-
TDDL介绍及原理
目录
产生背景:
- 单一数据库无法满足要求
-
- 数据分库分表
- 读写分离
- 系统容灾
-
- 主备切换
- 运维管理
-
- 动态数据源
TDDL原理
三层数据源做了什么

- Matrix: 主要做sql解释、优化和执行,把要做的事情发给下一层
- group: 它可以给下一层做主备切换、读写分离上一层是感受不到的,group里面有不同的db,在这里有数据的切分,所以有了不同的db区
- Atom: 一个group有多个atom,主备分别是不同的atom,它主要做了链接的管理,如何和物理数据库进行连接

如上图,group里面将一个表分成了许多的表,具体的落库是在atom,而这些分库分表和链接是根据规则进行的。
TDDL工作流程

- 首先会根据mybatis传来的sql,即图中的client传来的sql给到Matrix
- Matrix会根据算法规则给到具体的分区(图中是根据ID进行拆分的的)
- 图中看到ID=3的发送给了group0,ID=2的发送给了group1
- 在group中根据读写分离的规则以及权重规则发送给Atom进行具体的落库或者是查询
- 如果是查询操作最后会在Matrix进行数据的合并
- 最后传回client端
TDDL架构

matrix和repo的作用上面已经解释
动态配置加载与管理:它需要配置三个数据源和一些规则,它会动态的更新服务器的状态,比如atom主服务器宕机就会告诉group进行一个主备切换,并且进行一个权重的变化。

在Matrix层具有解释器、优化器、执行器
优化器:可以进行一些简单的语法优化进行一些性能的优化
解释器:如果SQL有一些聚合函数、join、函数计算需要在上层进行执行以及join的下推,tddl都是支持的。
TDDL的主备切换

