代码包来源: https://github.com/iarai/Landslide4Sense-2022、https://www.iarai.ac.at/landslide4sense/challenge/代码包路径: E:\Downloads\20220916-Landslide4Sense-2022-main\Landslide4Sense-2022-main(已传至百度网盘) 或 E:\Downloads\Landslide4Sense-2022-main (2)\Landslide4Sense-2022-main自用电脑运行环境: 使用自建的Python 3.8虚拟环境,位于D:\software\anaconda3\envs\LandSlide_Detection_Faster-RCNN-main;常规Anaconda3 Python 3.9环境可能配置存在些许问题,运行代码报错 “Torch not compiled with CUDA enabled”,故未用
图 1 Python 3.8虚拟环境设置
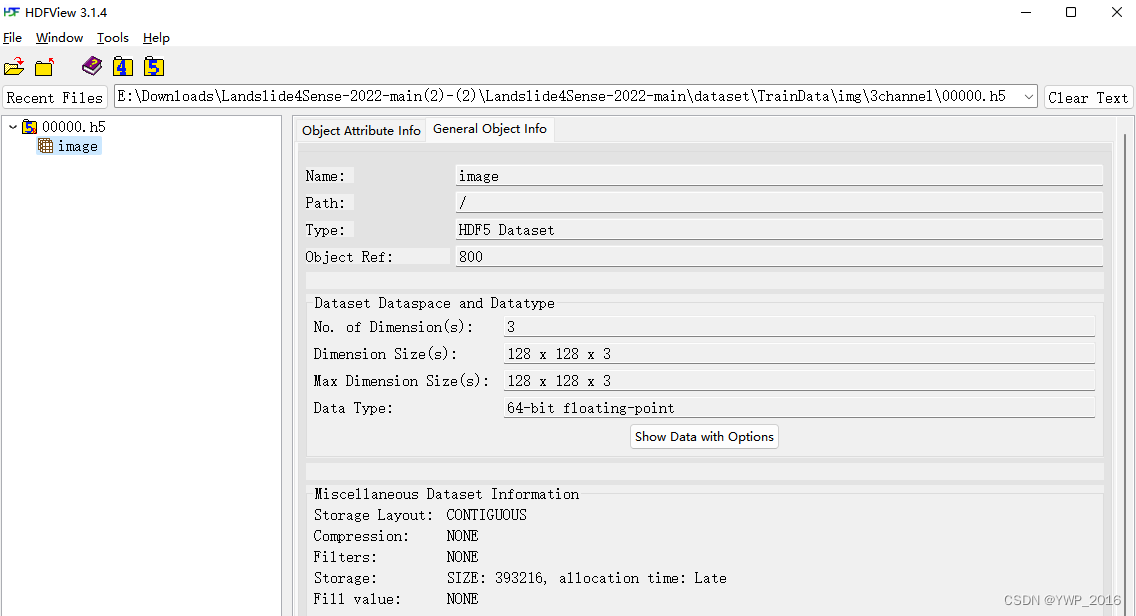
dataset 数据情况: image_1.h5(128×128×14),其中,训练集有mask标注(mask_1.h5,128×128×2)。源代码Train.py的test_list路径指向训练数据集。查看h5文件:h5_visualization.py读取解压h5文件为图片(https://blog.csdn.net/qq_39909808/article/details/125047516),image_1.h5转为image_1.nii.gz后打开,如下图
图 2 模型自带h5数据一览
file_path = r"E:\Downloads\Landslide4Sense-2022-main(2)-(2)\Landslide4Sense-2022-main\dataset\TrainData\mask\20220915mask"
raw_files = os.walk(file_path)
save_path = r"E:\Downloads\Landslide4Sense-2022-main(2)-(2)\Landslide4Sense-2022-main\dataset\TrainData\mask\20220915mask\resize"
if not os.path.exists(save_path):
for root, dirs, files in raw_files:
picture_path = os.path.join(root, file)
pic_org = Image.open (picture_path)
pic_new = pic_org.resize((width, height), Image.ANTIALIAS)
_, sub_folder = os.path.split(root)
pic_new_path = os.path.join(save_path, sub_folder)
if not os.path.exists(pic_new_path):
os.makedirs(pic_new_path)
pic_new_path = os.path.join(pic_new_path, file)
pic_new.save(pic_new_path)
print ("%s have been resized!" %pic_new_path)
使用自己的图片建模,可按如下操作将图片转为.h5文件 (原繁琐操作:先由代码得到group形式的.h5文件,可通过HDFView将其单独保存);再套用Landslide4Sense代码from skimage.transform import resize as imresize
content_image = imageio.imread(r'E:\Downloads\Landslide4Sense-2022-main(2)-(2)\Landslide4Sense-2022-main\dataset\TrainData\img\20220915img\resize\20220915img/df021.png' )
image = imresize(content_image, [128 ,128 ,3 ])
archive = h5py.File(r'E:\Downloads\Landslide4Sense-2022-main(2)-(2)\Landslide4Sense-2022-main\dataset\TrainData\img\20220915img\resize\20220915img/20.h5' , 'w' )
archive.create_dataset('img' , data=image)
图 3 转换后的h5示例
import torch.optim as optim
from torch.utils import data
import torch.backends.cudnn as cudnn
from utils.tools import *
from dataset.landslide_dataset import LandslideDataSet
name_classes = ['Non-Landslide' ,'Landslide' ]
def importName (modulename, name ):
