-
【机器学习】树模型预剪枝和后剪枝
在树模型建模的过程中的树模型的超参数会影响模型的精度,那么如何调整超参数呢?可以提前限制模型的超参数,也可以在训练模型之后再调整。本文将介绍树模型的预剪枝和后剪枝的实践过程。
原始模型
使用基础数据集和基础的树模型进行训练,然后查看树模型在训练集和测试集的精度:
df = pd.read_csv('https://mirror.coggle.club/dataset/heart.csv') X = df.drop(columns=['output']) y = df['output'] x_train,x_test,y_train,y_test = train_test_split(X,y,stratify=y) clf = tree.DecisionTreeClassifier(random_state=0) clf.fit(x_train,y_train)- 1
- 2
- 3
- 4
- 5
- 6
- 7
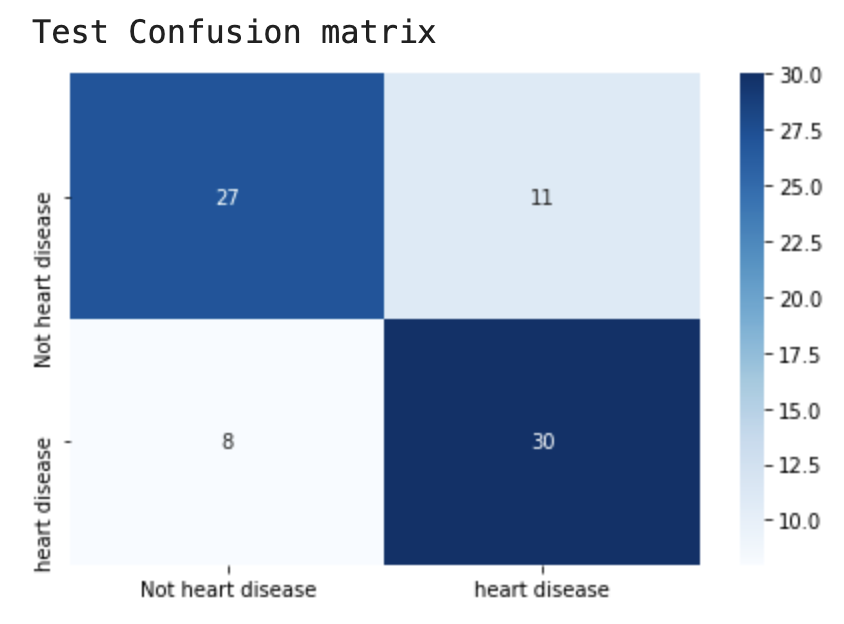
模型在训练集上准确率100%,但在测试集上存在19个错误样本。

