-
哈夫曼树实现文件压缩
哈夫曼树
哈夫曼树的数据结构很简单,每一次都将权值最小的两个的节点合成一个更大的节点,然后放到优先级队列里面,如此操作之后,所有的节点都在叶子节点。
#pragma once #include#include #include using namespace std; template <class W> struct HuffmanTreeNode { HuffmanTreeNode(const W &weight) : _pLeft(NULL), _pRight(NULL), _pParent(NULL), _weight(weight) { } HuffmanTreeNode<W> *_pLeft; HuffmanTreeNode<W> *_pRight; HuffmanTreeNode<W> *_pParent; W _weight; }; template <class W> class HuffmanTree { typedef HuffmanTreeNode<W> *PNode; private: PNode _pRoot; public: HuffmanTree() : _pRoot(NULL) { } HuffmanTree(W *array, size_t size) { _CreateHuffmantree(array, size); } void _Destroy(PNode &pRoot) { //后序 if (pRoot) { _Destroy(pRoot->_pLeft); _Destroy(pRoot->_pRight); delete pRoot; pRoot = NULL; } } ~HuffmanTree() { _Destroy(_pRoot); } PNode GetRoot() { return _pRoot; } private: //构建哈夫曼树 void _CreateHuffmantree(W *array, size_t size) { struct PtrNodeCompare { bool operator()(PNode n1, PNode n2) //重载“()” { return n1->_weight < n2->_weight; } }; priority_queue<PNode, vector<PNode>, PtrNodeCompare> hp; // for (size_t i = 0; i < size; ++i) { hp.push(new HuffmanTreeNode<W>(array[i])); // 数据入堆 } //空堆 if (hp.empty()) _pRoot = NULL; while (hp.size() > 1) // 取两个出来只回收1个 { PNode pLeft = hp.top(); hp.pop(); PNode pRight = hp.top(); hp.pop(); PNode pParent = new HuffmanTreeNode<W>(pLeft->_weight + pRight->_weight); //左加右的权值,作为新节点 pParent->_pLeft = pLeft; pLeft->_pParent = pParent; pParent->_pRight = pRight; pRight->_pParent = pParent; hp.push(pParent); } _pRoot = hp.top(); // 根节点在堆顶 } }; - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
用哈夫曼树压缩文件
根据哈夫曼树的特性,我们首先需要统计文件中所有字符(char)的出现次数,生成对应的“码表”(字符+次数),然后码表构建哈夫曼树。码表是我们用来压缩和解压缩的重要数据结构。
以下是对应的字符结构体:
struct CharInfo { unsigned char _ch; //字符 比如字符a unsigned int _count; //字符次数 比如字符a出现45 string _code; //对应的哈夫曼编码 字符a构建的哈夫曼编码为011100 bool operator!=(const CharInfo &info) { return _count != info._count; } CharInfo operator+(const CharInfo &info) { CharInfo ret; ret._count = _count + info._count; return ret; } bool operator>(const CharInfo &info) { return _count > info._count; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
在文件压缩和解压缩的类型中,有以下成员变量和函数:
