-
LeetCode·每日一题·850.矩形面积 || ·【离散化+扫描线+数组】
题目

示例

思路
什么是扫描线?
扫描线就是用来解决矩形覆盖面积问题。假如我们想要计算下图的覆盖面积,我们需要计算两个矩形的面积相加,然后减去中间蓝色交叉的部分。

若有n个矩形,我们需要计算他们两两交叉的面积,然后减去,时间复杂度非常高。假如我们可以对其进行分割,如图:

我们只需要计算矩形①②③的面积即可,于是问题转化为如何计算矩形①②③的面积。
矩形的宽很好计算,我们只需要把x轴的点按照从小到大的顺序排列即可。
难的是计算矩形的高。于是便有了扫描线。
定义:我们从左向右看,定义矩形的左侧边为入边,右侧边为出边,也就是我们扫描的方向,看起来就像用一个线从左向右来扫描所有的矩形
于是我们从左往右扫,遇到入边的线,则对入边区间进行+1操作,遇到出边的线,那么对出边区间进行-1操作。然后我们遍历整个区间,就得到了矩形的高。
我们举例计算:

当我们扫描到第一条边,是入边,范围是[1,3],于是我们给[1,3] + 1,此时整个范围只有[1,3]被覆盖,高为2,第一个矩形面积为 1 * 2 = 2

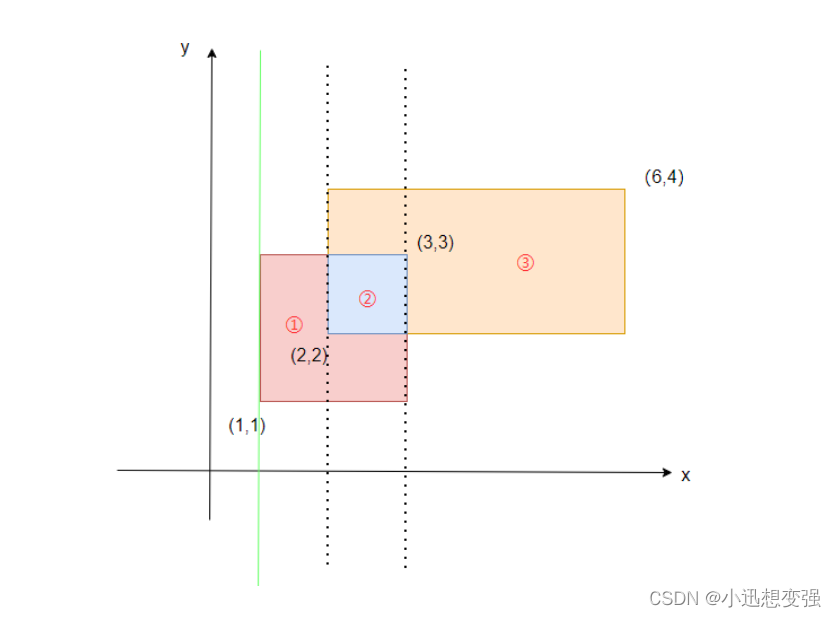 当我们扫描到第二条边,是入边,范围是[2,4],于是我们给[2,4] + 1,此时整个范围只有[1,4]被覆盖,高为3,第一个矩形面积为 1 * 3 = 3
当我们扫描到第二条边,是入边,范围是[2,4],于是我们给[2,4] + 1,此时整个范围只有[1,4]被覆盖,高为3,第一个矩形面积为 1 * 3 = 3
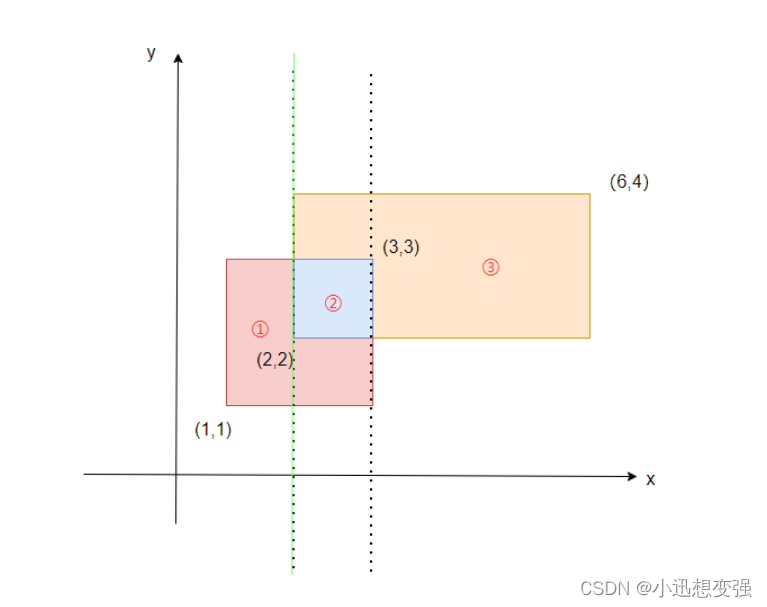
当我们扫描到第三条边,是出边,范围是[1,3],于是我们给[1,3] - 1,此时整个范围只有[2,4]被覆盖,高为2,第一个矩形面积为 3 * 2 = 6

