-
第9章 Spring Boot整合JPA 与 JpaRepository 基础方法介绍
参考文章:
第1章 Spring Boot到底是什么?_陈小房的博客-CSDN博客
第2章 第一个Spring Boot项目_陈小房的博客-CSDN博客
第3章 Spring Boot项目配置详解_陈小房的博客-CSDN博客
第4章 Spring Boot的Web应用开发入门_陈小房的博客-CSDN博客
第5章 Spring Boot模板Thymeleaf入门详解_陈小房的博客-CSDN博客
第6章 MyBatis框架入门详解(1)_陈小房的博客-CSDN博客
1. 什么是JPA
JPA(Java Persistence API, Java 持久化API)是SUN公司提出的Java持久化规范,它提供了一种对象/关系映射的管理工具来管理Java中的关系型数据库。JPA的主要目的是简化现有的持久化开发工作并且整合ORM框架,JPA本身并不是ORM框架,它是一种规范,这种规范可以私下通过注解或者XML描述“对象-关系表”之间的映射关系,并将实体对象持久化到数据库中,从而极大地简化现有的持久化开发工作。
1.1 JPA和MyBatis的关系
实现JPA的框架有Hibernate, TopLink, 而我们前面介绍的MyBatis不属于实现JPA的框架,主要区别有:
- Mybatis是对象和结果集的映射,而JPA规范强调的是对象和关系表之间的映射。
- 遵守JPA规范的框架具有良好的移植性,不用关心用什么数据库,而Mybatis框架在更改数据库时需要修改底层SQL。
2. Spring Data JPA
2.1 配置SpringData JPA
Spring Data 是Spring 的一个子项目, 旨在统一和简化对各类型持久化存储, 而不拘泥于是关系型数据库还是NoSQL 数据存储。
Spring Data JPA是Spring Data项目的一部分,它是在ORM框架思想、JPA规范的基础上封装的一套JPA应用框架。使用Spring Data JPA只需要继承和扩展Spring Data 中统一的数据访问接口Repository接口无需编写SQL实现数据库访问。
在pom.xml文件中添加spring-boot-starter-data-jpa依赖
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-starter-data-jpaartifactId>
- dependency>
在数据库中新建一个schema用于JPA测试
然后在application.properties文件中进行相关配置
- spring.datasource.url=jdbc:mysql://localhost:3306/jpa_demo?useSSL=true&useUnicode=true&characterEncoding=UTF-8
- spring.datasource.username=root
- spring.datasource.password=itJMF-4RObQ2
- spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
- #JPA 配置
- spring.jpa.hibernate.ddl-auto=update
- #spring.jpa.hibernate.ddl-auto=create
- spring.jpa.show-sql=true
- spring.jpa.properties.hibernate.format_sql=true
这里对JPA配置进行简单说明
spring.jpa.hibernate.ddl-auto
该配置比较常用,配置实体类维护数据库表结构的具体行为。它主要有4个选项
- create: 启动时删数据库中的表,然后创建新表,退出时不删除数据表
- create-drop: 启动时删数据库中的表,然后创建,退出时删除数据表 如果表不存在则报错
- update: 如果启动时表格式不一致则更新表,原有数据保留
- validate: 项目启动表结构进行校验 如果不一致则报错”
这里我们选择了update
spring.jpa.show-sql=true 操作时在控制台打印真实的SQL语句,便于调试
spring.jpa.properties.hibernate.format_sql=true 以JSON格式打印输出SQL语句方便查看
3. 验证Spring Data JPA
首先,创建Scenic实体类,它是一个实体类,按照JPA的设计思想,这个实体类也是定义数据库中的表结构的类,示例代码如下
- @Entity
- @Table(name = "scenics")
- public class Scenic {
- @GeneratedValue(strategy = GenerationType.IDENTITY)
- @Id
- private int scenicId;
- private int cityId;
- //@Column(name = "scenicName")
- @Column(length = 64)
- private String scenicName;
- private int price;
- public Scenic() {
- }
- public Scenic(Integer cityId, String scenicName, int price ){
- this.cityId = cityId;
- this.scenicName = scenicName;
- this.price = price;
- }
- public int getScenicId() {
- return scenicId;
- }
- public void setScenicId(int scenicId) {
- this.scenicId = scenicId;
- }
- public int getCityId() {
- return cityId;
- }
- public void setCityId(int cityId) {
- this.cityId = cityId;
- }
- public String getScenicName() {
- return scenicName;
- }
- public void setScenicName(String scenicName) {
- this.scenicName = scenicName;
- }
- public int getPrice() {
- return price;
- }
- public void setPrice(int price) {
- this.price = price;
- }
- }
注意这个实体类中使用了JPA相关的注解
@Entity 这个注解是使用JPA时必须的注解,代表这个类对应了一个数据库表
@Table 这是一个可选的注解,用于说明数据库实体对应的表信息,包括表的名称、索引信息等,如果没有则表名和实体类的名称一致,一般情况下我们不使用该注解,这里为了演示,我们使用该注解将表名申明为Scenics
@Id 代表对应的主键
@GeneratedValue 设置数据库主键自动生成规则。strategy属性提供4种选项
AUTO:主键由程序控制,是默认选项。
IDENTITY:主键由数据库自动生成,即采用数据库ID自增长的方式,注意Oracle不支持这种方式。
SEQUENCE:通过数据库的序列产生主键,通过@SequenceGenerator注解指定序列名,注意MySQL不支持这种方式。
TABLE:通过特定的数据库表产生主键,使用该策略可以使应用更易于数据库移植。
@Column注解:声明实体属性的表字段的定义。默认的实体每个属性都对应表的一个字段,字段名默认与属性名保持一致。字段的类型根据实体属性类型自动对应。这里主要声明了字符字段的长度length,如果不声明,则系统会采用255作为该字段的长度。
这里需要注意JPA自动建表的字段命名规则采用的是下划线,如属性scenicName会将生成数据库字段scenic_name,如果需要生成非下划线字段,可以采用@Column(name = "ScenicName")
运行测试
运行Spring boot应用,控制台输出
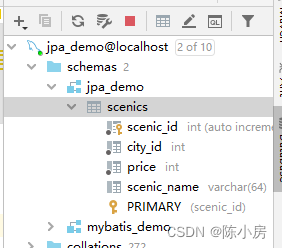
查看数据库,可以看到已经自动创建了scenics数据库表
4. JpaRepository类定义
接下来学习如何通过类来操作数据库,在Spring Data JPA中使用JpaRepository接口类完成对数据库的操作。JpaRepository是Spring Data JPA中最重要的类之一。
这是JpaRepository接口的定义
- @NoRepositoryBean
- public interface JpaRepository
可以看出JpaRepository继承了接口PagingAndSortingRepository和QueryByExampleExecutor。而PagingAndSortingRepository又继承CrudRepository。
- @NoRepositoryBean
- public interface PagingAndSortingRepository
所以JpaRepository接口同时拥有了基本CRUD功能以及分页功能。
JpaRepository提供了30多个默认方法,基本能满足项目中的数据库操作功能。当我们需要定义自己的Repository接口的时候,我们可以直接继承JpaRepository,从而获得SpringBoot Data JPA为我们内置的多种基本数据操作方法。
5. JpaRepository基础方法
下面对主要的方法进行测试
在项目目录下新建repository包,添加接口文件ScenicRepository
代码如下
- @Repository
- public interface ScenicRepository extends JpaRepository
- }
在测试用例类Chapter9ApplicationTests中添加测试方法进行测试
5.1 新增数据
save
JPARepository接口提供save方法用于新增数据,它的使用很简单,只要传入需要新增的实体类即可
- @Resource
- private ScenicRepository scenicRepository;
- @Test
- public void testSave() {
- Scenic scenic = new Scenic(1, "scenic1", 10);
- scenicRepository.save(scenic);
- }
执行结果

