-
JMeter类比loadrunner断言、参数化、集合点、关联、事务——学习笔记
断言
常用的4种断言方法
一、Response Assertion(响应断言)
二、Size Assertion(数据包字节大小断言)
三、Duration Assertion(持续时间断言)
四、beanshell 断言(自由断言)一、Response Assertion(响应断言)
判断返回内容中的内容
作用对象:响应报文中的所有对象APPly to:适用范围
Main sample and sub-samples:作用于父节点取样器及对应子节点取样器
Main sample only:仅作用于父节点取样器
Sub-samples only:仅作用于子节点取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)要测试的响应字段:要检查的项
Text Response 匹配从服务器返回的响应文本(不包括Response Headers)
Response Code 匹配响应状态码
Response Message 匹配响应信息。如:OK
Response Headers 匹配响应头
Request Headers 匹配请求头
URL Sampled 匹配URL链接
Document(text) 匹配文档内容
Ignore Status 一个请求多项响应断言时,忽略某一项断言的响应结果,而继续下一项断言
Request Data 匹配请求数据模式匹配规则:
包括:返回结果包括你指定的内容
匹配:根据指定内容进行匹配(好像跟Equals查不多,弄不明白有什么区别)
Equals:返回结果与你指定结果一致
Substring:返回结果是指定结果的字串
否:不进行匹配
或者:暂不确定该模式的用法
要测试的模式:即填写你指定的结果(可填写多个),按钮【添加】、【删除】是进行指定内容的管理二、Size Assertion(数据包字节大小断言)
判断响应结果是否包含正确数量的byte。可定义(=, !=, >, <, >=, <=)
用于判断返回内容的大小;
作用对象:返回信息,响应报文APPly to:应用范围(返回内容的断言范围)
Main sample and sub-samples:作用于父节点取样器及对应子节点取样器
Main sample only:仅作用于父节点取样器
Sub-samples only:仅作用于子节点取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)Response Size Field to Test:响应字节的测试范围(可以选择用于判断的响应范围)
Full Response:全部响应
Response Headers:响应头部
Response Body:响应主体
响应代码:响应报文相关的代码
响应信息:响应报文的信息
Size to Assert:断言字节范围
字节大小单位为:字节;比较顺序是①返回内容的大小②比较类型③指定字节大小三、Duration Assertion(持续时间断言)
判断是否在给定的时间内返回响应结果
用于判断服务器的响应时间
作用对象:服务器APPly to:适用范围
Main sample and sub-samples:作用于父节点取样器及对应子节点取样器
Main sample only:仅作用于父节点取样器
Sub-samples only:仅作用于子节点取样器Duration to assert:持续断言
Duration in milliseconds:响应时间设置(单位:毫秒),如果响应时间大于设置的响应时间,则断言失败,否则成功!四、beanshell 断言
Bean Shell常用内置变量,是一种松散类型的脚本语言(这点和JS类似),一种完全符合java语法的java脚本语言,并且又拥有自己的一些语法和方法;
作用对象:针对sampler中的Bean Shell sampler而使用的断言Name:断言的名字(可以用一个比较容易理解和分辨的名称)
Comments:注释(对这个断言进行一个解释,备注)
Reset bsh.interpreter before each call:在每次调用Bean Shell之前重置bsh.interpreter类
(bsh.interpreter是Bean Shell脚本语言的一种类,也可以理解为一种解析器)
Parameters(String Parameters and String []bsh.args):String参数(String []bsh.args是主类main函数的形式参数,是一个String 对象数组,可以用来获取命令行用户输入进去的参数)
Script file:脚本文件(可以填入脚本文件路径)