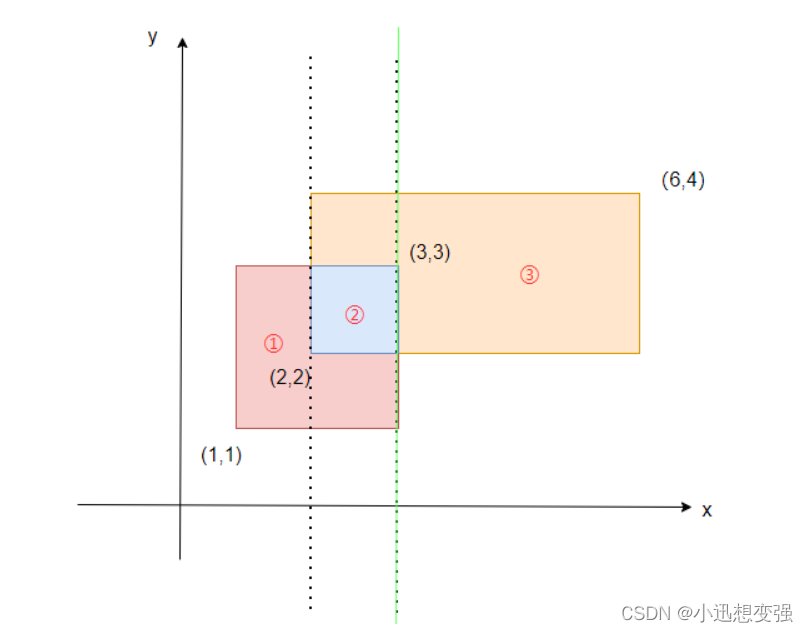
当我们扫描到第四条边,是出边,范围是[2,4],于是我们给[2,4] - 1,此时整个范围没有覆盖,结束计算

