-
SQL优化
1.确认是否建立索引,是否索引失效
原则:没有索引考虑加索引,有索引先看索引建立的是否合理以及尽量避免索引失效
1.1.如果不是业务需要查询所有字段,避免直接select*
原因:
完全没有走覆盖索引的可能
有可能索引失效
增加了数据传输的开销
...
1.2.避免在where子句中对有索引的字段进行null值判断
前提:
mysql v5.7
在height上建立了普通索引
现象:
用null值判断,索引失效

不用null值判断,走索引

1.3其他索引失效的情况
2.limit 1优化
limit 1的作用:只返回一条记录,即使有多条也忽略其他只返回第一条。
前提:如果我们已经知道得到的数据永远仅仅只有一条的话,那就可以加上 LIMIT 1,进行优化.
现象:
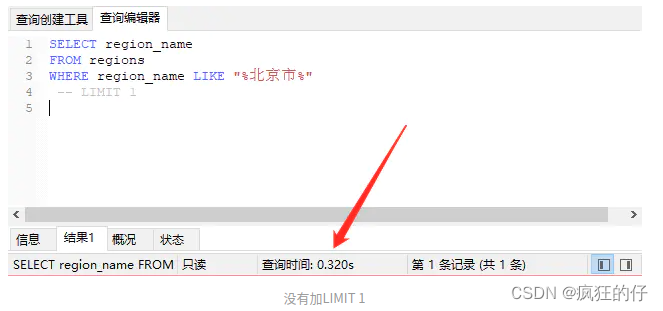
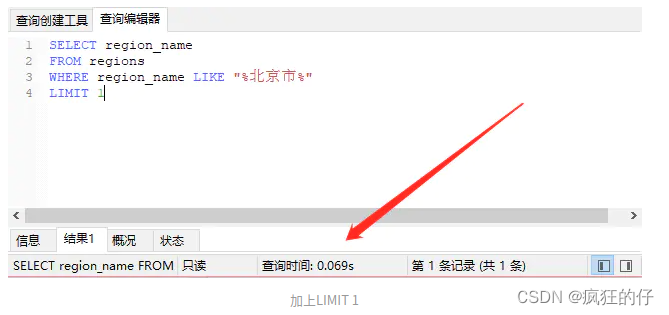
SELECT * FROM regions WHERE region_name LIKE "%北京市%"region_name表中有70万条数据.
没加 limit 1
加 limit 1
原因:
如果没有加 LIMIT 1 的话,数据库会在找到符合条件的记录以后继续向下查询,继续寻找另一个符合条件的记录,直到最后一条数据.如果我们已经知道得到的数据永远仅仅只有一条的话,那就可以加上 LIMIT 1,让数据库找到一条数据之后就立刻返回结果,这样就大大提升了性能!
参考
3.insert 优化
3.1将多条单独的insert语句改为批量一次性插入
- INSERTINTO`insert_table`(`datetime`,`uid`,`content`,`type`)VALUES('0','userid_0','content_0',0);
- INSERTINTO`insert_table`(`datetime`,`uid`,`content`,`type`)VALUES('1','userid_1','content_1',1);
- //修改成:
- INSERTINTO`insert_table`(`datetime`,`uid`,`content`,`type`)VALUES('0','userid_0','content_0',0),
- ('1','userid_1','content_1',1);
原因:
减少SQL语句解析的操作,只需要解析一次就能进行数据的插入操作.
SQL语句较短,可以减少网络传输的IO.
3.2将多条insert语句放到一个事务中,并手动提交
- STARTTRANSACTION;
- INSERTINTO`insert_table`(`datetime`,`uid`,`content`,`type`)VALUES('0','userid_0','content_0',0);
- INSERTINTO`insert_table`(`datetime`,`uid`,`content`,`type`)VALUES('1','userid_1','content_1',1);
- ...
- COMMIT;
原因:
进行一个INSERT操作时,MySQL内部会建立一个事物,在事物内进行真正插入处理,通过使用自动提交事物可以减少创建事物的消耗,所有插入都在执行后才进行提交操作.
参考:http://seo.wordc.cn/contentlp.asp?id=1040
4.update优化
innodb引擎使用update时,会有行锁/表锁两种模式, 如果where 字段没有索引的时候会升级成表锁.
- update table set xx=1 where name=xx (name没有索引,此时是表锁)
- update table set xx=1 where id=xx (id有索引,此时是行锁)
5.count 优化
前提:
COUNT(字段)、COUNT(常量)和COUNT(*)之间的区别:
-
COUNT(常量) 和 COUNT(*) 表示的是直接查询符合条件的数据库表的行数。
-
COUNT(列名)表示的是查询符合条件的列的值不为NULL的行数。
相较与COUNT(常量) ,平时更推荐使用COUNT(*),因为mysql对其做了很多优化.根据存储引擎不同,优化方式不同,比如:
MyISAM
因为MyISAM的锁是表级锁,所以同一张表上面的操作需要串行进行,所以,MyISAM 做了一个简单的优化,那就是它可以把表的总行数单独记录下来,如果从一张表中使用 COUNT(*) 进行查询的时候,可以直接返回这个记录下来的数值就可以了,当然,前提是不能有 where 条件。MyISAM 之所以可以把表中的总行数记录下来供 COUNT(*) 查询使用,那是因为 MyISAM 数据库是表级锁,不会有并发的数据库行数修改,所以查询得到的行数是准确的.
InnoDB
COUNT(*)的目的只是为了统计总行数,所以,他根本不关心自己查到的具体值,所以,他如果能够在扫表的过程中,选择一个成本较低的索引进行的话,那就可以大大节省时间。一般有二级索引就优先选择二级索引,而不是主键索引.
三者执行速度比较
count(*)>count(1)>count(字段)
count(*)>count(1)前面已经分析了,但count(字段)为什么最慢.因count(字段)遍历字段值的时候,需要取值进行判断是否为null,而count(*)和count(1)不需要关心每一行数据是否有null值或全为null值.
6.增加硬件配置
加内存,加硬盘,加CPU等等
-
相关阅读:
CentOS断电丢失数据修复问题
视频融合平台EasyCVR接入大华SDK时无法接入设备通道该如何解决?
使用mindspore将pkl文件转为onnx时报错
css justify-content Test210428
Elasticsearch的分析与分析器
Springboot2 D2- 运维实用篇
Linux 三剑客grep sed 与 awk
SQL使用大全
【Java】解决Java报错:IllegalArgumentException
【猿灰灰赠书活动 - 04期】- 【分布式统一大数据虚拟文件系统——Alluxio原理、技术与实践】
- 原文地址:https://blog.csdn.net/DYYssb/article/details/126814288