//获取文件的大小 unsigned long getFileSize(const char *path) { unsigned long filesize = -1; FILE *fp; fp = fopen(path, "r"); if (fp == NULL) { return filesize; } fseek(fp, 0L, SEEK_END); filesize = ftell(fp); fclose(fp); return filesize; } struct CharInfo { unsigned char _ch; //字符 a unsigned int _count; //字符次数 45 string _code; //对应的哈夫曼编码 011100 bool operator!=(const CharInfo &info) { return _count != info._count; } CharInfo operator+(const CharInfo &info) { CharInfo ret; ret._count = _count + info._count; return ret; } bool operator>(const CharInfo &info) { return _count > info._count; } }; class FileCompressAndUnCompress { typedef HuffmanTreeNode<CharInfo> Node; struct TmpInfo { unsigned char _ch; //字符 unsigned int _count; //次数 }; protected: CharInfo _infos[256]; public: //构造函数 FileCompressAndUnCompress() { for (size_t i = 0; i < 256; ++i) { _infos[i]._ch = i; _infos[i]._count = 0; } } //获取哈夫曼编码 void GenerateHuffmanCode(Node *root, string code) { if (root == NULL) return; //前序遍历生成编码 if (root->_pLeft == NULL && root->_pRight == NULL) { _infos[(unsigned char)root->_weight._ch]._code = code; // 码值 return; } GenerateHuffmanCode(root->_pLeft, code + '0'); GenerateHuffmanCode(root->_pRight, code + '1'); } void Compress(const char *file); void Uncompress(const char *file); };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
压缩
void Compress(const char *file) // file:要压缩的文件 { //获取文件的大小 unsigned long fileSize = getFileSize(file); // 1.统计字符出现的次数 FILE *fout = fopen(file, "rb"); assert(fout); char ch = fgetc(fout); while (feof(fout) == 0) //文件结束,则返回值为1,否则为0 { _infos[(unsigned char)ch]._count++; // 计算对应字符出现的频率 ch = fgetc(fout); } // 2.生成Huffmantree 及code // 2.1 生成Huffmantree, 构建哈夫曼树 HuffmanTree<CharInfo> tree(_infos, 256); string compressfile = file; compressfile += ".huffman"; FILE *fin = fopen(compressfile.c_str(), "wb"); //打开压缩文件 assert(fin); string code; // 2.2 根据哈夫曼树每个字符对应的code GenerateHuffmanCode(tree.GetRoot(), code); // 2.3 将码表写入压缩文件中 int writeNum = 0; int objSize = sizeof(TmpInfo); for (size_t i = 0; i < 256; ++i) { if (_infos[i]._count > 0) { TmpInfo info; info._ch = _infos[i]._ch; info._count = _infos[i]._count; printf("codec ch:%u, cout:%u\n", (unsigned char)info._ch, info._count); fwrite(&info, objSize, 1, fin); writeNum++; } } //把info._count = -1写进去作为数据字典的结束标志位 TmpInfo info; info._count = -1; printf("code objSize:%d\n", objSize); fwrite(&info, objSize, 1, fin); // 3.开始压缩文件 int writeCount = 0; int readCount = 0; //文件指针回到开头 fseek(fout, 0, SEEK_SET); //文件指针、偏移量、参照位置 ch = fgetc(fout); readCount++; unsigned char value = 0; size_t pos = 0; while (feof(fout) == 0) // 一个个字符读取 { // 读取数据,查找对应编码 string &code = _infos[(unsigned char)ch]._code; // 查找对应的编码 printf("code[%d]:%u:%s\n", readCount, (unsigned char)ch, code.c_str()); // 根据对应的编码,修改对应的value值 for (size_t i = 0; i < code.size(); ++i) { if (code[i] == '1') { value |= (1 << pos); } else if (code[i] != '0') { assert(false); printf("assert(false); ??????????"); } ++pos; if (pos == 8) { writeCount++; // 够8个bit就存储一次,不用担心code是否全部读完 fputc(value, fin); value = 0; pos = 0; } } readCount++; ch = fgetc(fout); } //最后可能不够8bit,也存储进去 if (pos > 0) { writeCount++; fputc(value, fin); //写入压缩文件(fin) } printf("码表的大小:%d字节\n", objSize * (writeNum + 1)); printf("压缩后的文件大小:%d字节\n", writeCount); unsigned long totalSize = writeCount + objSize * (writeNum + 1); printf("压缩后总文件大小:%lu字节, 原始文件大小:%lu字节, 压缩率:%0.2f\n", totalSize, fileSize, (float)(totalSize * 1.0 / fileSize)); fclose(fout); fclose(fin); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
以下面的测试文件为例:

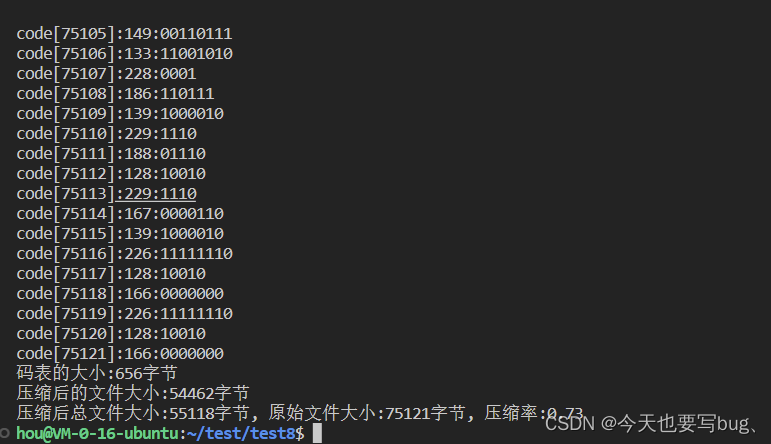
如果压缩文件中相同字符的重复率很高,那压缩效率会大幅提高:
以全部为1的文件为例:

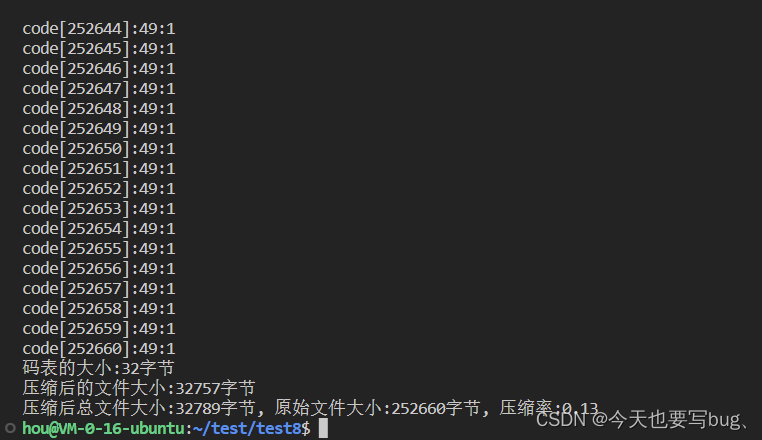
解压缩
void Uncompress(const char *file) //要解压缩的文件 { string uncompressfile = file; //找到最后一个'.' size_t pos = uncompressfile.rfind('.'); assert(pos != string::npos); //删除掉".huffman"后缀 uncompressfile.erase(pos); // uncompressfile += ".unhuffman"; FILE *fin = fopen(uncompressfile.c_str(), "wb"); //打开解压缩文件 assert(fin); FILE *fout = fopen(file, "rb"); //打开压缩文件 assert(fout); // 读入码表 TmpInfo info; int cycleNum = 1; int objSize = sizeof(TmpInfo); fread(&info, objSize, 1, fout); while (info._count != -1) //-1为结束标志 { _infos[(unsigned char)info._ch]._ch = info._ch; _infos[(unsigned char)info._ch]._count = info._count; fread(&info, objSize, 1, fout); cycleNum++; } //根据码表重建huaffman树 HuffmanTree<CharInfo> tree(_infos, 256); //参数:数组,256个,无效值(出现0次) Node *root = tree.GetRoot(); Node *cur = root; unsigned int n = root->_weight._count; //所有叶子节点的和(源文件字符的个数) char ch = fgetc(fout); //从fout(压缩文件)读字符 int readCount = 0; while (ch != EOF || n > 0) { for (size_t i = 0; i < 8; ++i) { if ((ch & (1 << i)) == 0) cur = cur->_pLeft; // 往左边找 else cur = cur->_pRight; // 往右边找 if (cur->_pLeft == NULL && cur->_pRight == NULL) { // cout << cur->_weight._ch; //找到对应的字符,写入解压缩文件 fputc(cur->_weight._ch, fin); cur = root; if (--n == 0) break; } } ch = fgetc(fout); } printf("解压缩完成\n"); fclose(fin); fclose(fout); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
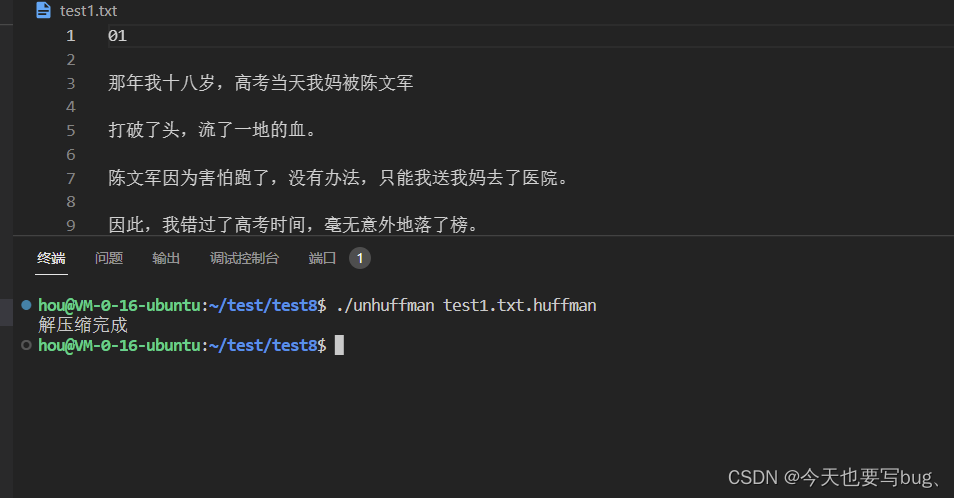
对上面的压缩文件进行解压缩:

全部代码
- HuffmanTree.hpp:
