-
doris通关之概念、架构篇
doris基本概念
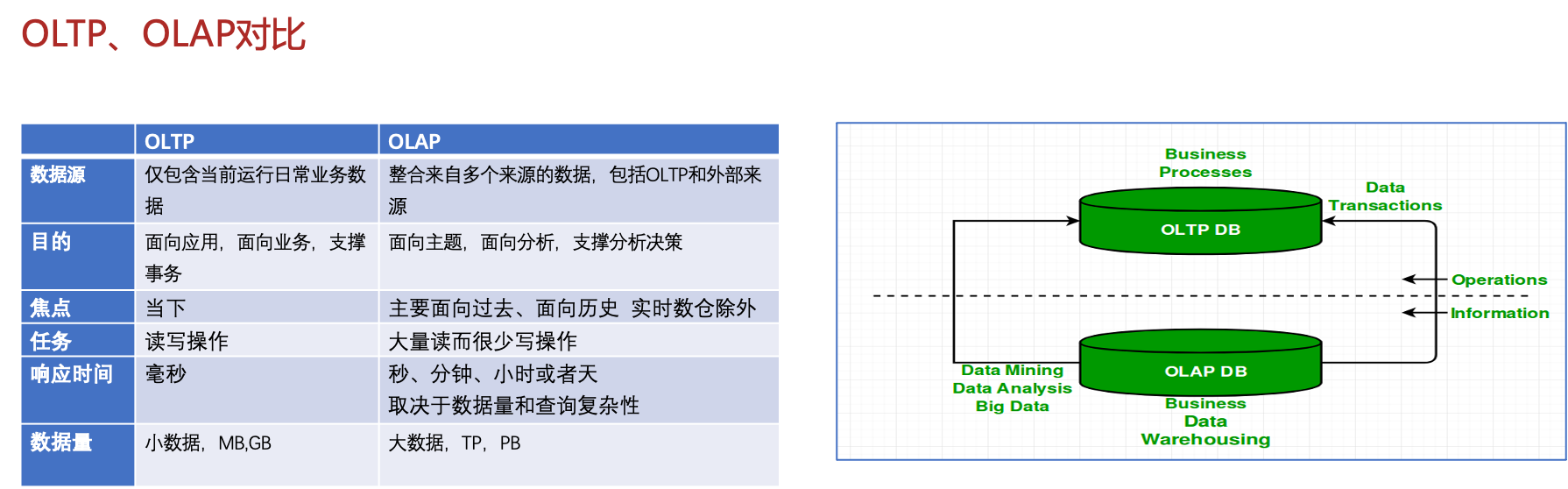
1.OLTP和OLAP概念
OLTP是 Online Transaction Processing 的简称;OLAP 是 OnLine Analytical Processing 的简称
OLTP的查询一般只会访问少量的记录,且大多时候都会利用索引。比如最常见的基于主键的 CRUD 操作
OLAP 的查询一般需要 Scan 大量数据,大多时候只访问部分列,聚合的需求(Sum,Count,Max,Min 等)会多于明细的需求(查询原始的明细数据)
1.1.OLAP分类
- MOLAP:通过预计算,提供稳定的切片数据,实现多次查询一次计算,减轻了查询时的计算压力,保证了查询的稳定性,是“空间换时间”的最佳路径。实现了基于Bitmap的去重算法,支持在不同维度下去重指标的实时统计,效率较高。
- ROLAP:基于实时的大规模并行计算,对集群的要求较高。MPP引擎的核心是通过将数据分散,以实现CPU、IO、内存资源的分布,来提升并行计算能力。在当前数据存储以磁盘为主的情况下,数据Scan需要的较大的磁盘IO,以及并行导致的高CPU,仍然是资源的短板。因此,高频的大规模汇总统计,并发能力将面临较大挑战,这取决于集群硬件方面的并行计算能力。传统去重算法需要大量计算资源,实时的大规模去重指标对CPU、内存都是一个巨大挑战。目前Doris最新版本已经支持Bitmap算法,配合预计算可以很好地解决去重应用场景。