Script(see below for variables that are defined):参照下文定义的变量(使脚本文件参照定义的变量来运行)五、 BSF断言
BSF(Bean Scripting Framework);是一个支持在Java应用程序内调用脚本语言 (Script),并且支持脚本语言直接访问Java对象和方法的一个开源项目;
作用对象:针对sampler中的BSF sampler而使用的断言Script language(e.g.beanshell,javascirpt,jexl):脚本语言(可以从下面的下拉框中选择对应的脚本语言JavaScript、beanshell等)
parameters to be passed to script(=> String Parameters and String []args):(传递给脚本的参数→可以理解为使用BSF断言脚本时候一起引用的参数 )
Script file(overrides script):重写脚本(可以通过选择脚本文件的状态,是浏览调用已有的脚本还是在在下方的输入框内写入脚本;)
Script:下面的输入框表示可以输入变量类型,运用的脚本(取样结果、断言结果、取样日志文件等参数)六、比较断言(compare assertion)
这是一种比较特殊的断言元件,针对断言进行字符串替换时使用;
作用对象:需要替换的字符串Select Comparison Operators:选择比较运算符
Compare Content:可以选择比较的内容类型(true/false或者自定义,编辑)
Compare Time:比较时间(可以设定比较的时间,单位为秒,默认为-1)
Comparison Fitters:比较修改工具
regular expression substitutions:替换正则表达式
Regex String:要替换的字符串(可从断言结果中选择)
substitutions:替换的字符串(替换结果)七、HTML断言
对响应类为XML类型的文件进行断言;
作用对象:针对sampler中的SOAP/XML-RPC Request而使用的断言Tidy Settings:Tidy 环境(Tidy是一个HTML语法检查器和打印工具,可以将HTML转换为XML类型的文件)
Doctype:文档类型(可通过下拉框选择不同文档类型→ omit疏忽遗漏的/auto动态的/strict严格的/loose宽泛的)
Format:文件格式(可选择HTML/XHTML/XML三种不同类型的文件格式来检查返回内容)
Errors only:误差校正(能接受的最大值)
Error threshold:误差/错误范围(可选择误差/错误数量的范围,最大值)
Warning threshold:警告范围(可选择误差警告的数量范围,最大值)
如果勾选“Error only”这里忽略Warning,只对误差作统计检查;如果对返回内容的检查结果不超过指定结果,则断言通过,否则失败。
Write JTidy report to file:写入JTidy报告的文件(JTidy是Tidy的一个java移植,可以将它当成一个处理HTML文件的DOM解析器)八、JSR223断言
JSR223即Java 规范请求,是指向JCP(Java Community Process)提出新增一个标准化技术规范的正式请求;
作用对象:针对sampler中的JSR223 sampler而使用的断言Script language(e.g.beanshell,javascirpt,jexl):脚本语言(可以从下面的下拉框中选择对应的脚本语言JavaScript、beanshell等)
parameters to be passed to script(=> String Parameters and String []args):(传递给脚本的参数→可以理解为使用JSR223断言脚本时候一起引用的参数 )
Script file(overrides script):重写脚本(可以通过选择脚本文件的状态,是浏览调用已有的脚本还是在在下方的输入框内写入脚本;)
Script:下面的输入框表示可以输入变量类型,运用的脚本(取样结果、断言结果、取样日志文件等参数)九、MD5Hex断言
MD5是一种消息摘要算法,用以提供消息的完整性保护(具体关于MD5的知识请自行查询);
作用对象:针对参数类型为MD5Hex加密的参数的断言MD5Hex:将已被MD5加密的参数写入其中,添加取样器等其他元件
十、SMIME断言
SMIME是一种多用途网际邮件扩充协议,相比于之前的SMAP邮件传输协议,增加了安全性,对邮件主题进行保护;
