-
Redis.

NoSQL
概述
NoSQL = Not Only SQL(不仅仅是SQL) ,泛指 non-relational(非关系型数据库)。今天随着互联网web2.0网站的兴起,比如谷歌或 Facebook 每天为他们的用户收集万亿比特的数据,这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展,就是一个数据量超大。传统的SQL语句库不再适应这些应用了。NoSQL数据库是为了解决大规模数据集合多重数据种类带来的挑战,特别是超大规模数据的存储。
NoSQL数据库的一个显著特点就是去掉了关系数据库的关系型特性,数据之间一旦没有关系,使得扩展性、读写性能都大大提高。
为什么使用 NoSQL(关系型数据库的瓶颈)
1、无法应对每秒上万次的读写请求,无法处理大量集中的高并发操作。关系型数据的是 IO 密集的应用。硬盘 IO 也变为性能瓶颈。
2、表中存储记录数量有限,横向可扩展能力有限,一张表最大二百多列。纵向数据可承受能力也是有限的,一张表的数据到达百万级,读写的速度就会逐渐的下降。面对海量数据,必须使用主从复制,分库分表。这样的系统架构是难以维护的。
大数据查询 SQL 效率极低,数据量到达一定程度时,查询时间会呈指数级别增长。
3、无法简单地通过增加硬件、服务节点来提高系统性能。数据整个存储在一个数据库中的。多个服务器没有很好的解决办法,来复制这些数据。
4、关系型数据库大多是收费的,对硬件的要求较高。软件和硬件的成本花费比重较大。
NoSQL 的适用场景
NoSQL 和传统的关系型数据库不是排斥和取代的关系,在一个分布式应用中往往是结合使用的。复杂的互联网应用通常都是多数据源、多数据类型,应该根据数据的使用情况和特点,存放在合适的数据库中。
- 数据模型比较简单
- 需要灵活性更强的 IT 系统
- 对数据库性能要求较高
- 不需要高度的数据一致性
- 对于给定的 Key,比较容易映射复杂值的环境
NoSQL 数据库四大家族
键值(Key-Value)存储
- 特点:键值数据库就像传统语言中使用的哈希表。通过 Key 添加、查询或者删除数据。
- 优点:查询速度快。
- 缺点:数据无结构化,通常只被当作字符串或者二进制数据存储。
- 应用场景:内容缓存、用户信息比如会话、配置信息、购物车等,主要用于处理大量数据的高访问负载。
- NoSQL 代表:Redis、Memcached…
文档(Document-Oriented)存储
- 特点:文档数据库将数据以文档的形式储存,类似 JSON,是一系列数据项的集合。每个数据项都有一个名称与对应的值,值既可以是简单的数据类型,如字符串、数字和日期等;也可以是复杂的类型,如有序列表和关联对象。
- 优点:数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构。
- 缺点:查询性能不高,缺乏统一的查询语法。
- 应用场景:日志、 Web 应用等。
- NoSQL 代表:MongoDB、CouchDB…
列(Wide Column Store/Column-Family)存储
- 特点:列存储数据库将数据储存在列族(Column Family)中,将多个列聚合成一个列族,键仍然存在,但是它们的特点是指向了多个列。举个例子,如果我们有一个 Person 类,我们通常会一起查询他们的姓名和年龄而不是薪资。这种情况下,姓名和年龄就会被放入一个列族中,而薪资则在另一个列族中。
- 优点:列存储查找速度快,可扩展性强,更容易进行分布式扩展,适用于分布式的文件系统,应对分布式存储的海量数据。
- 缺点:查询性能不高,缺乏统一的查询语法。
- 应用场景:日志、 分布式的文件系统(对象存储)、推荐画像、时空数据、消息/订单等。
- NoSQL 代表:Cassandra、HBase…
图形(Graph-Oriented)存储
- 特点:图形数据库允许我们将数据以图的方式储存。
- 优点:图形相关算法。比如最短路径寻址,N 度关系查找等。
- 缺点:很多时候需要对整个图做计算才能得出需要的信息,分布式的集群方案不好做,处理超级节点乏力,没有分片存储机制,国内社区不活跃。
- 应用场景:社交网络,推荐系统等。专注于构建关系图谱。
- NoSQL 代表:Neo4j、Infinite Graph…
NoSQL 的优势
1、大数据量,高性能
NoSQL 数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。关系型数据库(例如MySQL)使用查询缓存。这种查询缓存在更新数据后,缓存就是失效了。在频繁的数据读写交互应用中。缓存的性能不高。NoSQL 的缓存性能要高的多。
2、灵活的数据模型
NoSQL 无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。尤其在快速变化的市场环境中,用户的需求总是在不断变化的。
3、高可用
NoSQL 在不太影响性能的情况,就可以方便的实现高可用的架构。
NoSQL 能很好的解决关系型数据库扩展性差的问题。弥补了关系数据(比如 MySQL)在某些方面的不足,在某些方面能极大的节省开发成本和维护成本。
MySQL 和 NoSQL 都有各自的特点和使用的应用场景,两者结合使用。让关系数据库关注在关系上,NoSQL 关注在存储上。
4、低成本
这是大多数分布式数据库共有的特点,因为主要都是开源软件,没有昂贵的License 成本
NoSQL 的劣势
- 无关系,数据之间是无联系的。
- 不支持标准的 SQL,没有公认的 NoSQL 标准
- 没有关系型数据库的约束,大多数也没有索引的概念
- 没有事务,不能依靠事务实现 ACID
- 没有丰富的数据类型(数值,日期,字符,二进制,大文本等)
Redis
Redis 概述
REmote DIctionary Server(Redis) 是一个 key-value 存储系统,是跨平台的非关系型数据库,目前最常用于作为缓存服务器来使用。
Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对 (Key-Value) 存储数据库,并提供多种语言的 API。
Redis 通常被称为数据结构服务器,因为值(value)可以是字符串(String)、哈希(Hash)、列表(list)、集合(sets)和有序集合(sorted sets)等类型。
Redis 的作者是 Salvatore Sanfilippo,来自意大利的西西里岛,现在居住在卡塔尼亚。目前供职于 Pivotal 公司( Pivotal 是 Spring 框架的开发团队),Salyatore Sanfilippo 被称为 Redis 之父。

官网:https://redis.io/
中文官网:https://redis.cn/
源码地址:https://github.com/redis/redis
Redis 在线测试:http://try.redis.io/
Redis 命令参考:http://doc.redisfans.com/
缓存服务器原理

将访问过的数据库里的数据(select)当做缓存存储在内存中(Redis),再次获取数据的时候直接从内存(Redis)中获取,避免了对数据库造成过大的压力。
Redis 特点
- 高性能的内存型数据库,常用来做缓存服务器
- Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- 类型丰富,Redis 不仅仅支持简单的 key-value 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。
- Redis 是单线程、单进程
- Redis 支持数据的备份,即 master-slave 模式的数据备份。
Redis 优势
- 性能极高 – Redis 能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis 支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC 指令包起来。
- 丰富的特性 – Redis 还支持 publish/subscribe, 通知,key 过期等等特性。
Redis 与其他 key-value 存储的不同【了解】
- Redis 有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
- Redis 运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样 Redis 可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
Redis 安装(Windows)
Windows 版本的 Redis 是 Microsoft 的开源部门提供的 Redis。这个版本的 Redis 适合开发人员学习使用,生产环境中使用 Linux 系统上的 Redis
下载地址
# 这个版本比较老,2016年就不维护了 https://github.com/microsoftarchive/redis/releases # 最新版本5.0 https://github.com/tporadowski/redis/releases- 1
- 2
- 3
- 4
- 5
1、双击打开最新版本的64位 msi 格式安装包

2、点击下一步

3、勾选同意协议并点击下一步

4、选择路径,注意这里建议不要使用C盘路径和中文路径。勾选添加环境变量,点击下一步。
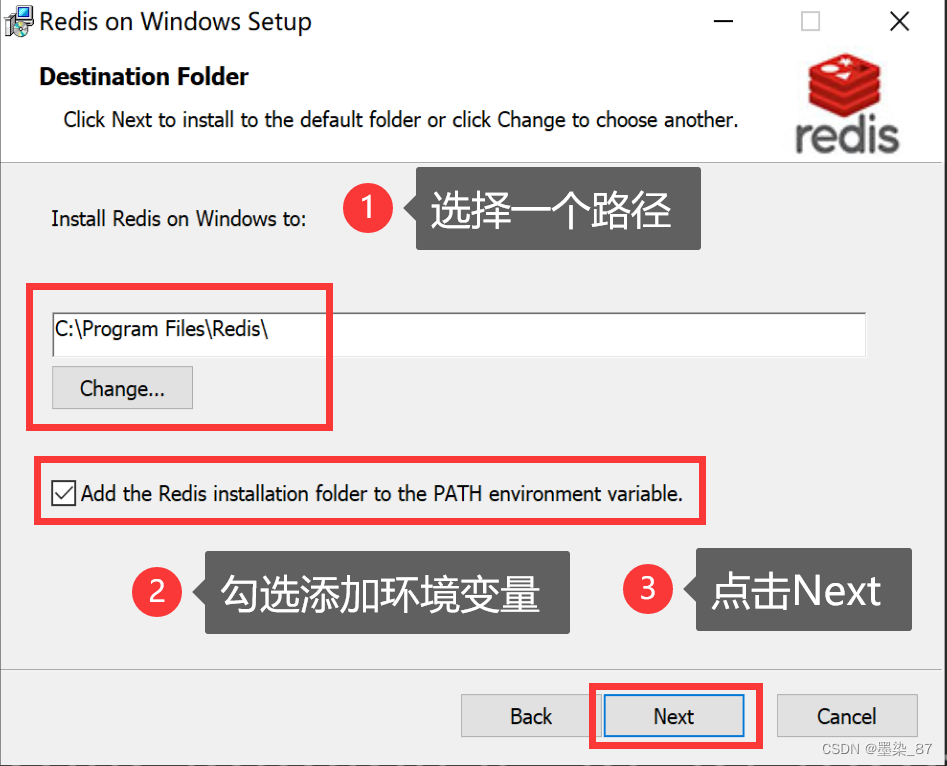
5、配置端口号,不用动直接下一步
6、直接下一步
7、安装

8、是

9、点击完成

Redis 配置文件
远程连接 redis 需要修改 redis 主目录下的 redis.conf 配置文件:
①、bind ip 绑定ip此行注释
②、protected-mode yes 保护模式改为 no
修改前
bind 127.0.0.1 protected-mode yes- 1
- 2
- 3
修改后
# bind 127.0.0.1 protected-mode no- 1
- 2
- 3
Windows 下启动并连接 Redis 服务器
启动 Redis 服务器
在当前目录下启动 cmd,并输入以下命令即可
redis-server.exe redis.windows.conf- 1

启动 Redis 客户端
Redis 客户端是一个程序,通过网络连接到 Redis 服务器, 在客户端软件中使用 Redis 可以识别的命令,向 Redis 服务器发送命令, 告诉 Redis 想要做什么。Redis 把处理结果显示在客户端界面上。 通过 Redis 客户端和 Redis 服务器交互。
直接连接
在当前目录下启动 cmd,并输入以下命令即可
redis-cli.exe- 1