saveAll
如果需要批量新增则可以使用saveAll方法
- @Test
- public void testSaveAll() {
- List
scenicList = new ArrayList<>(); - scenicList.add(new Scenic(11, "savaAll_11", 100));
- scenicList.add(new Scenic(12, "saveAll_12", 200));
- scenicList.add(new Scenic(13, "saveAll_13", 300));
- scenicRepository.saveAll(scenicList);
- }
执行结果

5. 2 更新数据库方法
更新已有数据库的方法也是save
- @Test
- public void testUpdate() {
- Scenic scenic = scenicRepository.findById(1).get();
- scenic.setScenicName("scenicUpdate");
- scenicRepository.save(scenic);
- }
执行结果
5.3 查找数据
findById
可以根据id查询对应的实体,函数原型如下
- /**
- * 根据id查询对应的实体。
- */
- Optional<T> findById(ID id);
测试代码
- @Test
- public void testFindById() {
- Scenic scenic = scenicRepository.findById(2).get();
- System.out.println(scenic.getScenicName() + ":" + scenic.getScenicId());
- }
执行输出

findAll
查询所有的实体。方法原型
Iterable
findAll(); 测试代码
- @Test
- public void testFindAll() {
- List
scenicList = scenicRepository.findAll(); - for(Scenic scenic: scenicList) {
- System.out.println( scenic.getScenicName()+ ":" + scenic.getScenicId() + ":" + scenic.getPrice());
- }
- }
测试结果