作用对象:针对采用了该种邮件传输协议的信息signature:签名(可选择对协议的签名验证状态)
Verify signature:验证签名
Message not signed:没有签名消息
Signer certificate:签名证书(因为SMIME协议增加了安全传输,需要证书验证)
No check:不检查
Check values:检查
Signer distinguished name:签名证书者名称(证书注册者的名称)
Sigmer email address:签名者的邮件地址(注册的邮件地址)
Issuer distinguished name:发行者名称(由谁发行的证书)
Serial Number:证书序号
Certificate file:选择证书文件
Execute assertion message at position:执行断言消息的位置(在返回消息的具体哪个位置执行断言)十一、XML概要断言
亦可以称为XML模型断言/XML数据类型断言;XML Schema 定义了两种主要的数据类型:①xml document schema 文档架构 ;② 文档架构xml-schema xml模式
作用对象:返回结果为XML概要断言的2中数据类型的消息XML Schema:XML概要模型
File Name:文件名(写入需要断言的文件名称)十二、XML断言
XML(可扩展标记语言) 提供一种描述结构化数据的方法。与主要用于控制数据的显示和外观的 HTML 标记不同,XML 标记用于定义数据本身的结构和数据类型;
作用对象:判断返回结果是否和xml的格式即<>成对出现
十三、XPath断言
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。
作用对象:针对返回信息为XPAth的数据类型进行断言
Apply to:适用范围
Main sample and sub-samples:主要样本和次级样本
Main sample only:仅主要样本
Sub-samples only:仅次级样本
JMeter Variable:jmeter变量(输入框内可输入jmeter的变量名称)
XML Parsing Options:XML解析选项
Use Tidy(tolerant parser):使用Tidy(容错解析器),默认选择quiet(不显示)
Quiet:不显示
Report errors:错误报告
Show warnings:显示错误
Use Namespaces:使用名称空间
Validate XML:验证XML(文件包/数据)
Ignore Whitespace:忽略空格(这允许你指定语法分析器可以忽略哪个空格,而哪个空格是重要的)
Fetch external DTDs:获取外部DTDs(一些XML元素具有属性,属性包含应用程序使用的信息,属性仅在程序对元素进行读、写操作时,提供元素的额外信息,这时候需要在DTDs中声明)
XPath Assertion:输入框中写入xpath断言,点击Validate验证其正确性
True if nothing matches:确认都不匹配参数化
4种参数化方式:
函数助手:_CSVRead 随机函数${__Random(1,100,)}
CSV Data Set Config:CSV数据控件
User Defined Variables:用户定义的变量
User Variables:用户参数一、函数助手:_CSVRead
点击jmeter的界面,功能栏选项→ 函数助手对话框→ _CSVRead
CSV file to get values from | *alias:CSV文件取值路径,即这里需要写入之前的需要参数化的参数的文件路径
CSV文件列号| next|*alias:文件起始列号:CSV文件列号是从0开始的,第一列为0,第二列为1,以此类推
函数字符串:即生成的参数化后的参数,可以直接在登陆请求中的参数中引用,第一列为用户名,函数字段号为0,第二列为密码,函数字段号为1,以此类推进行修改使用即可二、配置元件——CSV Data Set Config
点击线程组添加配置元件→ CSV Data Set Config(CSV 数据文件设置)
说明:
Filename:F:\jmeter\csvtest.dat文件名,保存参数化数据的文件目录,可选择相对或者绝对路径(建议填写相对路径,避免脚本迁移时需要修改路径);
File encoding:UTF-8,csvtest.dat文件的编码格式,在保存时保存编码格式为UTF-8即可;
Variable Names(comma-delimited):对应参数文件每列的变量名,类似excel文件的文件头,起到标示作用,同时也是后续引用的标识符,建议采用有意义的英文标示; (如:有几列参数,在这里面就写几个参数名称,每个名称中间用分隔符分割,这里的 user,pwd,可以被利用变量名来引用: u s e r , {user}, user,{pwd};