使用 IP 地址和端口号进行连接
添加指定的 IP 地址以及端口号
redis-cli -h 127.0.0.1 -p 6379- 1
远程连接到其他服务器
替换 IP 地址以及端口号即可
redis-cli.exe -h 192.168.204.128 -p 6379- 1
String 字符串类型 【重点】
string 是 redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value 。
string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象 。
string 类型是Redis最基本的数据类型,一个键最大能存储512MB。
set【重点】
格式
set key value [ex seconds] [px milliseconds] [nx|xx]- 1
描述
将字符串值
value关联到key。如果
key已经持有其他值,SET就覆写旧值, 无视类型。当
SET命令对一个带有生存时间(TTL)的键进行设置之后, 该键原有的 TTL 将被清除。在 Redis 2.6.12 版本以前,
SET命令总是返回OK。从 Redis 2.6.12 版本开始,
SET命令只在设置操作成功完成时才返回OK; 如果命令使用了NX或者XX选项, 但是因为条件没达到而造成设置操作未执行, 那么命令将返回空批量回复(NULL Bulk Reply)。可选参数
从 Redis 2.6.12 版本开始,
SET命令的行为可以通过一系列参数来修改:EX seconds: 将键的过期时间设置为seconds秒。 执行SET key value EX seconds的效果等同于执行SETEX key seconds value。PX milliseconds: 将键的过期时间设置为milliseconds毫秒。 执行SET key value PX milliseconds的效果等同于执行PSETEX key milliseconds value。NX: 只在键不存在时, 才对键进行设置操作。 执行SET key value NX的效果等同于执行SETNX key value。XX: 只在键已经存在时, 才对键进行设置操作。
案例代码
对不存在的键进行设置:
redis> SET key "value" OK redis> GET key "value"- 1
- 2
- 3
- 4
- 5
对已存在的键进行设置:
redis> SET key "new-value" OK redis> GET key "new-value"- 1
- 2
- 3
- 4
- 5
使用
EX选项:redis> SET key-with-expire-time "hello" EX 10086 OK redis> GET key-with-expire-time "hello" redis> TTL key-with-expire-time (integer) 10069- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
使用
PX选项:redis> SET key-with-pexpire-time "moto" PX 123321 OK redis> GET key-with-pexpire-time "moto" redis> PTTL key-with-pexpire-time (integer) 111939- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
使用
NX选项:redis> SET not-exists-key "value" NX OK # 键不存在,设置成功 redis> GET not-exists-key "value" redis> SET not-exists-key "new-value" NX (nil) # 键已经存在,设置失败 redis> GEt not-exists-key "value" # 维持原值不变- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
使用
XX选项:redis> EXISTS exists-key (integer) 0 redis> SET exists-key "value" XX (nil) # 因为键不存在,设置失败 redis> SET exists-key "value" OK # 先给键设置一个值 redis> SET exists-key "new-value" XX OK # 设置新值成功 redis> GET exists-key "new-value"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
get【重点】
描述
返回与键
key相关联的字符串值。如果键
key不存在, 那么返回特殊值nil; 否则, 返回键key的值。如果键
key的值并非字符串类型, 那么返回一个错误, 因为GET命令只能用于字符串值。案例代码
对不存在的键
key或是字符串类型的键key执行GET命令:redis> GET db (nil) redis> SET db redis OK redis> GET db "redis"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
对不是字符串类型的键
key执行GET命令:redis> DEL db (integer) 1 redis> LPUSH db redis mongodb mysql (integer) 3 redis> GET db (error) ERR Operation against a key holding the wrong kind of value- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
setnx【重点】
描述
只在键
key不存在的情况下, 将键key的值设置为value。若键
key已经存在, 则SETNX命令不做任何动作。SETNX是『SET if Not eXists』(如果不存在,则 SET)的简写。命令在设置成功时返回
1, 设置失败时返回0。案例代码
redis> EXISTS job # job 不存在 (integer) 0 redis> SETNX job "programmer" # job 设置成功 (integer) 1 redis> SETNX job "code-farmer" # 尝试覆盖 job ,失败 (integer) 0 redis> GET job # 没有被覆盖 "programmer"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
setex【重点】
描述
将键
key的值设置为value, 并将键key的生存时间设置为seconds秒钟。如果键
key已经存在, 那么SETEX命令将覆盖已有的值。SETEX命令的效果和以下两个命令的效果类似:SET key value EXPIRE key seconds # 设置生存时间- 1
- 2
SETEX和这两个命令的不同之处在于SETEX是一个原子(atomic)操作, 它可以在同一时间内完成设置值和设置过期时间这两个操作, 因此SETEX命令在储存缓存的时候非常实用。命令在设置成功时返回
OK。 当seconds参数不合法时, 命令将返回一个错误。案例代码
在键
key不存在的情况下执行SETEX:redis> SETEX cache_user_id 60 10086 OK redis> GET cache_user_id # 值 "10086" redis> TTL cache_user_id # 剩余生存时间 (integer) 49- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
键
key已经存在,使用SETEX覆盖旧值:redis> SET cd "timeless" OK redis> SETEX cd 3000 "goodbye my love" OK redis> GET cd "goodbye my love" redis> TTL cd (integer) 2997- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
PSETEX
格式
psetex key milliseconds value- 1
描述
这个命令和
SETEX命令相似, 但它以毫秒为单位设置key的生存时间, 而不是像SETEX命令那样以秒为单位进行设置。命令在设置成功时返回OK。案例代码
redis> PSETEX mykey 1000 "Hello" OK redis> PTTL mykey (integer) 999 redis> GET mykey "Hello"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
getset
格式
getset key value- 1
描述
将键
key的值设为value, 并返回键key在被设置之前的旧值。如果键
key没有旧值, 也即是说, 键key在被设置之前并不存在, 那么命令返回nil。当键
key存在但不是字符串类型时, 命令返回一个错误。案例代码
redis> GETSET db mongodb # 没有旧值,返回 nil (nil) redis> GET db "mongodb" redis> GETSET db redis # 返回旧值 mongodb "mongodb" redis> GET db "redis"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
strlen【重点】
格式
strlen key- 1
描述
返回键
key储存的字符串值的长度。当键
key不存在时, 命令返回0。当
key储存的不是字符串值时, 返回一个错误。案例代码
获取字符串值的长度:
redis> SET mykey "Hello world" OK redis> STRLEN mykey (integer) 11- 1
- 2
- 3
- 4
- 5
不存在的键的长度为
0:redis> STRLEN nonexisting (integer) 0- 1
- 2
append【重点】
格式
append key value- 1
描述
如果键
key已经存在并且它的值是一个字符串,APPEND命令将把value追加到键key现有值的末尾。如果
key不存在,APPEND就简单地将键key的值设为value, 就像执行SET key value一样。追加
value之后, 键key的值的长度。案例代码
对不存在的
key执行APPEND:redis> EXISTS myphone # 确保 myphone 不存在 (integer) 0 redis> APPEND myphone "nokia" # 对不存在的 key 进行 APPEND ,等同于 SET myphone "nokia" (integer) 5 # 字符长度- 1
- 2
- 3
- 4
- 5
对已存在的字符串进行
APPEND:redis> APPEND myphone " - 1110" # 长度从 5 个字符增加到 12 个字符 (integer) 12 redis> GET myphone "nokia - 1110"- 1
- 2
- 3
- 4
- 5
setrange【重点】
相当于Java中的replace()
格式
setrange key offset value- 1
描述
从偏移量
offset开始, 用value参数覆写(overwrite)键key储存的字符串值。不存在的键key当作空白字符串处理。SETRANGE命令会返回被修改之后, 字符串值的长度。SETRANGE命令会确保字符串足够长以便将value设置到指定的偏移量上, 如果键key原来储存的字符串长度比偏移量小(比如字符串只有5个字符长,但你设置的offset是10), 那么原字符和偏移量之间的空白将用零字节(zerobytes,"\x00")进行填充。因为 Redis 字符串的大小被限制在 512 兆(megabytes)以内, 所以用户能够使用的最大偏移量为 2^29-1(536870911) , 如果你需要使用比这更大的空间, 请使用多个
key。当生成一个很长的字符串时, Redis 需要分配内存空间, 该操作有时候可能会造成服务器阻塞(block)。 在2010年出产的Macbook Pro上, 设置偏移量为 536870911(512MB 内存分配)将耗费约 300 毫秒, 设置偏移量为 134217728(128MB 内存分配)将耗费约 80 毫秒, 设置偏移量 33554432(32MB 内存分配)将耗费约 30 毫秒, 设置偏移量为 8388608(8MB 内存分配)将耗费约 8 毫秒。
案例代码
对非空字符串执行
SETRANGE命令:redis> SET greeting "hello world" OK redis> SETRANGE greeting 6 "Redis" (integer) 11 redis> GET greeting "hello Redis"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
对空字符串/不存在的键执行
SETRANGE命令:redis> EXISTS empty_string (integer) 0 redis> SETRANGE empty_string 5 "Redis!" # 对不存在的 key 使用 SETRANGE (integer) 11 redis> GET empty_string # 空白处被"\x00"填充 "\x00\x00\x00\x00\x00Redis!"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
getrange【重点】
类似于 Java 中的 substr()
格式
getrange key start end- 1
描述
返回键
key储存的字符串值的指定部分, 字符串的截取范围由start和end两个偏移量决定 (包括start和end在内)。负数偏移量表示从字符串的末尾开始计数,
-1表示最后一个字符,-2表示倒数第二个字符, 以此类推。GETRANGE通过保证子字符串的值域(range)不超过实际字符串的值域来处理超出范围的值域请求。GETRANGE命令在 Redis 2.0 之前的版本里面被称为SUBSTR命令。案例代码
redis> SET greeting "hello, my friend" OK redis> GETRANGE greeting 0 4 # 返回索引0-4的字符,包括4。 "hello" redis> GETRANGE greeting -1 -5 # 不支持回绕操作 "" redis> GETRANGE greeting -3 -1 # 负数索引 "end" redis> GETRANGE greeting 0 -1 # 从第一个到最后一个 "hello, my friend" redis> GETRANGE greeting 0 1008611 # 值域范围不超过实际字符串,超过部分自动被符略 "hello, my friend"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
incr【重点】
格式
incr key- 1
描述
为键
key储存的数字值加上一。如果键
key不存在, 那么它的值会先被初始化为0, 然后再执行INCR命令。如果键
key储存的值不能被解释为数字, 那么INCR命令将返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。INCR命令会返回键key在执行加一操作之后的值。INCR命令是一个针对字符串的操作。 因为 Redis 并没有专用的整数类型, 所以键key储存的值在执行INCR命令时会被解释为十进制 64 位有符号整数。原子性操作。线程安全,常用于计数器。
案例代码
redis> SET page_view 20 OK redis> INCR page_view (integer) 21 redis> GET page_view # 数字值在 Redis 中以字符串的形式保存 "21"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
incrby【重点】
格式
incrby key increment- 1
描述
为键
key储存的数字值加上增量increment。如果键key不存在, 那么键key的值会先被初始化为0, 然后再执行INCRBY命令。如果键
key储存的值不能被解释为数字, 那么INCRBY命令将返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。在加上增量
increment之后, 键key当前的值。案例代码
键存在,并且值为数字:
redis> SET rank 50 OK redis> INCRBY rank 20 (integer) 70 redis> GET rank "70"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
键不存在:
redis> EXISTS counter (integer) 0 redis> INCRBY counter 30 (integer) 30 redis> GET counter "30"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
键存在,但值无法被解释为数字:
redis> SET book "long long ago..." OK redis> INCRBY book 200 (error) ERR value is not an integer or out of range- 1
- 2
- 3
- 4
- 5
incrbyfloat
格式
incrbyfloat key increment- 1
描述
为键
key储存的值加上浮点数增量increment。如果键
key不存在, 那么INCRBYFLOAT会先将键key的值设为0, 然后再执行加法操作。返回值为在加上增量
increment之后, 键key的值。此外, 无论加法计算所得的浮点数的实际精度有多长,
INCRBYFLOAT命令的计算结果最多只保留小数点的后十七位。当以下任意一个条件发生时, 命令返回一个错误:
- 键
key的值不是字符串类型(因为 Redis 中的数字和浮点数都以字符串的形式保存,所以它们都属于字符串类型); - 键
key当前的值或者给定的增量increment不能被解释(parse)为双精度浮点数。
案例代码
redis> GET decimal "3.0" redis> INCRBYFLOAT decimal 2.56 "5.56" redis> GET decimal "5.56"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
decr【重点】
格式
decr key- 1
描述
为键
key储存的数字值减去一。如果键
key不存在, 那么键key的值会先被初始化为0, 然后再执行DECR操作。如果键
key储存的值不能被解释为数字, 那么DECR命令将返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。DECR命令会返回键key在执行减一操作之后的值。案例代码
对储存数字值的键
key执行DECR命令:redis> SET failure_times 10 OK redis> DECR failure_times (integer) 9- 1
- 2
- 3
- 4
- 5
对不存在的键执行
DECR命令:redis> EXISTS count (integer) 0 redis> DECR count (integer) -1- 1
- 2
- 3
- 4
- 5
decrby【重点】
格式
decrby key decrement- 1
描述
将键
key储存的整数值减去减量decrement。如果键
key不存在, 那么键key的值会先被初始化为0, 然后再执行DECRBY命令。如果键
key储存的值不能被解释为数字, 那么DECRBY命令将返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。DECRBY命令会返回键在执行减法操作之后的值。案例代码
对已经存在的键执行
DECRBY命令:redis> SET count 100 OK redis> DECRBY count 20 (integer) 80- 1
- 2
- 3
- 4
- 5
对不存在的键执行
DECRBY命令:redis> EXISTS pages (integer) 0 redis> DECRBY pages 10 (integer) -10- 1
- 2
- 3
- 4
- 5
mest【重点】
格式
mest key value [key value …]- 1
描述
同时为多个键设置值。
如果某个给定键已经存在, 那么
MSET将使用新值去覆盖旧值, 如果这不是你所希望的效果, 请考虑使用MSETNX命令, 这个命令只会在所有给定键都不存在的情况下进行设置。MSET是一个原子性(atomic)操作, 所有给定键都会在同一时间内被设置, 不会出现某些键被设置了但是另一些键没有被设置的情况。MSET命令总是返回OK。案例代码
同时对多个键进行设置:
redis> MSET date "2012.3.30" time "11:00 a.m." weather "sunny" OK redis> MGET date time weather 1) "2012.3.30" 2) "11:00 a.m." 3) "sunny"- 1
- 2
- 3
- 4
- 5
- 6
- 7
覆盖已有的值:
redis> MGET k1 k2 1) "hello" 2) "world" redis> MSET k1 "good" k2 "bye" OK redis> MGET k1 k2 1) "good" 2) "bye"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
msetnx
格式
msetnx key value [key value …]- 1
描述
当且仅当所有给定键都不存在时, 为所有给定键设置值。即使只有一个给定键已经存在,
MSETNX命令也会拒绝执行对所有键的设置操作。MSETNX是一个原子性(atomic)操作, 所有给定键要么就全部都被设置, 要么就全部都不设置, 不可能出现第三种状态。当所有给定键都设置成功时, 命令返回
1; 如果因为某个给定键已经存在而导致设置未能成功执行, 那么命令返回0。案例代码
对不存在的键执行
MSETNX命令:redis> MSETNX rmdbs "MySQL" nosql "MongoDB" key-value-store "redis" (integer) 1 redis> MGET rmdbs nosql key-value-store 1) "MySQL" 2) "MongoDB" 3) "redis"- 1
- 2
- 3
- 4
- 5
- 6
- 7
对某个已经存在的键进行设置:
redis> MSETNX rmdbs "Sqlite" language "python" # rmdbs 键已经存在,操作失败 (integer) 0 redis> EXISTS language # 因为 MSETNX 命令没有成功执行 (integer) 0 # 所以 language 键没有被设置 redis> GET rmdbs # rmdbs 键也没有被修改 "MySQL"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
mget【重点】
格式
mget key [key …]- 1
描述
返回给定的一个或多个字符串键的值。
如果给定的字符串键里面, 有某个键不存在, 那么这个键的值将以特殊值
nil表示。MGET命令将返回一个列表, 列表中包含了所有给定键的值。案例代码
redis> SET redis redis.com OK redis> SET mongodb mongodb.org OK redis> MGET redis mongodb 1) "redis.com" 2) "mongodb.org" redis> MGET redis mongodb mysql # 不存在的 mysql 返回 nil 1) "redis.com" 2) "mongodb.org" 3) (nil)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Hash 哈希表类型【重要】
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
hset【重点】
格式
hset hash field value- 1
描述
将哈希表
hash中域field的值设置为value。如果给定的哈希表并不存在, 那么一个新的哈希表将被创建并执行
HSET操作。如果域field已经存在于哈希表中, 那么它的旧值将被新值value覆盖。当
HSET命令在哈希表中新创建field域并成功为它设置值时, 命令返回1; 如果域field已经存在于哈希表, 并且HSET命令成功使用新值覆盖了它的旧值, 那么命令返回0。案例代码
设置一个新域:
redis> HSET website google "www.g.cn" (integer) 1 redis> HGET website google "www.g.cn"- 1
- 2
- 3
- 4
- 5
对一个已存在的域进行更新:
redis> HSET website google "www.google.com" (integer) 0 redis> HGET website google "www.google.com"- 1
- 2
- 3
- 4
- 5
hsetnx
格式
hsetnx hash field value- 1
描述
当且仅当域
field尚未存在于哈希表的情况下, 将它的值设置为value。如果给定域已经存在于哈希表当中, 那么命令将放弃执行设置操作。
如果哈希表
hash不存在, 那么一个新的哈希表将被创建并执行HSETNX命令。HSETNX命令在设置成功时返回1, 在给定域已经存在而放弃执行设置操作时返回0。案例代码
域尚未存在, 设置成功:
redis> HSETNX database key-value-store Redis (integer) 1 redis> HGET database key-value-store "Redis"- 1
- 2
- 3
- 4
- 5
域已经存在, 设置未成功, 域原有的值未被改变:
redis> HSETNX database key-value-store Riak (integer) 0 redis> HGET database key-value-store "Redis"- 1
- 2
- 3
- 4
- 5
hget【重点】
格式
hget hash field- 1
描述
HGET命令在默认情况下返回给定域的值。如果给定域不存在于哈希表中, 又或者给定的哈希表并不存在, 那么命令返回
nil。案例代码
域存在的情况:
redis> HSET homepage redis redis.com (integer) 1 redis> HGET homepage redis "redis.com"- 1
- 2
- 3
- 4
- 5
域不存在的情况:
redis> HGET site mysql (nil)- 1
- 2
hexists【重点】
格式
hexists hash field- 1
描述
检查给定域
field是否存在于哈希表hash当中。在给定域存在时返回
1, 在给定域不存在时返回0。案例代码
给定域不存在:
redis> HEXISTS phone myphone (integer) 0- 1
- 2
给定域存在:
redis> HSET phone myphone nokia-1110 (integer) 1 redis> HEXISTS phone myphone (integer) 1- 1
- 2
- 3
- 4
- 5
hdel【重点】
格式
hdel key field [field …]- 1
描述
删除哈希表
key中的一个或多个指定域,不存在的域将被忽略。返回值为被成功移除的域的数量,不包括被忽略的域。
案例代码
# 测试数据 redis> HGETALL abbr 1) "a" 2) "apple" 3) "b" 4) "banana" 5) "c" 6) "cat" 7) "d" 8) "dog" # 删除单个域 redis> HDEL abbr a (integer) 1 # 删除不存在的域 redis> HDEL abbr not-exists-field (integer) 0 # 删除多个域 redis> HDEL abbr b c (integer) 2 redis> HGETALL abbr 1) "d" 2) "dog"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
hlen【重点】
格式
hlen key- 1
描述
返回哈希表
key中域的数量。当key不存在时,返回0。案例代码
redis> HSET db redis redis.com (integer) 1 redis> HSET db mysql mysql.com (integer) 1 redis> HLEN db (integer) 2 redis> HSET db mongodb mongodb.org (integer) 1 redis> HLEN db (integer) 3- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
hgetall【重点】
格式
hgetall key- 1
描述
返回哈希表
key中,所有的域和值。在返回值里,紧跟每个域名(field name)之后是域的值(value),所以返回值的长度是哈希表大小的两倍。若
key不存在,返回空列表。案例代码
redis> HSET people jack "Jack Sparrow" (integer) 1 redis> HSET people gump "Forrest Gump" (integer) 1 redis> HGETALL people 1) "jack" # 域 2) "Jack Sparrow" # 值 3) "gump" 4) "Forrest Gump"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
hkeys【常用】
格式
hkeys key- 1
描述
返回哈希表
key中的所有域。当key不存在时,返回一个空表。案例代码
# 哈希表非空 redis> HMSET website google www.google.com yahoo www.yahoo.com OK redis> HKEYS website 1) "google" 2) "yahoo" # 空哈希表/key不存在 redis> EXISTS fake_key (integer) 0 redis> HKEYS fake_key (empty list or set)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
hvals【常用】
格式
hvals key- 1
描述
返回哈希表
key中所有域的值。当key不存在时,返回一个空表。案例代码
# 非空哈希表 redis> HMSET website google www.google.com yahoo www.yahoo.com OK redis> HVALS website 1) "www.google.com" 2) "www.yahoo.com" # 空哈希表/不存在的key redis> EXISTS not_exists (integer) 0 redis> HVALS not_exists (empty list or set)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
hincrby
格式
hincrby key field increment- 1
描述
为哈希表
key中的域field的值加上增量increment。增量也可以为负数,相当于对给定域进行减法操作。
如果
key不存在,一个新的哈希表被创建并执行 HINCRBY 命令。如果域
field不存在,那么在执行命令前,域的值被初始化为0。对一个储存字符串值的域
field执行 HINCRBY 命令将造成一个错误。本操作的值被限制在 64 位(bit)有符号数字表示之内。返回值为执行 HINCRBY 命令之后,哈希表
key中域field的值。案例代码
# increment 为正数 redis> HEXISTS counter page_view # 对空域进行设置 (integer) 0 redis> HINCRBY counter page_view 200 (integer) 200 redis> HGET counter page_view "200" # increment 为负数 redis> HGET counter page_view "200" redis> HINCRBY counter page_view -50 (integer) 150 redis> HGET counter page_view "150" # 尝试对字符串值的域执行HINCRBY命令 redis> HSET myhash string hello,world # 设定一个字符串值 (integer) 1 redis> HGET myhash string "hello,world" redis> HINCRBY myhash string 1 # 命令执行失败,错误。 (error) ERR hash value is not an integer redis> HGET myhash string # 原值不变 "hello,world"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
hincrbyfloat
格式