""" Import a named object from a module in the context of this function.
module = __import__ (modulename, globals (), locals ( ), [name])
return vars (module)[name]
parser = argparse.ArgumentParser(description="Baseline method for Land4Seen" )
parser.add_argument("--data_dir" , type =str , default='E:\Downloads/20220916-Landslide4Sense-2022-main\Landslide4Sense-2022-main\dataset/' ,
parser.add_argument("--model_module" , type =str , default='model.Networks' ,
help ='model module to import' )
parser.add_argument("--model_name" , type =str , default='unet' ,
help ='modle name in given module' )
parser.add_argument("--train_list" , type =str , default='./dataset/train.txt' ,
help ="training list file." )
parser.add_argument("--test_list" , type =str , default='./dataset/train.txt' ,
parser.add_argument("--input_size" , type =str , default='128,128' ,
help ="width and height of input images." )
parser.add_argument("--num_classes" , type =int , default=2 ,
help ="number of classes." )
parser.add_argument("--batch_size" , type =int , default=32 ,
help ="number of images in each batch." )
parser.add_argument("--num_workers" , type =int , default=4 ,
help ="number of workers for multithread dataloading." )
parser.add_argument("--learning_rate" , type =float , default=1e-3 ,
parser.add_argument("--num_steps" , type =int , default=10 ,
help ="number of training steps." )
parser.add_argument("--num_steps_stop" , type =int , default=10 ,
help ="number of training steps for early stopping." )
parser.add_argument("--weight_decay" , type =float , default=5e-4 ,
help ="regularisation parameter for L2-loss." )
parser.add_argument("--gpu_id" , type =int , default=0 ,
help ="gpu id in the training." )
parser.add_argument("--snapshot_dir" , type =str , default='./exp/' ,
help ="where to save snapshots of the model." )
return parser.parse_args()
os.environ["CUDA_VISIBLE_DEVICES" ] = str (args.gpu_id)
snapshot_dir = args.snapshot_dir
if os.path.exists(snapshot_dir)==False :
os.makedirs(snapshot_dir)
w, h = map (int , args.input_size.split(',' ))
model_import = importName(args.model_module, args.model_name)
model = model_import(n_classes=args.num_classes)
src_loader = data.DataLoader(
LandslideDataSet(args.data_dir, args.train_list, max_iters=args.num_steps_stop*args.batch_size,set ='labeled' ),
batch_size=args.batch_size, shuffle=True , num_workers=args.num_workers, pin_memory=True )