Delimitet:参数文件分隔符,用来在“Variable Names”中分隔参数,与参数文件中的分隔符保持一致即可;
Allow quote data:是否允许引用数据,默认false,选项选为“true”的时候对全角字符的处理出现乱码 ;
Recycle on EOF?:是否循环读取参数文件内容;因为CSV Data Set Config一次读入一行,分割后存入若干变量中交给一个线程,如果线程数超过文本的记录行数,那么可以选择从头再次读入;
△ Ture:为true时,当已读取完参数文件内的测试用例数据,还需继续获取用例数据时,此时会循环读取参数文件数据(即:读取文件到结尾时,再重头读取文件);
△False:为false时,若已至文件末尾,则不再继续读取测试数据;通常在“线程组线程数* 线程组循环次数>参数文件行数”时,选用false(即:读取文件到结尾时,停止读取文件);
Stop thread on EOF?:当Recycle on EOF为False时(读取文件到结尾),停止进程,当Recycle on EOF为True时,此项无意义;
△若为ture,则在读取到参数文件行末尾时,终止参数文件读取线程;
△若为false,此时线程继续读取,但会请求错误,因此时读取的数据为EOF;
Sharing mode:共享模式,即参数文件的作用域,有以下几种方式:
△All threads:当前测试计划中的所有线程中的所有的线程都有效,默认;
如果脚本有多个线程组,在这种模式下,各线程组的所有线程也要依次唯一顺序取值。
△Current thread group:当前线程组中的线程有效;
各个线程组之间隔离,线程组内的线程顺序唯一取值。
△Current thread:当前线程有效;三、配置元件——User Defined Variables
点击线程组添加配置元件→ User Defined Variables(用户定义的变量)
PS:User Defined Variables中定义的参数值在test plan执行过程中不能发生取值的改变,因此一般仅将test plan中不需要随迭代发生改变的参数(只取一次的参数)设置在此处;例如:被测应用的host和port值四、前置处理器——User Variables
点击线程组添加前置处理器——User Variables(用户参数)
PS:User Variables中设置的参数可以在test plan执行过程中发生变化总结:
1、函数助手_CSVRead的参数化功能相比CSV Data Set Config较弱;
2、CSV Data Set Config适用于参数取值范围较大的时候使用,该方法具有更大的灵活性;
3、User Defined Variables一般用于test plan中不需要随请求迭代的参数设置;
4、User Variables适用于参数取值范围很小的时候使用;PS:相比于loadrunner来说,jmeter参数化有以下不同:
1.jmeter参数文件第一行没有列名称
2.参数文件的编码,尽量保存为UTF-8(编码问题在使用CSV Data Set Config参数化时要求的比较严格)
3.Jmeter的参数化没有LoadRunner做的出色,它是依赖于线程设置的(只有CSV Data Set Config参数化方法才有)定时器
定时器的作用域
1、定时器是在每个sampler(采样器)之前执行的,而不是之后(无论定时器位置在sampler之前还是下面);
2、当执行一个sampler之前时,所有当前作用域内的定时器都会被执行;
3、如果希望定时器仅应用于其中一个sampler,则把定时器作为子节点加入;
4、如果希望在sampler执行完之后再等待,则可以使用Test Action;集合点
定时器→同步定时器1、固定定时器(Constant Timer)
让每个线程在请求之前按相同的指定时间停顿。固定定时器的延时不会计入单个sampler的响应时间,但会计入事务控制器的时间。
对于“java请求”这个sampler来说,定时器相当于loadrunner中的pacing(两次迭代之间的间隔时间);
对于“事务控制器”来说,定时器相当于loadrunner中的think time(思考时间:实际操作中,模拟真实用户在操作过程中的等待时间)2、高斯随机定时器(Gaussian Random Timer)
如需要每个线程在请求前按随机时间停顿,那么使用这个定时器,上图表示暂停时间会分布在100到400之间,计算公式参考:Math.abs((this.random.nextGaussian() * 300) + 100)
