第
1
章
Explain
查看执行计划
Spark 3.0
大版本发布,
Spark SQL
的优化占比将近
50%
。
Spark SQL
取代
Spark Core
,成
为新一代的引擎内核,所有其他子框架如
Mllib
、
Streaming
和
Graph
,都可以共享
Spark
SQL
的性能优化,都能从
Spark
社区对于
Spark SQL
的投入中受益。
要优化
SparkSQL
应用时,一定是要了解
SparkSQL
执行计划的。发现
SQL
执行慢的根
本原因,才能知道应该在哪儿进行优化,是调整
SQL
的编写方式、还是用
Hint
、还是调参,
而不是把优化方案拿来试一遍。
1.1
准备测试用表和数据
1
、上传
3
个
log
到
hdfs
新建的
sparkdata
路径
2
、
hive
中创建
sparktuning
数据库
3
、执行
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num
executors 3 --executor-cores 2 --executor-memory 4g --class
com.atguigu.sparktuning.utils.
InitUtil
spark-tuning-1.0-SNAPSHOT-jar
with-dependencies.jar
1.2
基本语法
.explain(
mode="xxx"
)
从
3.0
开始,
explain
方法有一个新的参数
mode
,该参数可以指定执行计划展示格式:
➢
explain(mode="simple")
:只展示物理执行计划。
➢
explain(mode="extended")
:展示物理执行计划和逻辑执行计划。
➢
explain(mode="codegen")
:展示要
Codegen
生成的可执行
Java
代码。
➢
explain(mode="cost")
:展示优化后的逻辑执行计划以及相关的统计。
➢
explain(mode="formatted")
:以分隔的方式输出,它会输出更易读的物理执行计划,
并展示每个节点的详细信息。
1.3
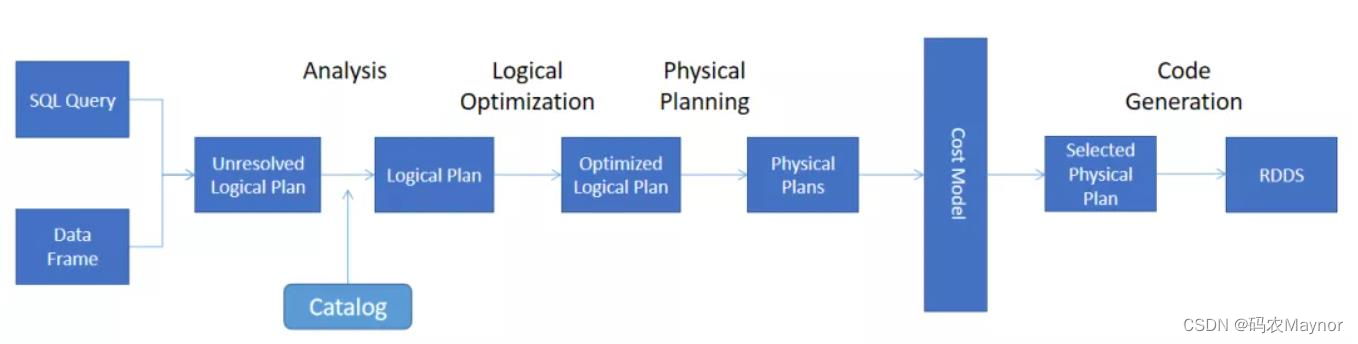
执行计划处理流程
核心的执行过程一共有
5
个步骤:
这些操作和计划都是
Spark SQL
自动处理的,会生成以下计划:
➢
Unresolved
逻辑执行计划:
== Parsed Logical Plan ==
Parser
组件检查
SQL
语法上是否有问题,然后生成
Unresolved
(未决断)的逻辑计划,
不检查表名、不检查列名。
➢
Resolved
逻辑执行计划:
== Analyzed Logical Plan ==
通过访问
Spark
中的
Catalog
存储库来解析验证语义、列名、类型、表名等。
➢
优化后的逻辑执行计划:
== Optimized Logical Plan ==
Catalyst
优化器根据各种规则进行优化。
➢
物理执行计划:
== Physical Plan ==
1
)
HashAggregate
运算符表示数据聚合,一般
HashAggregate
是成对出现,第一个
HashAggregate
是将执行节点本地的数据进行局部聚合,另一个
HashAggregate
是
将各个分区的数据进一步进行聚合计算。
2
)
Exchange
运算符其实就是
shuffle
,表示需要在集群上移动数据。很多时候
HashAggregate
会以
Exchange
分隔开来。
3
)
Project
运算符是
SQL
中的投影操作,就是选择列(例如:
select name, age
…)。
4
)
BroadcastHashJoin
运算符表示通过基于广播方式进行
HashJoin
。
5
)
LocalTableScan
运算符就是全表扫描本地的表。