hincrbyfloat key field increment- 1
描述
为哈希表
key中的域field加上浮点数增量increment。如果哈希表中没有域
field,那么 HINCRBYFLOAT 会先将域field的值设为0,然后再执行加法操作。如果键
key不存在,那么 HINCRBYFLOAT 会先创建一个哈希表,再创建域field,最后再执行加法操作。返回值为执行加法操作之后
field域的值。案例代码
# 值和增量都是普通小数 redis> HSET mykey field 10.50 (integer) 1 redis> HINCRBYFLOAT mykey field 0.1 "10.6" # 值和增量都是指数符号 redis> HSET mykey field 5.0e3 (integer) 0 redis> HINCRBYFLOAT mykey field 2.0e2 "5200" # 对不存在的键执行 HINCRBYFLOAT redis> EXISTS price (integer) 0 redis> HINCRBYFLOAT price milk 3.5 "3.5" redis> HGETALL price 1) "milk" 2) "3.5" # 对不存在的域进行 HINCRBYFLOAT redis> HGETALL price 1) "milk" 2) "3.5" redis> HINCRBYFLOAT price coffee 4.5 # 新增 coffee 域 "4.5" redis> HGETALL price 1) "milk" 2) "3.5" 3) "coffee" 4) "4.5"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
hmset【常用】
格式
hmset key field value [field value …]- 1
描述
同时将多个
field-value(域-值)对设置到哈希表key中。此命令会覆盖哈希表中已存在的域。如果key不存在,一个空哈希表被创建并执行 HMSET 操作。如果命令执行成功,返回
OK。当key不是哈希表(hash)类型时,返回一个错误。案例代码
redis> HMSET website google www.google.com yahoo www.yahoo.com OK redis> HGET website google "www.google.com" redis> HGET website yahoo "www.yahoo.com"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
hmget【常用】
格式
hmget key field [field …]- 1
描述
返回哈希表
key中,一个或多个给定域的值。如果给定的域不存在于哈希表,那么返回一个
nil值。因为不存在的
key被当作一个空哈希表来处理,所以对一个不存在的key进行 HMGET 操作将返回一个只带有nil值的表。一个包含多个给定域的关联值的表,表值的排列顺序和给定域参数的请求顺序一样。
案例代码
redis> HMSET pet dog "doudou" cat "nounou" # 一次设置多个域 OK redis> HMGET pet dog cat fake_pet # 返回值的顺序和传入参数的顺序一样 1) "doudou" 2) "nounou" 3) (nil) # 不存在的域返回nil值- 1
- 2
- 3
- 4
- 5
- 6
- 7
List 列表类型【重点】
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
lpush【重点】
格式
lpush key value [value …]- 1
描述
将一个或多个值
value插入到列表key的表头如果有多个
value值,那么各个value值按从左到右的顺序依次插入到表头: 比如说,对空列表mylist执行命令LPUSH mylist a b c,列表的值将是c b a,这等同于原子性地执行LPUSH mylist a、LPUSH mylist b和LPUSH mylist c三个命令。如果
key不存在,一个空列表会被创建并执行 LPUSH 操作。当key存在但不是列表类型时,返回一个错误。返回值为执行 LPUSH 命令后,列表的长度。
案例代码
# 加入单个元素 redis> LPUSH languages python (integer) 1 # 加入重复元素 redis> LPUSH languages python (integer) 2 redis> LRANGE languages 0 -1 # 列表允许重复元素 1) "python" 2) "python" # 加入多个元素 redis> LPUSH mylist a b c (integer) 3 redis> LRANGE mylist 0 -1 1) "c" 2) "b" 3) "a"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
lpushx【重点】
格式
lpushx key value- 1
描述
将值
value插入到列表key的表头,当且仅当key存在并且是一个列表。和 [LPUSH key value value …] 命令相反,当
key不存在时, LPUSHX 命令什么也不做。返回值为LPUSHX 命令执行之后,表的长度。
案例代码
# 对空列表执行 LPUSHX redis> LLEN greet # greet 是一个空列表 (integer) 0 redis> LPUSHX greet "hello" # 尝试 LPUSHX,失败,因为列表为空 (integer) 0 # 对非空列表执行 LPUSHX redis> LPUSH greet "hello" # 先用 LPUSH 创建一个有一个元素的列表 (integer) 1 redis> LPUSHX greet "good morning" # 这次 LPUSHX 执行成功 (integer) 2 redis> LRANGE greet 0 -1 1) "good morning" 2) "hello"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
rpush【重点】
格式
rpush key value [value …]- 1
描述
将一个或多个值
value插入到列表key的表尾(最右边)。如果有多个
value值,那么各个value值按从左到右的顺序依次插入到表尾:比如对一个空列表mylist执行RPUSH mylist a b c,得出的结果列表为a b c,等同于执行命令RPUSH mylist a、RPUSH mylist b、RPUSH mylist c。如果
key不存在,一个空列表会被创建并执行 RPUSH 操作。当key存在但不是列表类型时,返回一个错误。返回值为执行 RPUSH 操作后,表的长度。
案例代码
# 添加单个元素 redis> RPUSH languages c (integer) 1 # 添加重复元素 redis> RPUSH languages c (integer) 2 redis> LRANGE languages 0 -1 # 列表允许重复元素 1) "c" 2) "c" # 添加多个元素 redis> RPUSH mylist a b c (integer) 3 redis> LRANGE mylist 0 -1 1) "a" 2) "b" 3) "c"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
rpushx【重点】
格式
rpushx key value- 1
描述
将值
value插入到列表key的表尾,当且仅当key存在并且是一个列表。和 [RPUSH key value value …] 命令相反,当
key不存在时, RPUSHX 命令什么也不做。返回值为RPUSHX 命令执行之后,表的长度。
案例代码
# key不存在 redis> LLEN greet (integer) 0 redis> RPUSHX greet "hello" # 对不存在的 key 进行 RPUSHX,PUSH 失败。 (integer) 0 # key 存在且是一个非空列表 redis> RPUSH greet "hi" # 先用 RPUSH 插入一个元素 (integer) 1 redis> RPUSHX greet "hello" # greet 现在是一个列表类型,RPUSHX 操作成功。 (integer) 2 redis> LRANGE greet 0 -1 1) "hi" 2) "hello"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
lpop【重点】
格式
lpop key- 1
描述
移除并返回列表
key的头元素。返回值为列表的头元素。 当
key不存在时,返回nil。案例代码
redis> LLEN course (integer) 0 redis> RPUSH course algorithm001 (integer) 1 redis> RPUSH course c++101 (integer) 2 redis> LPOP course # 移除头元素 "algorithm001"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
rpop【重点】
格式
rpop key- 1
描述
移除并返回列表
key的尾元素。返回值为列表的尾元素。 当
key不存在时,返回nil。案例代码
redis> RPUSH mylist "one" (integer) 1 redis> RPUSH mylist "two" (integer) 2 redis> RPUSH mylist "three" (integer) 3 redis> RPOP mylist # 返回被弹出的元素 "three" redis> LRANGE mylist 0 -1 # 列表剩下的元素 1) "one" 2) "two"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
rpoplpush
格式
rpoplpush source destination- 1
描述
命令 RPOPLPUSH 在一个原子时间内,执行以下两个动作:
- 将列表
source中的最后一个元素(尾元素)弹出,并返回给客户端。 - 将
source弹出的元素插入到列表destination,作为destination列表的的头元素。
如果
source不存在,值nil被返回,并且不执行其他动作。如果
source和destination相同,则列表中的表尾元素被移动到表头,并返回该元素,可以把这种特殊情况视作列表的旋转(rotation)操作。返回值为被弹出的元素。
案例代码
# source 和 destination 不同 redis> LRANGE alpha 0 -1 # 查看所有元素 1) "a" 2) "b" 3) "c" 4) "d" redis> RPOPLPUSH alpha reciver # 执行一次 RPOPLPUSH 看看 "d" redis> LRANGE alpha 0 -1 1) "a" 2) "b" 3) "c" redis> LRANGE reciver 0 -1 1) "d" redis> RPOPLPUSH alpha reciver # 再执行一次,证实 RPOP 和 LPUSH 的位置正确 "c" redis> LRANGE alpha 0 -1 1) "a" 2) "b" redis> LRANGE reciver 0 -1 1) "c" 2) "d" # source 和 destination 相同 redis> LRANGE number 0 -1 1) "1" 2) "2" 3) "3" 4) "4" redis> RPOPLPUSH number number "4" redis> LRANGE number 0 -1 # 4 被旋转到了表头 1) "4" 2) "1" 3) "2" 4) "3" redis> RPOPLPUSH number number "3" redis> LRANGE number 0 -1 # 这次是 3 被旋转到了表头 1) "3" 2) "4" 3) "1" 4) "2"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
lrem【常用】
格式
lrem key count value- 1
描述
根据参数
count的值,移除列表中与参数value相等的元素。count的值可以是以下几种:count > 0: 从表头开始向表尾搜索,移除与value相等的元素,数量为count。count < 0: 从表尾开始向表头搜索,移除与value相等的元素,数量为count的绝对值。count = 0: 移除表中所有与value相等的值。
返回值为被移除元素的数量。 因为不存在的
key被视作空表(empty list),所以当key不存在时, LREM 命令总是返回0。案例代码
# 先创建一个表,内容排列是 # morning hello morning helllo morning redis> LPUSH greet "morning" (integer) 1 redis> LPUSH greet "hello" (integer) 2 redis> LPUSH greet "morning" (integer) 3 redis> LPUSH greet "hello" (integer) 4 redis> LPUSH greet "morning" (integer) 5 redis> LRANGE greet 0 4 # 查看所有元素 1) "morning" 2) "hello" 3) "morning" 4) "hello" 5) "morning" redis> LREM greet 2 morning # 移除从表头到表尾,最先发现的两个 morning (integer) 2 # 两个元素被移除 redis> LLEN greet # 还剩 3 个元素 (integer) 3 redis> LRANGE greet 0 2 1) "hello" 2) "hello" 3) "morning" redis> LREM greet -1 morning # 移除从表尾到表头,第一个 morning (integer) 1 redis> LLEN greet # 剩下两个元素 (integer) 2 redis> LRANGE greet 0 1 1) "hello" 2) "hello" redis> LREM greet 0 hello # 移除表中所有 hello (integer) 2 # 两个 hello 被移除 redis> LLEN greet (integer) 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
llen【重点】
格式
llen key- 1
描述
返回列表
key的长度。如果
key不存在,则key被解释为一个空列表,返回0.如果
key不是列表类型,返回一个错误。案例代码
# 空列表 redis> LLEN job (integer) 0 # 非空列表 redis> LPUSH job "cook food" (integer) 1 redis> LPUSH job "have lunch" (integer) 2 redis> LLEN job (integer) 2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
lindex【重点】
格式
lindex key index- 1
描述
返回列表
key中,下标为index的元素。 如果index参数的值不在列表的区间范围内(out of range),返回nil。下标(index)参数
start和stop都以0为底,也就是说,以0表示列表的第一个元素,以1表示列表的第二个元素,以此类推。你也可以使用负数下标,以
-1表示列表的最后一个元素,-2表示列表的倒数第二个元素,以此类推。如果
key不是列表类型,返回一个错误。案例代码
redis> LPUSH mylist "World" (integer) 1 redis> LPUSH mylist "Hello" (integer) 2 redis> LINDEX mylist 0 "Hello" redis> LINDEX mylist -1 "World" redis> LINDEX mylist 3 # index不在 mylist 的区间范围内 (nil)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
linsert【常用】
格式
linsert key BEFORE|AFTER pivot value- 1
描述
将值
value插入到列表key当中,位于值pivot之前或之后。当
pivot不存在于列表key时,不执行任何操作。当
key不存在时,key被视为空列表,不执行任何操作。如果
key不是列表类型,返回一个错误。如果命令执行成功,返回插入操作完成之后,列表的长度。 如果没有找到
pivot,返回-1。 如果key不存在或为空列表,返回0。案例代码
redis> RPUSH mylist "Hello" (integer) 1 redis> RPUSH mylist "World" (integer) 2 redis> LINSERT mylist BEFORE "World" "There" (integer) 3 redis> LRANGE mylist 0 -1 1) "Hello" 2) "There" 3) "World" # 对一个非空列表插入,查找一个不存在的 pivot redis> LINSERT mylist BEFORE "go" "let's" (integer) -1 # 失败 # 对一个空列表执行 LINSERT 命令 redis> EXISTS fake_list (integer) 0 redis> LINSERT fake_list BEFORE "nono" "gogogog" (integer) 0 # 失败- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
lset【常用】
格式
lset key index value- 1
描述
将列表
key下标为index的元素的值设置为value。当
index参数超出范围,或对一个空列表(key不存在)进行 LSET 时,返回一个错误。操作成功返回
ok,否则返回错误信息。案例代码
# 对空列表(key 不存在)进行 LSET redis> EXISTS list (integer) 0 redis> LSET list 0 item (error) ERR no such key # 对非空列表进行 LSET redis> LPUSH job "cook food" (integer) 1 redis> LRANGE job 0 0 1) "cook food" redis> LSET job 0 "play game" OK redis> LRANGE job 0 0 1) "play game" # index 超出范围 redis> LLEN list # 列表长度为 1 (integer) 1 redis> LSET list 3 'out of range' (error) ERR index out of range- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
lrange【重点】
格式
lrange key start stop- 1
描述
返回列表
key中指定区间内的元素,区间以偏移量start和stop指定。下标(index)参数
start和stop都以0为底,也就是说,以0表示列表的第一个元素,以1表示列表的第二个元素,以此类推。你也可以使用负数下标,以
-1表示列表的最后一个元素,-2表示列表的倒数第二个元素,以此类推。超出范围的下标值不会引起错误。
如果
start下标比列表的最大下标end(LLEN list减去1)还要大,那么 LRANGE 返回一个空列表。如果
stop下标比end下标还要大,Redis将stop的值设置为end。案例代码
redis> RPUSH fp-language lisp (integer) 1 redis> LRANGE fp-language 0 0 1) "lisp" redis> RPUSH fp-language scheme (integer) 2 redis> LRANGE fp-language 0 1 1) "lisp" 2) "scheme"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
ltrim
格式
ltrim key start stop- 1
描述
对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
当
key不是列表类型时,返回一个错误。命令执行成功时,返回ok。超出范围的下标值不会引起错误。
如果
start下标比列表的最大下标end(LLEN list减去1)还要大,或者start > stop, LTRIM 返回一个空列表(因为 LTRIM 已经将整个列表清空)。如果
stop下标比end下标还要大,Redis将stop的值设置为end。案例代码
# 情况 1: 常见情况, start 和 stop 都在列表的索引范围之内 redis> LRANGE alpha 0 -1 # alpha 是一个包含 5 个字符串的列表 1) "h" 2) "e" 3) "l" 4) "l" 5) "o" redis> LTRIM alpha 1 -1 # 删除 alpha 列表索引为 0 的元素 OK redis> LRANGE alpha 0 -1 # "h" 被删除了 1) "e" 2) "l" 3) "l" 4) "o" # 情况 2: stop 比列表的最大下标还要大 redis> LTRIM alpha 1 10086 # 保留 alpha 列表索引 1 至索引 10086 上的元素 OK redis> LRANGE alpha 0 -1 # 只有索引 0 上的元素 "e" 被删除了,其他元素还在 1) "l" 2) "l" 3) "o" # 情况 3: start 和 stop 都比列表的最大下标要大,并且 start < stop redis> LTRIM alpha 10086 123321 OK redis> LRANGE alpha 0 -1 # 列表被清空 (empty list or set) # 情况 4: start 和 stop 都比列表的最大下标要大,并且 start > stop redis> RPUSH new-alpha "h" "e" "l" "l" "o" # 重新建立一个新列表 (integer) 5 redis> LRANGE new-alpha 0 -1 1) "h" 2) "e" 3) "l" 4) "l" 5) "o" redis> LTRIM new-alpha 123321 10086 # 执行 LTRIM OK redis> LRANGE new-alpha 0 -1 # 同样被清空 (empty list or set)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
blpop【了解】
格式
blpop key [key …] timeout- 1
描述
BLPOP 是列表的阻塞式(blocking)弹出原语。
它是 LPOP key 命令的阻塞版本,当给定列表内没有任何元素可供弹出的时候,连接将被 BLPOP 命令阻塞,直到等待超时或发现可弹出元素为止。
当给定多个
key参数时,按参数key的先后顺序依次检查各个列表,弹出第一个非空列表的头元素。如果列表为空,返回一个
nil。 否则,返回一个含有两个元素的列表,第一个元素是被弹出元素所属的key,第二个元素是被弹出元素的值。brpop【了解】
格式
brpop key [key …] timeout- 1
描述
BRPOP 是列表的阻塞式(blocking)弹出原语。
它是 RPOP key 命令的阻塞版本,当给定列表内没有任何元素可供弹出的时候,连接将被 BRPOP 命令阻塞,直到等待超时或发现可弹出元素为止。
当给定多个
key参数时,按参数key的先后顺序依次检查各个列表,弹出第一个非空列表的尾部元素。假如在指定时间内没有任何元素被弹出,则返回一个
nil和等待时长。 反之,返回一个含有两个元素的列表,第一个元素是被弹出元素所属的key,第二个元素是被弹出元素的值。案例代码
redis> LLEN course (integer) 0 redis> RPUSH course algorithm001 (integer) 1 redis> RPUSH course c++101 (integer) 2 redis> BRPOP course 30 1) "course" # 被弹出元素所属的列表键 2) "c++101" # 被弹出的元素- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
brpoplpush【了解】
格式
brpoplpush source destination timeout- 1
描述
BRPOPLPUSH 是 RPOPLPUSH source destination 的阻塞版本,当给定列表
source不为空时, BRPOPLPUSH 的表现和 RPOPLPUSH source destination 一样。当列表
source为空时, BRPOPLPUSH 命令将阻塞连接,直到等待超时,或有另一个客户端对source执行 [LPUSH key value value …] 或 [RPUSH key value value …] 命令为止。超时参数
timeout接受一个以秒为单位的数字作为值。超时参数设为0表示阻塞时间可以无限期延长(block indefinitely) 。假如在指定时间内没有任何元素被弹出,则返回一个
nil和等待时长。 反之,返回一个含有两个元素的列表,第一个元素是被弹出元素的值,第二个元素是等待时长。案例代码
# 非空列表 redis> BRPOPLPUSH msg reciver 500 "hello moto" # 弹出元素的值 (3.38s) # 等待时长 redis> LLEN reciver (integer) 1 redis> LRANGE reciver 0 0 1) "hello moto" # 空列表 redis> BRPOPLPUSH msg reciver 1 (nil) (1.34s)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
Set 集合类型【重点】
Redis 的 Set 是 string 类型的无序集合,集合成员是唯一的,即集合中不能出现重复的数据。
sadd【重点】
格式
sadd key member [member …]- 1
描述
将一个或多个
member元素加入到集合key当中,已经存在于集合的member元素将被忽略。假如
key不存在,则创建一个只包含member元素作成员的集合。当key不是集合类型时,返回一个错误。返回值为被添加到集合中的新元素的数量,不包括被忽略的元素。
案例代码
# 添加单个元素 redis> SADD bbs "discuz.net" (integer) 1 # 添加重复元素 redis> SADD bbs "discuz.net" (integer) 0 # 添加多个元素 redis> SADD bbs "tianya.cn" "groups.google.com" (integer) 2 redis> SMEMBERS bbs 1) "discuz.net" 2) "groups.google.com" 3) "tianya.cn"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
sismember【重点】
格式
sismember key member- 1
描述
判断
member元素是否集合key的成员。如果
member元素是集合的成员,返回1。 如果member元素不是集合的成员,或key不存在,返回0。案例代码
redis> SMEMBERS joe's_movies 1) "hi, lady" 2) "Fast Five" 3) "2012" redis> SISMEMBER joe's_movies "bet man" (integer) 0 redis> SISMEMBER joe's_movies "Fast Five" (integer) 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
spop【常用】
格式
spop key- 1
描述
移除并返回集合中的一个随机元素。当
key不存在或key是空集时,返回nil。如果只想获取一个随机元素,但不想该元素从集合中被移除的话,可以使用 [SRANDMEMBER key count] 命令。
案例代码
redis> SMEMBERS db 1) "MySQL" 2) "MongoDB" 3) "Redis" redis> SPOP db "Redis" redis> SMEMBERS db 1) "MySQL" 2) "MongoDB" redis> SPOP db "MySQL" redis> SMEMBERS db 1) "MongoDB"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
srandmember【常用】
格式
srandmember key [count]- 1
描述
如果命令执行时,只提供了
key参数,那么返回集合中的一个随机元素。从 Redis 2.6 版本开始, SRANDMEMBER 命令接受可选的
count参数:- 如果
count为正数,且小于集合基数,那么命令返回一个包含count个元素的数组,数组中的元素各不相同。如果count大于等于集合基数,那么返回整个集合。 - 如果
count为负数,那么命令返回一个数组,数组中的元素可能会重复出现多次,而数组的长度为count的绝对值。
该操作和 SPOP key 相似,但 SPOP key 将随机元素从集合中移除并返回,而 SRANDMEMBER 则仅仅返回随机元素,而不对集合进行任何改动。
返回值:只提供
key参数时,返回一个元素;如果集合为空,返回nil。 如果提供了count参数,那么返回一个数组;如果集合为空,返回空数组。案例代码
# 添加元素 redis> SADD fruit apple banana cherry (integer) 3 # 只给定 key 参数,返回一个随机元素 redis> SRANDMEMBER fruit "cherry" redis> SRANDMEMBER fruit "apple" # 给定 3 为 count 参数,返回 3 个随机元素 # 每个随机元素都不相同 redis> SRANDMEMBER fruit 3 1) "apple" 2) "banana" 3) "cherry" # 给定 -3 为 count 参数,返回 3 个随机元素 # 元素可能会重复出现多次 redis> SRANDMEMBER fruit -3 1) "banana" 2) "cherry" 3) "apple" redis> SRANDMEMBER fruit -3 1) "apple" 2) "apple" 3) "cherry" # 如果 count 是整数,且大于等于集合基数,那么返回整个集合 redis> SRANDMEMBER fruit 10 1) "apple" 2) "banana" 3) "cherry" # 如果 count 是负数,且 count 的绝对值大于集合的基数 # 那么返回的数组的长度为 count 的绝对值 redis> SRANDMEMBER fruit -10 1) "banana" 2) "apple" 3) "banana" 4) "cherry" 5) "apple" 6) "apple" 7) "cherry" 8) "apple" 9) "apple" 10) "banana" # SRANDMEMBER 并不会修改集合内容 redis> SMEMBERS fruit 1) "apple" 2) "cherry" 3) "banana" # 集合为空时返回 nil 或者空数组 redis> SRANDMEMBER not-exists (nil) redis> SRANDMEMBER not-eixsts 10 (empty list or set)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
srem【重点】
格式
srem key member [member …]- 1
描述
移除集合
key中的一个或多个member元素,不存在的member元素会被忽略。当key不是集合类型,返回一个错误。返回值为被成功移除的元素的数量,不包括被忽略的元素。
案例代码
# 测试数据 redis> SMEMBERS languages 1) "c" 2) "lisp" 3) "python" 4) "ruby" # 移除单个元素 redis> SREM languages ruby (integer) 1 # 移除不存在元素 redis> SREM languages non-exists-language (integer) 0 # 移除多个元素 redis> SREM languages lisp python c (integer) 3 redis> SMEMBERS languages (empty list or set)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
smove
格式
smove source destination member- 1
描述
将
member元素从source集合移动到destination集合。SMOVE 是原子性操作。
如果
source集合不存在或不包含指定的member元素,则 SMOVE 命令不执行任何操作,仅返回0。否则,member元素从source集合中被移除,并添加到destination集合中去。当
