-
Policy-Based Method RL
Policy-Based Method RL

策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s) 是一个概率密度函数,以 s s s为输入,输出是 每个动作的概率分布。
agent根据策略函数随机抽样选择动作 a a a执行。
1.策略网络
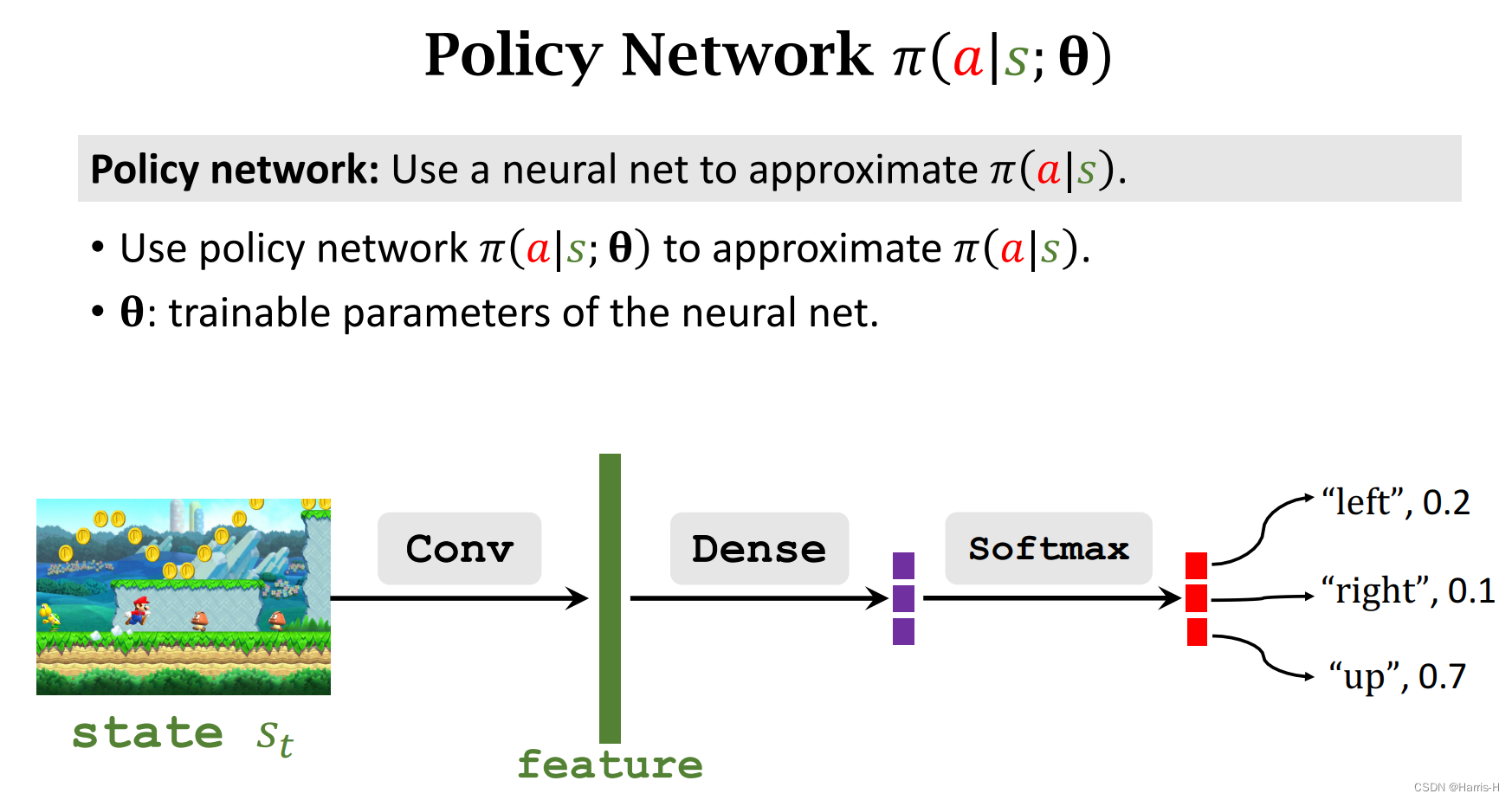
我们使用策略网络来近似策略函数 π \pi π,网络的训练参数为 θ \theta θ
2.状态价值函数

定义状态价值函数 V π ( s t ) V_\pi(s_t) Vπ(st) 为动作价值函数的期望。

当 a a a为离散随机变量时,我们将 V p i ( s t ) V_{pi}(s_t) Vpi(st) 通过连乘的方式累加求和。

通过策略网络的近似,我们可以得到如上图等式。

我们的目标是最大化 V π V_\pi Vπ对于 S S S的期望, J ( θ ) J(\theta) J(θ)用来表示当前策略 π \pi π的胜率。
因此我们要最大化 J ( θ ) J(\theta) J(θ)。
通过Policy Gradient 策略梯度算法实现。

通过带入,我们的 V V V对于 θ \theta θ的导数也就是梯度的等式变形。

通过对 π \pi π 函数相对 θ \theta θ的导数和 Q π Q_{\pi} Qπ的乘积之和,便可以得到梯度,但是该方法过于简化且不严谨,因为 Q π Q_\pi Qπ也与 θ \theta θ有关,但是最终实际结果一样。

对于连续型随机变量,我们不能使用上述方法。

而是对 log π ( θ ) \log \pi(\theta) logπ(θ) 求导数,根据链式法则可以得到如上图变形。

最后,我们可以用上图的期望所表示梯度。

因为 π \pi π策略函数是一个神经网络,无法进行积分求期望,因此我们考虑用蒙特卡洛近似,即根据策略函数随机抽样 a ^ \hat{a} a^ ,定义 g ( a ^ , θ ) g(\hat{a},\theta) g(a^,θ)作为无偏估计,近似表示梯度。
算法如下图所示:

3.价值函数如何近似

在该方法中,我们不知道价值函数 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at),我们如何近似呢?
第一种方法是REINFORCE,将agent执行完一轮的动作,得到一个 ( s , a , r ) (s,a,r) (s,a,r)的轨迹,然后用 u t u_t ut 实际回报近似 E [ U t ] E[U_t] E[Ut] 。
第二种方法就是使用actor-critic method,使用策略网络近似 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at) 函数。

-
相关阅读:
java ssm勤工助学岗位管理系统
导出视频里的字幕
Greenplum广播与重分布原理
CocosCreator3.8研究笔记(十九)CocosCreator UI组件(三)
图像处理灰度变换
Python函数
微服务概述
最全BAT大型互联网公司面试题整理,没有之一
SpringBoot整合Redis
硬件设计基础----三极管
- 原文地址:https://blog.csdn.net/weixin_45750972/article/details/126773909