股文)
1 主要功能类
2 MAP类
3 Reduce类

3.3 类型

3.4 MAP阶段

3.5 shuffle
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。
这一过程主要是分区和排序,就这两个过程;
有几个分区就对应几个reduce;
map过程出来的k,v根据k放到不同的分区中,然后reduce进行处理。
3.5 Reduce阶段


3.6 WordCount小案例

(1)创建项目和3个类
(2)配置依赖库
(3)添加资源文件
(4)实现这3个类在eclipse中实现3步:
1 建好包,把3个java文件考进去
2 把配置文件.perproties放到src目录下
3 导包,导入hadoop包3.7 序列化


3.8 自定义输出小案例(理解MapTask工作机制)
4 YARN
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
参考资料
1 看这个视频就够了,必须都学了,尚硅谷_Hadoop_概论
https://www.bilibili.com/video/BV1Qp4y1n7EN?p=4&spm_id_from=pageDriver&vd_source=eef37ea4f9af07ac3ada3c77ce1c6ec52 Hadoop Shell命令
https://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html3 Hadoop常用命令 - 走看看
http://t.zoukankan.com/hunttown-p-5809227.html4 hdfs shell的基本操作以及hdfsWeb查看文件 - 知乎
https://zhuanlan.zhihu.com/p/374573384 -
相关阅读:
ACE默认高效实现之自适应锁策略兼谈模板与宏
Qt5开发从入门到精通——第五篇二节( 文本编辑器 Easy Word 开发 V1.1 详解 )
026-为什么要使用接口
『亚马逊云科技产品测评』活动征文|搭建Squoosh图片在线压缩工具
荣誉榜再度添彩!热烈祝贺旭帆科技荣获安徽省大数据企业!
使用MybatisPlus快速进行增删改查
MySQL案例详解 二:MHA高可用配置及故障切换
什么是深度学习?最易懂的机器学习入门文章
WalkMe的数字用户体验到底是啥
在编程Python的时候发生ModuleNotFoundError: No module named distutils报错怎么办
- 原文地址:https://blog.csdn.net/xiaotiig/article/details/126459458