-
无服务器学习02:挑战及发展
无服务器学习02:挑战及发展
一. 无服务计算的兴起
云计算兴起之初,市场上存在两种虚拟化解决方案。一是AWS提供的Elastic Compute Cloud (EC2)[1]服务,二是Google提供的App Engine[2]服务。在当时看来,两种解决方案针锋相对,分别代表了两种极端:EC2实例尽可能的还原物理环境,用户几乎可以掌控从OS Kernel 向上的整个软件栈;而App Engine 则为用户提供了丰富的云端基础服务,用户可以使用这些服务开发云应用。[3]
市场最终选择了AWS的“低级”虚拟化方案,因此谷歌、微软以及国内各大云提供商都提供了类似的接口。虚拟机方案能够成功,归功于在云计算的早期,前景尚不明朗的情况下,用户更多的是希望在云中构建与本地相同的环境,以实现应用迁移,而不是重新开发一套云端应用。
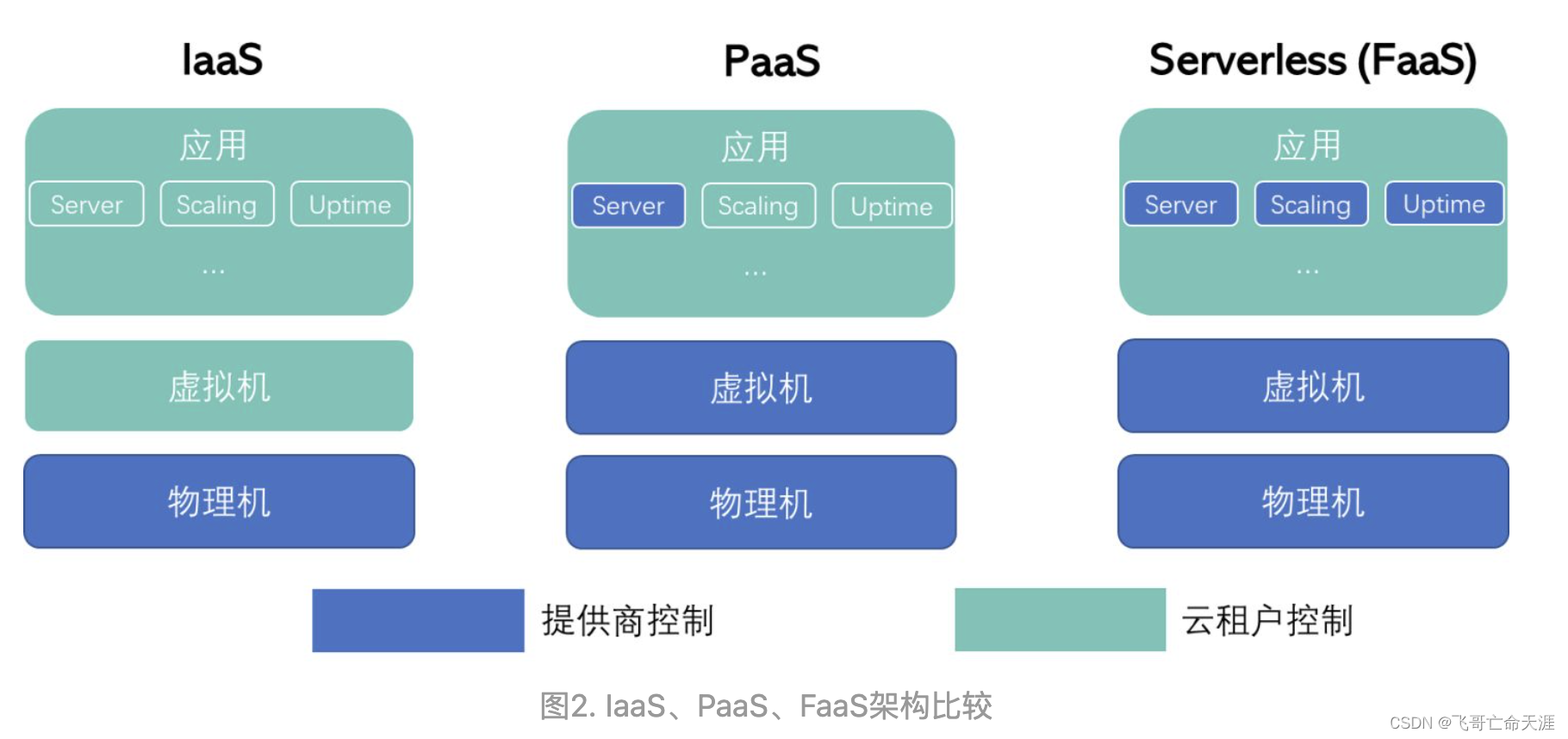
**然而这种选择的代价是,开发人员必须自己管理整个虚拟环境。**表1中列出了云中运行环境必须管理的问题。**一系列繁琐的环境管理工作激发了使用简单应用程序的客户对于简单云路径的需求。**例如,国庆期间朋友圈迎来了更换国旗头像的热潮。实现一个这样的图片处理程序,可能只需要几十行JavaScript的代码,与配置和维护服务器来运行这段代码的工作量相比,开发工作简直是微不足道的。
基于这种需求,AWS在2015年推出了名为AWS Lambda[8]的云函数服务。引发了业界对无服务计算的广泛,通过Lambda,用户只需要考虑应用程序的代码逻辑,无需考虑扩展、部署、容错、监控、日志记录服务器配置,因而又称之“无服务”计算。
如今,各大云提供商都提供了无服务计算服务。随着越来越多的大型应用,如大数据处理、机器学习模型训练等采用无服务计算的架构,无服务计算的性能问题也日益凸显。[9]
二. 挑战及发展
2.1 运行时的挑战
在现有FaaS平台中,每个Function实例都运行在隔离的容器或轻量级虚拟机的环境中,当请求到达时FaaS平台会启动并初始化一个新的实例来响应用户的请求,过程如图三[10]所示。

