-
Oracle partition分区表(一)-----范围分区、列表分区、哈希分区
一、基本概念
将一个表划分为多个分区表,“分而治之”。
当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个“表空间”(物理文件上),这样查询数据时,不至于每次都扫描整张表而只是从当前的分区查到所要的数据大大提高了数据查询的速度。
随着表中行数的增多,管理和性能性能影响也将随之增加。备份将要花费更多时间,恢复也将 要花费更说的时间,对整个数据表的查询也将花费更多时间。通过把一个表中的行分为几个部分,可以减少大型表的管理和性能问题,以这种方式划分发表数据的方法称为对表的分区。二、分区表作用
Oracle的表分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还可以极大简化常见的管理任务,分区是构建千兆字节数据系统或超高可用性系统的关键工具。 分区功能能够将表、索引或索引组织表进一步细分为段,这些数据库对象的段叫做分区。每个分区有自己的名称,还可以选择自己的存储特性。从数据库管理员的角度来看,一个分区后的对象具有多个段,这些段既可进行集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当大的灵活性。但是,从应用程序的角度来看,分区后的表与非分区表完全相同,使用 SQL DML 命令访问分区后的表时,无需任何修改。
三、优缺点
优点:
- 改善查询性能: 对分区对象的查询可以仅搜索自己关心的分区,提高检索速度;
- 方便数据管理:因为分区表的数据存储在多个部分中,所以按分区加载和删除数据比在大表中加载和删除数据更容易;
- 增强可用性: 如果某个分区出现故障,其它分区的数据仍然可用;
- 维护方便: 如果某个分区出现故障,仅修复该分区即可;
- 均衡I/O: 将不同的分区放置不同的磁盘,以均衡 I/O,改善整个系统性能;
- 方便备份恢复:因为分区比被分区的表要小,所以针对分区的备份和恢复方法要比备份和恢复整个表的方法多
缺点
- 已经存在的表没有方法可以直接转化为分区表- 不过有很多间接方法,如:重定义表 (Oracle 提供了在线重定义表的功能)
场景
- 表的大小超过2GB。
- 表中包含历史数据,新的数据被增加到新的分区中。
四、思维导图
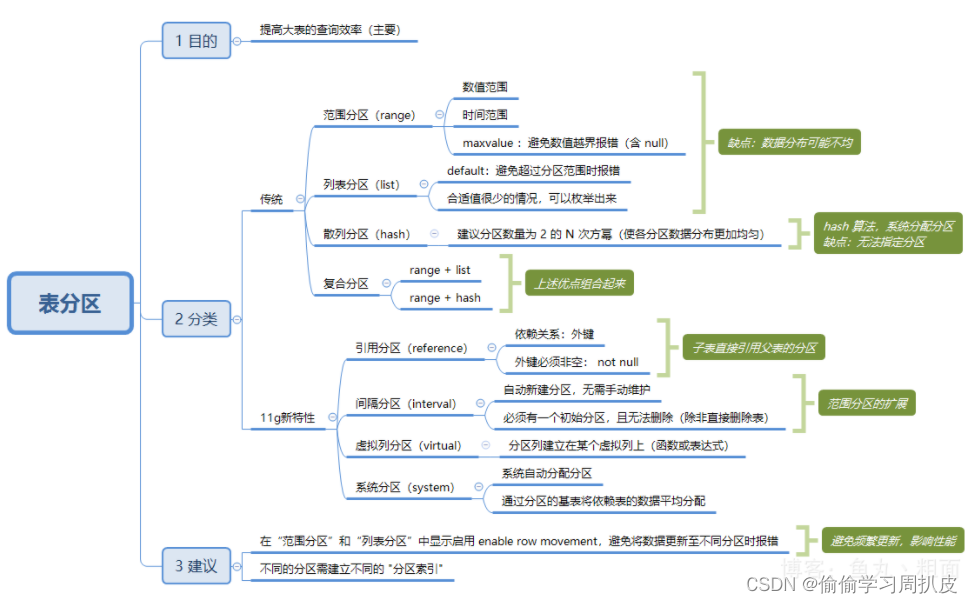
五、分区表相关视图
--显示分区表信息 SELECT * FROM DBA_PART_TABLES; --显示表分区信息 显示数据库所有分区表的详细分区信息﹕ SELECT * FROM DBA_TAB_PARTITIONS; --显示子分区信息 显示数据库所有组合分区表的子分区信息﹕ SELECT * FROM DBA_TAB_SUBPARTITIONS; --显示分区列 显示数据库所有分区表的分区列信息﹕ SELECT * FROM DBA_PART_KEY_COLUMNS; --显示子分区列 显示数据库所有分区表的子分区列信息﹕ SELECT * FROM DBA_SUBPART_KEY_COLUMNS;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
六、分区表分类和相关语句
1.范围分区 range
- 说明:
针对记录字段的值在某个范围。
范围分区就是对数据表中的某个值的范围进行分区,根据某个值的范围,决定将该数据存储在哪个分区上。如根据序号分区,根据业务记录的创建日期进行分区等(联通每个月的账单记录就用的分区表存储)。 - 规则:
数值范围分区
时间范围分区 - 语句规律:
(1)每一个分区都必须有一个VALUES LESS THEN子句,它指定了一个不包括在该分区中的上限值。
分区键的任何值等于或者大于这个上限值的记录都会被加入到下一个高一些的分区中。
(2)所有分区,除了第一个,都会有一个隐式的下限值,这个值就是此分区的前一个分区的上限值。
(3)在最高的分区中,MAXVALUE被定义。MAXVALUE代表了一个不确定的值。这个值高于其它分区中的任何分区键的值,
也可以理解为高于任何分区中指定的VALUE LESS THEN的值,同时包括空值。若不添加maxvalue的分区插入数值一旦超过设置的最大上限会报错。
情况1:数值范围分区
--创建分区表 create table pt_range_test1( pid number(10), pname varchar2(30) ) partition by range(pid)( partition p1 values less than(100) tablespace tetstbs1, partition p2 values less than(500) tablespace tetstbs2, partition p3 values less than(maxvalue) tablespace tetstbs3 ) enable row movement; --插入数据 insert into pt_range_test1 (pid, pname) values (1, '1111'); insert into pt_range_test1 (pid, pname) values (501, '2222'); insert into pt_range_test1 (pid, pname) values (null, '3333'); commit; --查询数据 select * from user_tab_partitions t; --或者 select 'P1' 分区名, t.* from pt_range_test1 partition (p1) t union all select 'P2' 分区名, t.* from pt_range_test1 partition (p2) t union all select 'P3' 分区名, t.* from pt_range_test1 partition (p3) t; --查询单个分区表数据 select 'P3' 分区名, t.* from pt_range_test1 partition (p3) t;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