上图是未宕机时和MySQL建立的连接
在宕机后会切换IP地址,这里有一个巡检的任务,当主机挂掉之后,会进行主从之间的切换,切换时会把主库变为从库,从库变为主库,切换成功之后就会改配置,在group中会有它与主库的绑定信息和从库的绑定信息即group和atom之间的关系,之后会把IP地址会告诉group层会和新的IP地址进行绑定为主库,主库修改为从库配置,动态配置加载与管理会订阅这里的修改,之后会推送到动态配置加载与管理。
读写分离
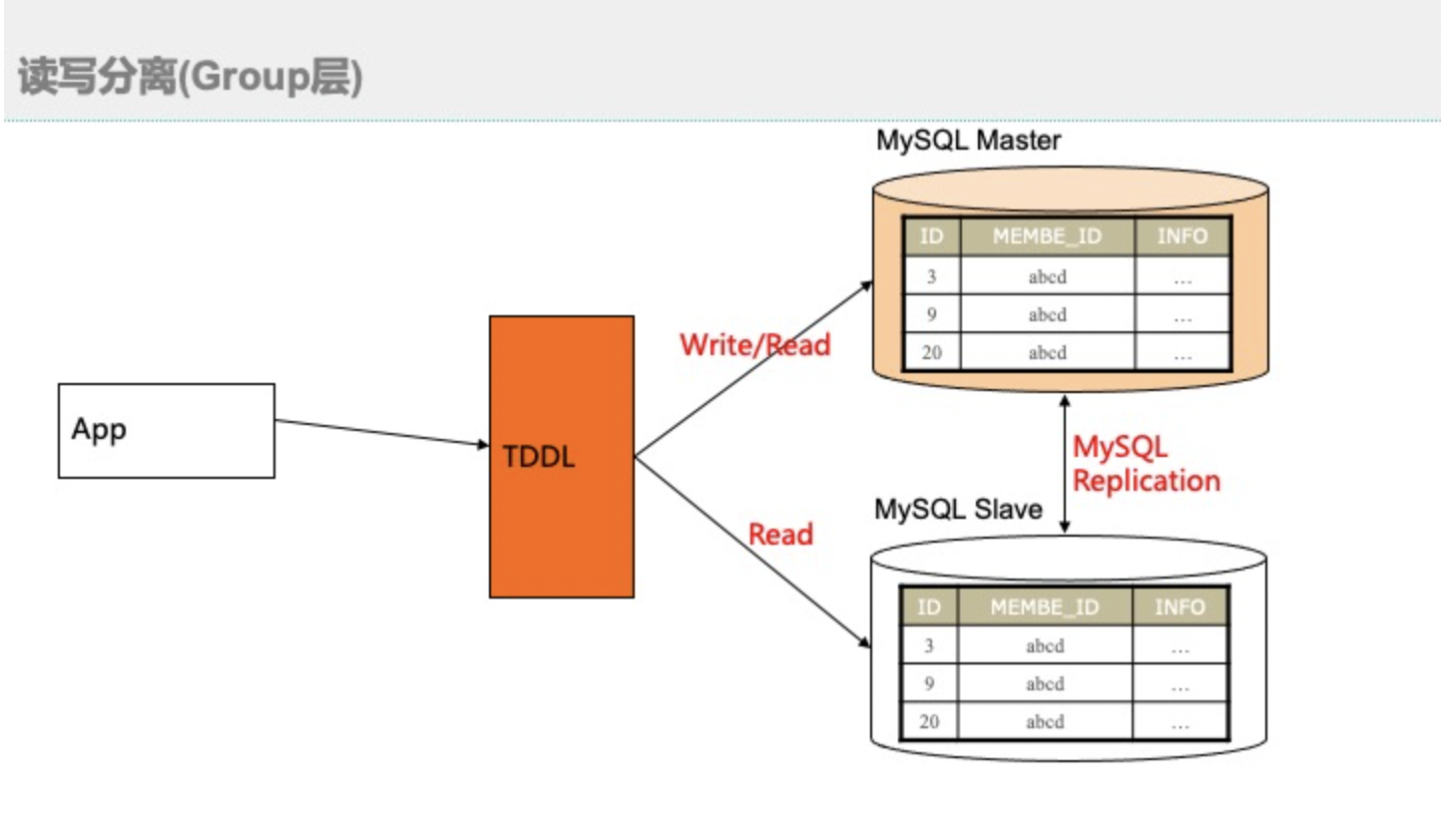
在进行读写分离时,主机可以进行读也可以进行写,而从机则只能进行读。
水平拆分
 正在上传…重新上传取消
正在上传…重新上传取消首先要选择拆分字段:
选取规则:
- 离散程度比较大的:如果选取的字段做哈希之后还是打在同一数据库上那么这个分库和没有分库没什么区别
- 字段没有空数据
选取好字段之后会根据哈希函数决定要操作到哪个atom数据库
一般在扩容时需要提前配置好三层数据源,哈希函数也要改变
拆分表的数据库访问
 正在上传…重新上传取消如果查询时有不同的拆分字段,会把它们分别进行哈希去查询不同的库,最后进行数据集的合并。
正在上传…重新上传取消如果查询时有不同的拆分字段,会把它们分别进行哈希去查询不同的库,最后进行数据集的合并。思考:如果查询的不是拆分字段怎么办?
使用搜索引擎中间件,根据所给数据先查询到拆分字段在进行查询
路由规则
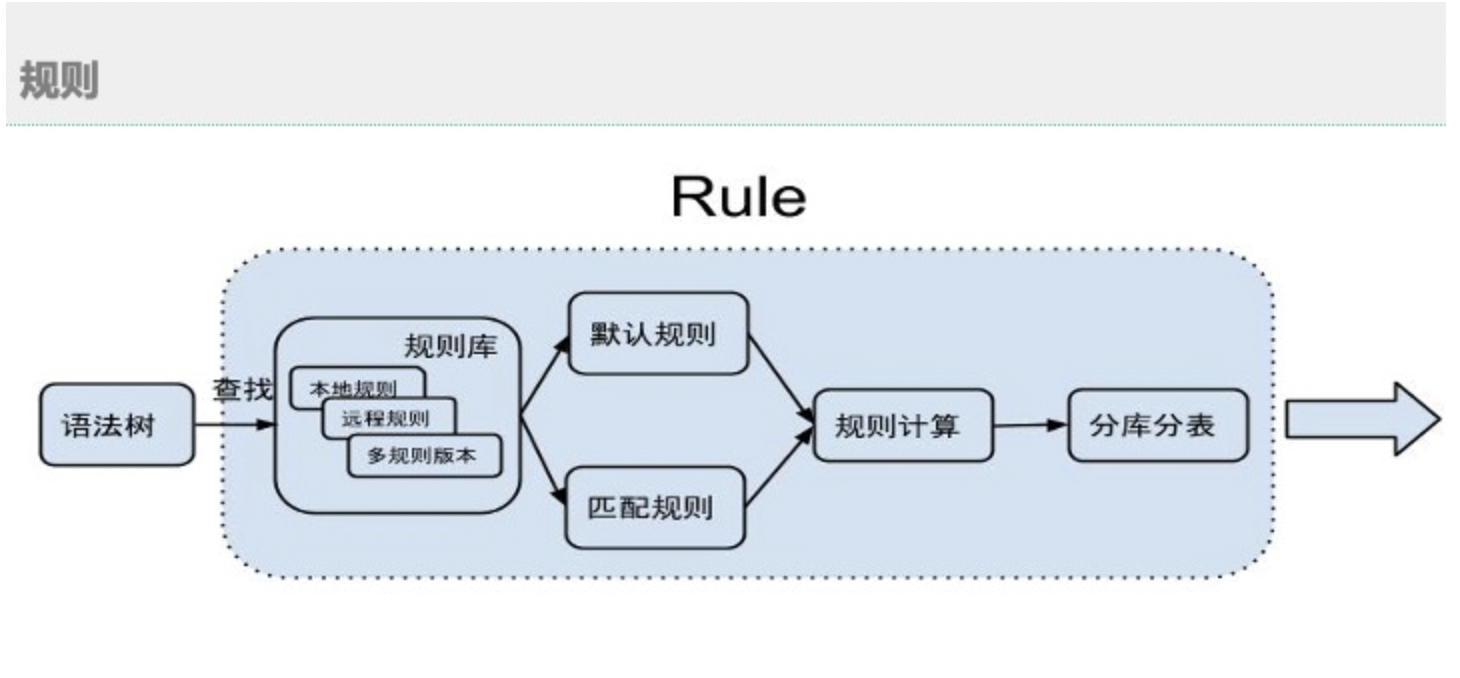
支持自己定义本地定义规则,里面有一些默认的路由规则,来支持tddl的分库分表的插入和查询,默认规则定义在Dimond。根据规则计算进行分库分表