这种触发式启动的模式可以很好的根据负载的变化来自动的扩展或者缩小实例的数目。- 用户既无需担心流量洪峰时,实例资源严重不足导致的服务质量下降,因为FaaS平台会自动启动足够数目的实例来响应;
- 又可以极大的节省成本,因为FaaS会在低负载时会主动缩减实例
- 同时无服务计算平台采用Pay-As-You-Go的计费模式,仅对运行过程中资源收费。因此用户无需超配资源,就可以既保证服务质量,又节省成本。更惊喜的是,上述过程无需用户任何的配置,都是由无服务计算平台自动实现,用户只需要提交Function的代码即可!
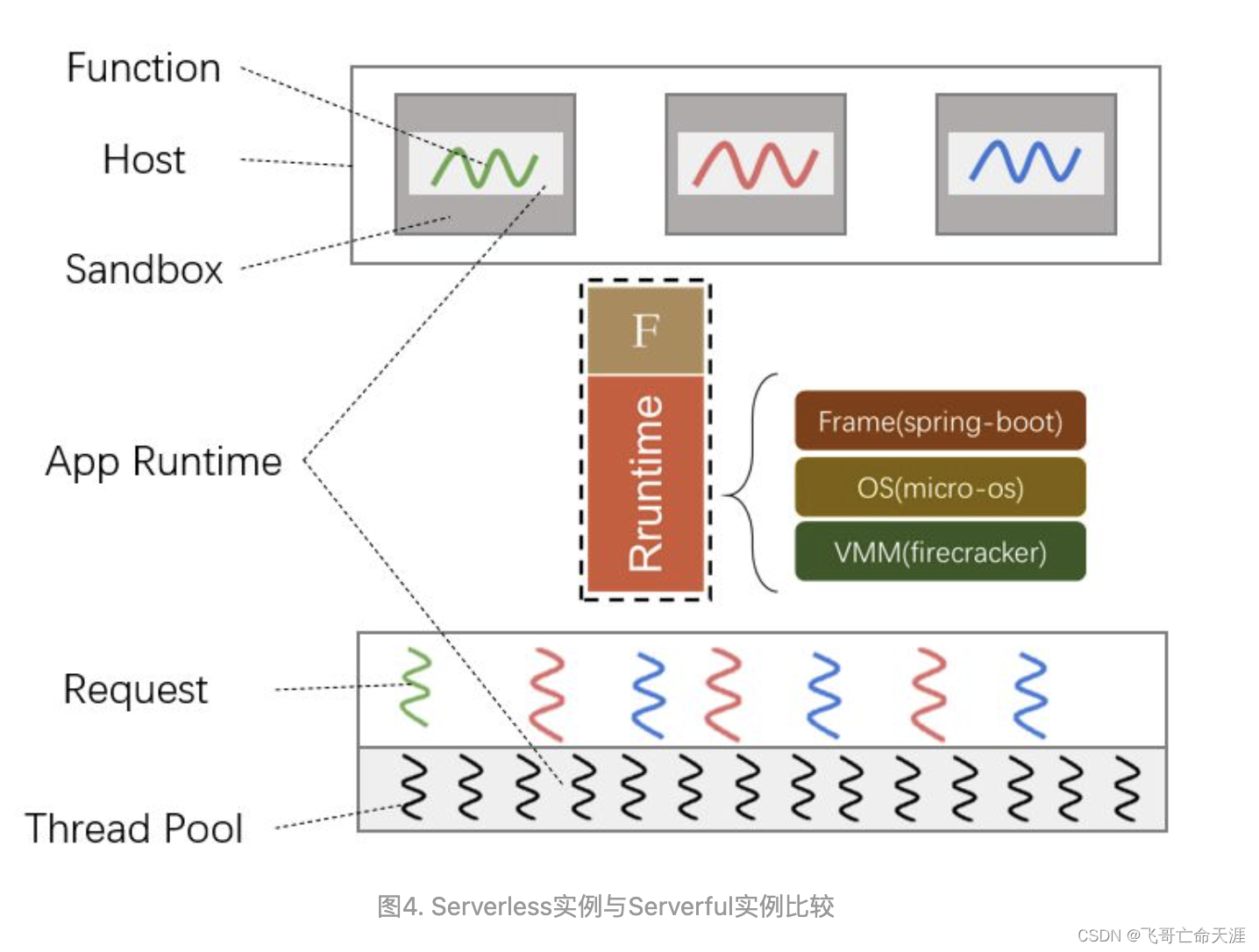
图4所示,原来的Application直接通过一个线程响应请求,整个过程几乎没有任何初始化的开销。然而对于Serverless而言,需要首先启动一个Sandbox实例,
- 如容器或者轻量级虚拟机,
- 然后初始化Function的运行环境,
- 最后需要通过网络向Gateway传输执行结果,
- 再由Gateway返回给用户。
挑战1:
- 整个过程冗长、且存在严重的冷启动的开销,冷启动的时间甚至超过了Function的执行时间[9]。
- 而且由于原来完整的服务被拆分为数以千计的细粒度Function,冷启动的频率极大的增加!
- 同时由于每个Function实例都具有完整的运行环境,这使得在高并发的情况下,无服务计算的部署密度远小于传统的Serverful服务方式。
针对解决冷启动问题,主流的解决方案包括:
1、解决:实例缓存
缓存实例即预启动服务实例,构建一个实例池,从而避免冷启动的过程,如Lambda的预留实例、OpenWhisk的warm-start机制等。此方案可以跳过初始化的过程,
问题1
但是需要在没有请求的情况下保留足够数量的实例,对于云提供商而言是额外的成本开销!此外,面对超高的突发负载,“池“策略的局限性将进一步凸显,对于超过“池”容量的负载请求,依然需要冷启动实例!

