采集网站
【场景描述】采集谷歌浏览器关键词搜索出的网页列表数据。
【源网站介绍】谷歌一家位于美国的跨国科技企业,被公认为全球最大的搜索引擎公司,业务包括互联网搜索、云计算、广告技术等,同时开发并提供大量基于互联网的产品与服务。
【使用工具】前嗅ForeSpider数据采集系统,免费下载:
http://www.forenose.com/view/forespider/view/download.html
【入口网址】
【采集内容】采集谷歌“apple”关键词下的全部列表数据,包括来源、标题以及摘要。

【待采集内容】
思路分析
配置思路概览:

配置步骤
一. 新建采集任务
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,自定义任务名称并输入在【任务名称】框内,点击“完成”。

【新建采集任务】
二. 模板配置
- 翻页链接采集配置
①查找翻页链接及其规律
在入口地址页内打开“F12”,按如下步骤找到翻页地址,并复制刷新后的翻页链接地址

【翻页链接位置】
对比观察翻页链接的规律

【翻页链接】
观察发现:随着翻页变化,页码数与请求网址(Requestrian URL)中“start=”后的数字相关。所以,其规律为:
"https://www.google.com/search?q=apple&ei=K_UaY4yIFNqBxc8PuNiymAk&start="+页码数减1后乘以10+"&sa=N&ved=2ahUKEwjMyfG7oYf6AhXaQPEDHTisDJM4KBDy0wN6BAgBEEE&biw=553&bih=755&dpr=1"
找到翻页链接位置及其规律就可以对应去编写脚本。
②脚本的创建与编写

【脚本的创建与编写】
脚本文本:
url u;//定义一个u,赋予其url属性
var url_beg=DOM.FindClass("AaVjTc","table");//定义一个url_beg,其属性位置位于 table class ="AaVjTc"所属节点下
var ur=url_beg.child.child.next.next.next;//定义一个ur,其位置属性位于url_beg二级子节点三级兄弟节点下
for(int i=0;i<=7;i++){ //为翻页数字页码写一个循环
u.title="谷歌第"+(i+1)+"页";//将标题内容设置为:谷歌第几页
var ur="https://www.google.com/search?q=apple&ei=K_UaY4yIFNqBxc8PuNiymAk&start="+i*10+"&sa=N&ved=2ahUKEwjMyfG7oYf6AhXaQPEDHTisDJM4KBDy0wN6BAgBEEE&biw=553&bih=755&dpr=1";//根据翻页链接规律,拼全链接
u.urlname=ur;//取得已拼合链接
u.entryid=CHANN.id;
u.tmplid=2;//关联模板02
RESULT.AddLink(u); //输出采集结果
ur=ur.next;//进入下个翻页链接的采集
}
③查看采集预览
查看采集预览,并将链接粘贴到浏览器验证一下是否采集正确。
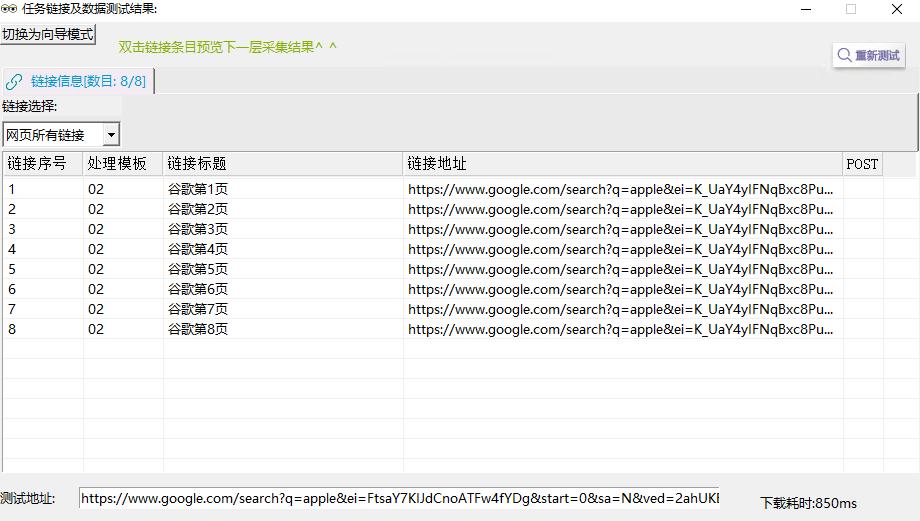
【采集预览】
- 数据抽取
①新建模板、添加数据抽取
如下新建模板并添加数据抽取,在示例地址框内输入任一翻页链接