1.2.MOLAP和ROLAP对比
a.MOLAP模式的劣势(以Kylin为例)
- 应用层模型复杂,根据业务需要以及Kylin生产需要,还要做较多模型预处理。这样在不同的业务场景中,模型的利用率也比较低。
- 由于MOLAP不支持明细数据的查询,在“汇总+明细”的应用场景中,明细数据需要同步到DBMS引擎来响应交互,增加了生产的运维成本。
- 较多的预处理伴随着较高的生产成本。
b.ROLAP模式的优势
- 应用层模型设计简化,将数据固定在一个稳定的数据粒度即可。比如商家粒度的星形模型,同时复用率也比较高。
- App层的业务表达可以通过视图进行封装,减少了数据冗余,同时提高了应用的灵活性,降低了运维成本。
- 同时支持“汇总+明细”。
- 模型轻量标准化,极大的降低了生产成本。
综上所述,在变化维、非预设维、细粒度统计的应用场景下,使用MPP引擎驱动的ROLAP模式,可以简化模型设计,减少预计算的代价,并通过强大的实时计算能力,可以支撑良好的实时交互体验。
1.3.对比其他的OLAP系统
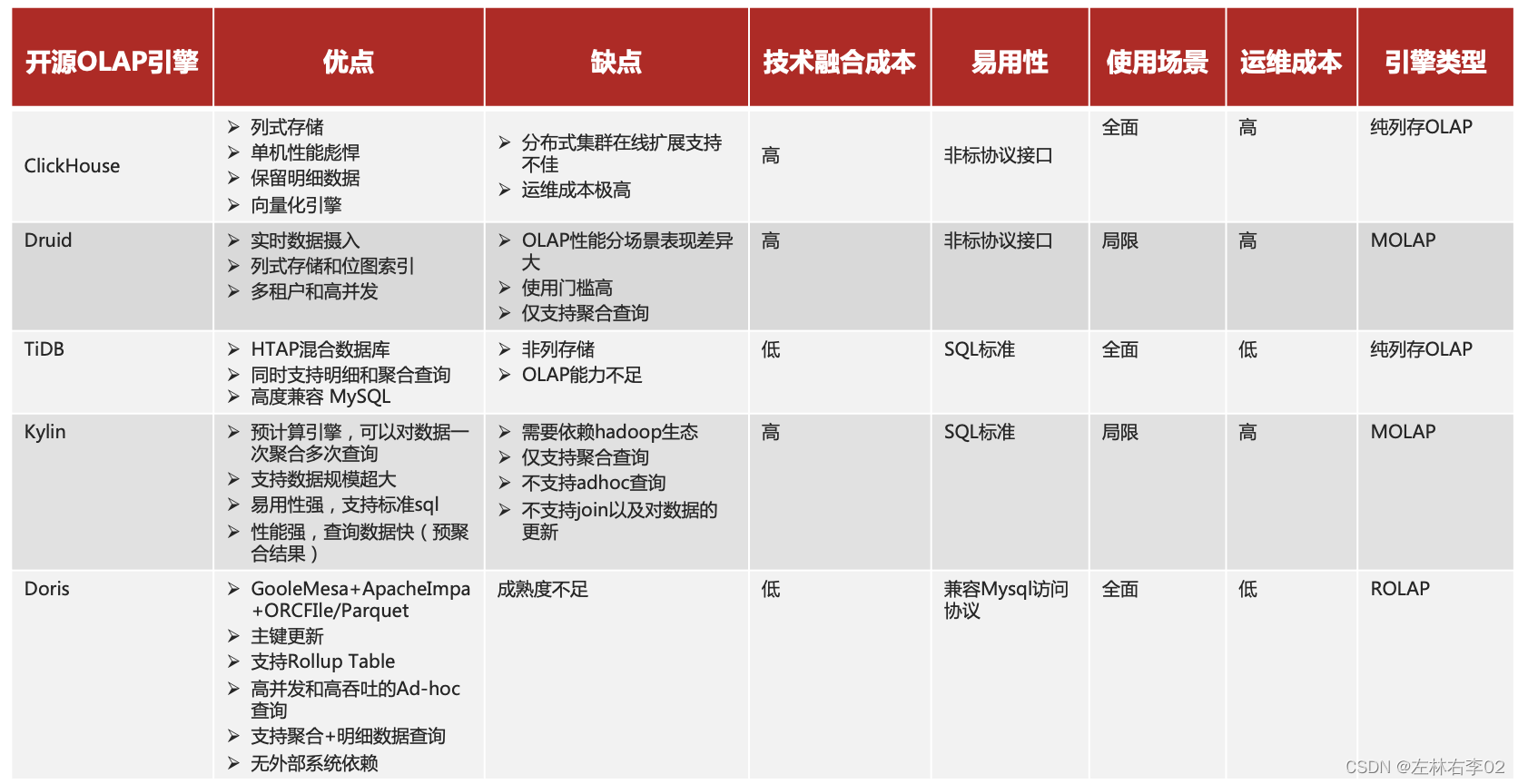
2.doris架构
Doris主要整合了Google Mesa(数据模型),Apache Impala(MPP Query Engine)和Apache ORCFile (存储格式,编码和压缩) 的技术

为什么要将这三种技术整合?