缓存的实例可以分为仅缓存Sandbox和缓存整个Function实例两种。好处与问题2
前者具有很好的通用性,缓存的sandbox可以用于处理不同Function的请求,但是无法消除应用的初始化开销[11];缓存整个实例如图5[12]所示,可以完全的消除冷启动的开销,但是通用性极差,放大了池化策略的缺点!
问题2尚未解决==============
2、解决:内部并发
在面临突发请求时,启动足够的实例将面临巨大的性能挑战!考虑到单个Function执行所需的资源很小,可以考虑用一个实例并发处理多个请求,从而大大减少冷启动的数目。Knative[13] 融合了原来传统微服务的方式,将一个Function定义为一个更小的微服务,是一个拥有IP的可访问的执行单元,一个function实例可以并发的处理多个用户请求。Knative通过类似于HPA的方式实现了自动扩展,如图6所示。

每个Fucntion都运行在一个Pod中,Pod运行一个sidecar服务用于监控流量,并周期性向自动扩展组件Autoscaler汇报,Autoscaler 将根据负载情况控制实例的数目。
内部并发,可以减少启动实例的数目,从而减少冷启动开销。问题1
但是如何确定实例的并发数目是一个复杂的问题,
- 用户需要根据经验为每一个Function配置合理资源和并发度,这其实于无服务计算的无服务理念相违背。
- 其次HPA的策略需要统计一段时间内的负载变化请款,这就导致实例的扩展总是滞后于负载的变化,面对突发的请求负载,将会导致严重的性能毛刺。
解决1:Checkpoint-Restore OnDemand
- Catalyzer[11]、Replayable Execution[14]等提出了按需加载的Checkpoin-Restore方案,这是在不破坏隔离性的情况下,真正可以减少冷启动开销的策略。
- Checkpoint-Restore本身是一个成熟的技术,他会保存应用程序某一时刻的内存状态到持久化存储中,称之为Checkpoint;然后可以通过保存的内存状态恢复程序的运行状态,使之在停止的位置继续运行,称之为Restore。
问题1
然而Restore的过程,开销依然存在且无法忽略,如图7所示。