destination集合已经包含member元素时, SMOVE 命令只是简单地将source集合中的member元素删除。当
source或destination不是集合类型时,返回一个错误。如果
member元素被成功移除,返回1。 如果member元素不是source集合的成员,并且没有任何操作对destination集合执行,那么返回0。案例代码
redis> SMEMBERS songs 1) "Billie Jean" 2) "Believe Me" redis> SMEMBERS my_songs (empty list or set) redis> SMOVE songs my_songs "Believe Me" (integer) 1 redis> SMEMBERS songs 1) "Billie Jean" redis> SMEMBERS my_songs 1) "Believe Me"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
scard【重点】
格式
scard key- 1
描述
返回集合
key的基数(集合中元素的数量)。返回值为集合的基数。 当
key不存在时,返回0。案例代码
redis> SADD tool pc printer phone (integer) 3 redis> SCARD tool # 非空集合 (integer) 3 redis> DEL tool (integer) 1 redis> SCARD tool # 空集合 (integer) 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
smembers【重点】
格式
smembers key- 1
描述
返回集合
key中的所有成员。不存在的key被视为空集合。返回值为集合中的所有成员。
案例代码
# key 不存在或集合为空 redis> EXISTS not_exists_key (integer) 0 redis> SMEMBERS not_exists_key (empty list or set) # 非空集合 redis> SADD language Ruby Python Clojure (integer) 3 redis> SMEMBERS language 1) "Python" 2) "Ruby" 3) "Clojure"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
sinter
格式
sinter key [key …]- 1
描述
返回一个集合的全部成员,该集合是所有给定集合的交集。
不存在的
key被视为空集。当给定集合当中有一个空集时,结果也为空集(根据集合运算定律)。案例代码
redis> SMEMBERS group_1 1) "LI LEI" 2) "TOM" 3) "JACK" redis> SMEMBERS group_2 1) "HAN MEIMEI" 2) "JACK" redis> SINTER group_1 group_2 1) "JACK"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
sinterstore
格式
sinterstore destination key [key …]- 1
描述
这个命令类似于 [SINTER key key …] 命令,但它将结果保存到
destination集合,而不是简单地返回结果集。如果
destination集合已经存在,则将其覆盖。destination可以是key本身。返回值为结果集中的成员数量。
案例代码
redis> SMEMBERS songs 1) "good bye joe" 2) "hello,peter" redis> SMEMBERS my_songs 1) "good bye joe" 2) "falling" redis> SINTERSTORE song_interset songs my_songs (integer) 1 redis> SMEMBERS song_interset 1) "good bye joe"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
sunion
格式
sunion key [key …]- 1
描述
返回一个集合的全部成员,该集合是所有给定集合的并集。不存在的
key被视为空集。案例代码
redis> SMEMBERS songs 1) "Billie Jean" redis> SMEMBERS my_songs 1) "Believe Me" redis> SUNION songs my_songs 1) "Billie Jean" 2) "Believe Me"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
sunionstore
格式
sunionstore destination key [key …]- 1
描述
这个命令类似于 [SUNION key key …] 命令,但它将结果保存到
destination集合,而不是简单地返回结果集。如果
destination已经存在,则将其覆盖。destination可以是key本身。返回值为结果集中的元素数量。
案例代码
redis> SMEMBERS NoSQL 1) "MongoDB" 2) "Redis" redis> SMEMBERS SQL 1) "sqlite" 2) "MySQL" redis> SUNIONSTORE db NoSQL SQL (integer) 4 redis> SMEMBERS db 1) "MySQL" 2) "sqlite" 3) "MongoDB" 4) "Redis"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
sdiff
格式
sdiff key [key …]- 1
描述
返回一个集合的全部成员,该集合是所有给定集合之间的差集。
不存在的
key被视为空集。案例代码
redis> SMEMBERS peter's_movies 1) "bet man" 2) "start war" 3) "2012" redis> SMEMBERS joe's_movies 1) "hi, lady" 2) "Fast Five" 3) "2012" redis> SDIFF peter's_movies joe's_movies 1) "bet man" 2) "start war"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
sdiffstore
格式
sdiffstore destination key [key …]- 1
描述
这个命令的作用和 [SDIFF key key …] 类似,但它将结果保存到
destination集合,而不是简单地返回结果集。如果
destination集合已经存在,则将其覆盖。destination可以是key本身。返回值为结果集中的元素数量。
案例代码
redis> SMEMBERS joe's_movies 1) "hi, lady" 2) "Fast Five" 3) "2012" redis> SMEMBERS peter's_movies 1) "bet man" 2) "start war" 3) "2012" redis> SDIFFSTORE joe_diff_peter joe's_movies peter's_movies (integer) 2 redis> SMEMBERS joe_diff_peter 1) "hi, lady" 2) "Fast Five"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
ZSet 有序集合类型【重点】
Redis 有序集合 zset 和集合 set 一样也是 string 类型元素的集合,且不允许重复的成员。不同的是 zset 的每个元素都会关联一个分数(分数可以重复),redis 通过分数来为集合中的成员进行从小到大的排序。
zadd【重点】
格式
zadd key score member [[score member] [score member] …]- 1
描述
将一个或多个
member元素及其score值加入到有序集key当中。如果某个
member已经是有序集的成员,那么更新这个member的score值,并通过重新插入这个member元素,来保证该member在正确的位置上。score值可以是整数值或双精度浮点数。如果
key不存在,则创建一个空的有序集并执行 ZADD 操作。当key存在但不是有序集类型时,返回一个错误。返回值为被成功添加的新成员的数量,不包括那些被更新的、已经存在的成员。
案例代码
# 添加单个元素 redis> ZADD page_rank 10 google.com (integer) 1 # 添加多个元素 redis> ZADD page_rank 9 baidu.com 8 bing.com (integer) 2 redis> ZRANGE page_rank 0 -1 WITHSCORES 1) "bing.com" 2) "8" 3) "baidu.com" 4) "9" 5) "google.com" 6) "10" # 添加已存在元素,且 score 值不变 redis> ZADD page_rank 10 google.com (integer) 0 redis> ZRANGE page_rank 0 -1 WITHSCORES # 没有改变 1) "bing.com" 2) "8" 3) "baidu.com" 4) "9" 5) "google.com" 6) "10" # 添加已存在元素,但是改变 score 值 redis> ZADD page_rank 6 bing.com (integer) 0 redis> ZRANGE page_rank 0 -1 WITHSCORES # bing.com 元素的 score 值被改变 1) "bing.com" 2) "6" 3) "baidu.com" 4) "9" 5) "google.com" 6) "10"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
zscore
格式
zscore key member- 1
描述
返回有序集
key中,成员member的score值,以字符串形式表示。如果
member元素不是有序集key的成员,或key不存在,返回nil。案例代码
redis> ZRANGE salary 0 -1 WITHSCORES # 测试数据 1) "tom" 2) "2000" 3) "peter" 4) "3500" 5) "jack" 6) "5000" redis> ZSCORE salary peter # 注意返回值是字符串 "3500"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
zincrby
格式
zincrby key increment member- 1
描述
为有序集
key的成员member的score值加上增量increment。可以通过传递一个负数值
increment,让score减去相应的值,比如ZINCRBY key -5 member,就是让member的score值减去5。当
key不存在,或member不是key的成员时,ZINCRBY key increment member等同于ZADD key increment member。当
key不是有序集类型时,返回一个错误。score值可以是整数值或双精度浮点数。返回值为
member成员的新score值,以字符串形式表示。案例代码
redis> ZSCORE salary tom "2000" redis> ZINCRBY salary 2000 tom # tom 加薪啦! "4000"- 1
- 2
- 3
- 4
- 5
zcard【重点】
格式
zcard key- 1
描述
当
key存在且是有序集类型时,返回有序集的基数。当key不存在时,返回0。案例代码
redis > ZADD salary 2000 tom # 添加一个成员 (integer) 1 redis > ZCARD salary (integer) 1 redis > ZADD salary 5000 jack # 再添加一个成员 (integer) 1 redis > ZCARD salary (integer) 2 redis > EXISTS non_exists_key # 对不存在的 key 进行 ZCARD 操作 (integer) 0 redis > ZCARD non_exists_key (integer) 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
zcount【常用】
格式
zcount key min max- 1
描述
返回有序集
key中,score值在min和max之间(默认包括score值等于min或max)的成员的数量。案例代码
redis> ZRANGE salary 0 -1 WITHSCORES # 测试数据 1) "jack" 2) "2000" 3) "peter" 4) "3500" 5) "tom" 6) "5000" redis> ZCOUNT salary 2000 5000 # 计算薪水在 2000-5000 之间的人数 (integer) 3 redis> ZCOUNT salary 3000 5000 # 计算薪水在 3000-5000 之间的人数 (integer) 2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
zrange【重点】
格式
zrange key start stop [WITHSCORES]- 1
描述
返回有序集
key中,指定区间内的成员。其中成员的位置按
score值递增(从小到大)来排序。具有相同
score值的成员按字典序(lexicographical order )来排列。下标参数
start和stop都以0为底,也就是说,以0表示有序集第一个成员,以1表示有序集第二个成员,以此类推。 你也可以使用负数下标,以-1表示最后一个成员,-2表示倒数第二个成员,以此类推。超出范围的下标并不会引起错误。 比如说,当
start的值比有序集的最大下标还要大,或是start > stop时, ZRANGE 命令只是简单地返回一个空列表。 另一方面,假如stop参数的值比有序集的最大下标还要大,那么 Redis 将stop当作最大下标来处理。可以通过使用
WITHSCORES选项,来让成员和它的score值一并返回,返回列表以value1,score1, ..., valueN,scoreN的格式表示。 客户端库可能会返回一些更复杂的数据类型,比如数组、元组等。案例代码
redis > ZRANGE salary 0 -1 WITHSCORES # 显示整个有序集成员 1) "jack" 2) "3500" 3) "tom" 4) "5000" 5) "boss" 6) "10086" redis > ZRANGE salary 0 -1 # 显示整个有序集成员不带score 1) "jack" 2) "tom" 3) "boss" redis > ZRANGE salary 1 2 WITHSCORES # 显示有序集下标区间 1 至 2 的成员 1) "tom" 2) "5000" 3) "boss" 4) "10086" redis > ZRANGE salary 0 200000 WITHSCORES # 测试 end 下标超出最大下标时的情况 1) "jack" 2) "3500" 3) "tom" 4) "5000" 5) "boss" 6) "10086" redis > ZRANGE salary 200000 3000000 WITHSCORES # 测试当给定区间不存在于有序集时的情况 (empty list or set)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
zrevrange【重点】
格式
zrevrange key start stop [WITHSCORES]- 1
描述
返回有序集
key中,带有score值(可选)的有序集成员的列表。其中成员的位置按
score值递减(从大到小)来排列。 具有相同score值的成员按字典序的逆序(reverse lexicographical order)排列。除了成员按
score值递减的次序排列这一点外, ZREVRANGE 命令的其他方面和 [ZRANGE key start stop WITHSCORES] 命令一样。案例代码
redis> ZRANGE salary 0 -1 WITHSCORES # 递增排列 1) "peter" 2) "3500" 3) "tom" 4) "4000" 5) "jack" 6) "5000" redis> ZREVRANGE salary 0 -1 WITHSCORES # 递减排列 1) "jack" 2) "5000" 3) "tom" 4) "4000" 5) "peter" 6) "3500" redis> ZREVRANGE salary 0 -1 # 递减排列,不带score 1) "jack" 2) "tom" 3) "peter"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
zrangebyscore【常用】
格式
zrangebyscore key min max [WITHSCORES] [LIMIT offset count]- 1
描述
返回有序集
key中,所有score值介于min和max之间(包括等于min或max)的成员。有序集成员按score值递增(从小到大)次序排列。可选的
LIMIT参数指定返回结果的数量及区间(就像SQL中的SELECT LIMIT offset, count),注意当offset很大时,定位offset的操作可能需要遍历整个有序集,此过程最坏复杂度为 O(N) 时间。可选的
WITHSCORES参数决定结果集是单单返回有序集的成员,还是将有序集成员及其score值一起返回。 该选项自 Redis 2.0 版本起可用。min和max可以是-inf和+inf,这样一来,你就可以在不知道有序集的最低和最高score值的情况下,使用 ZRANGEBYSCORE 这类命令。默认情况下,区间的取值使用闭区间 (小于等于或大于等于),你也可以通过给参数前增加
(符号来使用可选的开区间 (小于或大于)。举个例子:
ZRANGEBYSCORE zset (1 5- 1
返回所有符合条件
1 < score <= 5的成员,而ZRANGEBYSCORE zset (5 (10- 1
则返回所有符合条件
5 < score < 10的成员。案例代码
redis> ZADD salary 2500 jack # 测试数据 (integer) 0 redis> ZADD salary 5000 tom (integer) 0 redis> ZADD salary 12000 peter (integer) 0 redis> ZRANGEBYSCORE salary -inf +inf # 显示整个有序集 1) "jack" 2) "tom" 3) "peter" redis> ZRANGEBYSCORE salary -inf +inf WITHSCORES # 显示整个有序集及成员的 score 值 1) "jack" 2) "2500" 3) "tom" 4) "5000" 5) "peter" 6) "12000" redis> ZRANGEBYSCORE salary -inf 5000 WITHSCORES # 显示工资 <=5000 的所有成员 1) "jack" 2) "2500" 3) "tom" 4) "5000" redis> ZRANGEBYSCORE salary (5000 400000 # 显示工资大于 5000 小于等于 400000 的成员 1) "peter"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
zrevrangebyscore【常用】
格式
zrevrangebyscore key max min [WITHSCORES] [LIMIT offset count]- 1
描述
返回有序集
key中,score值介于max和min之间(默认包括等于max或min)的所有的成员。有序集成员按score值递减(从大到小)的次序排列。具有相同
score值的成员按字典序的逆序(reverse lexicographical order )排列。除了成员按
score值递减的次序排列这一点外, ZREVRANGEBYSCORE 命令的其他方面和 [ZRANGEBYSCORE key min max WITHSCORES] [LIMIT offset count] 命令一样。案例代码
redis > ZADD salary 10086 jack (integer) 1 redis > ZADD salary 5000 tom (integer) 1 redis > ZADD salary 7500 peter (integer) 1 redis > ZADD salary 3500 joe (integer) 1 redis > ZREVRANGEBYSCORE salary +inf -inf # 逆序排列所有成员 1) "jack" 2) "peter" 3) "tom" 4) "joe" redis > ZREVRANGEBYSCORE salary 10000 2000 # 逆序排列薪水介于 10000 和 2000 之间的成员 1) "peter" 2) "tom" 3) "joe"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
zrank【重点】
格式
zrank key member- 1
描述
返回有序集
key中成员member的排名。其中有序集成员按score值递增(从小到大)顺序排列。排名以
0为底,也就是说,score值最小的成员排名为0。使用 ZREVRANK key member 命令可以获得成员按
score值递减(从大到小)排列的排名。如果
member是有序集key的成员,返回member的排名。 如果member不是有序集key的成员,返回nil。案例代码
redis> ZRANGE salary 0 -1 WITHSCORES # 显示所有成员及其 score 值 1) "peter" 2) "3500" 3) "tom" 4) "4000" 5) "jack" 6) "5000" redis> ZRANK salary tom # 显示 tom 的薪水排名,第二 (integer) 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
zrevrank
格式
zrevrank key member- 1
描述
返回有序集
key中成员member的排名。其中有序集成员按score值递减(从大到小)排序。排名以
0为底,也就是说,score值最大的成员排名为0。使用 ZRANK key member 命令可以获得成员按score值递增(从小到大)排列的排名。如果
member是有序集key的成员,返回member的排名。 如果member不是有序集key的成员,返回nil。案例代码
redis 127.0.0.1:6379> ZRANGE salary 0 -1 WITHSCORES # 测试数据 1) "jack" 2) "2000" 3) "peter" 4) "3500" 5) "tom" 6) "5000" redis> ZREVRANK salary peter # peter 的工资排第二 (integer) 1 redis> ZREVRANK salary tom # tom 的工资最高 (integer) 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
zrem【重点】
格式
zrem key member [member …]- 1
描述
移除有序集
key中的一个或多个成员,不存在的成员将被忽略。当key存在但不是有序集类型时,返回一个错误。返回值为被成功移除的成员的数量,不包括被忽略的成员。
案例代码
# 测试数据 redis> ZRANGE page_rank 0 -1 WITHSCORES 1) "bing.com" 2) "8" 3) "baidu.com" 4) "9" 5) "google.com" 6) "10" # 移除单个元素 redis> ZREM page_rank google.com (integer) 1 redis> ZRANGE page_rank 0 -1 WITHSCORES 1) "bing.com" 2) "8" 3) "baidu.com" 4) "9" # 移除多个元素 redis> ZREM page_rank baidu.com bing.com (integer) 2 redis> ZRANGE page_rank 0 -1 WITHSCORES (empty list or set) # 移除不存在元素 redis> ZREM page_rank non-exists-element (integer) 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
zremrangebyrank
格式
zremrangebyrank key start stop- 1
描述
移除有序集
key中,指定排名(rank)区间内的所有成员。区间分别以下标参数
start和stop指出,包含start和stop在内。下标参数
start和stop都以0为底,也就是说,以0表示有序集第一个成员,以1表示有序集第二个成员,以此类推。 你也可以使用负数下标,以-1表示最后一个成员,-2表示倒数第二个成员,以此类推。返回值为被移除成员的数量。
案例代码
redis> ZADD salary 2000 jack (integer) 1 redis> ZADD salary 5000 tom (integer) 1 redis> ZADD salary 3500 peter (integer) 1 redis> ZREMRANGEBYRANK salary 0 1 # 移除下标 0 至 1 区间内的成员 (integer) 2 redis> ZRANGE salary 0 -1 WITHSCORES # 有序集只剩下一个成员 1) "tom" 2) "5000"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
zremrangebyscore
格式
zremrangebyscore key min max- 1
描述
移除有序集
key中,所有score值介于min和max之间(包括等于min或max)的成员。返回值为被移除成员的数量。
案例代码
redis> ZRANGE salary 0 -1 WITHSCORES # 显示有序集内所有成员及其 score 值 1) "tom" 2) "2000" 3) "peter" 4) "3500" 5) "jack" 6) "5000" redis> ZREMRANGEBYSCORE salary 1500 3500 # 移除所有薪水在 1500 到 3500 内的员工 (integer) 2 redis> ZRANGE salary 0 -1 WITHSCORES # 剩下的有序集成员 1) "jack" 2) "5000"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
zlexcount【了解】
格式
zlexcount key min max- 1
描述
对于一个所有成员的分值都相同的有序集合键
key来说, 这个命令会返回该集合中, 成员介于min和max范围内的元素数量。这个命令的
min参数和max参数的意义和 [ZRANGEBYLEX key min max LIMIT offset count] 命令的min参数和max参数的意义一样。返回值为指定范围内的元素数量。
案例代码
redis> ZADD myzset 0 a 0 b 0 c 0 d 0 e (integer) 5 redis> ZADD myzset 0 f 0 g (integer) 2 redis> ZLEXCOUNT myzset - + (integer) 7 redis> ZLEXCOUNT myzset [b [f (integer) 5- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
zremrangebylex
格式
zremrangebylex key min max- 1
描述
对于一个所有成员的分值都相同的有序集合键
key来说, 这个命令会移除该集合中, 成员介于min和max范围内的所有元素。这个命令的
min参数和max参数的意义和 [ZRANGEBYLEX key min max LIMIT offset count] 命令的min参数和max参数的意义一样。返回值为被移除的元素数量。
案例代码
redis> ZADD myzset 0 aaaa 0 b 0 c 0 d 0 e (integer) 5 redis> ZADD myzset 0 foo 0 zap 0 zip 0 ALPHA 0 alpha (integer) 5 redis> ZRANGE myzset 0 -1 1) "ALPHA" 2) "aaaa" 3) "alpha" 4) "b" 5) "c" 6) "d" 7) "e" 8) "foo" 9) "zap" 10) "zip" redis> ZREMRANGEBYLEX myzset [alpha [omega (integer) 6 redis> ZRANGE myzset 0 -1 1) "ALPHA" 2) "aaaa" 3) "zap" 4) "zip"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
zunionstore
格式
zunionstore destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX]- 1
描述
计算给定的一个或多个有序集的并集,其中给定
key的数量必须以numkeys参数指定,并将该并集(结果集)储存到destination。默认情况下,结果集中某个成员的
score值是所有给定集下该成员score值之和 。返回值为保存到
destination的结果集的基数。案例代码
redis> ZRANGE programmer 0 -1 WITHSCORES 1) "peter" 2) "2000" 3) "jack" 4) "3500" 5) "tom" 6) "5000" redis> ZRANGE manager 0 -1 WITHSCORES 1) "herry" 2) "2000" 3) "mary" 4) "3500" 5) "bob" 6) "4000" redis> ZUNIONSTORE salary 2 programmer manager WEIGHTS 1 3 # 公司决定加薪。。。除了程序员。。。 (integer) 6 redis> ZRANGE salary 0 -1 WITHSCORES 1) "peter" 2) "2000" 3) "jack" 4) "3500" 5) "tom" 6) "5000" 7) "herry" 8) "6000" 9) "mary" 10) "10500" 11) "bob" 12) "12000"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
zinterstore
格式
zinterstore destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX]- 1
描述
计算给定的一个或多个有序集的交集,其中给定
key的数量必须以numkeys参数指定,并将该交集(结果集)储存到destination。默认情况下,结果集中某个成员的
score值是所有给定集下该成员score值之和.返回值为保存到
destination的结果集的基数。案例代码
redis > ZADD mid_test 70 "Li Lei" (integer) 1 redis > ZADD mid_test 70 "Han Meimei" (integer) 1 redis > ZADD mid_test 99.5 "Tom" (integer) 1 redis > ZADD fin_test 88 "Li Lei" (integer) 1 redis > ZADD fin_test 75 "Han Meimei" (integer) 1 redis > ZADD fin_test 99.5 "Tom" (integer) 1 redis > ZINTERSTORE sum_point 2 mid_test fin_test (integer) 3 redis > ZRANGE sum_point 0 -1 WITHSCORES # 显示有序集内所有成员及其 score 值 1) "Han Meimei" 2) "145" 3) "Li Lei" 4) "158" 5) "Tom" 6) "199"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Redis 数据库常规命令
ping
描述
使用客户端向 Redis 服务器发送一个
PING,如果服务器运作正常的话,会返回一个PONG,否则返回一个连接错误。通常用于测试与服务器的连接是否仍然生效,或者用于测量延迟值。
案例代码
# 客户端和服务器连接正常 redis> PING PONG # 客户端和服务器连接不正常(网络不正常或服务器未能正常运行) redis 127.0.0.1:6379> PING Could not connect to Redis at 127.0.0.1:6379: Connection refused- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