规则语法如上图:最前面是拆分字段,后面的1是步长,1024是枚举多少次,代码是如果有1024个分区会从第一个分区开始枚举步长为1的枚举1024次,一般默认不开启,需要配置开启
正在上传…重新上传取消上面表达式,第一个是配置数据库,第二个是配置数据库表,第三个是允不允许没有拆分字段时是否开启全表扫描,默认不开启。上面的步长和枚举次数就是配置的这个。

- 根据时间进行分区时一般分的都是表,而不是库
- 在分库分表时可以用同一个字段进行分库也进行分表
- 如果查询时没有填写拆分字段,就会进行全表扫描,根据步长进行枚举

- 根据多个字段进行拆分时,如果条件只有其中一个拆分条件会对这个拆分条件下所有分库进行查询
- 如果是between and语句也会根据步长进行查询
查询优化

主要作用是将SQL下推到MySQL去执行,从而避免tddl进行操作。
- join:
-
- 会查看join连接查询的是不是同一个库,如果是同一个库会直接下推到MySQL
- 可以做一个广播表,广播表就是将另一个库内容拷贝在本库中,进行下推执行SQL
- 如果不能下推就在tddl进行操作
- order by:
-
- 会将语句先优化再下推到MySQL,最后进行合并处理
- merge:
-
- 使用union进行语句合并优化
并行优化