#pragma once #include#include #include using namespace std; template <class W> struct HuffmanTreeNode { HuffmanTreeNode(const W &weight) : _pLeft(NULL), _pRight(NULL), _pParent(NULL), _weight(weight) { } HuffmanTreeNode<W> *_pLeft; HuffmanTreeNode<W> *_pRight; HuffmanTreeNode<W> *_pParent; //权值 W _weight; }; template <class W> class HuffmanTree { typedef HuffmanTreeNode<W> *PNode; private: //根节点 PNode _pRoot; public: HuffmanTree() : _pRoot(NULL) { } HuffmanTree(W *array, size_t size) { _CreateHuffmantree(array, size); } void _Destroy(PNode &pRoot) { //后序 if (pRoot) { _Destroy(pRoot->_pLeft); _Destroy(pRoot->_pRight); delete pRoot; pRoot = NULL; } } ~HuffmanTree() { _Destroy(_pRoot); } PNode GetRoot() { return _pRoot; } private: //构建哈夫曼树 void _CreateHuffmantree(W *array, size_t size) { //小根堆 struct PtrNodeCompare { bool operator()(PNode n1, PNode n2) //重载“()” { return n1->_weight > n2->_weight; } }; priority_queue<PNode, vector<PNode>, PtrNodeCompare> hp; for (size_t i = 0; i < size; ++i) { hp.push(new HuffmanTreeNode<W>(array[i])); // 数据入堆 } //空堆 if (hp.empty()) { _pRoot = NULL; } while (hp.size() > 1) // 取两个出来只回收1个 { PNode pLeft = hp.top(); hp.pop(); PNode pRight = hp.top(); hp.pop(); PNode pParent = new HuffmanTreeNode<W>(pLeft->_weight + pRight->_weight); //左加右的权值,作为新节点 pParent->_pLeft = pLeft; pLeft->_pParent = pParent; pParent->_pRight = pRight; pRight->_pParent = pParent; hp.push(pParent); } _pRoot = hp.top(); // 根节点在堆顶 } }; - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- FileCompress.hpp(压缩和解压缩的头文件)
/*利用库中的优先级队列实现哈夫曼树,最后基于哈夫曼树最终实现文件压缩。 描述: 1.统计文件中字符出现的次数,利用优先级队列构建Haffman树,生成Huffman编码。 构造过程可以使用priority_queue辅助,每次pq.top()都可以取出权值(频数)最小的节点。每取出两个最小权值的节点,就new出一个新的节点,左右孩子分别指向它们。然后把这个新节点push进优先队列。 2.压缩:利用Haffman编码对文件进行压缩,即在压缩文件中按顺序存入每个字符的Haffman编码。 3.将文件中出现的字符以及它们出现的次数写入配置文件中,以便后续压缩使用。 4.解压缩:利用配置文件重构Haffman树,对文件进行减压缩。 */ #pragma once #include "HuffmanTree.hpp" #include#include #include using namespace std; //获取文件的大小 unsigned long getFileSize(const char *path) { unsigned long filesize = -1; FILE *fp; fp = fopen(path, "r"); if (fp == NULL) { return filesize; } fseek(fp, 0L, SEEK_END); filesize = ftell(fp); fclose(fp); return filesize; } struct CharInfo { unsigned char _ch; //字符 a unsigned int _count; //字符次数 45 string _code; //对应的哈夫曼编码 011100 bool operator!=(const CharInfo &info) { return _count != info._count; } CharInfo operator+(const CharInfo &info) { CharInfo ret; ret._count = _count + info._count; return ret; } bool operator>(const CharInfo &info) { return _count > info._count; } }; class FileCompressAndUnCompress { typedef HuffmanTreeNode<CharInfo> Node; struct TmpInfo { unsigned char _ch; //字符 unsigned int _count; //次数 }; protected: CharInfo _infos[256]; public: //构造函数 FileCompressAndUnCompress() { for (size_t