exists【重点】
格式
exists key [key …]- 1
描述
检查给定
key是否存在。若key存在,返回1,否则返回0。案例代码
redis> SET db "redis" OK redis> SET db1 "mysql" OK redis> EXISTS db (integer) 1 redis> EXISTS db db1 (integer) 2 redis> DEL db (integer) 1 redis> EXISTS db (integer) 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
type【常用】
格式
type key- 1
描述
返回
key所储存的值的类型。返回值 描述 nonekey不存在 `string 字符串 list列表 set集合 zset有序集 hash哈希表 stream流 案例代码
# 字符串 redis> SET weather "sunny" OK redis> TYPE weather string # 列表 redis> LPUSH book_list "programming in scala" (integer) 1 redis> TYPE book_list list # 集合 redis> SADD pat "dog" (integer) 1 redis> TYPE pat set- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
rename
格式
rename key newkey- 1
描述
将
key改名为newkey。当
key和newkey相同,或者key不存在时,返回一个错误。当
newkey已经存在时, RENAME 命令将覆盖旧值。案例代码
# key 存在且 newkey 不存在 redis> SET message "hello world" OK redis> RENAME message greeting OK redis> EXISTS message # message 不复存在 (integer) 0 redis> EXISTS greeting # greeting 取而代之 (integer) 1 # 当 key 不存在时,返回错误 redis> RENAME fake_key never_exists (error) ERR no such key # newkey 已存在时, RENAME 会覆盖旧 newkey redis> SET pc "lenovo" OK redis> SET personal_computer "dell" OK redis> RENAME pc personal_computer OK redis> GET pc (nil) redis:1> GET personal_computer # 原来的值 dell 被覆盖了 "lenovo"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
del【重点】
格式
del key [key …]- 1
描述
删除给定的一个或多个
key。不存在的key会被忽略。返回值为被删除key的数量案例代码
# 删除单个 key redis> SET name huangz OK redis> DEL name (integer) 1 # 删除一个不存在的 key redis> EXISTS phone (integer) 0 redis> DEL phone # 失败,没有 key 被删除 (integer) 0 # 同时删除多个 key redis> SET name "redis" OK redis> SET type "key-value store" OK redis> SET website "redis.com" OK redis> DEL name type website (integer) 3- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
dbsize
描述
返回当前数据库的 key 的数量。
案例代码
redis> DBSIZE (integer) 5 redis> SET new_key "hello_moto" # 增加一个 key 试试 OK redis> DBSIZE (integer) 6- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
keys【慎用】
格式
keys pattern- 1
描述
查找所有符合给定模式
pattern的key, 可以使用通配符。通配符:● * :表示 0-多个字符
● ?:表示单个字符
比如说:
KEYS *匹配数据库中所有key。KEYS h?llo匹配hello,hallo和hxllo等。KEYS h*llo匹配hllo和heeeeello等。KEYS h[ae]llo匹配hello和hallo,但不匹配hillo。
特殊符号用
\隔开。KEYS 的速度非常快,但在一个大的数据库中使用它仍然可能造成性能问题,如果你需要从一个数据集中查找特定的
key,你最好还是用 Redis 的集合结构(set)来代替。案例代码
redis> MSET one 1 two 2 three 3 four 4 # 一次设置 4 个 key OK redis> KEYS *o* 1) "four" 2) "two" 3) "one" redis> KEYS t?? 1) "two" redis> KEYS t[w]* 1) "two" redis> KEYS * # 匹配数据库内所有 key 1) "four" 2) "three" 3) "two" 4) "one"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
flushdb【慎用】
描述
清空当前数据库中的所有 key。此命令从不失败。总是返回 OK
案例代码
redis> DBSIZE # 清空前的 key 数量 (integer) 4 redis> FLUSHDB OK redis> DBSIZE # 清空后的 key 数量 (integer) 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
flushall【慎用】
描述
清空整个 Redis 服务器的数据(删除所有数据库的所有 key )。此命令从不失败。总是返回
OK。案例代码
redis> DBSIZE # 0 号数据库的 key 数量 (integer) 9 redis> SELECT 1 # 切换到 1 号数据库 OK redis[1]> DBSIZE # 1 号数据库的 key 数量 (integer) 6 redis[1]> flushall # 清空所有数据库的所有 key OK redis[1]> DBSIZE # 不但 1 号数据库被清空了 (integer) 0 redis[1]> SELECT 0 # 0 号数据库(以及其他所有数据库)也一样 OK redis> DBSIZE (integer) 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
select
格式
select index- 1
描述
切换到指定的数据库,数据库索引号
index用数字值指定,以0作为起始索引值。默认使用
0号数据库。总是返回 OK案例代码
redis> SET db_number 0 # 默认使用 0 号数据库 OK redis> SELECT 1 # 使用 1 号数据库 OK redis[1]> GET db_number # 已经切换到 1 号数据库,注意 Redis 现在的命令提示符多了个 [1] (nil) redis[1]> SET db_number 1 OK redis[1]> GET db_number "1" redis[1]> SELECT 3 # 再切换到 3 号数据库 OK redis[3]> # 提示符从 [1] 改变成了 [3]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
quit | exit
描述
请求服务器关闭与当前客户端的连接。一旦所有等待中的回复(如果有的话)顺利写入到客户端,连接就会被关闭。
总是返回
OK(但是不会被打印显示,因为当时 Redis-cli 已经退出)。案例代码
$ redis redis> QUIT $- 1
- 2
- 3
- 4
- 5
shutdown
格式
shutdown [save|nosave]- 1
描述
SHUTDOWN 命令执行以下操作:
- 停止所有客户端
- 如果有至少一个保存点在等待,执行 SAVE 命令
- 如果 AOF 选项被打开,更新 AOF 文件
- 关闭 redis 服务器(server)
如果持久化被打开的话, SHUTDOWN 命令会保证服务器正常关闭而不丢失任何数据。
另一方面,假如只是单纯地执行 SAVE 命令,然后再执行 QUIT 命令,则没有这一保证 —— 因为在执行 SAVE 之后、执行 QUIT 之前的这段时间中间,其他客户端可能正在和服务器进行通讯,这时如果执行 QUIT 就会造成数据丢失。
通过使用可选的修饰符,可以修改 SHUTDOWN 命令的表现。比如说:
- 执行
SHUTDOWN SAVE会强制让数据库执行保存操作,即使没有设定(configure)保存点 - 执行
SHUTDOWN NOSAVE会阻止数据库执行保存操作,即使已经设定有一个或多个保存点(你可以将这一用法看作是强制停止服务器的一个假想的 ABORT 命令)
案例代码
redis> PING PONG redis> SHUTDOWN $ $ redis Could not connect to Redis at: Connection refused not connected>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Redis 自动过期命令
expire【重点】
格式
expire key seconds- 1
描述
为给定
key设置生存时间,当key过期时(生存时间为0),它会被自动删除。设置成功返回
1。 当key不存在或者不能为key设置生存时间时(比如在低于 2.1.3 版本的 Redis 中你尝试更新key的生存时间),返回0。可以对一个已经带有生存时间的
key执行EXPIRE命令,新指定的生存时间会取代旧的生存时间。案例代码
redis> SET cache_page "www.google.com" OK redis> EXPIRE cache_page 30 # 设置过期时间为 30 秒 (integer) 1 redis> TTL cache_page # 查看剩余生存时间 (integer) 23 redis> EXPIRE cache_page 30000 # 更新过期时间 (integer) 1 redis> TTL cache_page (integer) 29996- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
expireat
格式
expireat key timestamp- 1
描述
EXPIREAT的作用和EXPIRE类似,都用于为key设置生存时间。不同在于
EXPIREAT命令接受的时间参数是 UNIX 时间戳(unix timestamp)。如果生存时间设置成功,返回
1; 当key不存在或没办法设置生存时间,返回0。案例代码
redis> SET cache www.google.com OK redis> EXPIREAT cache 1355292000 # 这个 key 将在 1355292000 毫秒后过期 (integer) 1 redis> TTL cache (integer) 45081860- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
ttl【重点】
格式
ttl key- 1
描述
以秒为单位,返回给定
key的剩余生存时间(TTL, time to live)。当
key不存在时,返回-2。 当key存在但没有设置剩余生存时间时,返回-1。 否则,以秒为单位,返回key的剩余生存时间。在 Redis 2.8 以前,当
key不存在,或者key没有设置剩余生存时间时,命令都返回-1。案例代码
# 不存在的 key redis> FLUSHDB OK redis> TTL key (integer) -2 # key 存在,但没有设置剩余生存时间 redis> SET key value OK redis> TTL key (integer) -1 # 有剩余生存时间的 key redis> EXPIRE key 10086 (integer) 1 redis> TTL key (integer) 10084- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
presist
格式
presist key- 1
描述
移除给定
key的生存时间,将这个key从“易失的”(带生存时间key)转换成“持久的”(一个不带生存时间、永不过期的key)。当生存时间移除成功时,返回
1. 如果key不存在或key没有设置生存时间,返回0。案例代码
redis> SET mykey "Hello" OK redis> EXPIRE mykey 10 # 为 key 设置生存时间 (integer) 1 redis> TTL mykey (integer) 10 redis> PERSIST mykey # 移除 key 的生存时间 (integer) 1 redis> TTL mykey (integer) -1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Redis 事务【了解】
事务概述
事务是指一系列操作步骤,这一系列的操作步骤,要么完全地执行,要么完全地不执行。
Redis 中的事务(transaction)是一组命令的集合,至少是两个或两个以上的命令,redis 事务保证这些命令被执行时中间不会被任何其他操作打断。
multi
描述
标记一个事务块的开始。
事务块内的多条命令会按照先后顺序被放进一个队列当中,最后由 EXEC 命令原子性(atomic)地执行。
返回值总是
OK。案例代码
redis> MULTI # 标记事务开始 OK redis> INCR user_id # 多条命令按顺序入队 QUEUED redis> INCR user_id QUEUED redis> INCR user_id QUEUED redis> PING QUEUED redis> EXEC # 执行 1) (integer) 1 2) (integer) 2 3) (integer) 3 4) PONG- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
exec
描述
执行所有事务块内的命令。
假如某个(或某些) key 正处于 WATCH 命令的监视之下,且事务块中有和这个(或这些) key 相关的命令,那么 EXEC 命令只在这个(或这些) key 没有被其他命令所改动的情况下执行并生效,否则该事务被打断(abort)。
事务块内所有命令的返回值,按命令执行的先后顺序排列。
当操作被打断时,返回空值
nil。案例代码
# 事务被成功执行 redis> MULTI OK redis> INCR user_id QUEUED redis> INCR user_id QUEUED redis> INCR user_id QUEUED redis> PING QUEUED redis> EXEC 1) (integer) 1 2) (integer) 2 3) (integer) 3 4) PONG # 监视 key ,且事务成功执行 redis> WATCH lock lock_times OK redis> MULTI OK redis> SET lock "huangz" QUEUED redis> INCR lock_times QUEUED redis> EXEC 1) OK 2) (integer) 1 # 监视 key ,且事务被打断 redis> WATCH lock lock_times OK redis> MULTI OK redis> SET lock "joe" # 就在这时,另一个客户端修改了 lock_times 的值 QUEUED redis> INCR lock_times QUEUED redis> EXEC # 因为 lock_times 被修改, joe 的事务执行失败 (nil)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
discard
描述
取消事务,放弃执行事务块内的所有命令。
如果正在使用
WATCH命令监视某个(或某些) key,那么取消所有监视,等同于执行命令UNWATCH。总是返回
OK。案例代码
redis> MULTI OK redis> PING QUEUED redis> SET greeting "hello" QUEUED redis> DISCARD OK- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
watch
格式
watch key [key …]- 1
描述
监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。
总是返回
OK。案例代码
客户端一
127.0.0.1:6379> set age 1 OK 127.0.0.1:6379> watch age OK 127.0.0.1:6379> multi OK 127.0.0.1:6379> set age 10 QUEUED- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
客户端二
127.0.0.1:6379> set age 20 OK 127.0.0.1:6379> get age "20"- 1
- 2
- 3
- 4
客户端一
127.0.0.1:6379> exec (nil) 127.0.0.1:6379> get age "20"- 1
- 2
- 3
- 4
unwatch
描述
取消 WATCH 命令对所有 key 的监视。
如果在执行 WATCH 命令之后, EXEC 命令或 DISCARD 命令先被执行了的话,那么就不需要再执行 UNWATCH 了。
因为 EXEC 命令会执行事务,因此 WATCH 命令的效果已经产生了;而 DISCARD 命令在取消事务的同时也会取消所有对 key 的监视,因此这两个命令执行之后,就没有必要执行 UNWATCH 了。
总是返回 OK
案例代码
redis> WATCH lock lock_times OK redis> UNWATCH OK- 1
- 2
- 3
- 4
- 5
扩展:Redis witch机制
1、Redis 的 WATCH 机制
WATCH 机制原理:
WATCH 机制:使用 WATCH 监视一个或多个 key , 跟踪 key 的 value 修改情况, 如果有key 的 value 值在事务 EXEC 执行之前被修改了, 整个事务被取消。EXEC 返回提示信息,表示事务已经失败。
WATCH 机制使的事务 EXEC 变的有条件,事务只有在被 WATCH 的 key 没有修改的前提下才能执行。不满足条件,事务被取消。使用 WATCH 监视了一个带过期时间的键, 那么即使这个键过期了, 事务仍然可以正常执行。
大多数情况下, 不同的客户端会访问不同的键, 相互同时竞争同一 key 的情况一般都很少, 乐观锁能够以很好的性能解决数据冲突的问题。
2、何时取消 key 的监视(WATCH)
① WATCH 命令可以被调用多次。 对键的监视从 WATCH 执行之后开始生效, 直到调用 EXEC 为止。不管事务是否成功执行, 对所有键的监视都会被取消。
② 当客户端断开连接时, 该客户端对键的监视也会被取消。
③ UNWATCH 命令可以手动取消对所有键的监视
类似 MySQL 中的乐观锁
总结
1.单独的隔离操作
事务中的所有命令都会序列化,然后按顺序执行,在执行过程中,不会被其他客户端发送的命令打断。
2.没有隔离级别的概念
队列中的命令没有被提交之前都不会执行。
3.不能保证原子性
Redis 同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,不会回滚
Redis 持久化【重点】
持久化概述
持久化可以理解为存储,就是将数据存储到一个不会丢失的地方,如果把数据放在内存中,电脑关闭或重启数据就会丢失,所以放在内存中的数据不是持久化的,而放在磁盘就算是一种持久化。
Redis 的数据存储在内存中,内存是瞬时的,如果 linux 宕机或重启,又或者 Redis 崩溃或重启,所有的内存数据都会丢失,为解决这个问题,Redis 提供两种机制对数据进行持久化存储,便于发生故障后能迅速恢复数据。分别为 RDB 和 AOF。
RDB 方式
什么是 RDB 方式?
Redis Database(RDB),就是在指定的时间间隔内将内存中的数据集快照写入磁盘,数据恢复时将快照文件直接再读到内存。
RDB 保存了在某个时间点的数据集(全部数据)。存储在一个二进制文件中,只有一个文件。默认是 dump.rdb。RDB 技术非常适合做备份,可以保存最近一个小时,一天,一个月的全部数据。保存数据是在单独的进程中写文件,不影响 Redis 的正常使用。RDB 恢复数据时比其他 AOF 速度快。
配置 RDB 方式
RDB 方式的数据持久化,仅需在 redis.conf 文件中配置即可,默认配置是启用的。
在配置文件 redis.conf 中搜索 SNAPSHOTTING, 查找在注释开始和结束之间的关于 RDB的配置说明。
①:配置执行 RDB 生成快照文件的时间策略。
对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个 key 改动”这一条件被满足时, 自动保存一次数据集。
# 配置格式 save# 900秒内,如果超过1个key被修改,则发起快照保存 save 900 1 # 300秒内,如果超过10个key被修改,则发起快照保存 save 300 10 # 60秒内,如果1万个key被修改,则发起快照保存 save 60 10000 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