test_loader = data.DataLoader(
LandslideDataSet(args.data_dir, args.train_list,set ='labeled' ),
batch_size=1 , shuffle=False , num_workers=args.num_workers, pin_memory=True )
optimizer = optim.Adam(model.parameters(),
lr=args.learning_rate, weight_decay=args.weight_decay)
interp = nn.Upsample(size=(input_size[1 ], input_size[0 ]), mode='bilinear' )
hist = np.zeros((args.num_steps_stop,3 ))
cross_entropy_loss = nn.CrossEntropyLoss(ignore_index=255 )
for batch_id, src_data in enumerate (src_loader):
if batch_id==args.num_steps_stop:
images, labels, _, _ = src_data
pred_interp = interp(pred)
labels = labels.cuda().long()
cross_entropy_loss_value = cross_entropy_loss(pred_interp, labels)
_, predict_labels = torch.max (pred_interp, 1 )
predict_labels = predict_labels.detach().cpu().numpy()
labels = labels.cpu().numpy()
batch_oa = np.sum (predict_labels==labels)*1. /len (labels.reshape(-1 ))
hist[batch_id,0 ] = cross_entropy_loss_value.item()
hist[batch_id,1 ] = batch_oa
cross_entropy_loss_value.backward()
hist[batch_id,-1 ] = time.time() - tem_time
if (batch_id+1 ) % 1 == 0 :
print ('Iter %d/%d Time: %.2f Batch_OA = %.1f cross_entropy_loss = %.3f' %(batch_id+1 ,args.num_steps,10 *np.mean(hist[batch_id-9 :batch_id+1 ,-1 ]),np.mean(hist[batch_id-9 :batch_id+1 ,1 ])*100 ,np.mean(hist[batch_id-9 :batch_id+1 ,0 ])))
if (batch_id+1 ) % 1 == 0 :
print ('Testing..........' )
TP_all = np.zeros((args.num_classes, 1 ))
FP_all = np.zeros((args.num_classes, 1 ))
TN_all = np.zeros((args.num_classes, 1 ))
FN_all = np.zeros((args.num_classes, 1 ))
F1 = np.zeros((args.num_classes, 1 ))
for _, batch in enumerate (test_loader):
image, label,_, name = batch
label = label.squeeze().numpy()
image = image.float ().cuda()
_,pred = torch.max (interp(nn.functional.softmax(pred,dim=1 )).detach(), 1 )
pred = pred.squeeze().data.cpu().numpy()
TP,FP,TN,FN,n_valid_sample = eval_image(pred.reshape(-1 ),label.reshape(-1 ),args.num_classes)
n_valid_sample_all += n_valid_sample
OA = np.sum (TP_all)*1.0 / n_valid_sample_all
for i in range (args.num_classes):
P = TP_all[i]*1.0 / (TP_all[i] + FP_all[i] + epsilon)
R = TP_all[i]*1.0 / (TP_all[i] + FN_all[i] + epsilon)
F1[i] = 2.0 *P*R / (P + R + epsilon)
print ('===>' + name_classes[i] + ' Precision: %.2f' %(P * 100 ))
print ('===>' + name_classes[i] + ' Recall: %.2f' %(R * 100 ))
print ('===>' + name_classes[i] + ' F1: %.2f' %(F1[i] * 100 ))