1.4
案例实操
将提供的代码打成
jar
包,提交到
yarn
运行
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num
executors 3 --executor-cores 2 --executor-memory 4g --class
com.atguigu.sparktuning.explain.ExplainDemo spark-tuning-1.0-SNAPSHOT
jar-with-dependencies.jar
 核心的执行过程一共有 5 个步骤:
核心的执行过程一共有 5 个步骤: 这些操作和计划都是 Spark SQL 自动处理的,会生成以下计划:➢ Unresolved 逻辑执行计划: == Parsed Logical Plan ==Parser 组件检查 SQL 语法上是否有问题,然后生成 Unresolved (未决断)的逻辑计划,不检查表名、不检查列名。➢ Resolved 逻辑执行计划: == Analyzed Logical Plan ==通过访问 Spark 中的 Catalog 存储库来解析验证语义、列名、类型、表名等。➢ 优化后的逻辑执行计划: == Optimized Logical Plan ==Catalyst 优化器根据各种规则进行优化。➢ 物理执行计划: == Physical Plan ==1 ) HashAggregate 运算符表示数据聚合,一般 HashAggregate 是成对出现,第一个HashAggregate 是将执行节点本地的数据进行局部聚合,另一个 HashAggregate 是将各个分区的数据进一步进行聚合计算。2 ) Exchange 运算符其实就是 shuffle ,表示需要在集群上移动数据。很多时候HashAggregate 会以 Exchange 分隔开来。3 ) Project 运算符是 SQL 中的投影操作,就是选择列(例如: select name, age …)。4 ) BroadcastHashJoin 运算符表示通过基于广播方式进行 HashJoin 。5 ) LocalTableScan 运算符就是全表扫描本地的表。1.4 案例实操将提供的代码打成 jar 包,提交到 yarn 运行
这些操作和计划都是 Spark SQL 自动处理的,会生成以下计划:➢ Unresolved 逻辑执行计划: == Parsed Logical Plan ==Parser 组件检查 SQL 语法上是否有问题,然后生成 Unresolved (未决断)的逻辑计划,不检查表名、不检查列名。➢ Resolved 逻辑执行计划: == Analyzed Logical Plan ==通过访问 Spark 中的 Catalog 存储库来解析验证语义、列名、类型、表名等。➢ 优化后的逻辑执行计划: == Optimized Logical Plan ==Catalyst 优化器根据各种规则进行优化。➢ 物理执行计划: == Physical Plan ==1 ) HashAggregate 运算符表示数据聚合,一般 HashAggregate 是成对出现,第一个HashAggregate 是将执行节点本地的数据进行局部聚合,另一个 HashAggregate 是将各个分区的数据进一步进行聚合计算。2 ) Exchange 运算符其实就是 shuffle ,表示需要在集群上移动数据。很多时候HashAggregate 会以 Exchange 分隔开来。3 ) Project 运算符是 SQL 中的投影操作,就是选择列(例如: select name, age …)。4 ) BroadcastHashJoin 运算符表示通过基于广播方式进行 HashJoin 。5 ) LocalTableScan 运算符就是全表扫描本地的表。1.4 案例实操将提供的代码打成 jar 包,提交到 yarn 运行