情况2:时间范围分区
--创建分区表 create table pt_range_test2( pid number(10), pname varchar2(30), create_date date ) partition by range(create_date)( partition p1 values less than(to_date('2021-01-01', 'YYYY-MM-DD')) tablespace tetstbs1, partition p2 values less than(to_date('2022-01-01', 'YYYY-MM-DD')) tablespace tetstbs2, partition p3 values less than(maxvalue) tablespace tetstbs3 ) enable row movement; --查询同上- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.列表分区 list
- 说明:
该分区的特点是某列的值只有有限个值,基于这样的特点我们可以采用列表分区。 - 规则:
默认分区为DEFAULT,若不添加DEFAULT的分区插入数值不属于所设置的分区会报错。 - 语句规律:
在定义范围分区时,每个分区定义必须使用 values(‘value01’,‘value02’…)子句。表示该分区存储包含相关value值的数据行。
在定义范围分区时,最后一个分区可以是values(DEFAULT)。表示该分区存储未在其他分区定义的数据行。
--创建分区表 create table pt_list_test( pid number(10), pname varchar2(30), sex varchar2(10) ) partition by list(sex)( partition p1 values ('a', 'A') tablespace tetstbs1, partition p2 values ('b', 'B') tablespace tetstbs2, partition p3 values (default) tablespace tetstbs3 ) enable row movement; --插入数据 insert into pt_list_test (pid, pname, sex) values (1, '111', 'A'); insert into pt_list_test (pid, pname, sex) values (2, '222', 'b'); insert into pt_list_test (pid, pname, sex) values (3, '333', 'a'); commit; --查询数据 select 'P1' 分区名, t.* from pt_list_test partition (p1) t union all select 'P2' 分区名, t.* from pt_list_test partition (p2) t union all select 'P3' 分区名, t.* from pt_list_test partition (p3) t --查询单个分区表 select 'P3' 分区名, t.* from pt_list_test partition (p3) t- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
3.哈希分区(散列分区表) hash
- 说明:
这类分区是在列值上使用散列算法,以确定将行放入哪个分区中。 - 规则:
当列的值没有合适的条件,没有范围的规律,也没有固定的值,建议使用散列分区。
散列分区为通过指定分区编号来均匀分布数据的一种分区类型,因为通过在I/O设备上进行散列分区,
使得这些分区大小一致。建议分区的数量采用2的n次方,这样可以使得各个分区间数据分布更加均匀。 - 语句规律:
创建hash分区有两种方法:一种方法是指定分区的名字,另一种方法是指定分区数量。
散列分区通过在分区键值上执行一个散列函数来说决定数据的物理位置。在范围分区中,分区键的连续值通常储存在相同的分区中。而在散列分区中,连续的分区键值不必储存在相同的分区中。散列分区把记录分布在比范围分区更多的分区上,这减少了I/O争用的可能性。
还有一种定义hash分区的方式是:partition by hash(column) partition n store in (tbs1,tbsm)。表空间的数目不必等于分区的数目,即n不一定等于m,如果指定的分区数目比表空间的数目多,则分区将会以循环的方式分配到表空间中,一个表空间可以含有多个分区
1.常规方法指定分区名字
create table part_hash_t1(id number,name varchar2(20),age int) partition by hash(age)( partition p1 tablespace tbs1, partition p2 tablespace tbs2)- 1
- 2
- 3
- 4
2.指定分区数量
create table part_hash_t2(id number,name varchar2(20),age int) partition by hash(age) partitions 2 store in(tbs1,tbs2)- 1
- 2
-
相关阅读:
算法与数据结构(第三周)——数据结构基础:动态数组
Spring MVC:请求转发与请求重定向
普通用户如何利用小红书赚钱呢?小红书的流量是真的吗?
Linux设备驱动模型之SPI
全方面解析‘找不到msvcr120.dll无法继续执行代码’这个问题
如何提高网站安全防护?
AIR-CAP2702I-H-K9/AIR-CAP3602I-H-K9刷固件讲解
【Golang星辰图】全面解析:Go语言在Web开发中的顶尖库和框架
浅析axios原理与使用(包括axios的优雅写法与res的解构赋值)
Java枚举详解
- 原文地址:https://blog.csdn.net/qq_37432174/article/details/126786062