②:dbfilename:设置 RDB 的文件名,默认文件名为 dump.rdb
③:dir:指定 RDB 文件的存储位置,默认是 ./ 当前目录
【注意】RDB 方式存储的数据会在 dump.rdb 文件中(默认情况下在哪个目录启动redis服务端,该文件就会在对应目录下生成),该文件不能查看,如需备份,对 Redis 操作完成之后,只需拷贝该文件即可(Redis服务端启动时会自动加载该文件)。
AOF 方式
什么是 AOF 方式
Append-only File(AOF),Redis 每次接收到一条改变数据的命令时,它将把该命令写到一个 AOF 文件中(只记录写操作,读操作不记录),当 Redis 重启时,它通过执行 AOF 文件中所有的命令来恢复数据。
如何配置
AOF 方式的数据持久化,仅需在 redis.conf 文件中配置即可配置项:
①:appendonly:默认是 no,改成 yes 即开启了 aof 持久化

②:appendfilename:指定 AOF 文件名,默认文件名为 appendonly.aof

③:dir : 指定 RDB 和 AOF 文件存放的目录,默认是 ./
④:appendfsync:配置向 aof 文件写命令数据的策略:
- no:不主动进行同步操作,而是完全交由操作系统来做(即每 30 秒一次),比较快但不是很安全。
- always:每次执行写入都会执行同步,慢一些但是比较安全的。
- everysec:每秒执行一次同步操作,比较平衡,介于速度和安全之间。这是默认项。

⑤:auto-aof-rewrite-min-size:允许重写的最小 AOF 文件大小,默认是 64M 。当 aof 文件大于 64M 时,开始整理 aop 文件, 去掉无用的操作命令。缩小 aop 文件。

【注意】
1、AOF 不是默认开启的。
2、如果 AOF 和 RDB 同时开启,系统会默认读取AOF的数据(aof 数据最完整)。
RDB 与 AOF 的优缺点【重点】
RDB 优点
-
如果要进行大规模数据的恢复,RDB方式要比AOF方式恢复速度要快。
-
RDB是一个非常紧凑(compact)的文件,它保存了某个时间点的数据集,非常适合用作备份,同时也非常适合用作灾难性恢复,它只有一个文件,内容紧凑,通过备份原文件到本机外的其他主机上,一旦本机发生宕机,就能将备份文件复制到redis安装目录下,通过启用服务就能完成数据的恢复。
RDB 缺点
RDB这种持久化方式不太适应对数据完整性要求严格的情况,因为,尽管我们可以用过修改快照实现持久化的频率,但是要持久化的数据是一段时间内的整个数据集的状态,如果在还没有触发快照时,本机就宕机了,那么对数据库所做的写操作就随之而消失了并没有持久化本地dump.rdb文件中。
AOF 优点
- AOF有着多种持久化策略。
- AOF文件是一个只进行追加操作的日志文件,对文件写入不需要进行seek,即使在追加的过程中,写入了不完整的命令(例如:磁盘已满),可以使用redis-check-aof工具可以修复这种问题。
- Redis可以在AOF文件变得过大时,会自动地在后台对AOF进行重写:重写后的新的AOF文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为Redis在创建AOF文件的过程中,会继续将命令追加到现有的AOF文件中,即使在重写的过程中发生宕机,现有的AOF文件也不会丢失。一旦新AOF文件创建完毕,Redis就会从旧的AOF文件切换到新的AOF文件,并对新的AOF文件进行追加操作。
AOF 缺点
-
对于相同的数据集来说,AOF文件要比RDB文件大。
-
根据所使用的持久化策略来说,AOF的速度要慢于RDB。一般情况下,每秒同步策略效果较好。不使用同步策略的情况下,AOF与RDB速度一样快。
Redis 主从复制【重点】
通过持久化功能,Redis 保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,但是由于数据是存储在一台服务器上的,如果这台服务器出现故障,比如硬盘坏了, 也会导致数据丢失。
为了避免单点故障,我们需要将数据复制多份部署在多台不同的服务器上,即使有一台服务器出现故障其他服务器依然可以继续提供服务。
这就要求当一台服务器上的数据更新后,自动将更新的数据同步到其他服务器上。可以通过 Redis 的主从复制实现。
概述
主从复制是指将一台 Redis 服务器的数据,复制到其它的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点,且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。

作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复,但实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是 Redis 高可用的基础。
配置
1、查看当前库的信息:
[root@localhost src]# ./redis-cli --raw 127.0.0.1:6379> info replication # Replication role:master connected_slaves:0 master_replid:0814298ee615e647280caa5e98f6867f6fd45fa1 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

可以看到,role角色是master,connected_slaves从属为0个
2、复制三个配置文件并分别改个名字
[root@localhost redis-5.0.4]# cp redis.conf redis6379.conf [root@localhost redis-5.0.4]# cp redis.conf redis6380.conf [root@localhost redis-5.0.4]# cp redis.conf redis6381.conf- 1
- 2
- 3

3、分别配置三个redis.conf文件
[root@localhost redis-5.0.4]# vim redis6379.conf port 6379 pidfile /var/run/redis_6379.pid logfile "6379.log" dbfilename dump6379.rdb- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
[root@localhost redis-5.0.4]# vim redis6380.conf port 6380 pidfile /var/run/redis_63780pid logfile "6380.log" dbfilename dump6380.rdb slaveof 127.0.0.1 6379- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
[root@localhost redis-5.0.4]# vim redis6381.conf port 6381 pidfile /var/run/redis_6381.pid logfile "6381.log" dbfilename dump6381.rdb- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4、启动第一台服务器,并使用6379端口号登录到客户端,查看结果如下。
[root@l[root@localhost src]# ./redis-server ../redis6379.conf & [1] 73510 [root@localhost src]# ps -ef | grep redis root 73510 109368 0 21:30 pts/1 00:00:00 ./redis-server *:6379 root 73935 109368 0 21:31 pts/1 00:00:00 grep --color=auto redis ocalhost src]# ./redis-cli -p 6379 127.0.0.1:6379> info replication # Replication role:master connected_slaves:0 master_replid:0ea2a9c726b0d70f444c94b1ea9b8991c2e54d5c master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
5、启动第二台服务器,并使用6380端口号登录到客户端,查看结果如下。
[root@localhost src]# ./redis-server ../redis6380.conf & [2] 81266 [root@localhost src]# ps -ef | grep redis root 74428 109368 0 21:31 pts/1 00:00:00 ./redis-server *:6379 root 81266 109368 0 21:36 pts/1 00:00:00 ./redis-server *:6380 root 82095 109368 0 21:37 pts/1 00:00:00 grep --color=auto redis [root@localhost src]# ./redis-cli -p 6380 127.0.0.1:6380> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:5 master_sync_in_progress:0 slave_repl_offset:182 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:267a91039148ad9d37e6f0a7a27e27007532e174 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:182 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:182- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
这个时候发现我们的6380已经变成一个从服务器了,它的主服务器为127.0.0.1下的6379,也就是我们刚刚配的那台。

5、切换到6379端口的客户端下并查看
[root@localhost src]# ./redis-cli -p 6379 127.0.0.1:6379> info replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6380,state=online,offset=378,lag=1 master_replid:267a91039148ad9d37e6f0a7a27e27007532e174 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:378 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:378- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这个时候我们发现已经有了一台从属的从机,就是我们刚刚配置好的6380

6、开启第三台服务器
[root@localhost src]# ./redis-server ../redis6381.conf & [3] 89192 [root@localhost src]# ps -ef | grep redis root 74428 109368 0 21:31 pts/1 00:00:00 ./redis-server *:6379 root 81266 109368 0 21:36 pts/1 00:00:00 ./redis-server *:6380 root 89192 109368 0 21:43 pts/1 00:00:00 ./redis-server *:6381 root 89450 109368 0 21:43 pts/1 00:00:00 grep --color=auto redis- 1
- 2
- 3
- 4
- 5
- 6
- 7
7、使用6381登录到客户端
[root@localhost src]# ./redis-cli -p 6381 127.0.0.1:6381> info replication # Replication role:master connected_slaves:0 master_replid:89db8b5dd16041012a5e8064f901974d76eacbe3 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这个时候我们的6381还是一台主服务器,通过命令配置成从服务器
127.0.0.1:6381> slaveof 127.0.0.1 6379 OK 127.0.0.1:6381> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:4 master_sync_in_progress:0 slave_repl_offset:784 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:267a91039148ad9d37e6f0a7a27e27007532e174 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:784 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:785 repl_backlog_histlen:0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这个时候我们发现6381变成了6379的从服务器

8、使用6379登录到服务器
[root@localhost src]# ./redis-cli -p 6379 127.0.0.1:6379> info replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6380,state=online,offset=1106,lag=1 slave1:ip=127.0.0.1,port=6381,state=online,offset=1106,lag=1 master_replid:267a91039148ad9d37e6f0a7a27e27007532e174 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:1120 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:1120- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这个时候我们的6379已经有两台从机了。

9、分别开三个窗口,连接到对应端口的 Redis-cli 上。
10、在主服务器上写数据。
[root@localhost src]# ./redis-cli -p 6379 127.0.0.1:6379> set k1 v1 OK 127.0.0.1:6379> set k2 v2 OK 127.0.0.1:6379> keys * 1) "k2" 2) "k1" 127.0.0.1:6379> get k1 "v1" 127.0.0.1:6379> get k2 "v2"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
11、在两个从服务器上分别做测试
[root@localhost src]# ./redis-cli -p 6380 127.0.0.1:6380> keys * 1) "k2" 2) "k1" 127.0.0.1:6380> get k1 "v1" 127.0.0.1:6380> get k2 "v2" 127.0.0.1:6380> set k1 v3 (error) READONLY You can't write against a read only replica.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

[root@localhost src]# ./redis-cli -p 6381 127.0.0.1:6380> keys * 1) "k2" 2) "k1" 127.0.0.1:6380> get k1 "v1" 127.0.0.1:6380> get k2 "v2" 127.0.0.1:6380> set k1 v3 (error) READONLY You can't write against a read only replica.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