可以在不同库中让他们并行执行,提高执行效率
最佳实践

- 尽量在查询时带上拆分条件
- tddl不支持分布式事务
- 尽量避免聚合和排序冲突,造成创建临时表
全局ID
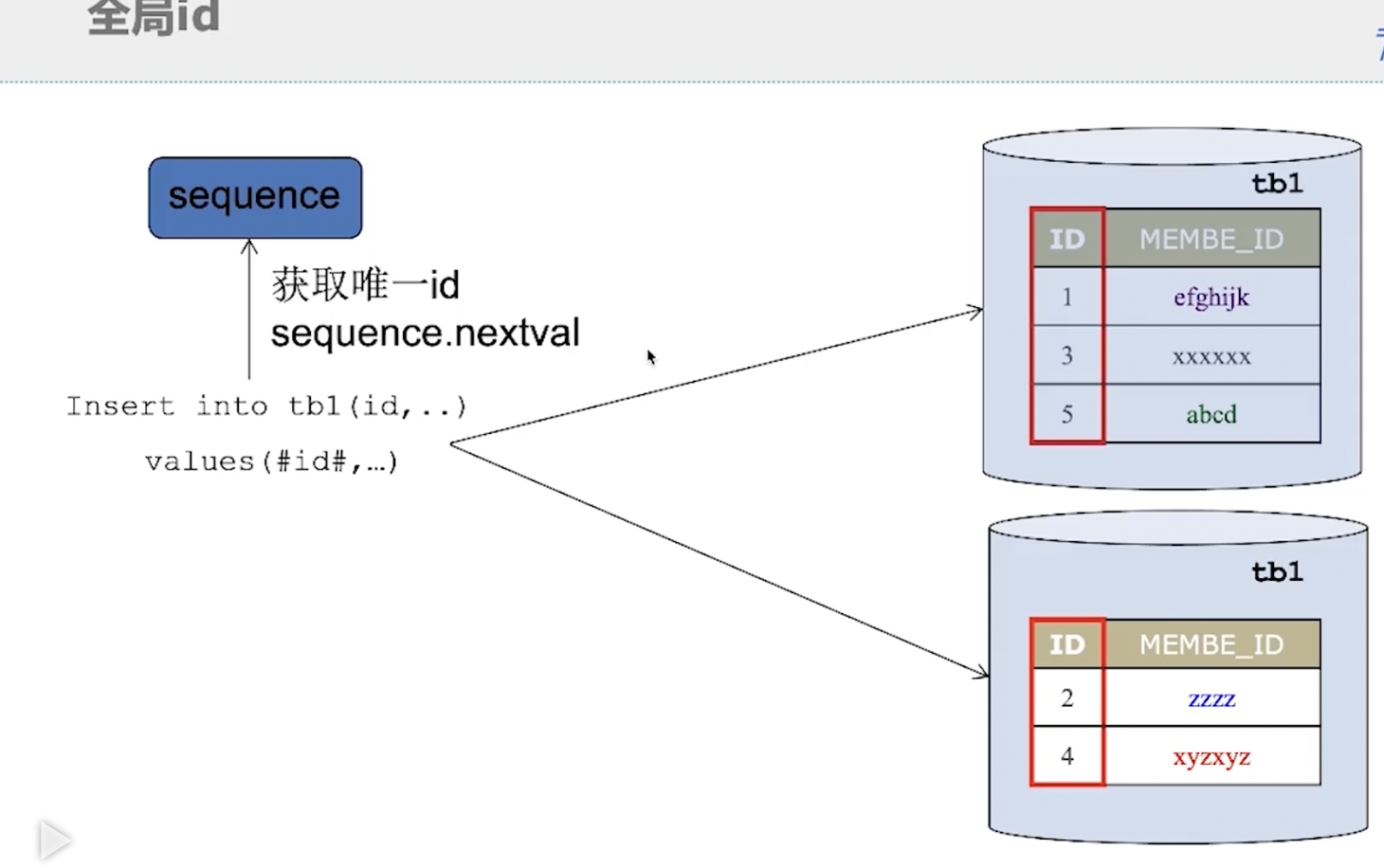
在单库单表MySQL服务中,都是在添加数据时使用自增ID的方式,方便b+树排序,但是如果分布式存储分库分表也这样就会造成重复的主键,所以这里使用的是tddl的sequence服务生成全局唯一主键,sequence服务可以隐式生成也可以显示生成,隐式生成就是不填主键的时候自动生成全局唯一主键,如果想使用显示服务,就要调用sequence服务的api,不会生成重复ID。
sequence如何解决主键递增重复问题

sequence是单独存在的一张表,在单机服务中根据数据库名字从value里面取一个范围到内存中,例如上图中tb2表先取1000个数到内存中,而sequence数据库value就是从0开始主键递增到1000,当1000个主键全用完之后,sequence数据库value做一个更新,再在内存中从1000开始自增1000个数来保证主键唯一。
在分库分表时,每一个分库都有sequence表,每个分库的sequence的value取值分段都不一样,一个举个例子:可以前1000个数分在分库1中,1000-2000到分库2中,这样就会解决递增主键重复问题。
-
相关阅读:
最短路问题之Dijkstra算法 洛谷 单源最短路径
软件测试 -- 自动化测试(Selenium)
python开发面试-20240715
专栏汇总(一)
【附源码】Python计算机毕业设计社区疫情防控监管系统
网上期货开户合约签署流程
npm常用命令
国庆周《Linux学习第二课》
Allegro DFM Ravel Rule 丝印线段到PAD 间距检查
微服务架构整理-(十二、SpringCloud实战之Zuul网关)
- 原文地址:https://blog.csdn.net/m566666/article/details/126887230