预剪枝
预剪枝就是在构造决策树的过程中,先对每个结点在划分前进行估计,如果当前结点的划分不能带来决策树模型泛化性能的提升,则不对当前结点进行划分并且将当前结点标记为叶结点。
停止决策树生长最简单的方法有:
-
限制树模型最大深度;
-
限制树模型叶子节点最小样本数量;
-
使用信息增益限制节点;
可以调节的对应超参数为:
-
max_depth
-
min_sample_split
-
min_samples_leaf
params = {'max_depth': [2,4,6,8,10,12], 'min_samples_split': [2,3,4], 'min_samples_leaf': [1,2]} clf = tree.DecisionTreeClassifier() gcv = GridSearchCV(estimator=clf,param_grid=params) gcv.fit(x_train,y_train) model = gcv.best_estimator_ model.fit(x_train,y_train)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
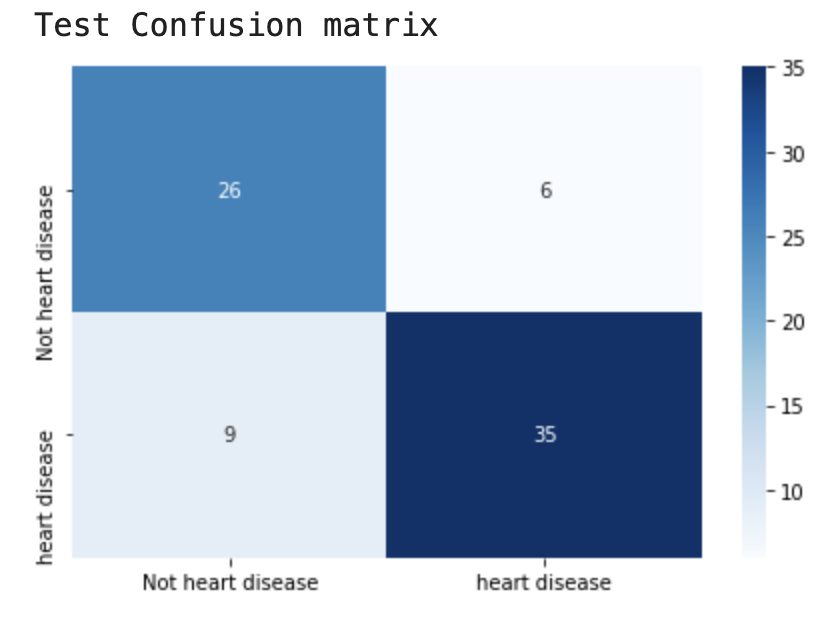
模型在训练集上有30个错误样本,但在测试集上只存在15个错误样本。
后剪枝
使用后剪枝方法需要将数据集分为测试集和训练集。用测试集来判断将这些叶节点合并是否能降低测试误差,如果是的话将合并。
-
Reduced-Error Pruning(REP)
-
Pesimistic-Error Pruning(PEP)
-
Cost-Complexity Pruning(CCP)
CCP对应的超参数为 alpha,我们将获得这棵树的 alpha 值。首先计算可选的alpha,并计算对应的模型的精度。
path = clf.cost_complexity_pruning_path(x_train, y_train) ccp_alphas, impurities = path.ccp_alphas, path.impurities clfs = [] for ccp_alpha in ccp_alphas: clf = tree.DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha) clf.fit(x_train, y_train) clfs.append(clf) train_acc = [] test_acc = [] for c in clfs: y_train_pred = c.predict(x_train) y_test_pred = c.predict(x_test) train_acc.append(accuracy_score(y_train_pred,y_train)) test_acc.append(accuracy_score(y_test_pred,y_test)) plt.scatter(ccp_alphas,train_acc) plt.scatter(ccp_alphas,test_acc)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
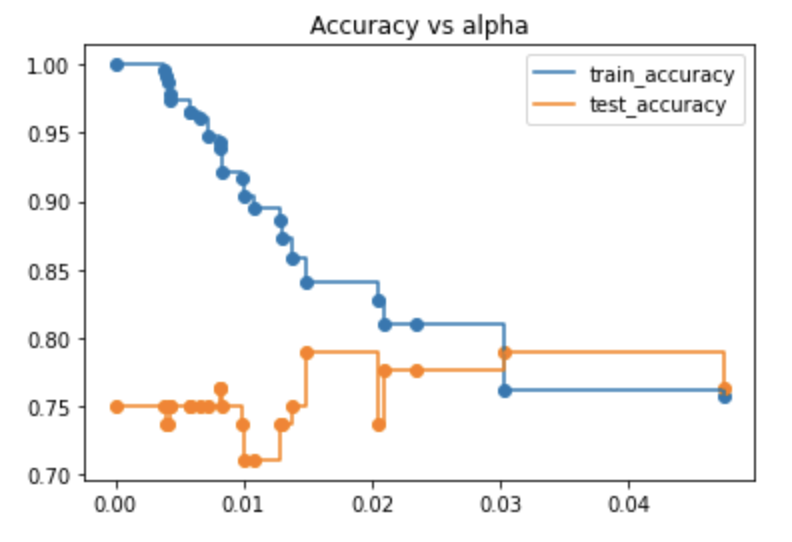
从结果可知如果alpha设置为0.2得到的测试集精度最好,我们将从新训练模型:
clf_ = tree.DecisionTreeClassifier(random_state=0,ccp_alpha=0.020) clf_.fit(x_train,y_train)- 1
- 2
模型在训练集上有36个错误样本,但在测试集上只存在16个错误样本。


推荐文章
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

-
相关阅读:
Activiti7学习笔记
微信小程序入门---超详细教程
前端工程师面试题详解(二)
Bytebase 2.20.0 - 支持为工单事件配置飞书个人通知
Kubernetes Operator
PHP利用phpmailer实现邮件发送功能
如何将 SonarQube和 SonarScanner 扫描vue项目bug?
1.4、栈
旋转变压器软件解码simulink仿真
6、Linux驱动开发:设备-更简单的设备注册
- 原文地址:https://blog.csdn.net/weixin_38037405/article/details/126869515