两台服务器都同步了主服务器中的数据,并且都只能做读操作,实现了读写分离。
容灾测试
即使主机断开链接,从机仍然可以连接到主机,如果使用的是命令行配置的从机,从机一旦断开链接后,就会变回主机了,如果再次变回从机,仍旧可以获取主机中的值。
1、关闭主服务器
127.0.0.1:6379> shutdown not connected> [1] 完成 ./redis-server ../redis6379.conf [root@localhost src]# ps -ef | grep redis root 43244 109368 0 22:13 pts/1 00:00:00 grep --color=auto redis root 81266 109368 0 21:36 pts/1 00:00:01 ./redis-server *:6380 root 89192 109368 0 21:43 pts/1 00:00:01 ./redis-server *:6381 root 109568 105784 0 21:57 pts/0 00:00:00 ./redis-cli -p 6380 root 111646 106057 0 21:57 pts/4 00:00:00 ./redis-cli -p 6381- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
此时主机已经关闭
2、查看从机状态
127.0.0.1:6380> set k1 v2 (error) READONLY You can't write against a read only replica. 127.0.0.1:6380> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:down master_last_io_seconds_ago:-1 master_sync_in_progress:0 slave_repl_offset:3077 master_link_down_since_seconds:90 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:267a91039148ad9d37e6f0a7a27e27007532e174 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:3077 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:3077- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
可以明显得看到主机已经挂掉了
3、使用命令让从机变成主机
# 此命令用于让从服务器变为主服务器 slaveof no one- 1
- 2
127.0.0.1:6380> slaveof no one OK 127.0.0.1:6380> info replication # Replication role:master connected_slaves:0 master_replid:9761af0d23e14f6a9fb79312ac96363d38063d96 master_replid2:267a91039148ad9d37e6f0a7a27e27007532e174 master_repl_offset:3077 second_repl_offset:3078 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:3077 127.0.0.1:6380> get k1 "v1" 127.0.0.1:6380> get k2 "v2" 127.0.0.1:6380> set k3 v3 OK- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
此时6380的状态已经变成了主机,并能够进行正常的读写操作,但是却没有从机
4、让6381变成6380的主机
127.0.0.1:6381> slaveof 127.0.0.1 6380 OK 127.0.0.1:6381> info replication # Replication role:slave master_host:127.0.0.0 master_port:6380 master_link_status:down master_last_io_seconds_ago:-1 master_sync_in_progress:0 slave_repl_offset:3077 master_link_down_since_seconds:237 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:267a91039148ad9d37e6f0a7a27e27007532e174 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:3077 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:785 repl_backlog_histlen:2293 127.0.0.1:6381> keys * 1) "k2" 2) "k3" 3) "k1" 127.0.0.1:6381> get k3 "v3"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
此时已经能够进行正常的读写操作。
5、此时6379再次重启,并当做6380的从机即可
[root@localhost src]# ./redis-server ../redis6379.conf & [4] 80292 [root@localhost src]# ./redis-cli -p 6379 127.0.0.1:6379> slaveof 127.0.0.1 6380 OK 127.0.0.1:6379> keys * 1) "k1" 2) "k3" 3) "k2" 127.0.0.1:6379> get k3 "v3"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
主从复制原理
Slave启动成功连接到master后会发送一个sync同步命令,Master接到命令后,会启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕后,master将传送整个数据文件到salve,并完成一次完整的同步。
全量复制:salve服务在接收到数据库文件数据后,将其存盘并加载到内存中.
增量复制:master继续将新的所有收集到的修改命令依次传递给salve,完成同步.
Redis 哨兵模式【重点】
概述
Sentinel 哨兵是 redis 官方提供的高可用方案,可以用它来监控多个 Redis 服务实例的运行情况。Redis Sentinel 是一个运行在特殊模式下的 Redis 服务器。Redis Sentinel 是在多个Sentinel 进程环境下互相协作工作的。
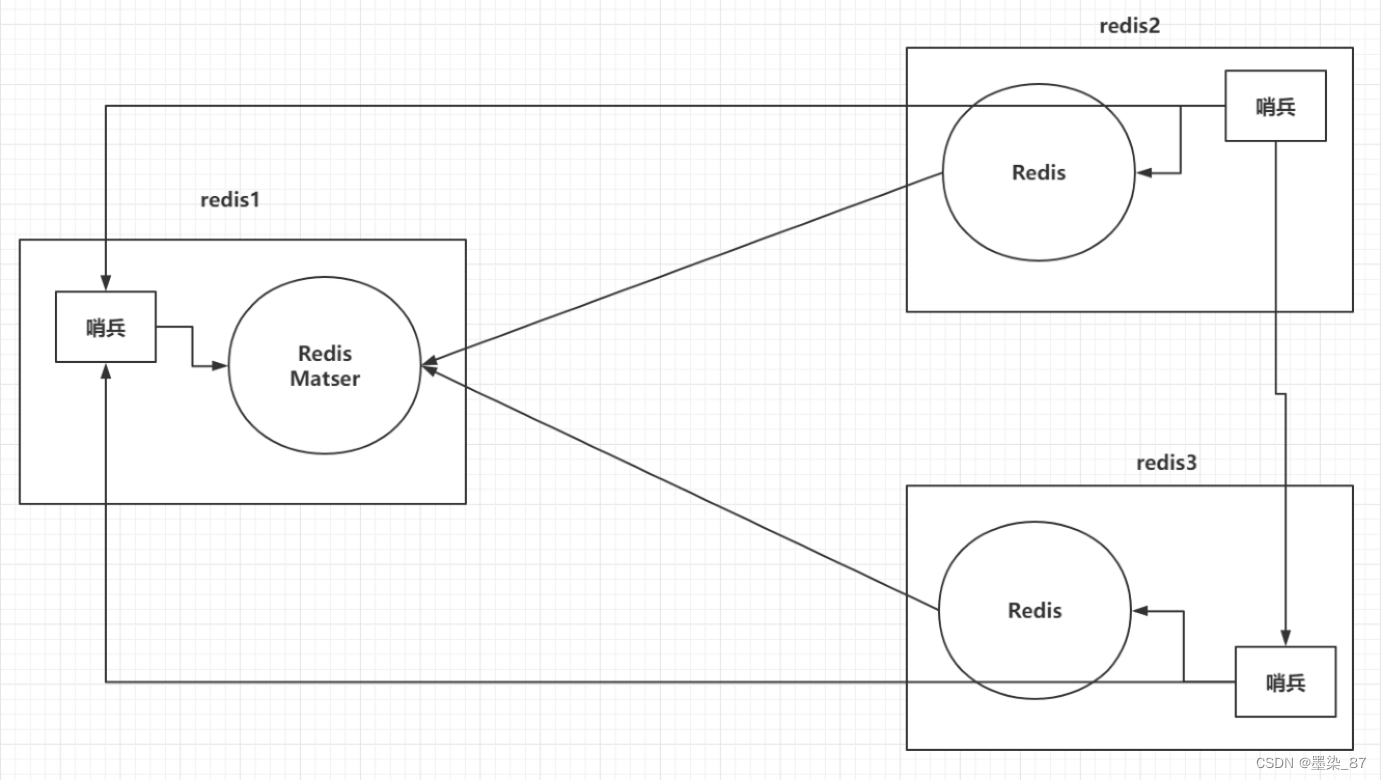
功能作用
-
监控(monitoring):Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
-
提醒(Notifation):当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
-
自动故障转移(Automatic failover):当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
配置
1、在 redis.conf 的同一级目录下的 sentinel.conf 就是哨兵的配置文件,将此文件复制三份,分别命名为 sentinel26379.conf、sentinel26380.conf、sentinel26381.conf
2、修改 sentinel26380.conf 的端口号

3、修改监控的 master 地址,因为主 master 的端口号为6379,所以这里不需要动
sentinel monitor :固定命令格式
mymaster : 哨兵名称【可修改】
127.0.0.1 :master的ip
6379 :master的端口号
2 :投票的数量

4、修改 sentinel26381.conf 的端口号

5、分别启动三个哨兵
[root@localhost src]# ./redis-sentinel ../sentinel26379.conf & [5] 27120- 1
- 2
[root@localhost src]# ./redis-sentinel ../sentinel26380.conf & [1] 37011- 1
- 2
[root@localhost src]# ./redis-sentinel ../sentinel26381.conf & [1] 39329- 1
- 2
任一个哨兵都能够检测到另外两个哨兵的存在。

6、此时已经启动了三个哨兵和三台服务器

7、此时使用6379登录客户端,并关闭 master 服务器
[root@localhost src]# ./redis-cli -p 6379 127.0.0.1:6379> info replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6380,state=online,offset=145959,lag=1 slave1:ip=127.0.0.1,port=6381,state=online,offset=146225,lag=0 master_replid:b1135818a282048d429241716495f271ef0764fb master_replid2:9761af0d23e14f6a9fb79312ac96363d38063d96 master_repl_offset:146225 second_repl_offset:7974 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:3382 repl_backlog_histlen:142844 127.0.0.1:6379> shutdown not connected> [root@localhost src]# ps -ef | grep redis root 27120 109368 0 00:59 pts/1 00:00:01 ./redis-sentinel *:26379 [sentinel] root 37011 105784 0 01:02 pts/0 00:00:01 ./redis-sentinel *:26380 [sentinel] root 39329 106057 0 01:03 pts/4 00:00:00 ./redis-sentinel *:26381 [sentinel] root 81266 109368 0 2月24 pts/1 00:00:08 ./redis-server *:6380 root 84457 56990 0 01:13 pts/6 00:00:00 grep --color=auto redis root 89192 109368 0 2月24 pts/1 00:00:08 ./redis-server *:6381- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
此时 master 已经被停止,稍等一会让哨兵做投票选举
8、这时候再查看哨兵的信息

发现 master 已经由6379切换到了6381
9、切换到 6381 启动的客户端

master 确实发生了替换,并且原本6379的从属6380也从属与6381。
10、此时再启动6379服务器并查看信息

自动变成了6381的从服务器
11、查看哨兵中的信息

发现哨兵起到了作用。
12、查看6381的信息

6379变成了6381的从服务器
优点
-
哨兵集群模式是基于主从模式的,所有主从的优点,哨兵模式同样具有。
-
主从可以切换,故障可以转移,系统可用性更好。
-
哨兵模式是主从模式的升级,系统更健壮,可用性更高。
缺点
-
Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
-
实现哨兵模式的配置也不简单,甚至可以说有些繁琐。
Redis 缓存穿透,击穿,雪崩,倾斜【重点】
缓存穿透(查不到)
概念
当用户去查询数据的时候,发现redis内存数据库中没有,于是向持久层数据库查询,发现也没有,于是查询失败,当用户过多时,缓存都没有查到,于是都去查持久层数据库,这会给持久层数据库造成很大的压力,此时相当于出现了缓存穿透。

解决方案
1、布隆过滤器:是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的压力.

2、缓存空对象:当存储层查不到时,即使返回的空对象也将其缓存起来,同时设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护后端数据.

但会有两个问题:
- 如果空值被缓存起来,就意味着需要更多的空间存储更多的键,会有很多空值的键
- 即使对空值设置了过期时间,还是会存在 缓存层和存储层会有一段时间窗口不一致,这对于需要保持一致性的业务会有影响
缓存击穿(访问量大,缓存过期)
概述
指对某一个key的频繁访问,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就会直接请求数据库,就像在一个屏障上凿开了一个洞,例如微博由于某个热搜导致宕机.
其实就是:当某个key在过期的瞬间,有大量的请求并发访问,这类数据一段是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并回写缓存,导致数据库瞬间压力过大。

解决方案
-
设置热点数据永不过期:从缓存层面上来说,不设置过期时间,就不会出现热点key过期后产生的问题
-
添加互斥锁:使用分布式锁,保证对每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可,这种方式将高并发的压力转移到了分布式锁上,对分布式锁也是一种极大的考验
缓存雪崩
概述
指在某一个时间段,缓存集中过期失效或Redis宕机导致的,例如双十一抢购热门商品,这些商品都会放在缓存中,假设缓存时间为一个小时,一个小时之后,这些商品的缓存都过期了,访问压力瞬间都来到了数据库上,此时数据库会产生周期性的压力波峰,所有的请求都会到达存储层,存储层的调用量暴增,造成存储层挂掉的情况.

其实比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网,因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,此时的数据库还是可以顶住压力的,而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,有可能瞬间就把服务器压垮。
解决方案
-
配置Redis的高可用:其实就是搭建集群环境,有更多的备用机
-
限流降级:在缓存失效后,通过加锁或者队列来控制读服务器以及写缓存的线程数量,比如对某个key只允许一个线程查询数据和写缓存,其他线程等待
-
数据预热:在项目正式部署之前,把可能用的数据预先访问一边,这样可以把一些数据加载到缓存中,在即将发生大并发访问之前手动触发加载缓存中不同的key,设置不同的过期时间,让缓存失效的时间尽量均衡
缓存倾斜
指某一台 redis 服务器压力过大而导致该服务器宕机。
Redis 安全设置
设置密码
我们可以通过 redis 的配置文件设置密码参数,这样客户端连接到 redis 服务就需要密码验证,这样可以让 redis 服务更安全。
1、通过命令查看是否设置了密码验证
127.0.0.1:6379> config get requirepass requirepass- 1
- 2
- 3
2、通过命令设置密码
127.0.0.1:6379> config set requirepass root OK- 1
- 2
3、此时进行的任何操作都必须经过密码的验证
127.0.0.1:6379> config get requirepass NOAUTH Authentication required. 127.0.0.1:6379> auth root OK 127.0.0.1:6379> config get requirepass requirepass root- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

