-
【博客486】prometheus-----rate,irate,increase的原理
prometheus-----rate,irate,increase的原理
三者综合比较
这三个函数接受的都是 Range Vector,返回的是 Instant Vector,比较常用。
区别:
rate计算指定时间范围内:增量/时间范围; irate计算指定时间范围内:最近两个点的增量/最近两个点的时间差;- 1
- 2
场景:
irate适合计算快速变化的counter,它可以反映出counter的快速变化; rate适合计算缓慢变化的counter,它用平均值将峰值削平了(长尾效应);- 1
- 2
1、increase()
increase(v range-vector) 函数获取区间向量中的第一个和最后一个样本并返回其增长量,它会在单调性发生变化时(如由于采样目标重启引起的计数器复位)自动中断。
例如,以下表达式返回区间向量中每个时间序列过去 5 分钟内 HTTP 请求数的增长数:
increase(http_requests_total{job="apiserver"}[5m])- 1
该函数配合counter数据类型使用,它的返回值类型只能是计数器类型。
此函数和 rate() 完全一样,只是它没有将最终单位转换为 “每秒”(1/s)。每个规定的采样周期就是它的最终单位。
例如:increase(http_requests_total[5m]) 得出的是5分钟的采样周期内处理完成的HTTP请求的总增长量(单位1/5m)。因此increase(foo[5m])/ (5 * 60) 等同于rate(foo[5m])。2、rate()
rate(v range-vector) 函数可以直接计算区间向量 v 在时间窗口内平均每秒增长速率,它会在单调性发生变化时(如由于采样目标重启引起的计数器复位)自动中断。
该函数配合counter数据类型使用,它的返回值类型只能用计数器,在长期趋势分析或者告警中推荐使用这个函数。该函数的返回结果不带有度量指标,只有标签列表。例如,以下表达式返回区间向量中每个时间序列过去 5 分钟内 HTTP 请求数的每秒增长率:
rate(http_requests_total[5m]) 结果: {code="200",handler="label_values",instance="120.77.65.193:9090",job="prometheus",method="get"} 0 {code="200",handler="query_range",instance="120.77.65.193:9090",job="prometheus",method="get"} 0 {code="200",handler="prometheus",instance="120.77.65.193:9090",job="prometheus",method="get"} 0.2 ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
当将 rate() 函数与聚合运算符(例如 sum())或随时间聚合的函数(任何以 _over_time 结尾的函数)一起使用时,必须先执行 rate 函数,然后再进行聚合操作,
否则当采样目标重新启动时 rate() 无法检测到计数器是否被重置。计算方法:
取时间范围内的firstValue和lastValue; 变化率 = (lastValue - firstValue) / Range;- 1
- 2
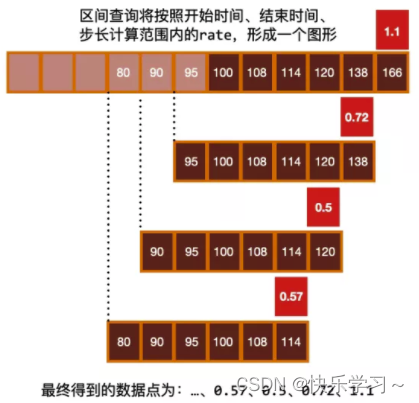
若要计算一段时间内的结果:
对每个数据点,计算(value - valueBeforeRange)/range;- 1
最终得到一串数据,绘制变化率图形;
当抓取指标的进程重启时,counter可能会重置为0,rate()认为指标值只要减少了就认为被重置了,然后它会自动进行调整。
3、irate()
irate(v range-vector) 函数用于计算区间向量的增长率,但是其反应出的是瞬时增长率。