解决1:按需恢复的策略
因此他们提出了按需恢复的策略,即不在启动的关键路径上完全恢复进程状态。**这是出于对进程初始化过程中启动的文件和加载的内存,只有很少一部分会在运行的过程中被使用这一实践情况的观察。**最终,该案可以将应用(JVM)的初始化开销,缩减至30ms左右。
3、解决:轻量级隔离
这是一种以弱化隔离性为代价的解决冷启动开销的方案。
- SOCK[15]设计了新型的容器模型,阉割了Docker中的部分功能,如使用NAT转发替换网络隔离,使用Mount-Bind替换AUFS的文件系统隔离等;
- SAND[10]认为,同Application的Function之间不需要强大的隔离,因此设计了一种两层的隔离方案,使用进程隔离Function,使用容器来隔离Application,并通过fork来创建新实例;
- FAASM[16]则直接将实例放在同一进程地址空间中,使用线程来驱动实例的执行,并通过WebAssembly机制来确保内存安全!
2.2 存储与通讯的挑战
无服务计算的实例是无状态和完全隔离的,这有利于实现按需的自动扩展。然而伴随着无服务计算的应用范围越来越广泛,无状态的特性逐渐成为性能瓶颈问题。由于完全的隔离,实例之间无法直接进行通讯,只能通过第三方的存储服务来传递中间结果,称之为无服务计算的临时存储问题。[17]
通常临时存储的介质包括磁盘、SSD和内存存储。三者的价格依次上升而访问的响应时间依次减小。因此如何选择合适的存储介质,在确保服务质量的前提下,节省最大的成本,是临时存储所面临的主要挑战。Pocket[18] 通过对Function任务的分析,可以帮助用户动态的选择合适的存储方式。问题1
然而即使选择内存存储,用户依然需要使用网络将数据拉取到本地,如果多个Function共享某个中间结果,那么就需要重复的拉取拷贝和数据序列化,如图9所示,这会导致额外的内存开销,降低函数的部署密度。
解决1:共享内存
针对这个问题,FAASM[16]基于WebAssembly共享地址空间的特性,设计了共享内存的数据通讯方案。

问题2
此外Function无法直接调用启动另一个Function,需要首先将调用的请求上传到全局的Gateway中,再由Gateway进行裁决和任务的下发,这就带来了额外的调用开销,如图10所示,对于延迟敏感的任务,这种开销是同样是无法接受的。

解决2:本地的消息队列
SAND[10]、Nightcore[19]等实现了本地的消息队列,当本机的资源合适时,可以选择直接在本地启动实例。
2.3 任务放置与调度的挑战
数据分析型任务可以根据数据依赖性抽象成一个DAG图,分为多个阶段,每个阶段包含多个并行任务。数据分析型负载通常随着时间的推移资源需求也在变化,因此特别适配于无服务计算平台,可以充分的利用其按需资源分配和快速实例扩展的特性。[20]
问题
- 然而由于数据分析任务流长且复杂,如果采用“invoke one_by_one”的方式逐一启动实例,会放大冷启动的开销,
- 而如果采用“invoke all”的方式,预启动所有实例则会造成严重的资源浪费。
- 此外任务间存在大量的中间数据传递,间接的数据通信开销巨大。
除前述解决冷启动和通讯的系统方案之外,通过恰当的调度策略,可以在现有系统的基础上优化任务的执行路径,在保证任务服务质量的前提下,节省成本开销。
现有的解决方案主要通过分析任务流的结构,利用任务流内的调用关系以及数据局部性等,决策Function的启动时机和数据传递。
解决1:优化启动时机
如下图所示,普通的启动模式分为:懒汉模式和饿汉模式。懒汉模式顺序初始化function,饿汉模式提前初始化function。显然懒汉的成本更低,饿汉的执行时间更短。Caerus[20]通过分析任务间的依赖关系,在何时位置启动下一步实例,重合执行可并发的部分,隐藏启动开销,同时缩短实例的等待时间。

解决2:优化数据传递
如下图所示,可以从一个DAG图中分割出多个子图,子图内部的中间数据自下而上的传递。可以让子图中所有任务重用同一个Function实例,对于子图重合的部分,根据数据大小,动态选择数据传递方向,尽量避免不必要的数据传递。[21]

总结
从无服务计算的概念被提出至今已有六年,特别是近三年来涌现了许多相关的研究。
- 各大云平台对于无服务计算的多是基于现有的虚拟化技术和针对VM、容器的编排方法来实现,用有状态、粗粒度的“胖子”来“伪装”无状态、细粒度的“瘦子”。
- 现有的研究多是在特定的场景对具体问题做针对性改进,无服务计算依然无法做到SaaS那样通用性。
参考
https://zhuanlan.zhihu.com/p/425433134

-
相关阅读:
Vue双向绑定的原理
5.4 一家人才测评机构低随机抽取的10名小企业的经理人用两种方法进行自信心测试,得到的自信心测试分数如下
获得淘宝商品详情 API 返回值说明
MySQL中对于索引的理解
STARK Low Degree Testing——FRI
资产实物综合管理系统应用方案介绍
join方法使用案例
TCP-3次握手小记
CloudCompare 二次开发(10)——点云投影到平面
Ajax——Ajax基础概念以及两种请求方式
- 原文地址:https://blog.csdn.net/tianyi520jx/article/details/126819862