- Mesa可以满足我们许多存储需求的需求,但是Mesa本身不提供SQL查询引擎。
- Impala是一个非常好的MPP SQL查询引擎,但是缺少完美的分布式存储引擎。
- 自研列式存储:存储层对存储数据的管理通过storage_root_path路径进行配置,路径可以是多个。存储目录下一层按照分桶进行组织,分桶目录下存放具体的tablet,按照tablet_id命名子目录。
因此选择了这三种技术的组合。
Doris的系统架构如下,Doris主要分为FE和BE两个组件:

Doris的架构很简洁,使用MySQL协议,用户可以使用任何MySQL ODBC/JDBC和MySQL客户端直接访问Doris,只设FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运维。- FE:Frontend,即 Doris 的前端节点。主要负责接收和返回客户端请求、元数据以及集群管理、查询计划生成等工作
- BE:Backend,即 Doris 的后端节点。主要负责数据存储与管理、查询计划执行等工作。
FE,BE都可线性扩展
2.1.FE的两种角色
FE主要有两个角色,一个是follower,另一个是observer。多个follower组成选举组,会选出一个master,master是follower的一个特例,Master跟follower,主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
Observer节点仅从 leader (master)节点进行元数据同步,不参与选举。可以横向扩展以提供元数据的读服务的扩展性。
数据的可靠性由BE保证,BE会对整个数据存储多副本或者是三副本。副本数可根据需求动态调整。
2.1.1.follower个数为什么要是奇数?