通过 Jedis 操作 Redis
概述
redis 的 Java 编程客户端,Redis 官方首选推荐使用 Jedis,jedis 是一个很小但很健全的
redis 的 java 客户端。通过 Jedis 可以像使用 Redis 命令行一样使用 Redis。
jedis 完全兼容 redis 2.8.x and 3.x.x
Jedis 源码:https://github.com/redis/jedis
Jedis 下载地址: https://github.com/redis/jedis/releases
api 文档:http://redis.github.io/jedis/
常用API
// Jedis核心类,相当于一个连接,内置了和Redis同名的方法 class Jedis { // 通过主机名和端口号获取Jedis连接 Jedis(String host, int port); // 设置连接所需的密码 String auth(String password); // 设置String类型的键值对 String set(String key, String value); // 根据键获取值 String get(String key); } // Jedis连接池配置对象 class JedisPoolConfig {} // Jedis连接池,用来获取Jedis连接 class JedisPool { // 通过主机和端口获取Jedis连接池 JedisPool(String host, int port); // 通过连接池配置对象,主机和端口号获取连接 JedisPool(GenericObjectPoolConfig poolConfig, String host, int port); // 通过连接池配置对象,主机、端口号、过期时间、密码、数据库源获取连接 JedisPool(GenericObjectPoolConfig poolConfig, String host, int port, int timeout, String password, int database); // 获取Jedis连接 Jedis getResource(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
案例代码
【注意】使用之前要确保将绑定 127.0.0.1 注释掉,并且把保护模式关掉。如果是Linux还需要关闭防火墙
1、pom.xml 导入对应的 jar 包
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0modelVersion> <groupId>com.fcgroupId> <artifactId>08_Redis_JedisartifactId> <version>1.0-SNAPSHOTversion> <properties> <maven.compiler.source>8maven.compiler.source> <maven.compiler.target>8maven.compiler.target> properties> <dependencies> <dependency> <groupId>redis.clientsgroupId> <artifactId>jedisartifactId> <version>3.5.1version> dependency> <dependency> <groupId>com.fasterxml.jackson.coregroupId> <artifactId>jackson-databindartifactId> <version>2.12.1version> dependency> <dependency> <groupId>junitgroupId> <artifactId>junitartifactId> <version>4.13version> dependency> <dependency> <groupId>org.projectlombokgroupId> <artifactId>lombokartifactId> <version>1.18.16version> dependency> dependencies> project>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
2、声明实体类对象
@Data @NoArgsConstructor @AllArgsConstructor public class User { private Integer id; private String name; private Integer age; private String info; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3、编写测试类
public class JedisDemo { /** * 测试Jedis连接Redis */ @Test public void testString() { // 使用IP地址和端口号获取Jedis操作对象 Jedis jedis = new Jedis("192.168.204.132", 6379); // 设置密码 // jedis.auth(); // 使用set方法设置String类型的键值对 String result = jedis.set("name", "易烊千玺"); System.out.println("是否设置成功:" + result); // exists方法判断指定键是否存在 Boolean nameExists = jedis.exists("name"); if (nameExists) { // 通过键获取值 String name = jedis.get("name"); System.out.println("name:" + name); } // 关闭资源 jedis.close(); } /** * 测试通过jedis池获取连接 */ @Test public void testJedisPool() { // 获取Jedis池配置对象 JedisPoolConfig jedisPoolConfig = new JedisPoolConfig(); // 设置最小的闲置连接数 jedisPoolConfig.setMinIdle(0); // 设置最大的闲置连接数 jedisPoolConfig.setMaxIdle(10); // 设置最大连接数 jedisPoolConfig.setMaxTotal(20); // 检查空闲连接是否可以使用 jedisPoolConfig.setTestOnBorrow(true); // 通过jedis池配置对象以及IP地址和端口号获取jedis连接池 JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.204.132", 6379); // 通过连接池获取jedis连接 Jedis jedis = jedisPool.getResource(); try { // 创建实体类对象 User user = new User(1, "易烊千玺", 20, "送你一朵小红花"); // 获取Jackson核心对象 ObjectMapper mapper = new ObjectMapper(); // 实体类对象转json字符串 String jsonString = mapper.writeValueAsString(user); // 设置String类型的键值对 String result = jedis.set("user", jsonString); // 设置过期时间 jedis.expire("user", 60 * 60); // 通过键取值 String value = jedis.get("user"); // json字符串转实体类对象 User readValue = mapper.readValue(value, User.class); System.out.println(result); System.out.println(readValue); } catch (JsonProcessingException e) { e.printStackTrace(); } finally { // 关闭资源 jedis.close(); jedisPool.close(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
SpringBoot 整合 Redis
基础使用
1、pom.xml 导入依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0modelVersion> <parent> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-parentartifactId> <version>2.4.2version> <relativePath/> parent> <groupId>com.fcgroupId> <artifactId>springboot-redisartifactId> <version>0.0.1-SNAPSHOTversion> <name>springboot-redisname> <description>Demo project for Spring Bootdescription> <properties> <java.version>1.8java.version> properties> <dependencies> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-data-redisartifactId> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-webartifactId> dependency> <dependency> <groupId>org.projectlombokgroupId> <artifactId>lombokartifactId> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-testartifactId> <scope>testscope> dependency> dependencies> <build> <plugins> <plugin> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-maven-pluginartifactId> plugin> plugins> build> project>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
2、application.yml
# Redis相关 spring: redis: host: localhost database: 0 port: 6379- 1
- 2
- 3
- 4
- 5
- 6
3、User 实体类
@Data @NoArgsConstructor @AllArgsConstructor public class User implements Serializable { private Integer id; private String name; private String gender; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4、RedisController
@RestController @RequestMapping("redis") public class RedisController { @Autowired private RedisService redisService; /** * 添加 * @param key 键 * @param value 值 * @return */ @RequestMapping("putString") public String putString(String key, String value) { redisService.put(key, value); return "添加成功"; } @RequestMapping("putObject") public String putObject(String key, User user) { redisService.put(key, user); return "添加成功"; } @RequestMapping("get") public Object get(String key) { return redisService.get(key); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
5、RedisService
public interface RedisService { void put(String key, Object value); Object get(String key); }- 1
- 2
- 3
- 4
- 5
6、RedisServiceImpl
@Service("redisService") public class RedisServiceImpl implements RedisService { @Autowired private RedisTemplate<Object, Object> redisTemplate; @Override public void put(String key, Object value) { redisTemplate.opsForValue().set(key, value); } @Override public Object get(String key) { return redisTemplate.opsForValue().get(key); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
使用 Json 解析工具类以及 Redis 工具类【重点】
1、pom.xml 导入依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0modelVersion> <parent> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-parentartifactId> <version>2.4.2version> <relativePath/> parent> <groupId>com.fcgroupId> <artifactId>springboot-redisartifactId> <version>0.0.1-SNAPSHOTversion> <name>springboot-redisname> <description>Demo project for Spring Bootdescription> <properties> <java.version>1.8java.version> properties> <dependencies> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-data-redisartifactId> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-webartifactId> dependency> <dependency> <groupId>com.fasterxml.jackson.coregroupId> <artifactId>jackson-databindartifactId> dependency> <dependency> <groupId>redis.clientsgroupId> <artifactId>jedisartifactId> dependency> <dependency> <groupId>org.projectlombokgroupId> <artifactId>lombokartifactId> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-testartifactId> <scope>testscope> dependency> dependencies> <build> <plugins> <plugin> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-maven-pluginartifactId> plugin> plugins> build> project>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
2、Json 解析工具类
/** * 提供一些方法用来进行Json字符串解析 */ public class JacksonUtils { private static final ObjectMapper mapper; private static final TypeFactory typeFactory; static { mapper = new ObjectMapper(); typeFactory = mapper.getTypeFactory(); } /** * Json字符串转实体类对象 * * @param jsonString Json字符串 * @param valueType 实体类的字节码对象 * @param泛型 --> 实体类对象的类型 * @return 返回一个实体类对象 */ public static <T> T toObject(String jsonString, Class<T> valueType) { if (jsonString == null) { return null; } T obj = null; try { obj = mapper.readValue(jsonString, valueType); } catch (JsonProcessingException e) { e.printStackTrace(); } return obj; } /** * Json字符串转对象数组 * * @param jsonString Json字符串 * @param param 实体类的字节码对象 * @param泛型 --> 实体类对象的类型 * @return 返回一个对象数组 */ public static <T> T[] toArray(String jsonString, Class<T> param) { if (jsonString == null) { return null; } ArrayType arrayType = typeFactory.constructArrayType(param); T[] array = null; try { array = mapper.readValue(jsonString, arrayType); } catch (JsonProcessingException e) { e.printStackTrace(); } return array; } /** * Json字符串转List集合 * * @param jsonString Json字符串 * @param params 实体类的字节码对象 * @param泛型 --> 实体类对象的类型 * @return 返回一个包含实体类对象的List集合 */ public static <T> List<T> toList(String jsonString, Class<T> params) { if (jsonString == null) { return null; } JavaType javaType = typeFactory.constructParametricType(Collection.class, params); List<T> list = null; try { list = mapper.readValue(jsonString, javaType); } catch (JsonProcessingException e) { e.printStackTrace(); } return list; } /** * Json字符串转Map映射 * * @param jsonString Json字符串 * @param param1 键的字节码对象 * @param param2 值的字节码对象 * @param泛型1 --> Map中键的数据类型 * @param public static <K, V> Map<K, V> toMap(String jsonString, Class<K> param1, Class<V> param2) { if (jsonString == null) { return null; } JavaType javaType = typeFactory.constructParametricType(Map.class, param1, param2); Map<K, V> map = null; try { map = mapper.readValue(jsonString, javaType); } catch (JsonProcessingException e) { e.printStackTrace(); } return map; } /** * 实体类对象转Json字符串 * * @param t 实体类对象 * @param泛型2 --> Map中值的数据类型 * @return 返回一个Map映射 */ 泛型 --> 实体类对象的类型 * @return 返回一个Json格式的字符串 */ public static <T> String toJsonString(T t) { if (t == null) { return null; } String value = null; try { value = mapper.writeValueAsString(t); } catch (JsonProcessingException e) { e.printStackTrace(); } return value; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
3、Redis 工具类
/** * Redis工具类,用来对Redis进行读取和写入操作 */ public class RedisUtils { private static final StringRedisTemplate template; static { template = new StringRedisTemplate(); // 使用Jedis设置连接工厂 template.setConnectionFactory(new JedisConnectionFactory()); // 初始化opsForValue等操作对象 template.afterPropertiesSet(); } /** * 设置键值对 * @param key 键 * @param value 值 */ public static void set(String key, String value) { ValueOperations<String, String> opsForValue = template.opsForValue(); opsForValue.set(key, value, 60 * 60, TimeUnit.SECONDS); } /** * 通过键获取值 * * @param key 键 * @return 值 */ public static String get(String key) { ValueOperations<String, String> opsForValue = template.opsForValue(); return opsForValue.get(key); } /** * 通过键删除对应的键值对 * * @param keys 键 * @return 是否删除成功 */ public static Boolean delete(String... keys) { boolean flag = false; Long result = template.delete(Arrays.asList(keys)); if (null != result) { flag = true; } return flag; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
4、Controller
@RestController @RequestMapping("redis") public class RedisController { @Autowired private RedisService redisService; /** * 测试Json解析工具类以及Redis工具类 * @param key 键 * @param user 值 * @return 返回Redis中的结果 */ @RequestMapping("testUtils") public Object testSetOnUtils(String key, User user) { redisService.putOnUtils(key, user); return redisService.getOnUtils(key); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
5、service 层接口
public interface RedisService { Object getOnUtils(String key); }- 1
- 2
- 3
6、service 层接口实现类
@Service("redisService") public class RedisServiceImpl implements RedisService { @Override public void putOnUtils(String key, User user) { String string = JacksonUtils.toJsonString(user); RedisUtils.set(key, string); } @Override public Object getOnUtils(String key) { return RedisUtils.get(key); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
补充:测试 Redis 性能
格式
redis-benchmark [option] [option value]- 1
redis 性能测试工具可选参数
序号 选项 描述 默认值 1 -h 指定服务器主机名 127.0.0.1 2 -p 指定服务器端口 6379 3 -s 指定服务器 socket 4 -c 指定并发连接数 50 5 -n 指定请求数 10000 6 -d 以字节的形式指定 SET/GET 值的数据大小 2 7 -k 1=keep alive 0=reconnect 1 8 -r SET/GET/INCR 使用随机 key, SADD 使用随机值 9 -P 通过管道传输 请求 1 10 -q 强制退出 redis。仅显示 query/sec 值 11 –csv 以 CSV 格式输出 12 -l 生成循环,永久执行测试 13 -t 仅运行以逗号分隔的测试命令列表。 14 -I Idle 模式。仅打开 N 个 idle 连接并等待。 案例代码
以下实例使用了多个参数来测试 redis 性能:
$ redis-benchmark -h 127.0.0.1 -p 6379 -t set,lpush -n 10000 -q SET: 146198.83 requests per second LPUSH: 145560.41 requests per second- 1
- 2
- 3
- 4
以上实例中主机为 127.0.0.1,端口号为 6379,执行的命令为 set,lpush,请求数为 10000,通过 -q 参数让结果只显示每秒执行的请求数。
补充:Redis 发布订阅
概述
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
Redis 客户端可以订阅任意数量的频道。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mmg0KLzL-1662615623663)(Pictures/Redis发布订阅.png)]
publish
格式
注意:该命令是在 redis 的目录下执行的,而不是 redis 客户端的内部指令。
publish channel message- 1
描述
将信息
message发送到指定的频道channel。返回值为接收到信息message的订阅者数量。案例代码
# 对没有订阅者的频道发送信息 redis> publish bad_channel "can any body hear me?" (integer) 0 # 向有一个订阅者的频道发送信息 redis> publish msg "good morning" (integer) 1 # 向有多个订阅者的频道发送信息 redis> publish chat_room "hello~ everyone" (integer) 3- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
subscribe
格式
subscribe channel [channel …]- 1
描述
订阅给定的一个或多个频道的信息。。返回值为接收到的信息。
案例代码
# 订阅 msg 和 chat_room 两个频道 # 1 - 6 行是执行 subscribe 之后的反馈信息 # 第 7 - 9 行才是接收到的第一条信息 # 第 10 - 12 行是第二条 redis> subscribe msg chat_room Reading messages... (press Ctrl-C to quit) 1) "subscribe" # 返回值的类型:显示订阅成功 2) "msg" # 订阅的频道名字 3) (integer) 1 # 目前已订阅的频道数量 1) "subscribe" 2) "chat_room" 3) (integer) 2 1) "message" # 返回值的类型:信息 2) "msg" # 来源(从那个频道发送过来) 3) "hello moto" # 信息内容 1) "message" 2) "chat_room" 3) "testing...haha"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
案例代码
1、首先订阅一个频道
127.0.0.1:6379> subscribe myChannel Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "myChannel" 3) (integer) 1- 1
- 2
- 3
- 4
- 5
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wk0QO792-1662615623664)(Pictures/Redis发布订阅01.png)]
2、现在,我们先重新开启个 redis 客户端,然后在同一个频道 runoobChat 发布消息
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cOhposm5-1662615623664)(Pictures/Redis发布订阅02.png)]
3、订阅者就能接收到消息。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3cMmMzKy-1662615623665)(Pictures/Redis发布订阅03.png)]
原理
Redis 是使用 C 实现的,通过分析 Redis 源码里的 pubsub.c 文件,了解发布和订阅机制的底层实现。籍此加深对 Redis 的理解。
Redis 通过 PUBLISH、SUBSCRIBE 和 PSUBSCRIBE 等命令实现发布和订阅功能。
通过 SUBSCRIBE 命令订阅某频道后,redis-server 里维护了一个字典,字典的键就是一个个 channel,而字典的值则是一个链表,链表中保存了所有订阅这个 channel 的客户端。SUBSCRIBE 命令的关键,就是将客户端添加到给定 channel 的订阅链表中。通过 PUBLISH 命令向订阅者发送消息,redis-server 会使用给定的频道作为键,在它所维护的 channel 字典中查找记录了订阅这个频道的所有客户端的链表,遍历这个链表,将消息发布给所有订阅者。
Pub/Sub 从字面上理解就是发布( Publish )与订阅( Subscribe ),在 Redis 中,你可以设定对某一个 key 值进行消息发布及消息订阅,当一个 key 值上进行了消息发布后,所有订阅它的客户端都会收到相应的消息。这一功能最明显的用法就是用作实时消息系统,比如普通的即时聊天,群聊等功能。
补充:Redis 集群搭建
value = mapper.writeValueAsString(t); } catch (JsonProcessingException e) { e.printStackTrace(); } return value; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
}
3、Redis 工具类 ```java /** * Redis工具类,用来对Redis进行读取和写入操作 */ public class RedisUtils { private static final StringRedisTemplate template; static { template = new StringRedisTemplate(); // 使用Jedis设置连接工厂 template.setConnectionFactory(new JedisConnectionFactory()); // 初始化opsForValue等操作对象 template.afterPropertiesSet(); } /** * 设置键值对 * @param key 键 * @param value 值 */ public static void set(String key, String value) { ValueOperations- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
4、Controller
@RestController @RequestMapping("redis") public class RedisController { @Autowired private RedisService redisService; /** * 测试Json解析工具类以及Redis工具类 * @param key 键 * @param user 值 * @return 返回Redis中的结果 */ @RequestMapping("testUtils") public Object testSetOnUtils(String key, User user) { redisService.putOnUtils(key, user); return redisService.getOnUtils(key); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
5、service 层接口
public interface RedisService { Object getOnUtils(String key); }- 1
- 2
- 3
6、service 层接口实现类
@Service("redisService") public class RedisServiceImpl implements RedisService { @Override public void putOnUtils(String key, User user) { String string = JacksonUtils.toJsonString(user); RedisUtils.set(key, string); } @Override public Object getOnUtils(String key) { return RedisUtils.get(key); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
补充:测试 Redis 性能
格式
redis-benchmark [option] [option value]- 1
redis 性能测试工具可选参数
序号 选项 描述 默认值 1 -h 指定服务器主机名 127.0.0.1 2 -p 指定服务器端口 6379 3 -s 指定服务器 socket 4 -c 指定并发连接数 50 5 -n 指定请求数 10000 6 -d 以字节的形式指定 SET/GET 值的数据大小 2 7 -k 1=keep alive 0=reconnect 1 8 -r SET/GET/INCR 使用随机 key, SADD 使用随机值 9 -P 通过管道传输 请求 1 10 -q 强制退出 redis。仅显示 query/sec 值 11 –csv 以 CSV 格式输出 12 -l 生成循环,永久执行测试 13 -t 仅运行以逗号分隔的测试命令列表。 14 -I Idle 模式。仅打开 N 个 idle 连接并等待。 案例代码
以下实例使用了多个参数来测试 redis 性能:
$ redis-benchmark -h 127.0.0.1 -p 6379 -t set,lpush -n 10000 -q SET: 146198.83 requests per second LPUSH: 145560.41 requests per second- 1
- 2
- 3
- 4
以上实例中主机为 127.0.0.1,端口号为 6379,执行的命令为 set,lpush,请求数为 10000,通过 -q 参数让结果只显示每秒执行的请求数。
补充:Redis 发布订阅
概述
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
Redis 客户端可以订阅任意数量的频道。

publish
格式
注意:该命令是在 redis 的目录下执行的,而不是 redis 客户端的内部指令。
publish channel message- 1
描述
将信息
message发送到指定的频道channel。返回值为接收到信息message的订阅者数量。案例代码
# 对没有订阅者的频道发送信息 redis> publish bad_channel "can any body hear me?" (integer) 0 # 向有一个订阅者的频道发送信息 redis> publish msg "good morning" (integer) 1 # 向有多个订阅者的频道发送信息 redis> publish chat_room "hello~ everyone" (integer) 3- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
subscribe
格式
subscribe channel [channel …]- 1
描述
订阅给定的一个或多个频道的信息。。返回值为接收到的信息。
案例代码
# 订阅 msg 和 chat_room 两个频道 # 1 - 6 行是执行 subscribe 之后的反馈信息 # 第 7 - 9 行才是接收到的第一条信息 # 第 10 - 12 行是第二条 redis> subscribe msg chat_room Reading messages... (press Ctrl-C to quit) 1) "subscribe" # 返回值的类型:显示订阅成功 2) "msg" # 订阅的频道名字 3) (integer) 1 # 目前已订阅的频道数量 1) "subscribe" 2) "chat_room" 3) (integer) 2 1) "message" # 返回值的类型:信息 2) "msg" # 来源(从那个频道发送过来) 3) "hello moto" # 信息内容 1) "message" 2) "chat_room" 3) "testing...haha"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
案例代码
1、首先订阅一个频道
127.0.0.1:6379> subscribe myChannel Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "myChannel" 3) (integer) 1- 1
- 2
- 3
- 4
- 5

2、现在,我们先重新开启个 redis 客户端,然后在同一个频道 runoobChat 发布消息

3、订阅者就能接收到消息。

原理
Redis 是使用 C 实现的,通过分析 Redis 源码里的 pubsub.c 文件,了解发布和订阅机制的底层实现。籍此加深对 Redis 的理解。
Redis 通过 PUBLISH、SUBSCRIBE 和 PSUBSCRIBE 等命令实现发布和订阅功能。
通过 SUBSCRIBE 命令订阅某频道后,redis-server 里维护了一个字典,字典的键就是一个个 channel,而字典的值则是一个链表,链表中保存了所有订阅这个 channel 的客户端。SUBSCRIBE 命令的关键,就是将客户端添加到给定 channel 的订阅链表中。通过 PUBLISH 命令向订阅者发送消息,redis-server 会使用给定的频道作为键,在它所维护的 channel 字典中查找记录了订阅这个频道的所有客户端的链表,遍历这个链表,将消息发布给所有订阅者。
Pub/Sub 从字面上理解就是发布( Publish )与订阅( Subscribe ),在 Redis 中,你可以设定对某一个 key 值进行消息发布及消息订阅,当一个 key 值上进行了消息发布后,所有订阅它的客户端都会收到相应的消息。这一功能最明显的用法就是用作实时消息系统,比如普通的即时聊天,群聊等功能。
补充:Redis 集群搭建
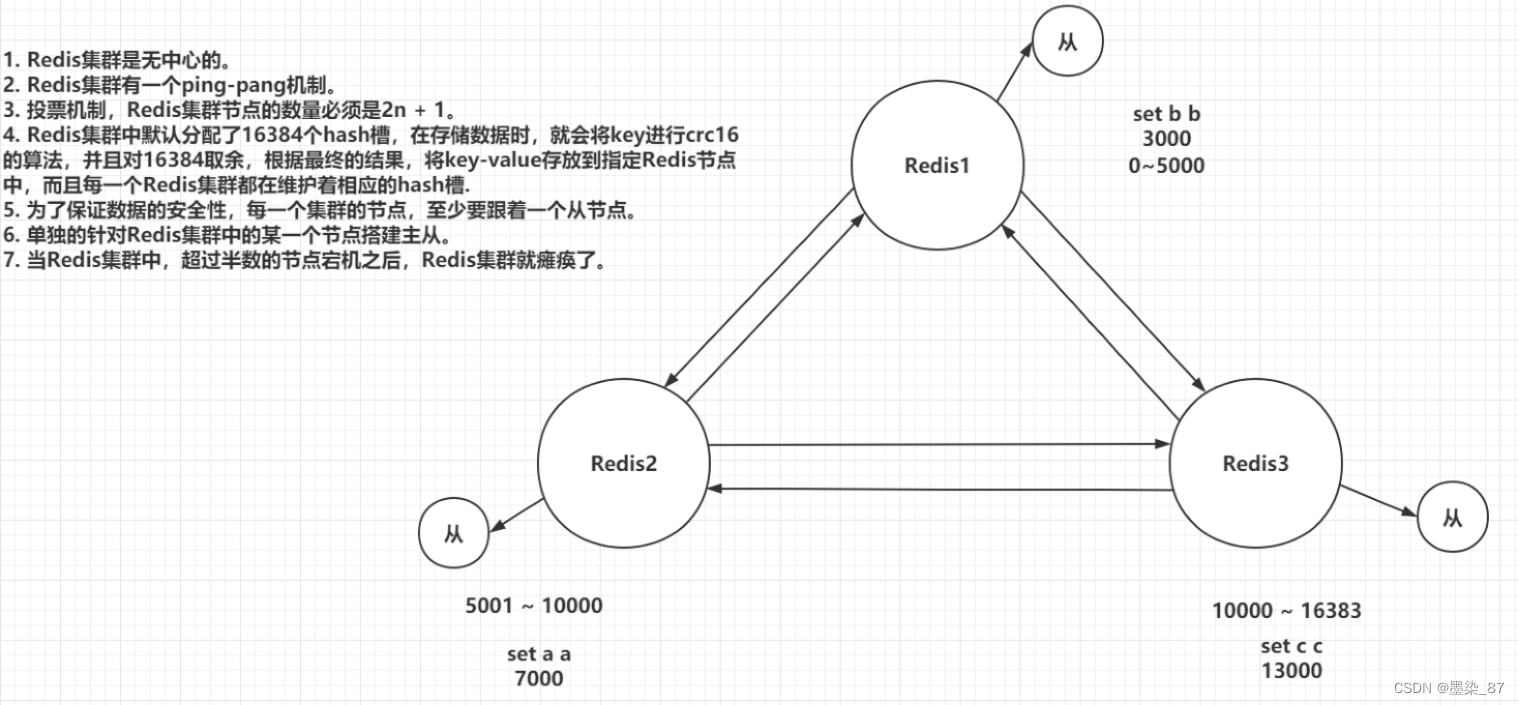
-
相关阅读:
008:安装Docker
使用golang+antlr4构建一个自己的语言解析器(二)
jquery ajax跨域解决方法(json方式)
Python文件管理
【NGINX--2】高性能负载均衡
C++文件和流
华为开发者大会2022,发布鸿蒙开发套件
Spring事件监听机制
音视频学习(十八)——使用ffmepg实现视音频解码
Oracle database 创建只读账号(新建用户与只读用户)
- 原文地址:https://blog.csdn.net/Angeliaz/article/details/126762920