【新建模板、添加数据抽取】
②数据表结构创建
如下在表结构内创建出所需采集的字段
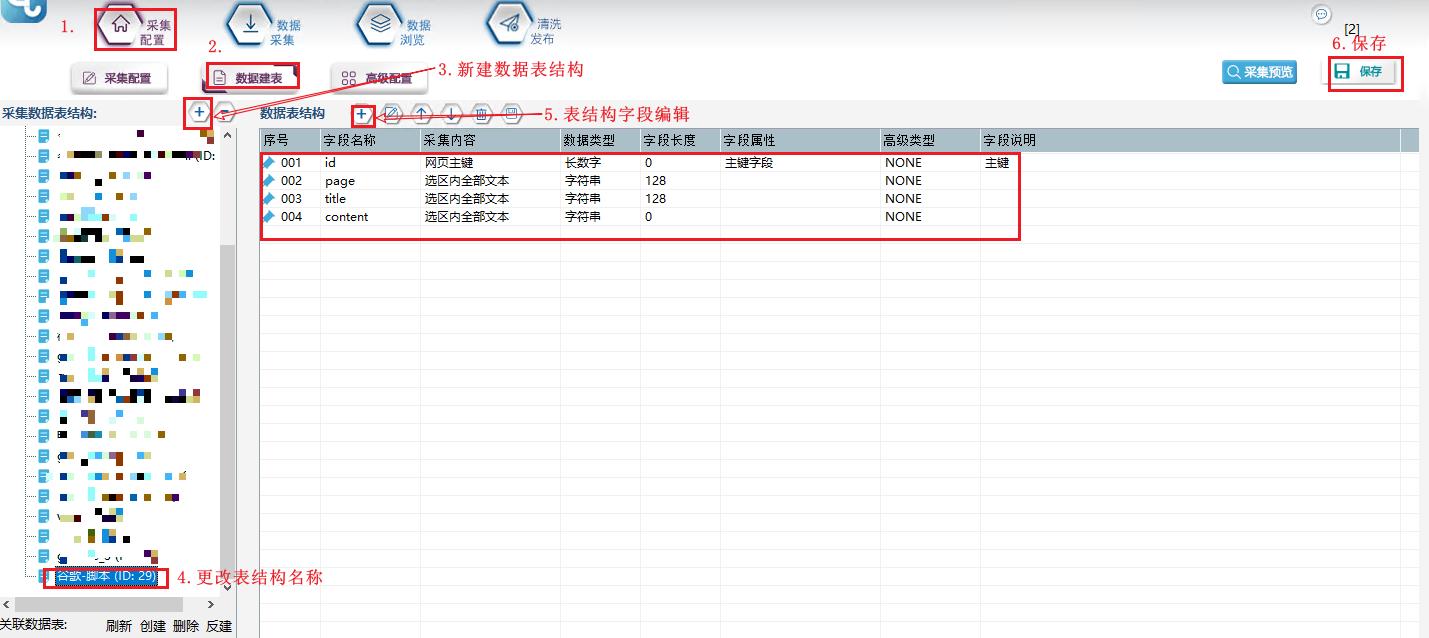
【创建表结构】
③关联表单
数据抽取关联数据结构表单

【关联表单】
④创建并编写数据抽取脚本
如下创建脚本,并根据网页结构编写数据抽取脚本

【脚本的创建与编写】
脚本文本:
record re ;//定义一个re,赋予其record属性
var ret=DOM.FindClass("hlcw0c","div");//定义一个ret,其位置属性位于 div class="hlcw0c"所在节点下
while (ret){//遍历ret
var beg=DOM.FindClass("MjjYud","div",ret);//定义一个beg,其位置属性位于 div class="MjjYud"所在节点下
var pu =beg.child.child.child;// 定义一个pu,其位置属性位于 div class="Z26q7c UK95Uc jGGQ5e VGXe8"所在节点下
var tit=pu.child.child.child.next; //定义一个tit,其位置属性位于 h3 class="LC20lb MBeuO DKV0Md"所在节点下
var pag=tit.next;//定义一个pag ,其位置属性位于tit下一兄弟节点下
var con=pu.next;//定义一个con ,其位置属性位于pu下一兄弟节点下
re.page=DOM.GetTextAll(pag);//取得列表内容来源
re.title=DOM.GetTextAll(tit);//取得列表内容标题
re.content=DOM.GetTextAll(con);//取得列表内容摘要
RESULT.AddRec(re,this.schemaid);//输出采集结果
ret=ret.next;//进入下一个待采集列表
}
⑤查看采集预览
查看采集预览,并核对一下内容是否采集正确。

【采集预览】