print ('===> mean F1: %.2f OA: %.2f' %(mF1*100 ,OA*100 ))
model_name = 'batch' +repr (batch_id+1 )+'_F1_' +repr (int (F1[1 ]*10000 ))+'.pth'
torch.save(model.state_dict(), os.path.join(
snapshot_dir, model_name))
if __name__ == '__main__' :
from torch.utils import data
from torch.utils.data import DataLoader
class LandslideDataSet (data.Dataset):
def __init__ (self, data_dir, list_path, max_iters=None ,set ='label' ):
self.list_path = list_path
self.mean = [-0.4914 , -0.3074 , -0.1277 , -0.0625 , 0.0439 , 0.0803 , 0.0644 , 0.0802 , 0.3000 , 0.4082 , 0.0823 , 0.0516 , 0.3338 , 0.7819 ]
self.std = [0.9325 , 0.8775 , 0.8860 , 0.8869 , 0.8857 , 0.8418 , 0.8354 , 0.8491 , 0.9061 , 1.6072 , 0.8848 , 0.9232 , 0.9018 , 1.2913 ]
self.img_ids = [i_id.strip() for i_id in open (list_path)]
n_repeat = int (np.ceil(max_iters / len (self.img_ids)))
self.img_ids = self.img_ids * n_repeat + self.img_ids[:max_iters-n_repeat*len (self.img_ids)]
for name in self.img_ids:
img_file = data_dir + name
label_file = data_dir + name.replace('img' ,'mask' ).replace('image' ,'mask' )
for name in self.img_ids:
img_file = data_dir + name
def __getitem__ (self, index ):
datafiles = self.files[index]
with h5py.File(datafiles['img' ], 'r' ) as hf:
with h5py.File(datafiles['label' ], 'r' ) as hf:
image = np.asarray(image, np.float32)
label = np.asarray(label, np.float32)
image = image.transpose((-1 , 0 , 1 ))
for i in range (len (self.mean)):
image[i,:,:] -= self.mean[i]
image[i,:,:] /= self.std[i]
return image.copy(), label.copy(), np.array(size), name
with h5py.File(datafiles['img' ], 'r' ) as hf:
image = np.asarray(image, np.float32)
image = image.transpose((-1 , 0 , 1 ))
for i in range (len (self.mean)):
image[i,:,:] -= self.mean[i]
image[i,:,:] /= self.std[i]
return image.copy(), np.array(size), name
if __name__ == '__main__' :
train_dataset = LandslideDataSet(data_dir='/dataset/' , list_path='./train.txt' )
train_loader = DataLoader(dataset=train_dataset,batch_size=1 ,shuffle=True ,pin_memory=True )
channels_sum,channel_squared_sum = 0 ,0
num_batches = len (train_loader)
for data,_,_,_ in train_loader:
channels_sum += torch.mean(data,dim=[0 ,2 ,3 ])
channel_squared_sum += torch.mean(data**2 ,dim=[0 ,2 ,3 ])
mean = channels_sum/num_batches
std = (channel_squared_sum/num_batches - mean**2 )**0.5
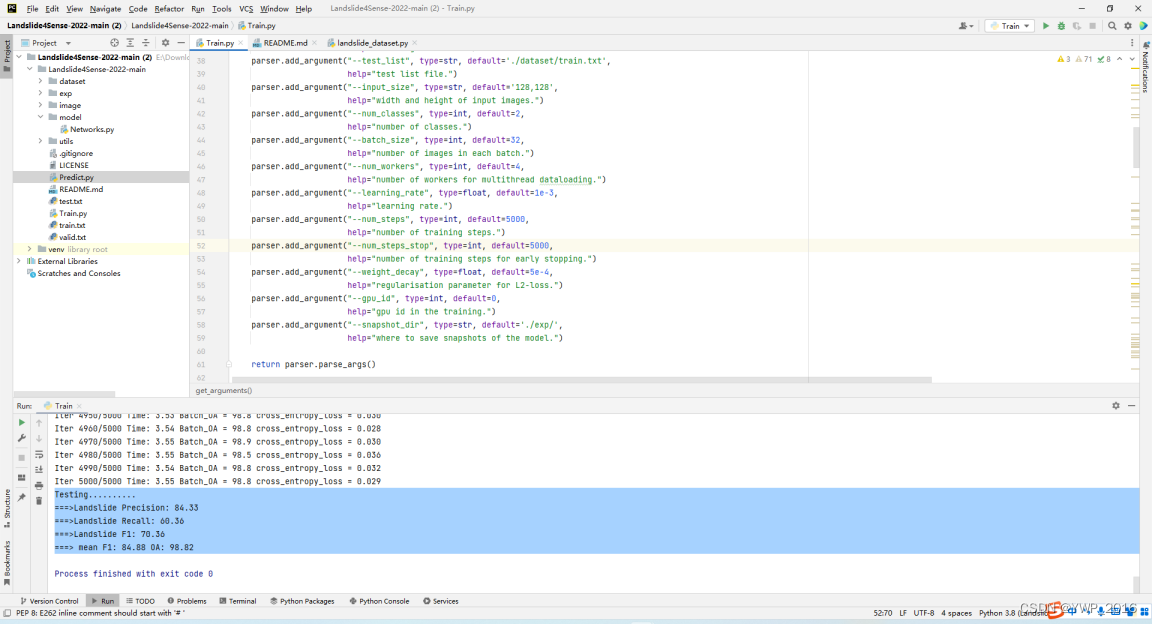
迭代5000次后,Precision: 84.33, Recall: 60.36, F1: 70.36