irate 函数是通过区间向量中最后两个两本数据来计算区间向量的增长速率,它会在单调性发生变化时(如由于采样目标重启引起的计数器复位)自动中断。
这种方式可以避免在时间窗口范围内的“长尾问题”,并且体现出更好的灵敏度,通过irate函数绘制的图标能够更好的反应样本数据的瞬时变化状态。例如,以下表达式返回区间向量中每个时间序列过去 5 分钟内最后两个样本数据的 HTTP 请求数的增长率:
irate(http_requests_total{job="api-server"}[5m])- 1
irate 只能用于绘制快速变化的计数器,在长期趋势分析或者告警中更推荐使用 rate 函数。
因为使用 irate 函数时,速率的简短变化会重置 FOR 语句,形成的图形有很多波峰,难以阅读。当将 irate() 函数与聚合运算符(例如 sum())或随时间聚合的函数(任何以 _over_time 结尾的函数)一起使用时,必须先执行 irate 函数,然后再进行聚合操作,
否则当采样目标重新启动时 irate() 无法检测到计数器是否被重置。irate函数相比于rate函数提供了更高的灵敏度,不过当需要分析长期趋势或者在告警规则中,irate的这种灵敏度反而容易造成干扰。因此在长期趋势分析或者告警中更推荐使用rate函数。
需要注意的是使用rate或者increase函数去计算样本的平均增长速率,容易陷入“长尾问题”当中,其无法反应在时间窗口内样本数据的突发变化。 例如,对于主机而言在2分钟的时间窗口内,可能在某一个由于访问量或者其它问题导致CPU占用100%的情况,但是通过计算在时间窗口内的平均增长率却无法反应出该问题。
为了解决该问题,PromQL提供了另外一个灵敏度更高的函数irate(v range-vector)。irate同样用于计算区间向量的计算率,但是其反应出的是瞬时增长率。irate函数是通过区间向量中最后两个样本数据来计算区间向量的增长速率。这种方式可以避免在时间窗口范围内的“长尾问题”,并且体现出更好的灵敏度,通过irate函数绘制的图标能够更好的反应样本数据的瞬时变化状态。
使用rate计算快速变化的样本平均增长率时,容易陷入长尾问题,因为它用平均值将峰值削平了,无法反映时间窗口内样本数据的快速变化。
与rate类似,irate同样可以计算counter的平均增长率,但其反映出的是瞬时增长率。Counter类型的监控指标其特点是只增不减,在没有发生重置(如服务器重启,应用重启)的情况下其样本值应该是不断增大的
irate计算增长率时,使用指定时间范围内的最后两个样本数据:
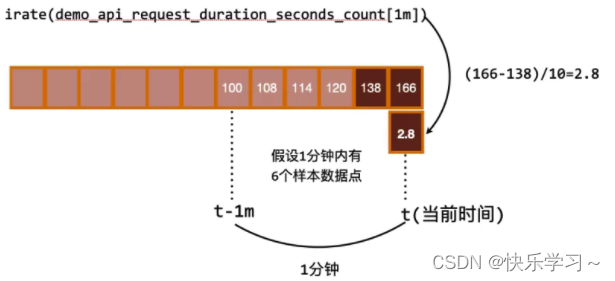
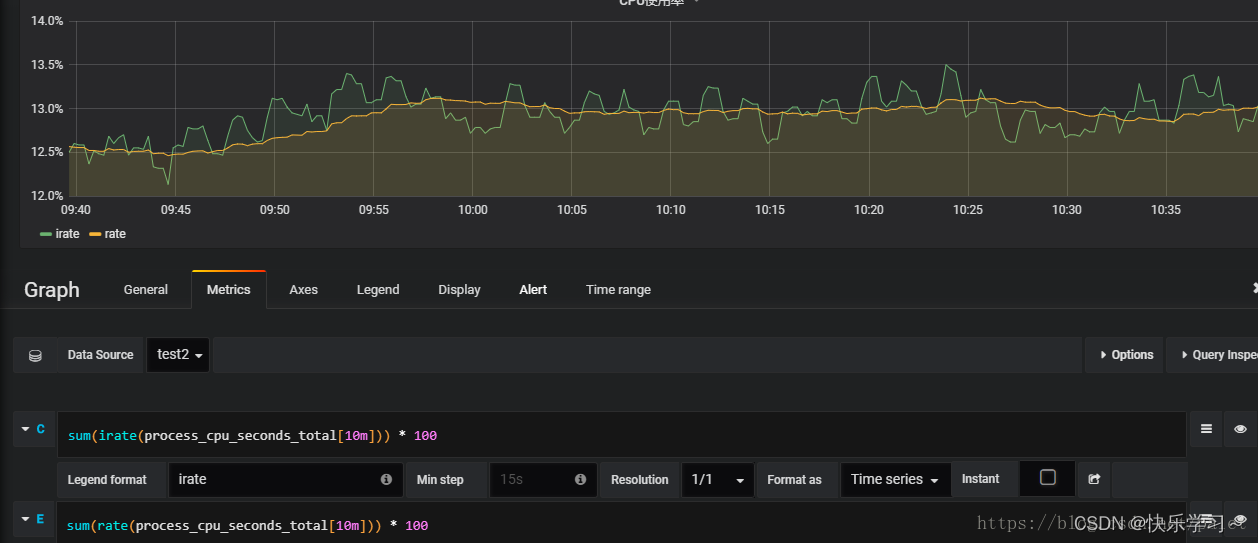
用grafana做了一个试验,创建一个测试的dashboard, 分别用 irate 和 rate 来监控CPU使用率指标,时间间隔分别用10m, 5m, 2m, 1m 。其中间隔为10分钟的表达式如下:
sum(irate(process_cpu_seconds_total[10m])) * 100 sum(rate(process_cpu_seconds_total[10m])) * 100- 1
- 2
- 3
下图是间隔10分钟的结果,可以看到,irate的曲线比较曲折,而rate的曲线相对平缓:
4、irate是取最后两个点去计算的,为什么irate还需要时间区间呢
比如:irate(node_network_receive_packets_total{device=~”en.*”}[1m])
因为只用最后两个点的差值来计算,会比 rate 平均值的方法得到的结果,变化更加剧烈,更能反映当时的情况。那既然是使用最后两个点计算,这里又为什么需要 [1m] 呢?这个 [1m] 不是用来计算的,是用来限制找 t-2 个点的时间的,比如,如果中间丢了很多数据,那么显然这个点的计算会很不准确,irate 在计算的时候会最多向前在 [1m] 找点,如果超过 [1m] 没有找到数据点,这个点的计算就放弃了。