3、均匀随机定时器(Uniform Random Timer)
和高斯随机定时器的作用差异不大,区别在于延时时间在指定范围内且每个时间的取值概率相同,每个时间间隔都有相同的概率发生,总的延迟时间就是随机值和偏移值之和。
(1)Random Delay Maximum(in milliseconds):随机延迟时间的最大毫秒数
(2)Constant Delay Offset(in milliseconds):暂停的毫秒数减去随机延迟的毫秒数4、固定吞吐量定时器(Constant Throughput Timer)
可以让JMeter以指定数字的吞吐量(即指定TPS,只是这里要求指定每分钟的执行数,而不是每秒)执行。
吞吐量计算的范围可以为指定为当前线程、当前线程组、所有线程组等范围,并且计算吞吐量的依据可以是最近一次线程的执行时延。这种定时器在特定的场景下,还是很有用的。5、同步定时器(Synchronizing Timer)
和loadrunner当中的集合点(rendezvous point)作用相似,其作用是:阻塞线程,直到指定的线程数量到达后,再一起释放,可以瞬间产生很大的压力。
(1)Number of Simulated Users to Group by:模拟用户的数量,即指定同时释放的线程数数量
(2)Timeout in milliseconds:超时时间,即超时多少毫秒后同时释放指定的线程数6、BeanShell定时器(BeanShell Timer)
BeanShell是一种松散类型的脚本语言(这点和JS类似),一种完全符合java语法的java脚本语言,并且又拥有自己的一些语法和方法。
7、泊松随机定时器(Poisson Random Timer)
在每个线程请求之前按随机的时间停顿,大部分的时间间隔出现在一个特定的值,总的延迟就是泊松分布值和偏移值之和。
(1)Lambda(in milliseconds):兰布达值
(2)Constant Delay Offset(in milliseconds):暂停的毫秒数减去随机延迟的毫秒数8、JSR223定时器(JSR223 Timer)
这个定时器相当于BeanShell定时器的“父集”,它可以使用java、JavaScript、beanshell等多种语言去实现你希望完成的事情
9、BSF定时器(BSF Timer)
使用方法和JSR223 Timer很相似,只需要在jmeter的lib文件夹导入其jar包,就可以支持脚本语言直接访问Java对象和方法的一定时器。
关联
方法一:正则表达式提取器
方法二:jp@gc - JSON Path Extractor提取器
方式三:Json Extractor提取器
方式四:边界提取器
方式五:beanshell后置处理器正则表达式提取器
说明:
后置处理器:在请求结束或者返回响应结果时发挥作用
正则表达式提取器:允许用户从服务器的响应中通过使用perl的正则表达式提取值。该元素会作用在指定范围取样器,用正则表达式提取所需值,生成模板字符串,并将结果存储到给定的变量名中。APPly to:作用范围(返回内容的断言范围)
Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
Main sample only:仅作用于父节点的取样器
Sub-samples only:仅作用于子节点的取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)要检查的响应字段:需要检查的响应报文的范围
主体:响应报文的主体
Body(unescaped):主体,响应的主体内容且替换了所有的html转义符,注意html转义符处理时不考虑上下文,因此可能有不正确的转换,不太建议使用
Body as a Document:从不同类型的文件中提取文本,注意这个选项比较影响性能
Response Headers:响应信息头
Request Headers:请求信息头
URL:统一资源定位符,即Internet上用来描述信息资源的字符串
Response Code:响应状态码,比如200、404等
Response Message:响应信息引用名称(Reference Name):Jmeter变量的名称,存储提取的结果;即下个请求需要引用的值、字段、变量名(例子中我提取的是SOCIAL_NO)
引用方法:引用方法:${引用名称}
正则表达式(Regular Expression):使用正则表达式解析响应结果,“()”表示提取字符串中的部分值,请不要使用“||”,除非你本身需要匹配这个字符。
‘csrfToken’:‘(.+?)’