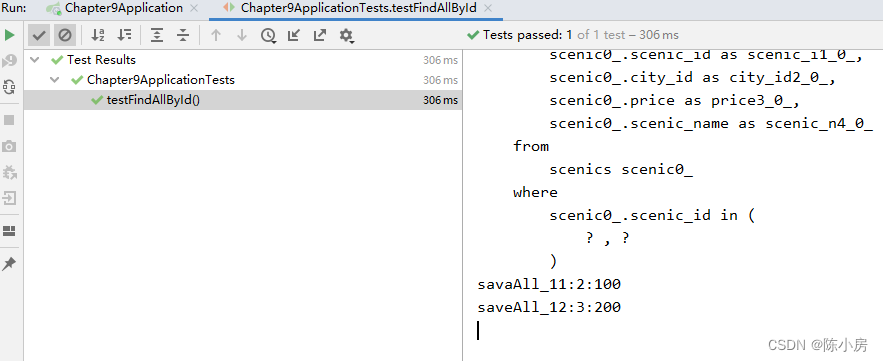
findAllById
如果不想查询全部数据,但是需要根据给定的Id查询部分数据,可以使用findAllById
- @Test
- public void testFindAllById() {
- List
idList = new ArrayList<>(); - idList.add(2);
- idList.add(3);
- List
scenicList = scenicRepository.findAllById(idList); - for (Scenic scenic : scenicList) {
- System.out.println(scenic.getScenicName() + ":" + scenic.getScenicId() + ":" + scenic.getPrice());
- }
- }
测试结果
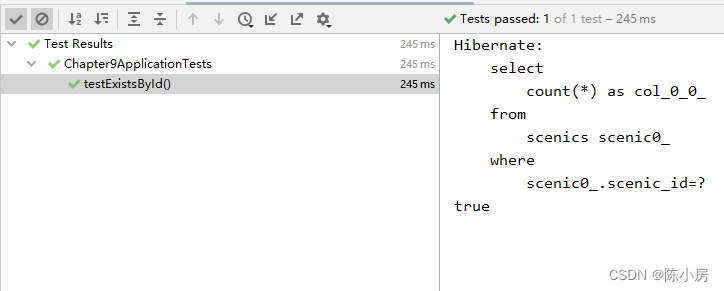
existsById
有时候我们并不想查找数据,而是只想知道数据是否存在与数据库表中,这个时候可以用existsById
boolean existsById(ID id);
测试代码
- @Test
- public void testExistsById() {
- System.out.println(scenicRepository.existsById(1));
- }
测试结果
findAll(Sort sort)
有时候需要对查询到的数据进行排序,此时可以传递一个排序函数。例如我们对secenic查询结果按照price降序排列
- @Test
- public void testFindAllSort() {
- Sort sort = Sort.by(Sort.Direction.DESC, "price");
- List
scenicList = scenicRepository.findAll(sort); - for(Scenic scenic: scenicList) {
- System.out.println( scenic.getScenicName()+ ":" + scenic.getScenicId() + ":" + scenic.getPrice());
- }
- }
执行结果

findAll(Pageable pageable)
返回一页实体,根据Pageable参数提供的规则进行过滤
- @Test
- public void testFindAllPageable() {
- // 分页查询
- // PageRequest.of 的第一个参数表示第几页(注意:第一页从序号0开始),第二个参数表示每页的大小
- // PageRequest of(int page, int size)
- Pageable pageable = PageRequest.of(1, 2);
- Page
page = scenicRepository.findAll(pageable); - System.out.println("总页数:" + page.getTotalPages());
- System.out.println("总记录数:" + page.getTotalElements());
- System.out.println("当前第几页:" + (page.getNumber() + 1));
- System.out.println("当前页面的记录数:" + page.getNumberOfElements());
- }
测试结果

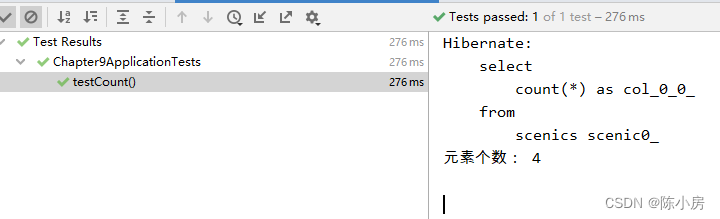
count
和SQL命令一样,用于统计数据元素个数
编写测试代码
- @Test
- public void testCount() {
- Long cnt = scenicRepository.count();
- System.out.println("元素个数: "+cnt);
- }
运行结果
5.4 数据删除
deleteById
根据id删除对应的数据
- @Test
- public void testDeleteById() {
- System.out.println("*************************");
- testFindAll();
- scenicRepository.deleteById(1);
- System.out.println("*************************");
- testFindAll();
- System.out.println("*************************");
- }
删除前
删除后

deleteAll()
deleteAll可以删除对应数据库表中的所有数据
- @Test
- public void testDeleteAll() {
- scenicRepository.deleteAll();
- }
测试结果
此外JPARepository还提供了delete(T entity) deleteAll(Iterable entities)可以根据一个或者多个具体实体删除
-
相关阅读:
LineRenderer屏幕绘制
王道数据结构编程题 链表
go中的map
新手小白剪辑视频知识点:视频分辨率和位深度,有什么区别?
Matlab loglog函数
[架构之路-50]:目标系统 - 系统软件 - Linux下的网络通信-6-PON、EPON、GPON
地级市市场化指数+樊纲市场化指数(包含分省、市两份数据)
02 MIT线性代数-矩阵消元 Elimination with matrices
PATH变量添加
Git 备忘单
- 原文地址:https://blog.csdn.net/qwdzq/article/details/126809651