5、是不是我们总是使用 irate 比较好呢
也不是,比如 requests/s 这种,如果变化太剧烈,从面板上你只能看到一条剧烈抖动导致看不清数值的曲线,而具体值我们是不太关心的,我们可能更关心一天中的 QPS 变化情况;但是像是 CPU,network 这种资源的变化,使用 irate 更加有意义一些。
6、查看一个函数的功能以及是接收instant-vector还是range-vector:
https://prometheus.io/docs/prometheus/latest/querying/functions/
7、rate 必须在 sum 之前
rate 必须在 sum 之前。Prometheus 支持在 Counter 的数据有下降之后自动处理的,比如服务器重启了,metric 重新从 0 开始。这个其实不是在存储的时候做的,比如应用暴露的 metric 就是从 2033 变成 0 了,那么 Prometheus 就会忠实地存储 0. 但是在计算 rate 的时候,就会识别出来这个下降。但是 sum 不会,所以如果先 sum 再 rate,曲线就会出现非常大的波动。
sum by (job)(rate(http_requests_total{job="node"}[5m])) # This is okay rate(sum by (job)(http_requests_total{job="node"})[5m]) # Don't do this- 1
- 2
- 3
Even if you’ve worked around this being invalid expression with a recording rule, the real problem is what happens when one of the servers restarts. The counters from the restarted server will reset to 0, the sum will decrease, which will then be treated by rate as a counter reset and you’d get a large spurious spike in the result.
即使您已经使用记录规则解决了这个无效表达式,真正的问题是当其中一台服务器重新
启动时会发生什么。重新启动的服务器中的计数器将重置为 0,总和将减少,然后将被速率视为计数器重置,您会在结果中得到一个很大的虚假峰值。同样的道理:
rate(counter_a[5m] + counter_b[5m]) # Don't do this rate(counter_a[5m]) + rate(counter_b[5m]) # This is okay- 1
- 2
- 3
The only mathematical operations you can safely directly apply to a counter’s values are rate, irate, increase, and resets
唯一可以安全地直接应用于计数器值的数学运算是 rate、irate、increase 和 resets -
相关阅读:
hadoop项目之求出每年二月的最高气温(Combiner优化)
Clearview X for mac v3.5.0 电子书阅读器 兼容 M1/M2/M3
ORA-01005 vs ORA-28040
【Hack The Box】linux练习-- Tabby
【语音识别】在Win11使用Docker部署FunASR服务器
【C语言】用纯C来创建顺序表
MIT 6.858 计算机系统安全讲义 2014 秋季(二)
如何评价微软发布的Phi-3,手机都可以运行的小模型
硬件学习(一)
计算机毕业设计(附源码)python幼儿健康管理系统
- 原文地址:https://blog.csdn.net/qq_43684922/article/details/126814146