图 4 模型自带数据训练结果
其他网络: Semantic-segmentation-methods-for-landslide-detection-master(https://github.com/waterybye/Semantic-segmentation-methods-for-landslide-detection)内含多种网络代码,将其扩充至当前Landslide4Sense-2022-main代码包下的model,即可训练DeepLabV3+ 、 FCN 或 GCN 网络,对应Train.py修改如下:parser.add_argument("--model_module" , type =str , default='model.deeplab3plus' ,
help ='model module to import' )
parser.add_argument("--model_name" , type =str , default='DeepLabv3_plus' ,
help ='modle name in given module' )
注意:训练DeepLabV3plus网络,图片需以128×128×3 三通道输入(对应上述转.h文件代码中的“image = imresize(content_image, [128,128])”);另外,还需修改channels、batch_size等参数(例如,设置迭代100次、batch_size为5),多加尝试对比 注意:为对应Train.py中的“model = model_import(n_classes=args.num_classes)”,需要将具体网络代码“num_classes”修改为“n_classes”
DeepLabv3+ 输入128×128×3 .h5图像, Train.py 进行如下关键修改(同上代码段) 注意:可能报错“CUDA out of memory” → 调整batch_size即可 parser.add_argument("--data_dir" , type =str , default='E:\Downloads/20220916-Landslide4Sense-2022-main\Landslide4Sense-2022-main\dataset/' ,
parser.add_argument("--model_module" , type =str , default='model.deeplab3plus' ,
help ='model module to import' )
parser.add_argument("--model_name" , type =str , default='DeepLabv3_plus' ,
help ='modle name in given module' )
parser.add_argument("--train_list" , type =str , default='./dataset/train_other.txt' ,
help ="training list file." )
parser.add_argument("--test_list" , type =str , default='./dataset/train_other.txt' ,
landslide_dataset.py 进行如下修改 self.mean = [-0.4914 , -0.3074 , -0.1277 ]
self.std = [0.9325 , 0.8775 , 0.8860 ]
if __name__ == '__main__' :
train_dataset = LandslideDataSet(data_dir='/dataset/' , list_path='./train_other.txt' )
FCN(8s/16s/32s)类同上述修改,只是在Train.py的相应模型设置不同,如下 parser.add_argument("--model_module" , type =str , default='model.fcn' ,
help ='model module to import' )
parser.add_argument("--model_name" , type =str , default='fcn8s' ,
help ='modle name in given module' )
GCN类同上述修改,只是在Train.py的相应模型设置不同,如下 parser.add_argument("--model_module" , type =str , default='model.gcn' ,
help ='model module to import' )
parser.add_argument("--model_name" , type =str , default='GCN' ,
help ='modle name in given module' )
Predict.py 预测: Predict.py在调用模型权重文件时报错“RecursionError: maximum recursion depth exceeded while calling a Python object”或“Process finished with exit code -1073741571 (0xC00000FD)”,故直接将Predict.py相关代码附在Train.py →→→ 输出对应mask,位于文件夹…\exp