‘csrfToken’:‘(.*?)’下面是常用的正则表达式操作符:
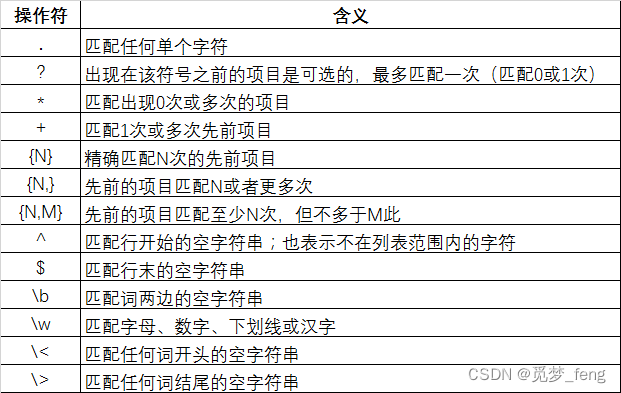
模板(Template):从匹配的结果中创建一个字符串,这是通过正则表达式匹配出来的一组值,意为使用提取到的第几个值(可能有多个值匹配,因此使用模板);从1开始匹配,以此类推.
参数可以在取值模板组合使用,例如:“1-2”作为模板得到的值是使用“-”连接的第一个待匹配内容与第二个待匹配内容组合而成的字符串。匹配数字(Match No):正则表达式匹配数据的结果可以看做一个数组,表示如何取值:0代表随机取值,正数n则表示取第n个值(比如1代表取第一个值),负数则表示提取所有符合条件的值。
缺省值:匹配失败时候的默认值;通常用于后续的逻辑判断,一般通常为特定含义的英文大写组合,比如:ERROR
最后,根据上面的说明,完成配置,然后可以先添加一个监视器(查看结果树),检查是否取到了对应的值;
提取到的参数,调用时用 S O C I A L N O 1 , {SOCIAL_NO_1}, SOCIALNO1,{SOCIAL_NO_2}…,如果想要得到匹配出的参数的个数,用 S O C I A L N O m a t c h N r ,如果想随机选取一个,只需要将匹配数字设为 0 ,使用 {SOCIAL_NO_matchNr},如果想随机选取一个,只需要将 匹配数字设为0,使用 SOCIALNOmatchNr,如果想随机选取一个,只需要将匹配数字设为0,使用{SOCIAL_NO}调用即可。事务控制器
作用:生成一个额外的采样器来测量其下测试元素的总体时间;值得注意的是,这个时间包含该控制器范围内的所有处理时间,而不仅仅是采样器的
Generate parent sample:生成父样本(不同的模式选择)
include duration of timer and pre-post processors in generated sample:包含时间的计时器和前后处理器生成的示例(不同的模式选择)
对于Jmeter2.3以上的版本,有两种模式的操作
①.事务采样器是添加到其下采样器后面的
②.事务采样器是作为其下采样器的父采样器生成的事务采样器的测量的时间包括其下采样器以及其他的一切时间。由于时钟频率问题,这个时间可能略大于单个采样器的时间之和;
时钟开始时间介于控制器记录开始时间与第一个采样器开始之间,时钟结束时间亦然。
事务采样器只有在其子采样器都成功的情况下才显示成功。在父模式下,事务控制器下的各个采样器只有在结果树里才能看到;同时,子采样器的数据也不会在CSV文件中显示,但是在XML文件中可以看到。
-
相关阅读:
Codeforces暑期训练周报(8.22~8.28)
荷兰国旗问题与快速排序算法
Qt5开发及实例V2.0-第二章Qt模板库工具类及控件
Spring Boot整合Minio实现文件上传和读取
[数据结构] 树与二叉树
小程序导航栏透明,精准设置小程序自定义标题的高度和定位
nginx配置指南
利用AI+大数据的方式分析恶意样本(四十一)
SEO方案尝试--Nuxtjs项目基础配置
线性回归
- 原文地址:https://blog.csdn.net/weixin_43820813/article/details/126818839