于是覆盖面积为2 + 3 + 6 = 11
计算高的方式就是区间问题,找所有区间内覆盖的长度,我们可以用线段树解决,线段树详解请移步。
为了方便,我们把所有的y坐标进行离散化处理
代码
- typedef struct {
- int key;
- UT_hash_handle hh;
- } HashItem;
- typedef struct Tuple {
- int val[3];
- } Tuple;
- HashItem *hashFindItem(HashItem **obj, int key) {
- HashItem *pEntry = NULL;
- HASH_FIND_INT(*obj, &key, pEntry);
- return pEntry;
- }
- bool hashAddItem(HashItem **obj, int key) {
- if (hashFindItem(obj, key)) {
- return false;
- }
- HashItem *pEntry = (HashItem *)malloc(sizeof(HashItem));
- pEntry->key = key;
- HASH_ADD_INT(*obj, key, pEntry);
- return true;
- }
- void hashFree(HashItem **obj) {
- HashItem *curr = NULL, *tmp = NULL;
- HASH_ITER(hh, *obj, curr, tmp) {
- HASH_DEL(*obj, curr);
- free(curr);
- }
- }
- static inline int cmp1(const void *pa, const void *pb) {
- return *(int *)pa - *(int *)pb;
- }
- static inline int cmp2(const void *pa, const void *pb) {
- Tuple *a = (Tuple *)pa, *b = (Tuple *)pb;
- if (a->val[0] != b->val[0]) {
- return a->val[0] - b->val[0];
- } else if (a->val[1] != b->val[1]) {
- return a->val[1] - b->val[1];
- } else {
- return a->val[2] - b->val[2];
- }
- }
- int rectangleArea(int** rectangles, int rectanglesSize, int* rectanglesColSize){
- int n = rectanglesSize;
- HashItem *set = NULL;
- for (int i = 0; i < n; i++) {
- // 下边界
- hashAddItem(&set, rectangles[i][1]);
- // 上边界
- hashAddItem(&set, rectangles[i][3]);
- }
- int hboundSize = HASH_COUNT(set);
- int hbound[hboundSize], pos = 0;
- for (HashItem *pEntry = set; pEntry != NULL; pEntry = pEntry->hh.next) {
- hbound[pos++] = pEntry->key;
- }
- hashFree(&set);
- qsort(hbound, hboundSize, sizeof(int), cmp1);
- // 「思路与算法部分」的 length 数组并不需要显式地存储下来
- // length[i] 可以通过 hbound[i+1] - hbound[i] 得到
- int seg[hboundSize - 1];
- int sweepSize = n * 2;
- Tuple sweep[sweepSize];
- pos = 0;
- memset(seg, 0, sizeof(seg));
- for (int i = 0; i < n; ++i) {
- // 左边界
- sweep[pos].val[0] = rectangles[i][0];
- sweep[pos].val[1] = i;
- sweep[pos].val[2] = 1;
- pos++;
- // 右边界
- sweep[pos].val[0] = rectangles[i][2];
- sweep[pos].val[1] = i;
- sweep[pos].val[2] = -1;
- pos++;
- }
- qsort(sweep, sweepSize, sizeof(Tuple), cmp2);
- long long ans = 0;
- for (int i = 0; i < n * 2; ++i) {
- int j = i;
- while (j + 1 < sweepSize && sweep[i].val[0] == sweep[j + 1].val[0]) {
- ++j;
- }
- if (j + 1 == sweepSize) {
- break;
- }
- // 一次性地处理掉一批横坐标相同的左右边界
- for (int k = i; k <= j; ++k) {
- int idx = sweep[k].val[1], diff = sweep[k].val[2];
- int left = rectangles[idx][1], right = rectangles[idx][3];
- for (int x = 0; x < hboundSize - 1; ++x) {
- if (left <= hbound[x] && hbound[x + 1] <= right) {
- seg[x] += diff;
- }
- }
- }
- int cover = 0;
- for (int k = 0; k < hboundSize - 1; ++k) {
- if (seg[k] > 0) {
- cover += (hbound[k + 1] - hbound[k]);
- }
- }
- ans += (long long)cover * (sweep[j + 1].val[0] - sweep[j].val[0]);
- i = j;
- }
- return ans % (long long)(1e9 + 7);
- }
-
相关阅读:
[电源选项]没有系统散热方式,没有被动散热选项
AM@有理函数的积分@有理分式积分
5、Linux驱动开发:设备-设备注册
C++ continue 语句
人工智能技术的应用前景:改变我们的生活和工作方式
使用水泥混凝土摊铺机进行建设公路项目有这样的特点
驭数有道,天翼云数据库 TeleDB 全新升级
华为HCIE云计算之FA桌面云业务发放
离散Hopfield神经网络分类——高校科研能力评价
Java刷题大全(笔试题)【大厂必备】(基础)
- 原文地址:https://blog.csdn.net/m0_64560763/article/details/126885371