一条元数据日志需要在多数 Follower 节点写入成功,才算成功。比如3个 FE ,2个写入成功才可以。这也是为什么 Follower 角色的个数需要是奇数的原因。

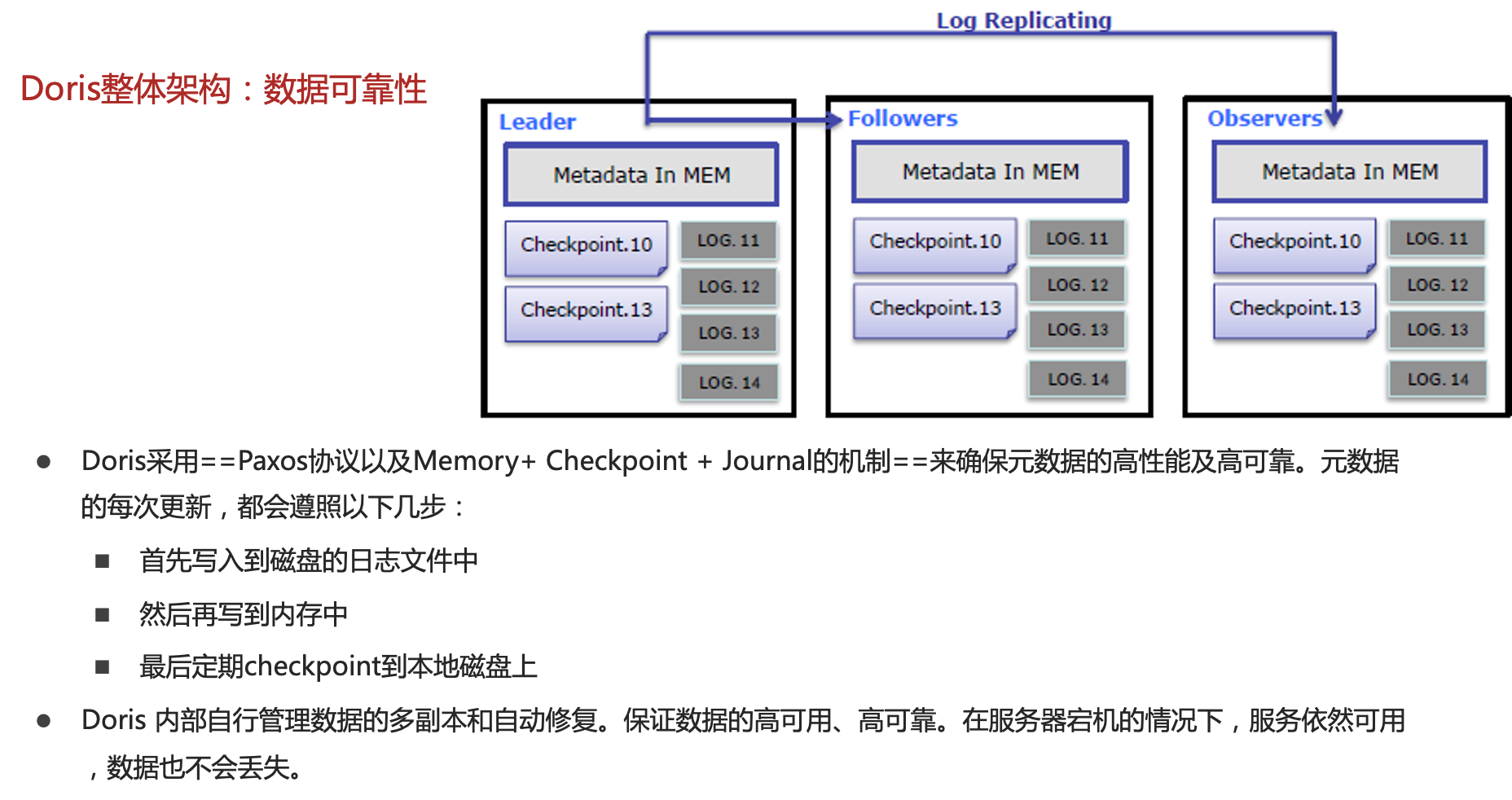
2.2.元数据管理及数据可靠性
Doris采用Paxos协议以及Memory+ Checkpoint + Journal的机制来确保元数据的高性能及高可靠。元数据的每次更新,都会遵照以下几步:- 首先写入到磁盘的日志文件中
- 然后再写到内存中
- 最后定期checkpoint到本地磁盘上
相当于是一个纯内存的一个结构,也就是说所有的元数据都会缓存在内存之中,从而保证FE在宕机后能够快速恢复元数据,而且不丢失元数据。
Leader、follower和 observer它们三个构成一个可靠的服务,如果发生节点宕机的情况,一般是部署一个leader两个follower,目前来说基本上也是这么部署的。就是说三个节点去达到一个高可用服务。单机的节点故障的时候其实基本上三个就够了,因为FE节点毕竟它只存了一份元数据,它的压力不大,所以如果FE太多的时候它会去消耗机器资源,所以多数情况下三个就足够了,可以达到一个很高可用的元数据服务。
-
相关阅读:
三目运算符以及debugger的应用
【Java】JVM内存回收
C语言实现将密码译回原文,并输出密码和原文
MVCC的执行原理
微信小程序_19,自定义组件-behaviors
CSS3 grid 网格/栅格布局
数据库管理-第108期 因Exadata存储节点操作系统空间异常的紧急处理(20230928)
干货分享|腾讯内部项目管理PPT
利用MATLAB数值求解边值问题——Berman问题
《Oracle系列》Oracle利用v$Session中client_info查询登录数据库的终端IP地址
- 原文地址:https://blog.csdn.net/u011624157/article/details/126795161