i = 0; i < 256; ++i) { _infos[i]._ch = i; _infos[i]._count = 0; } } //获取哈夫曼编码 void GenerateHuffmanCode(Node *root, string code) { if (root == NULL) return; //前序遍历生成编码 if (root->_pLeft == NULL && root->_pRight == NULL) { _infos[(unsigned char)root->_weight._ch]._code = code; // 码值 return; } GenerateHuffmanCode(root->_pLeft, code + '0'); GenerateHuffmanCode(root->_pRight, code + '1'); } void Compress(const char *file) // file:要压缩的文件 { //获取文件的大小 unsigned long fileSize = getFileSize(file); // 1.统计字符出现的次数 FILE *fout = fopen(file, "rb"); assert(fout); char ch = fgetc(fout); while (feof(fout) == 0) //文件结束,则返回值为1,否则为0 { _infos[(unsigned char)ch]._count++; // 计算对应字符出现的频率 ch = fgetc(fout); } // 2.生成Huffmantree 及code // 2.1 生成Huffmantree, 构建哈夫曼树 HuffmanTree<CharInfo> tree(_infos, 256); string compressfile = file; compressfile += ".huffman"; FILE *fin = fopen(compressfile.c_str(), "wb"); //打开压缩文件 assert(fin); string code; // 2.2 根据哈夫曼树每个字符对应的code GenerateHuffmanCode(tree.GetRoot(), code); // 2.3 将码表写入压缩文件中 int writeNum = 0; int objSize = sizeof(TmpInfo); for (size_t i = 0; i < 256; ++i) { if (_infos[i]._count > 0) { TmpInfo info; info._ch = _infos[i]._ch; info._count = _infos[i]._count; printf("codec ch:%u, cout:%u\n", (unsigned char)info._ch, info._count); fwrite(&info, objSize, 1, fin); writeNum++; } } //把info._count = -1写进去作为数据字典的结束标志位 TmpInfo info; info._count = -1; printf("code objSize:%d\n", objSize); fwrite(&info, objSize, 1, fin); // 3.开始压缩文件 int writeCount = 0; int readCount = 0; //文件指针回到开头 fseek(fout, 0, SEEK_SET); //文件指针、偏移量、参照位置 ch = fgetc(fout); readCount++; unsigned char value = 0; size_t pos = 0; while (feof(fout) == 0) // 一个个字符读取 { // 读取数据,查找对应编码 string &code = _infos[(unsigned char)ch]._code; // 查找对应的编码 printf("code[%d]:%u:%s\n", readCount, (unsigned char)ch, code.c_str()); // 根据对应的编码,修改对应的value值 for (size_t i = 0; i < code.size(); ++i) { if (code[i] == '1') { value |= (1 << pos); } else if (code[i] != '0') { assert(false); printf("assert(false); ??????????"); } ++pos; if (pos == 8) { writeCount++; // 够8个bit就存储一次,不用担心code是否全部读完 fputc(value, fin); value = 0; pos = 0; } } readCount++; ch = fgetc(fout); } //最后可能不够8bit,也存储进去 if (pos > 0) { writeCount++; fputc(value, fin); //写入压缩文件(fin) } printf("码表的大小:%d字节\n", objSize * (writeNum + 1)); printf("压缩后的文件大小:%d字节\n", writeCount); unsigned long totalSize = writeCount + objSize * (writeNum + 1); printf("压缩后总文件大小:%lu字节, 原始文件大小:%lu字节, 压缩率:%0.2f\n", totalSize, fileSize, (float)(totalSize * 1.0 / fileSize)); fclose(fout); fclose(fin); } void Uncompress(const char *file) //要解压缩的文件 { string uncompressfile = file; //找到最后一个'.' size_t pos = uncompressfile.rfind('.'); assert(pos != string::npos); //删除掉".huffman"后缀 uncompressfile.erase(pos); // uncompressfile += ".unhuffman"; FILE *fin = fopen(uncompressfile.c_str(), "wb"); //打开解压缩文件 assert(fin); FILE *fout = fopen(file, "rb"); //打开压缩文件 assert(fout); // 读入码表 TmpInfo info; int cycleNum = 1; int objSize = sizeof(TmpInfo); fread(&info, objSize, 1, fout); while (info._count != -1) //-1为结束标志 { _infos[(unsigned char)info._ch]._ch = info._ch; _infos[(unsigned char)info._ch]._count = info._count; fread(&info, objSize, 1, fout); cycleNum++; } //根据码表重建huaffman树 HuffmanTree<CharInfo> tree(_infos, 256); //参数:数组,256个,无效值(出现0次) Node *root = tree.GetRoot(); Node *cur = root; unsigned int n = root->_weight._count; //所有叶子节点的和(源文件字符的个数) char ch = fgetc(fout); //从fout(压缩文件)读字符 int readCount = 0; while (ch != EOF || n > 0) { for (size_t i = 0; i < 8; ++i) { if ((ch & (1 << i)) == 0) cur = cur->_pLeft; // 往左边找 else cur = cur->_pRight; // 往右边找 if (cur->_pLeft == NULL && cur->_pRight == NULL) { // cout << cur->_weight._ch; //找到对应的字符,写入解压缩文件 fputc(cur->_weight._ch, fin); cur = root; if (--n == 0) break; } } ch = fgetc(fout); } printf("解压缩完成\n"); fclose(fin); fclose(fout); } }; - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- compress.cpp(压缩文件)
#include "FileCompress.hpp" #include#include #include int main(int argc, char **argv) { if (argc != 2) { std::cout << "usage: " << argv[0] << ": " << std::endl; return 1; } FileCompressAndUnCompress fc; std::string fileName(argv[1]); fc.Compress(fileName.c_str()); // 压缩文件 return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- uncompress.cpp(解压缩文件)
#include "FileCompress.hpp" #include#include #include int main(int argc, char **argv) { if (argc != 2) { std::cout << "usage: " << argv[0] << ": " << std::endl; return 1; } FileCompressAndUnCompress fc; std::string fileName(argv[1]); fc.Uncompress(fileName.c_str()); // 解压缩文件 return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
-
相关阅读:
PHP NBA球迷俱乐部系统Dreamweaver开发mysql数据库web结构php编程计算机网页
苹果平板HOME键成历史,全面屏时代到来?2024平板电脑市场趋势分析
Python爬虫和数据分析,石油原油加工产品产量数据处理分析
【云原生 | Docker 高级篇】03、搭建 Redis 3主3从集群
C++之sqlite数据库读写
java计算机毕业设计台球收费管理系统设计与实现MyBatis+系统+LW文档+源码+调试部署
单片机卡死的几大原因、分析、解决
Unity的IPreprocessBuildWithReport:深入解析与实用案例
台湾SSS鑫创SSS1700替代Cmedia CM6533 24bit 96KHZ USB音频编解码芯片
【接口自动化测试】HTTP协议详解
- 原文地址:https://blog.csdn.net/qq_52670477/article/details/126800695
